高性能零售IT系统的建设03-监控体系化的重要不亚于开发的投入
系统监控的重要性不容小觑
前面我以两个“重口味”的例子给大家看到了这么一件事:
- 这是很基础的问题,属于1+1=2的问题;
- 可是在一个百万行代码的系统中、达百人团队协同开发时它必然会发生,不要指望这种简单问题的发生机率为0,一定有。而且这种问题有了后一定会“泛滥”最终酿成灾祸;
如我在前文中所述,99%的企业级系统开发并不是个个都是大厂的能力素质。你们可以认为大厂进去的普通程序员在“民间”都是架构师+及以上这种级别的。
99%的普通程序员只要思想上麻痹、一时疏忽一定会犯这种错误,而且这种错误一犯影响就是一大片。所以你把这种低级错误放到百万行代码的生产环境中去,这要改造和治理真心好比登天一样的复杂化。
况且,大都甲方(此处的甲方:指非IT专业以实业为基础来经营和运营的公司又需要IT能力的情况)都不会从0开始开发,至少他们会买一个框架,这个框架可以没有业务功能、没有menu、但是它至少要有一堆的在DB内可以支撑本企业业务运营、经营开展的那些“数据模型Table”和访问这些Table的基本的CRUD功能。这也是为什么大都“甲方”型企业在选型时,较大比重去看这个系统的“业务功能”是否较完善的核心道理。
这是现实、也是必要的。因为按照TOGAF架构核心思想,IT本身就是为“业务”去赋能的,这是对的。只是我们在实际工作中往往容易疏忽掉“技术为底”,没有了底上层就是建筑在沙滩上的城堡。
所以我们要做的是:不怕有这种“烂”代码,怕的是你找不到、发现不了,或者已经“成灾”并造成了严重损失后才意识到问题所在。并且我们需要避免动不动就把这样的一个生产环境推倒了重来。这个代价太大了。
项目被推倒不只是系统被 rm -fR这么简单的一个事情,而是这个部门、这些人、包括这个领导都给rm -fR了。
因此我们才需要完善的、体系化的去打造我们的监控体系。这就是本章的由来和我前面先写下两篇“重口味”篇章的原因。
一个企业级监控体系是如何一步步成型的
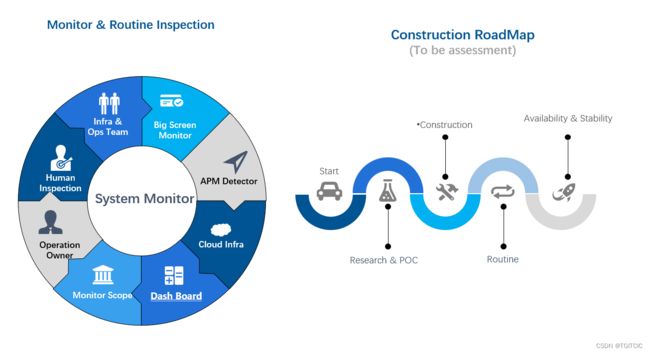
上图是我的总结,请抱歉因为本人的工作环境和我的笔记本上运行环境的道理,因此英语用了较多。
看左边:
- 专职运维人员,其实这部分运维人员已经超脱普通的运维人员了,他们其实是一支有devops能力的团队;
- 人肉巡检机制,我们制定了几十条每天上班如:打开APP看一下首页,点一下分类,下几单,再把它退了,以此来看看全过程中有无异常和卡顿,如有,那么我们会抛在一个工作群里把截图或者是手机操作时的截屏短视频可以体验出问题所在的截屏+上问题描述,以提醒level1人员和level2人员尽快响应。指的是这种:人肉巡检机制是必须要有的;
- operation owner,我们提倡全员是owner,一起为这个系统负责,因此我们需要制定level1-发现接收通用问题运维人员->level2-在level1基础上搞不定的需要开发代码看数据库、redis、mongo等才能搞得定的那批开发->level3-level2开发也搞不定了需要动到底层、算法类的研发人员或者是架构师一类才能搞得定的人;
- 监控范围,监控体系庞大又复杂,废力又烧钱。和之前我提到过的业务系统和大数据平台的建设一样,不要想着一蹴而就,也不要想着everything has been ready后再去开展业务。任何接地气的企业一定是小步快跑、敏捿叠代、逐步就位这么去搞的。那么设定每一个阶段的监控主力目标的规划是很重要的;
