pandas汇总和描述性统计
本文介绍pandas中汇总和描述性统计中的基本内容,仅供参考。
目录
1描述和汇总统计
1.1sum方法
1.2idxmin和idxmax方法
1.3describe方法
1.4描述和汇总统计的常用方法
2相关系数和协方差
3唯一值、值计数以及成员资格
3.1唯一值
3.2值计数
3.3成员资格
1描述和汇总统计
1.1sum方法
用DataFrame的sum方法将会返回一个含有列小计的Series:
- NA值会自动被排除,除非整个切片(这里指的是行或列)都是N
函数格式:
df.sum( axis=None, skipna=None, level=None, numeric_only=None, min_count=0, **kwargs, )
参数说明:
axis:约简的轴。DataFrame的行用0,列用1
skipna:排除缺失值,默认值为True
level:如果轴是层次化索引的(即Multiindex),则根据level分组约简
案例:
from pandas import Series, DataFrame
import pandas as pd
import numpy as np
df = DataFrame([[1.4, np.nan], [7.1, -4.5],
[np.nan, np.nan], [0.75,-1.3]],
index=['a','b','c','d'],
columns=[ 'one', 'two'])
df.sum()
#传入axis=1将会按行进行求和运算:
df.sum(axis=1)
df.mean(axis=1, skipna=False)



1.2idxmin和idxmax方法
idxmin和idxmax返回的是间接统计(达到最小值或最大值的索引)
案例:
df.idxmax()
df.cumsum() # 累计型的计算
1.3describe方法
用于一次性产生多个汇总统计
案例:
df1 = pd.DataFrame({'key':list('abcdfeg'),
'data1':range(7)})
df1['data1'].describe()
对于非数值型数据,describe会产生另外一种汇总统计
案例:
obj = Series(['a','a','b','c'] * 4)
obj.describe()
obj.describe()['count']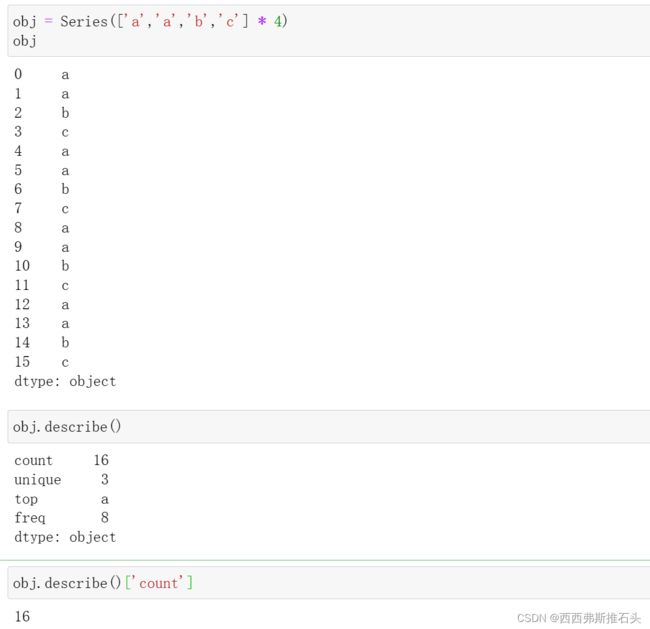
1.4描述和汇总统计的常用方法


2相关系数和协方差
Series的corr方法用于计算两个Series中重叠的、非NA的、按索引对齐的值的相关系数
与此类似,cov用于计算协方差。
DataFrame的corr和cov方法将以DataFrame的形式返回完整的相关系数或协方差矩阵:

利用DataFrame的corrwith方法,可以计算其列或行跟另一个Series或DataFrame之间的相关系数。传入一个Series将会返回一个相关系数值Series (针对各列进行计算):

3唯一值、值计数以及成员资格
3.1唯一值
函数是unique,它可以得到Series中的唯一值数组:

返回的唯一值是未排序的,如果需要的话,可以对结果再次进行排序
3.2值计数
value_counts用于计算一个Series中各值出现的频率:
结果Series是按值频率降序排列的(值作为行索引)。
value_counts还是一个顶级pandas方法,可用于任何数组或序列:

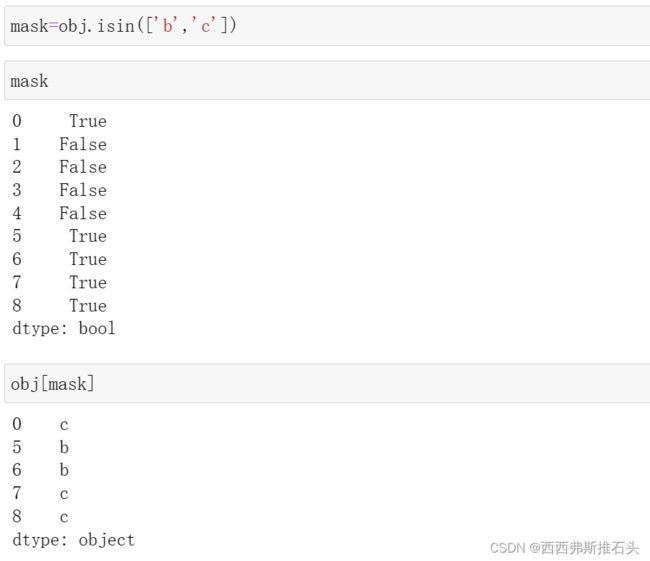
3.3成员资格
isin,它用于判断矢量化集合的成员资格,可用于选取 Series中或DataFrame列中数据的子集: