4.RocketMQ消息的消费
消费类型
- pull模型: consumer主动从broker中拉取消息,由consumer控制.拉取时间由客户端指定,频率太快空请求比例会增加,过慢实时性较弱
- push模型: broker收到消息之后主动推送给consumer,由broker控制.实时性较高,采用了典型的发布-订阅模式.consumer向关联的Queue注册监听器,一旦发现有新消息就会触发回调.基于长链接,长连接的维护会需要消耗系统资源
消费模式
- 广播消费: 同consumerGroup的每一个consumer实例都接受同一个topic的全量消息
- 集群消费: 同consumerGroup中平均分摊同一个topic的消息.每个消息只会被consumerGroup中某一个consumer消费
消息保存进度
- 广播模式: 消费进度保存在consumer端,每个CG中的consumer消费进度不同,各自保存自己的消费进度
- 集群模式: 消费进度保存在broker中.消费进度会参与到消费的负载均衡中,消费进度是共享的.broker中存放了各个Queue下的消费进度
Rebalance机制
Rebalance是为了提高消息的并发消费能力,由于一个Queue只能分配给一个consumer,因此某个consumerGroup中的consumer实例如果大于了Queue的数量,多余的consumer实例将分配不到任何队列
Rebalance存在的问题
-
消费暂停: 触发rebalance之后,此时原consumer就需要暂停部分队列的消息,等到这些队列分配新的consumer后,这些暂停消费的队列才能继续消费
-
消费重复: consumer在消费新分配给自己的队列时,必须接着之前的consumer提交的消费进度offset继续消费.然后默认情况下,offset是异步提交,此时broker中的offset与consumer实际消费的进度可能不一致.这种差异可能会导致消息重复消费
同步提交:consumer提交了其消费完毕的一批消息的offset给broker后,需要等待broker的成功ACK。当收到ACK后,consumer才会继续获取并消费下一批消息。在等待ACK期间,consumer是阻塞的。
异步提交:consumer提交了其消费完毕的一批消息的offset给broker后,不需要等待broker的成功ACK。consumer可以直接获取并消费下一批消息。
对于一次性读取消息的数量,需要根据具体业务场景选择一个相对均衡的是很有必要的。因为数量过大,系统性能提升了,但产生重复消费的消息数量可能会增加;数量过小,系统性能会下降,但被重复消费的消息数量可能会减少。
-
消费突刺: 由于rebalance可能导致重复消费,如果需要重复消费的消息过多,或因为rebalance的暂停时间过长导致消息的积压.可能会在rebalance结束之后瞬间需要消费的消息过多
Rebalance产生的原因
- 消费者订阅的Topic的Queue发生变化
- Broker扩容缩容
- Broker与NameServer的网络分区
- Queue的扩容缩容
- 消费者组中的消费者数量发生变化
- ConsumerGroup 扩容缩容
- Consumer与NameServer网络分区
Rebalance的过程
broker中维护多个Map集合,集合中动态存放当前topic的Queue消息,consumer group中的consumer实例消息.一旦发现消费者订阅的Queue数量发生变化或CG中的consumer发生变化,立刻向CG中的每个consumer实例发送rebalance通知
consumer收到通知之后会采用Queue分配算法重新获取自己对应的Queue,由consumer实例自主进行rebalance
TopicConfigManager:key是topic名称,value是TopicConfig。TopicConfig中维护着该Topic中所有Queue的数据。
ConsumerManager:key是Consumser Group Id,value是ConsumerGroupInfo。
ConsumerGroupInfo中维护着该Group中所有Consumer实例数据。ConsumerOffsetManager:key为
Topic与订阅该Topic的Group的组合,即topic@group,value是一个内层Map。内层Map的key为QueueId,内层Map的value为该Queue的消费进度offset。
rebalance与kafka的区别
kafka中,触发rebalance之后,broker会调用Group Coordinator来完成rebalance.Coordinator是一个broker进程. Coordinator会在consumer group中选择一个leader,由leader根据自身组情况完成Partition的分区,再上报给Group Coordinator,由Coordinator同步给Group中的所有consumer实例
Kafka中的Rebalance是由Consumer Leader完成的。而RocketMQ中的Rebalance是由每个Consumer自身完成的,Group中不存在Leader。
Queue分配算法
平均分配算法

类似kafka的Range分配策略,该算法是要根据avg = QueueCount / ConsumerCount的计算结果进行分配的。如果能够整除,则按顺序将avg个Queue逐个分配Consumer;如果不能整除,则将多余出的Queue按照Consumer顺序逐个分配。
该算法即,先计算好每个Consumer应该分得几 个Queue,然后再依次将这些数量的Queue逐个分配个Consumer。
环形分配算法
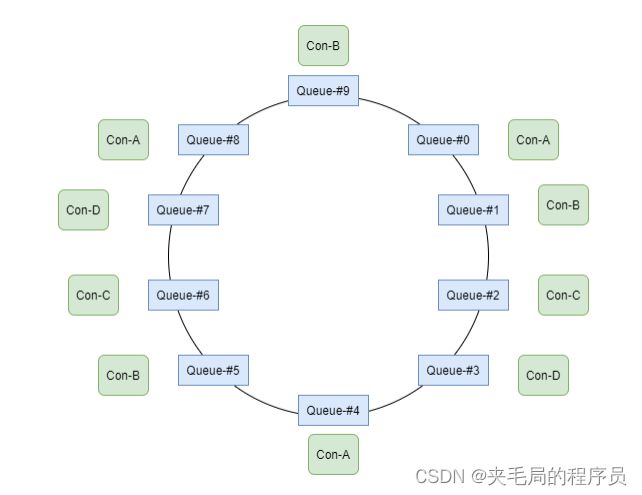
与kafka的RoundRobin类似,环形平均算法是指,根据消费者的顺序,依次在由queue队列组成的环形图中逐个分配