- dash board,这个dash board做大了可以做到超级复杂,但一开始的核心监控目标对我们来说其实最重要的就是各个模块、微服务的cpu、内存、网络IO、磁盘容量、中间件里如:redis的key数值、命中率;rabbitmq的连接数、内存使用率;mysql的主从是否有延迟;这种东西看看很多,一点不难,利用zabbix或者是grafna里都带有成熟的监控模板。你要做的就是填上相应的被监控系统、模块、应用的ip、端口、用户名、密码。这样的一个个以表格形式的东西就在grafna里出现在了你的面前了。然后你在grafna里把“刷新”时间设成“间隔5s、间隔10s”,这个dash board就会自己在那实时刷新了;
- cloud infra,现在都是云,云上自带不少监控不少dashboard,云上还有一些不一样的东西如:waf、cdn,这些东西利用起来利用它们里面自带的“回拨、回源、流量、黑产、DDOS、BOT”可以补足在“一开始阶段”的基本流量端监控所需;
- APM-留作专门的一个章节我们去讲解它的用处;
- big screen,哈哈!这个东西就是监控大屏。各位想一下,我们先有了基础的监控、数据可以抓到了、表格也能显示了、前后端不说高大上我们说实用性来说能满足一家企业、一个团队对于生产环境前半年运行的基本监控需要后,我们后面是不是才可以“基于”这些前提的基础上做一些:实时变化的柱状啦、饼啦、折线这些东西?是不是得有一个这样的先后过程呢?
看右边:
- start阶段,整个监控体系打造一定是小步快跑,敏捷叠代的。就算一下给你800万,你的团队也得从第一个人开始招吧?你不能说等我把人招齐了、硬件设备都买好了才开始监控,此时生产早出问题N遍了。
- research & poc,在我们手上只有“一把刀”、“一包火柴”、一些苦松枝的情况下,我至少可以先把火生起来、削木成箭、成矛用来抵御“夜晚出现的夜兽”吧?我们有不少同学,一开始就进入了大厂,这有好处也有不好的地方。好的地方在于他进去后的大厂环境是一个:everything has been ready,要什么有什么。不好的地方在于:不知道如何从0开始打造一个体系化的系统。这就是为什么我们在有限人员、有限资源的情况下我们会先去做一些poc论证。
- construction,少bla bla,多动手。少poc,而要把poc变成真正的production(生产应用)。因此我的建设是直接在生产上做POC,又省时又省力,因为监控是以对数据“读”为主,搞不死生产的因此不要太害怕胆大心思是法宝。目前外面开源方案太多太多,随便一抓一大把。但是选择最适合自己企业的组合才是最重要的。因此你要衡量手上的人力资源、人员素质和硬件相关资源。大厂有的是钱,监控上投个九位数,那个监控体系就是一整套的DevOps产品甚至自带AI的呢。而99%的企业我们都是这么一步步走过来的,都是需要在起步阶段用有限的资源去最大化满足我们的生产监控需要。因此我们没有那么多“启动资金”和“人手”,我们的方案在刚开始虽然对比大厂近10年来打造出来的产品像是个:乞丐叫花去和龙王比宝。但我说了,我们是从0开始打造,因此我们知道这个系统的每一条脉络、每一个“脾气”、“习性”、“品行”,并且最后过了3年再回首我们其实发觉最终成型的体系化的东西一点不比大厂差。这就叫“你扔你的原子弹,我打我的手榴弹”。
- routine,你光建设不执行、没有人去看也不行。监控监控,这东西就是需要人去看的,而且 不能说上了线看了挺漂亮,哎。。。第一眼看上去:黑屏、金属质感、科技感,很漂亮是吧?然后很多人看一眼就再也不去看了。你当监控是维密秀哈?这玩意如果不是天天、经常、持续(routine)的去看去发现、去发掘问题的话那么要这个监控干什么呢?
