《Python机器学习实践指南》——1.2 Python库和功能
本节书摘来异步社区《Python机器学习实践指南》一书中的第1章,第1.2节,作者: 【美】Alexander T. Combs,更多章节内容可以访问云栖社区“异步社区”公众号查看。
1.2 Python库和功能
现在,我们已经对数据科学工作流的每一步有了初步的理解,下面来看看在每一步中,存在哪些有用的Python库和功能可供选择。
1.2.1 获取
访问数据常见的方式之一是通过REST风格的API接口,需要知道的库是Python Request库。它被称为给人类使用的HTTP,为API的交互提供了一个整洁和简单的方式。
让我们来看一个使用Requests进行交互的例子,它从GitHub的API中拉取数据。在这里,我们将对该API进行调用,并请求某个用户的starred库列表。
import requests
r = requests.get(r"https://api.github.com/users/acombs/starred")
r.json() ```
这个请求将以JSON文档的形式,返回用户已经标记为starred的所有存储库以及它们的属性。图1-2是上述调用后输出结果的一个片段。
 Requests库有数量惊人的特性——这里无法全部涵盖,我建议你看看上面提供的链接所指向的文档。
####1.2.2 检查
由于数据检查是机器学习应用开发中关键的一步,我们现在来深入了解几个库,它们将在此项任务中很好地为我们服务。
1.Jupyter记事本
许多库有助于减轻数据检查过程的工作负荷。首先是带有IPython(``http://ipython.org/``)的Jupyter记事本。这是一个全面的、交互式的计算环境,对于数据探索是非常理想的选择。和大多数开发环境不同,Jupyter记事本是一个基于Web的前端(相对于IPython的内核而言),被分成单个的代码块或单元。根据需要,单元可以单独运行,也可以一次全部运行。这使得开发人员能够运行某个场景,看到输出结果,然后回到代码,做出调整,再看看所产生的变化——所有这些都无需离开记事本。图1-3是在Jupyter记事本中进行交互的样例。
Requests库有数量惊人的特性——这里无法全部涵盖,我建议你看看上面提供的链接所指向的文档。
####1.2.2 检查
由于数据检查是机器学习应用开发中关键的一步,我们现在来深入了解几个库,它们将在此项任务中很好地为我们服务。
1.Jupyter记事本
许多库有助于减轻数据检查过程的工作负荷。首先是带有IPython(``http://ipython.org/``)的Jupyter记事本。这是一个全面的、交互式的计算环境,对于数据探索是非常理想的选择。和大多数开发环境不同,Jupyter记事本是一个基于Web的前端(相对于IPython的内核而言),被分成单个的代码块或单元。根据需要,单元可以单独运行,也可以一次全部运行。这使得开发人员能够运行某个场景,看到输出结果,然后回到代码,做出调整,再看看所产生的变化——所有这些都无需离开记事本。图1-3是在Jupyter记事本中进行交互的样例。
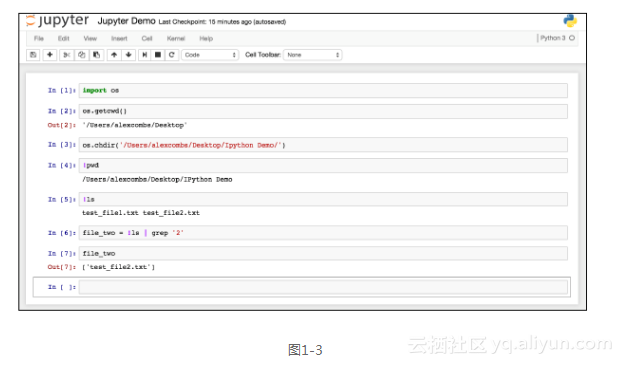 请注意,我们在这里做了一系列的事情,并不仅仅是和IPython的后端进行交互,而且也和终端shell进行了交互。这个特定的实例运行了Python 3.5的内核,但如果你愿意,也可以很容易地运行Python 2.X的内核。在这里,我们已经引入了Python os库,并进行了一次调用,找到当前的工作目录(单元#2),你可以看到输入代码单元格下方的输出。然后,我们在单元#3中使用os库改变了这个目录,但是在单元#4中停止使用os库,而是开始使用基于Linux的命令。这是通过在单元前添加!符号来完成的。在单元#6中可以看到,我们甚至能够将shell的输出保存到一个Python变量(file_two)。这是一个很棒的功能,使文件操作变成了一项简单的任务。
