SadTalker项目上手教程
背景
最近发现一个很有趣的GitHub项目SadTalker,它能够将一张图片跟一段音频合成一段视频,看起来毫无违和感,如果不仔细看,甚至很难辨别真假,预计未来某一天,一大波网红即将失业。
虽然这个项目目前的主要研究方向还是基于cuda的脸部训练,生成动态的视频,但如果能够接入语音服务,利用ChatGPT实时生成对话prompt,配合这个项目实时渲染动态视频,那么一个灵动的对话机器人就产生了。想想这两个月ai正在以可怕的速度进化,未来生命以数字形式留存,机械飞升不再是科幻小说才有的场景。
使用教程
SadTalker上手门槛低,对新手相当友好,按照我的步骤一步步进行将确保你能够正常玩转这个项目。
一、环境准备
1、安装 Anaconda
Anaconda 本身是一个python发行版本,它可以便捷获取包且对包能够进行管理,同时对环境可以统一管理。Anaconda包含了conda、Python在内的超过180个科学包及其依赖项。
Anaconda 与 Python 的区别在于,Anaconda 是一个发行版,提供了一组科学计算和数据分析的常用工具,而 Python是一种编程语言。Anaconda 是基于 Python 的,但它包含了许多 Python 库和工具,可以帮助开发者快速开始科学计算、数据分析和机器学习项目。
与 Python 的另一个区别是,Anaconda 还包含了一个叫做 conda 的包管理器,可以帮助开发者管理和部署 Python 库和工具。conda 可以帮助开发者在不同的环境中安装和使用 Python 库,并且可以方便地创建、复制和删除 Python 环境。
进入官网 anaconda,点击下载,然后按照提示安装即可,安装完成后,点电脑的开始按钮可以看到 Anaconda Prompt 的命令提示符程序,代表安装成功。
2、安装NVIDIA cuda-toolkit
项目基于 PyTorch,如果你的电脑使用了英伟达的显卡,那么建议你安装cuda-toolkit,以便充分发挥显卡进行机器训练的优势。非常不建议直接用CPU,速度会非常慢。
进入官网 cuda-toolkit,根据显卡的cuda版本号,选择对应版本的toolkit下载,然后按照提示进行安装即可,安装目录可自定义。
显卡cuda版本号可通过 nvidia-smi 命令查看。
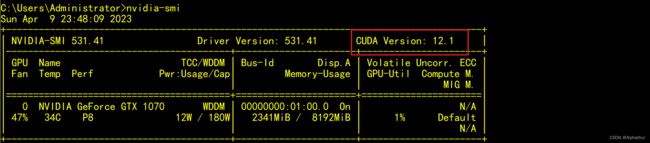
然后选择对应版本的cuda-toolkit。

3、安装 visual studio c++ 模块
如果你是首次使用 PyTorch 的新手用户,那么建议你提前安装好visual studio c++ 模块,因为PyTorch依赖于dlib库。
dlib是一个跨平台的用C++编写的代码库,这个库的机器提供了很多学习算法和工具。由于dlib库需要c++编译器,所以建议提前安装 visual studio c++ 模块,否则会报错的。
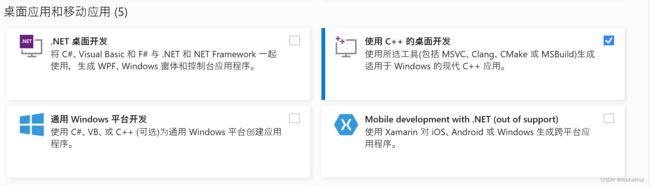
进入官网 visualstudio,选择社区版下载,仅勾选使用C++的桌面开发 ,然后安装即可。
二、下载项目及训练模型
1、下载源码
进入项目主页 SadTalker,通过Git将源码clone下来,或者直接点DownloadZip手动下载。
2 、下载gfpgan模型
gfpgan是腾讯开源的人脸复原模型,用于解决如何从低分辨率低质量的真实图像中获得较好的先验知识,复原人脸图像的问题。它利用封装在预训练脸部GAN中的丰富多样的先验信息进行人脸盲修复。这种生成性面部先验(GFP)通过空间特征变换层被纳入到人脸恢复过程中