- availability & stability,这边就不需要多说什么了,只说一个很好玩的事。有一个企业一直被TO C端客户投诉不稳定,而这个企业的IT部门一直不能提前和及时发现问题,结果最后第三方顾问介入了,发觉是因为:生产环境的监控系统本身已经崩了。因此它的那个“指针”老是指着错误率为0这个刻度上。同时一个经营、运营生产环境它是有“稳定性、可用率”要求的。这一块我会在后文展开。
一个企业级的监控怎么一步步开始打造出来
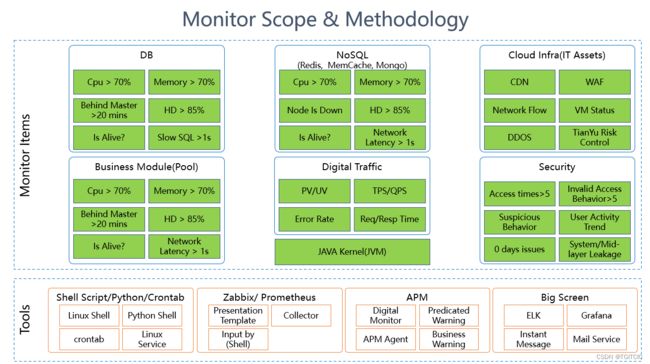
这个图是我4年多前提议给公司全球总部数字化管委会的“如何一步步打造我们自己的监控系统”。
如上文所述,我们和大厂没得比,去和特例比这本身就不具备可比性和科学性。如果你的团队一下子可以拿到:光可用在运维、监控上就达9位数投资的话那么你直接去问大厂买一整套监控平台布署在你企业就行了。
而这显然是天方夜谭,因此我们秉承着:你扔你的原子弹,我打我的手榴弹的顽强作风,我们规划了:
- 率先对于DB、NOSQL一类的cpu、内存、磁盘可利用率、是否活着、错误率、平均响应时间、网上的流量端资源如:CDN、WAF、DDOS、VM(云服务器)、基本入侵安全、信息泄漏、OWASP TOP10、0day漏洞这些基本资源的监控。它们会分布在2-3个监控portal内,也就是说我们的监控人员可能需要输入2-3个网址,在这2-3个网址间切换查看才能看到这些不同的内容(叫花子和龙王比宝,我们不去比一体化监控,光这些值想要把它们搞在一起你没个7位数搞不定)。那么后面在这些基础数据具备了、生产运行了挺好、业务上去了、单子多起来后我们自然一步步再把它们不断的去完善和一体化起来;
- 对于这2-3个监控portal,我们的技术手段为:有一些linux shell脚本,一些python脚本,我们主推prometheus+grafna来做dashboard,二期才会考虑去用APM,在一阶段的大屏我们也是需要几个的如:ELK内可以显示慢SQL、哪些微服务模块目前正在狂抛错(因为收集error的log4j日志)、我们甚至还会利用企业微信(免费的)的API+后端收集错误日志设置业务触发规则当达到一个什么阀值后,直接发一条企业微信到你的手机上提醒你目前有个什么错误正在发生呢。怎么样?这个东西的背后是“叫花子”,可是它起到的作用。。。照样可以“杀敌”;
利用免费开源和现有力量在建设过程中对于监控工具的补足
我们有了这些基本的监控已经可以满足我们的生产所需了,可是生产环境瞬息万变,我们对于“报警”看得很重,尤其是报警的实时性!