现在,让我们来看看使用该记事本所进行的一些简单的数据操作。这也是我们首次介绍另一个不可或缺的库:pandas。
####2.Pandas
Pandas是一个卓越的数据分析工具。根据Pandas的文档(``http://pandas.pydata.org/pandas-docs/version/0.17.1/``):
它有一个更广泛的目标,就是成为任何语言中,最强大和灵活的开源数据分析/操作工具。
即使它还没有达到这个目标,也不会差得太远。现在让我们来看看。
请注意,我们在这里做了一系列的事情,并不仅仅是和IPython的后端进行交互,而且也和终端shell进行了交互。这个特定的实例运行了Python 3.5的内核,但如果你愿意,也可以很容易地运行Python 2.X的内核。在这里,我们已经引入了Python os库,并进行了一次调用,找到当前的工作目录(单元#2),你可以看到输入代码单元格下方的输出。然后,我们在单元#3中使用os库改变了这个目录,但是在单元#4中停止使用os库,而是开始使用基于Linux的命令。这是通过在单元前添加!符号来完成的。在单元#6中可以看到,我们甚至能够将shell的输出保存到一个Python变量(file_two)。这是一个很棒的功能,使文件操作变成了一项简单的任务。
现在,让我们来看看使用该记事本所进行的一些简单的数据操作。这也是我们首次介绍另一个不可或缺的库:pandas。
####2.Pandas
Pandas是一个卓越的数据分析工具。根据Pandas的文档(``http://pandas.pydata.org/pandas-docs/version/0.17.1/``):
它有一个更广泛的目标,就是成为任何语言中,最强大和灵活的开源数据分析/操作工具。
即使它还没有达到这个目标,也不会差得太远。现在让我们来看看。import os
import pandas as pd
import requests
PATH = r'/Users/alexcombs/Desktop/iris/'
r=
requests.get('https://archive.ics.uci.edu/ml/machine-learning-databases/iri
s/iris.data')
with open(PATH + 'iris.data', 'w') as f:
f.write(r.text)
os.chdir(PATH)
df = pd.read_csv(PATH + 'iris.data', names=['sepal length', 'sepal width',
'petal length', 'petal width', 'class'])
df.head() `
前面的代码和屏幕截图如图1-4所示,我们已经从下载了一个经典的机器学习数据集:iris.data,并将其写入iris目录。这实际上是一个CSV文件,通过Pandas,我们进行了一个调用并读取了该文件。我们还增加了列名,因为这个特定的文件缺一个标题行。如果该文件已经包含了一个标题行,Pandas会自动解析并反映这一点。和其他CSV库相比,Pandas将其变为一个简单的操作。