点击 GFPGANv1.4 即可下载,将下载好的模型放到项目中E:\ProgramData\openAI\SadTalker\gfpgan\weights\下,源码是不包含\gfpgan\weights\这个目录的,可以手动创建下。
3 、下载其它必要模型
进入 Releases 页面,选择最新版本的Assets,所有除源码以外的文件都进行下载。
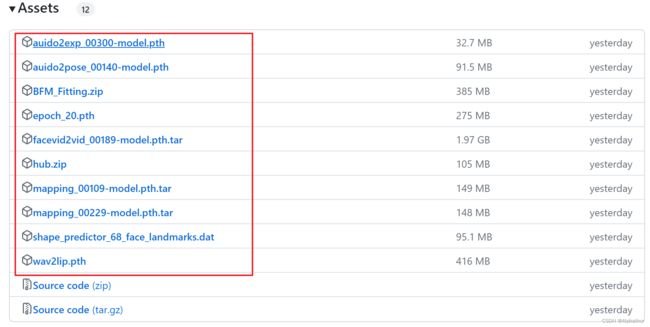 下载完成后,放到 E:\ProgramData\openAI\SadTalker\checkpoints目录下,此外需要将
下载完成后,放到 E:\ProgramData\openAI\SadTalker\checkpoints目录下,此外需要将hub.zip和BFM_Fitting.zip分别解压下,其他不用解压。源码不包含\checkpoints这个目录,需要手动创建下。
三、用 Anaconda 将项目跑起来
1、打开 Anaconda Prompt,设置pip源,并切换到项目目录

2、创建虚拟环境并安装依赖
首次运行需要通过conda create 命令创建运行环境,然后激活环境,然后下载依赖包。
以下命令执行过程中,可能会提示报错,根据报错提示下载相关的依赖即可。
如果是提示缺少dlib,那就非常考虑耐心了。由于dlib的安装需要相当长的时间,建议通过 pip install dlib -vvv 查看详细的安装进度,并且你要确保电脑不会因休眠而断网。
conda create -n sadtalker python=3.8
conda activate sadtalker
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
conda install ffmpeg
pip install -r requirements.txt
3、执行 conda info,复制GFPGANv1.4.pth到虚拟环境
根据 active env location 提示,找到虚拟环境的位置。
把源代码压缩包里面的:gfpgan\weights\GFPGANv1.4.pth 剪切到虚拟环境的 Lib\site-packages\gfpgan\weights 目录下
4、运行命令,生成视频
python inference.py --driven_audio E:\temp\sadtalker\input\1.wav --source_image E:\temp\sadtalker\input\1.jpg --result_dir E:\temp\sadtalker\output --still --enhancer gfpgan --full_img_enhancer gfpgan
其中 driven_audio 参数值要替换为 你的语音文件, source_image 参数值要替换为 你的图片, result_dir 参数值要替换为 你的资源输出目录。
这里是最后一步,可能会报错,如果出现 attempting to deserialize object on a cuda device but torch.cuda.is_available() is false.这样的报错。说明你没有正确安装GPU的cuda工具包,请返回安装NVIDIA cuda-toolkit 这一步进行安装,如有必要请升级显卡驱动。如果你确实没有英伟达的显卡,那么可根据报错提示,找到对应位置的源码,修改默认的device为cpu即可。
运行完成后,我们将看见一个栩栩如生的短视频。
后记
SadTalker项目迭代更新很快,目前已经对视频增加了水印,当然如果你有点程序基础,应该能研究出来怎么把那个水印给去掉。
另外由于迭代快,文字最后的命令可能会报错,如果你发现问题,欢迎到我评论区留言,我会尽快更新。
如果你喜欢这个项目,不妨给项目一个star,你的支持是对作者最大的鼓励。