企业微信在监控场景中的应用
因此才有了利用企业微信的应用场景,你可以免费注一个,然后里面的API调用都是免费的。免费的和收费的企业微信API唯一区别在于:并发有无限制而己。
那么我们反过来试问自己:我们监控运维人员一共也就10来个人,要什么上百上千并发呢?你能满足我50个并发我已经开心的不得了了。
我们在企业微信里把一个个应用自己去分门别类的建立起来。
然后利用企业微信提供的免费API自己结合shell、python去写一些小脚本。
然后,看,你的手机上的微信就可以收到这样的“及时”报警消息了。
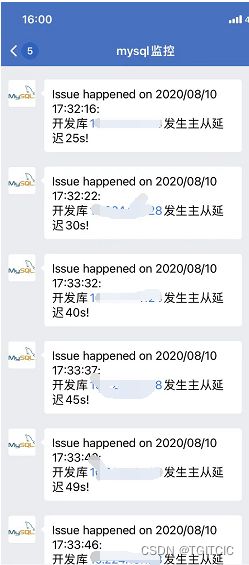
自己写一些小脚本
当然,我们的生产级脚本比下面我给出的要复杂的多,但是它的核心机制就这些,因此我可以给出各位拿了后也可以直接去运行的核心。
抓取mysql当前我们需要知道的qps、tps的值
这个值抓到了后我们可以用grafna抽到显示屏上或者把这个值里设一些预设阀值,然后发觉异常调用企业微信API去做实时报警。
#!/bin/bash
mysqladmin -uroot -p'111111' extended-status -i1|awk 'BEGIN{local_switch=0;print "QPS Commit Rollback TPS Threads_con Threads_run \n------------------------------------------------------- "}
$2 ~ /Queries$/ {q=$4-lq;lq=$4;}
$2 ~ /Com_commit$/ {c=$4-lc;lc=$4;}
$2 ~ /Com_rollback$/ {r=$4-lr;lr=$4;}
$2 ~ /Threads_connected$/ {tc=$4;}
$2 ~ /Threads_running$/ {tr=$4;
if(local_switch==0)
{local_switch=1; count=0}
else {
if(count>10)
{count=0;print "------------------------------------------------------- \nQPS Commit Rollback TPS Threads_con Threads_run \n------------------------------------------------------- ";}
else{
count+=1;
printf "%-6d %-8d %-7d %-8d %-10d %d \n", q,c,r,c+r,tc,tr;
}
}
}'监控我们的DB主从延迟如果有发生那么调企业微信API发送实时报警
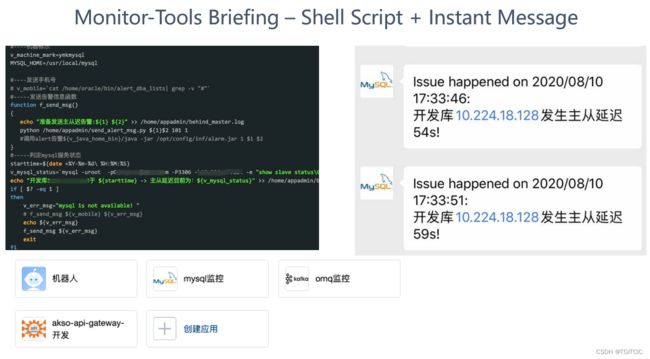
- 我们用JAVA做了一个小服务,内部调用了企业微信的API来进行传送消息。
- 然后我们用shell作mysql的主从延迟抓取,一旦抓取到了相应的信息后通过调用python或者是curl命令也可以,触发java小服务中的sendMsg API。
主从监控mysql shell脚本
#!/bin/bash
#desc:脚本
#通过从库监控Seconds_Behind_Master的值监控延迟情况。
#该值为null或着超过告警阈值会报错.