该算法不用事先计算每个Consumer需要分配几 个Queue,直接一个一个分即可。
一致性Hash

该算法会将consumer的hash值作为Node节点存放到hash环上,然后将queue的hash值也放到hash环上,通过顺时针方向,距离queue最近的那个consumer就是该queue要分配的consumer。
同机房策略
该算法会根据queue的部署机房位置和consumer的位置,过滤出当前consumer相同机房的queue。然后按照平均分配策略或环形平均策略对同机房queue进行分配。如果没有同机房queue,则按照平均分配策略或环形平均策略对所有queue进行分配。
对比
一致性hash算法存在的问题:
两种平均分配策略的分配效率较高,一致性hash策略的较低。因为一致性hash算法较复杂。另外,一致性hash策略分配的结果也很大可能上存在不平均的情况。
一致性hash算法存在的意义:
其可以有效减少由于消费者组扩容或缩容所带来的大量的Rebalance。
至少一次原则
RocketMQ中每一条消息至少被成功消费一次.Consumer在消费完消息后会向其消费进度记录器提交其消费消息的offset,offset被成功记录到记录器中,那么这条消费就被成功消费了。
集群模式: 消费进度记录器在broker
广播模式: 消费进度记录器在consumer
offset管理
本地管理模式
广播模式模式下Offset使用本地模式存储.每个消费者自己管理消费进度,各个消费者之间不存在消费进度交集
consumer在广播模式下Offset相关数据以json形式持久化到consumer的本地磁盘文件中.默认路径为用户家目录下 .rocketmq_offsets/${clientId}/${group}/Offsets.json。其中 c l i e n t I d 为当前消费者 i d ,默认为 i p @ D E F A U L T ; {clientId}为当前消费者id,默认为ip@DEFAULT; clientId为当前消费者id,默认为ip@DEFAULT;{group}为消费者组名称。
远程管理模式
集群模式下,offset使用远程模式管理.所有consumer实例对消息采用均衡消费.共享queue的消费进度
Consumer在集群消费模式下offset相关数据以json的形式持久化到Broker磁盘文件中,文件路径为当前用户主目录下的store/config/consumerOffset.json
Broker启动时会加载这个文件,并写入到一个双层Map(ConsumerOffsetManager)。外层map的key为topic@group,value为内层map。内层map的key为queueId,value为offset。当发生Rebalance时,新的Consumer会从该Map中获取到相应的数据来继续消费。
集群模式下offset采用远程管理模式,主要是为了保证Rebalance机制。
offset起始位置
consumer.setCusumerFromWhere()可以执行consumer的消息起始位置
public enum ConsumeFromWhere {
CONSUME_FROM_LAST_OFFSET,
@Deprecated
CONSUME_FROM_LAST_OFFSET_AND_FROM_MIN_WHEN_BOOT_FIRST,
@Deprecated
CONSUME_FROM_MIN_OFFSET,
@Deprecated
CONSUME_FROM_MAX_OFFSET,
CONSUME_FROM_FIRST_OFFSET,
CONSUME_FROM_TIMESTAMP,
}
CONSUME_FROM_LAST_OFFSET:从queue的当前最后一条消息开始消费
CONSUME_FROM_FIRST_OFFSET:从queue的第一条消息开始消费
CONSUME_FROM_TIMESTAMP:从指定的具体时间戳位置的消息开始消费。这个具体时间戳是通过另外一个语句指定的 。
consumer.setConsumeTimestamp(“20210701080000”) yyyyMMddHHmmss
当消费完一批消息后,Consumer会提交其消费进度offset给Broker,Broker在收到消费进度后会将其更新到那个双层Map(ConsumerOffsetManager)及consumerOffset.json文件中,然后向该Consumer进行ACK,而ACK内容中包含三项数据:当前消费队列的最小offset(minOffset)、最大offset(maxOffset)、及下次消费的起始offset(nextBeginOffset)。
重试队列
当rocketMQ对消息的消费出现异常时,会将发生异常的消息的offset提交到Broker中的重试队列。系统在发生消息消费异常时会为当前的topic@group创建一个重试队列,该队列以%RETRY%开头,到达重试时间后进行消费重试。
offset提交方式
集群消费模式下,Consumer消费完消息后会向Broker提交消费进度offset,其提交方式分为两种:
同步提交:消费者在消费完一批消息后会向broker提交这些消息的offset,然后等待broker的成功响应。若在等待超时之前收到了成功响应,则继续读取下一批消息进行消费(从ACK中获取nextBeginOffset)。若没有收到响应,则会重新提交,直到获取到响应。而在这个等待过程中,消费者是阻塞的。其严重影响了消费者的吞吐量。异步提交:消费者在消费完一批消息后向broker提交offset,但无需等待Broker的成功响应,可以继续读取并消费下一批消息。这种方式增加了消费者的吞吐量。但需要注意,broker在收到提交的offset后,还是会向消费者进行响应的。可能还没有收到ACK,此时Consumer会从Broker中直接获取nextBeginOffset。