#本脚还通过mysql命令执行情况判定mysql服务可用状态。
#author:mk
#date:2018/04/27
#source ~/.bash_profile
#source ~/.bashrc
#----Seconds_Behind_Master的值
WebUrl=http://localhost:9080/gateway/index
v_sbm='NULL'
#----检测域值,单位s
v_threshold=1
#----机器标示
v_machine_mark=ymkmysql
MYSQL_HOME=/usr/local/mysql
#----发送手机号
# v_mobile=`cat /home/oracle/bin/alert_dba_lists| grep -v "#"`
#-----发送告警信息函数
function f_send_msg
{
if [ ! $# -eq 2 ]
then
echo "usage:"
echo "f_send_msg ${error_msg}"
exit 0;
fi
python /Users/apple/opt/monitor/send_alert_msg.py ${error_msg} 101 1
#调用alert告警${v_java_home_bin}/java -jar /opt/config/inf/alarm.jar 1 $1 $2
}
#-----判定mysql服务状态
v_mysql_status=`/usr/local/mysql/bin/mysql -uroot -p111111 -P3307 -h127.0.0.1 -e "show slave status\G"|grep Seconds_Behind_Master`
if [ $? -eq 1 ]
then
v_err_msg="mysql is not available! "
# f_send_msg ${v_mobile} ${v_err_msg}
echo ${v_err_msg}
f_send_msg ${v_err_msg}
exit
fi
#------判定延迟情况
v_sbm=`echo ${v_mysql_status}|awk -F ":" '{print $2}'`
if [ "${v_sbm}" = " NULL" ]
then
v_err_msg="${v_machine_mark}_delay Seconds_Behind_Master is ${v_sbm}!"
# f_send_msg ${v_mobile} ${v_err_msg}
echo ${v_err_msg}
f_send_msg ${v_err_msg}
elif [ ${v_sbm} -gt ${v_threshold} ]
then
v_err_msg="${v_machine_mark}_delay Seconds_Behind_Master is ${v_sbm}!"
#f_send_msg ${v_mobile} ${v_err_msg}
echo ${v_err_msg}
f_send_msg ${v_err_msg}
fisend_alert_msg.py
#!/usr/bin/python
import re
import requests
import time
import json
import sys
url='http://localhost:9081/alertservice/sendMsg'
if (len(sys.argv)>1):
inputedmsg=sys.argv[1]
msgtype=sys.argv[2]
modelId=sys.argv[3]
print('input message->'+inputedmsg+' input msgtype->'+msgtype+' modelId->'+modelId)
currentTime=time.strftime('%Y/%m/%d %H:%M:%S',time.localtime(time.time()))
print 'current time is ', currentTime
if(msgtype=='101'):
wechatmsg='Issue happened on ' +currentTime +':\n'+ inputedmsg
wechatcontent={"modelId": modelId, "content": wechatmsg}
wechatheaders = {"content-type": "application/json; charset=UTF-8", "type": "101"}
req = requests.post(url, data=json.dumps(wechatcontent),headers=wechatheaders)
print(req.text)
elif(msgtype=='102'):
print('send mail msg')
else:
print('inputed msgtype required 101|102')
else:
print('inputed msg can not be null')用Glowroot补足生产监控中JVM内对象情况的监控
由于普通监控我们有时还需要深入了解到JVM内核,我们就使用glowroot。我们当然使用的是glowroot central的搭建,因为我们有30多个微服务模块,如果用的是glowroot的单机搭建那么我们为了监控不同的微服务内的jvm对象,我们需要在30多个glowroot的webui间切换。更况且我们用的是云原生,每次微服务模块的布署和重启会导致IP都变化的,30多个webui地址动态的怎么记得住?这不是变相增加了监控的“人肉成本”吗。
因此我们使用了glowroot的central搭建模式。
用druid来解决全局慢sql监控

然后要求开发按照时间排序,把所有的基于单表100万数据量、笛卡尔积1,000万数据底上进行即时交易类SQL凡是那些超过500毫秒的sql统统优化到300毫秒。
体系化监控中监控流程设计的重要性

上面我们用这些一个个“手榴弹”组织起来了我们的第一步监控防线,它是一个从0开始搭建的过程。从表面上看它虽然“土”,但是任何成熟的监控和平台都是这些一个个小土包子逐步发展和壮大起来的。而且整个团队经历了从0开始的过程,所以过了若干年,现在再看这支团队,一点不比大厂差。
有了工具,关键还有人。
而在企业IT信息化建设中,人恰恰是最容易犯错的。机器是不会犯错,只有人会犯错。
如何阻制人员的犯错和疏漏呢?你天天拿着鞭子抽?
这不是办法。
凡人凡人、活着就是被烦着的,因此我们需要需要训练人员。
我们把监控分为:
- 被动监控(以即时、邮件报警触发式响应);
- 主动监控(人肉监控);
- 结合项目CR开发流程;
被动监控
对于被动监控,即这个监控动作是由我们上面用的各种小工具来触发式完成的。一个工具当抓到了一条异常,它会以即时通讯工具或者邮件或者电话(钉钉带有这个功能)通知到相应的监控运维组人员,收到消息的运维人员必须在XXX分钟内马上开始根据预先定义的错误字典手册翻阅、查找。如果不能在XXX时间内搞定,那么它必须把这个case进行上升,即上升到level2,往level2和level1、level3共存的群里一抛(我们不用ticket机制,很多外资企业喜欢使用ticket,一个ticket流程下来几小时没了,生产环境都歇菜了还要监控有什么用呢?)。
level2收到消息后马上在XXX分钟内响应去排查问题。如果level2再搞不定往level3去上升这个问题。
主动监控
主动监控中我们设计有:前端人肉巡检流程,这个流程对于熟悉本企业业务的level1和level2来说,拿着手机、用鼠标点一点这样一轮下来不会超过30分钟,没事自己多玩玩、多点点、自己公司的东西你还能不玩了熟练?
这就是为什么一些大厂甚至有出现:如果你连自己公司的小程序、APP都玩不到每天多少分钟,你的KPI是不会好的的由来。
当发现了问题,老规矩:必须在XXX分钟内开始走case level上升流程。
我们来这么想,一个互联网系统,它对于IT有一个很重要的衡量指标,即:可利用率即avilability,一般外面通用的为系统可用率达99.99%即两个9,互联网大厂一般为三个9即:99.999%。
我们就拿两个9的99.99%系统可用率来计算,99.99*365天*24小时*60分钟=525,547.44分钟,那么100%可用率为=525,600分钟,这就意味着你的系统全年只有:52.56小时非正常菪机时间。
各位,你们自己算一下,因此,你的这个每次出现问题时需要的XXX分钟内可以响应要达到多少呢?嘿嘿,我留给你们自己算。
我告诉你们大厂是99.999%的系统可用率,它有时需要人为的响应率在3分钟内而又有不少系统恢复手段不是人肉而是“机器”、是AI去自动化做的。
如果没有这个系统可用率的保证,TO C端的客户正在买东西,他下了单,一点提交按钮,小程序或者APP白屏了。那么对不起,这个用户从此不会再来你的应用上买任何东西了。
为什么要和CR流程结合
前文中我说了什么?体系化建设!IT系统是体系化建设。这个系列会有上百万字,一个个case去孤立的写吗?
那不叫体系化,那就是眉毛胡子一把抓了。
所谓的体系化即任何流程、步骤需要有“闭环”。因为只有闭环才能落地。
因此,监控一堆东西,我们如何把它真正的去和系统性能形成这个“闭环”呢?
喏,我前文中已经提到过这么一句:一个问题不能单一、孤立的去看这个问题是一个bug。当一个同类型的bug反复出现了>=3次时它就被称为了一个defect,一个defect就是一个系统上的缺陷。
因此,我们把系统的监控中的主动、被动中发现的问题也变成一个个的bug,然后用当一个同类的bug发生>=3次时当成一个defect去处理时,此时,系统在性能优化环节中的一个重要的闭环就形成了。
即监控发现的任何问题都是当bug来看、都去当bug在企业内部或用禅道、或用jira来记录和追踪起来。
这是一个相当相当重要的概念,如果没有这个闭环,你永远会陷入到改bug、改bug,改来改去还是有各种bug。而系统性能问题也会处于一种:头痛医头痛、脚痛医脚痛的境地,而不能随着时间的延长、团队的成长你的系统越来越strong。那么你的团队、你的公司也永远无法“真正成长”。
监控工具+流程只是监控体系中的万里长征第一步
自动化监控、AI监控、自动化响应
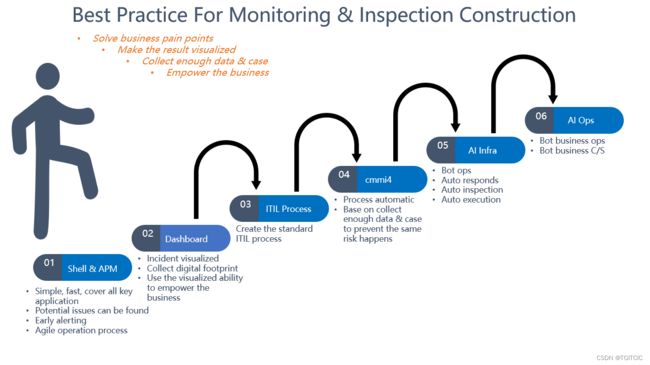
这是我在之前的某跨国公司我为整个全球总部设计的系统监控六步走体系,那家公司目前已经走到了第5步了。
我们可以看到,我上述的内容其实是在帮助大家完成第1步到第4步(包括我下一篇APM系统的介绍)。
它本身就是一个一步步走、小步快跑、敏捷叠代的过程。
我前文中已经有提及,当你的系统面临千万、亿级客户时,你的系统的可用率会到达99.999%这样的可用率要求。此时人肉根本已经响应不过来了,此时就会使用AI去做运维、用AI去做“重启、修数、切换主从”等操作。
比如说,我前面说到的有一点叫“主动巡检”中有一个“人肉点击动作标准步骤手册”,这个动作其实就可以使用很多开源免费的工具去自动做和取值以及判断从点击到取到正确值间的response time是多少的自动化判断。
比较著名的就是:Charles、Jmeter的代理机抓接口,甚至小程序上和APP上都有免费的“点击机器人”。
在你企业内部通过内网布署一个这样的AUTO Ops工具,那么它将极大化的去减少你的响应时间、人肉工作量、甚至你可以在晚上把人肉巡检工作也交给工具,让人们好好去睡觉。
看!科技改善人们的生活,就是这么来的。(微信里笑出泪的表情)
监控大屏的应用

淘宝、天猫、JD双11,都有作战室我们叫war room,各位想必家喻户晓吧。
搞一个环绕式IMAX大屏,上面实时显示各种订单、物流情况。
你可以说它是一种SHOW也罢,其实有SHOW的因素但实际也有其真正的实用的价值。
运维监控,我们知道是“苦力”活,就是因为它的工作无法可视化即:visualization。我们知道开发的工作交付物是成品、产品的交付物是:开发出来的产品可以给企业真金白银的带来运营上的收入。
运维的交付呢?它不可见?
因此我们有必要把运维的工作也visualization一下。你们看上图,它是我参与的某跨国大型企业的“作战室”,专门搞了5000多平米一个作战室。而作战室内显示的这些大屏上面有仪表盘啊、柱啊什么的还实时变化,这样的一个实时图表制作在外面是6位数制作费起板(我指仅仅图表的即时展示制作费)。
你真的以为个个企业都有这么多闲钱吗?
没!
怎么办?各位看到我上述的一些描述了吧!有了这些基础数据、利用这些基础数据先期自己制作表格来进行展示,当一支团队完整的走过这样的一个生命周期后,这支团队就会自己去制作这些大屏。其实这些大屏用的正是grafna和elk去做的,一点不需要外部第三方开发,就是我们自己的DevOps开发的。
同时,有了这些的实时大屏后,因为在一些双11等大促活动中生产情况瞬息万变,有时不仅仅需要IT系统的决策,业务和运营的决策同样也是相当重要的。
如:这边订单有卡住是因为XXX原因,需要做XXX调整。
再如:这个区域从近10分钟订单流量来看有哪几个品已经成为了爆品,而现在物流和仓储跟不上,马上打电话给李总、王总,要他们从附近的门店调拨货源去支持。
看!何止是Show的的作用,它真的是可以为业务、运营带来即时决策的作用的。因此,我们才称为“war room”。
届此,整个IT系统的监控体系化知识全部讲完。并且我们把系统监控和项目开发的CR流程形成了“闭环”从而进一步推动了高性能IT系统的建设。