解析文件只是该库的一个小功能。对适合于单台机器的数据集而言,Pandas是个终极的工具,这有点像Excel。就像流行的电子表格程序,操作的基本单位是表格形式的数据列和行。在Pandas的术语中,数据列称为系列(Series),而表格称为数据框(DateFrame)。
使用之前截屏中同样的iris数据框,让我们来看看几个常见的操作。
df['sepal length'] ```
前面的代码生成图1-5的输出。
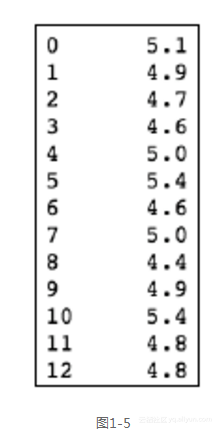 第一个操作是通过列名,从数据框中选择某一列。执行数据切片的另一种方式是使用.ix[row,column]标注。让我们使用下面这个标注,来选择前两列和前四行。
第一个操作是通过列名,从数据框中选择某一列。执行数据切片的另一种方式是使用.ix[row,column]标注。让我们使用下面这个标注,来选择前两列和前四行。 df.ix[:3, :2]`
前面的代码生成图1-6的输出。
使用.ix标注和Python列表切片的语法,我们能够选择该数据框中的一小片。现在,让我们更进一步,使用列表迭代器并只选择描述width的列。
df.ix[:3, [x for x in df.columns if 'width' in x]] ```
前面的代码生成图1-7所示的输出。
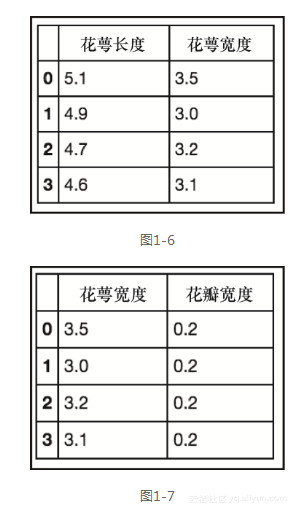 我们在这里所做的是创建一个列表,该列表是所有列的一个子集。前面的df.columns返回所有列的列表,而我们的迭代使用了一个条件查询,只选择标题中含有width字样的列。显然,在这种情况下,我们可以很容易地拼写出希望在列表中出现的列,但是这里展示了处理大规模数据集时该库所具有的能力。
我们已经看到了,如何基于其在数据框中的位置,来选择数据的分片,现在来看看另一种选择数据的方法。这次,我们将根据某些特定的条件,来选择数据的一个子集。我们首先列出所有可用的唯一类,然后选择其中之一。
我们在这里所做的是创建一个列表,该列表是所有列的一个子集。前面的df.columns返回所有列的列表,而我们的迭代使用了一个条件查询,只选择标题中含有width字样的列。显然,在这种情况下,我们可以很容易地拼写出希望在列表中出现的列,但是这里展示了处理大规模数据集时该库所具有的能力。
我们已经看到了,如何基于其在数据框中的位置,来选择数据的分片,现在来看看另一种选择数据的方法。这次,我们将根据某些特定的条件,来选择数据的一个子集。我们首先列出所有可用的唯一类,然后选择其中之一。 df['class'].unique()`
前面的代码生成图1-8的输出。

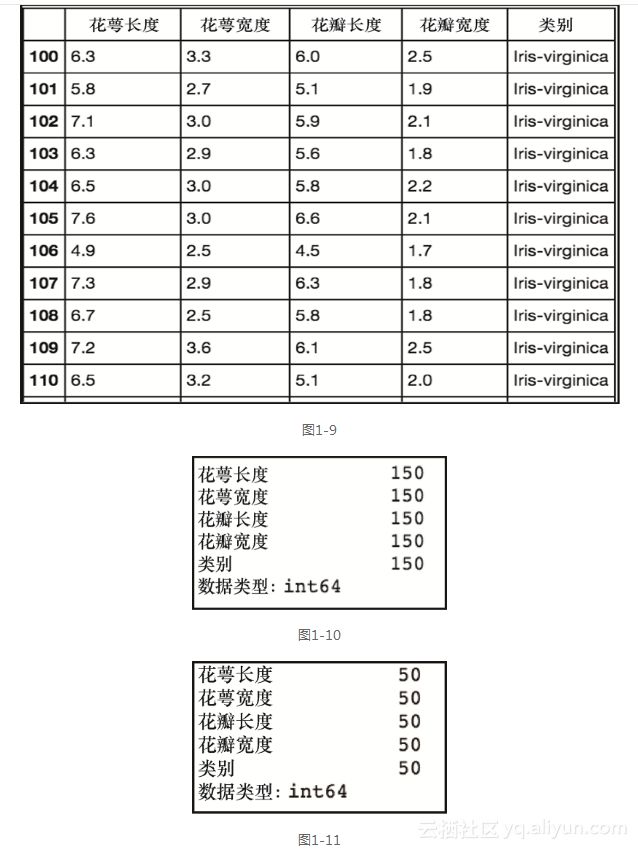
df[df['class']=='Iris-virginica']```
在图1-9所示最右侧的一列中,我们可以看到数据框只包含Iris-virginica类的数据。事实上,选择之后图1-11中数据框的大小是50行,比图1-10中原来的150行要小一些。df.count()
df[df['class']=='Iris-virginica'].count() `
我们还可以看到,在左侧的索引保留了原始行号。现在,可以将这些数据保存为一个新的数据框并重置索引,如下面的代码和截图1-12所示。
virginica = df[df['class']=='Iris-virginica'].reset_index(drop=True)
virginica ```
 我们通过在某个列上放置条件来选择数据,现在来添加更多的条件。我们将回到初始的数据框,并使用两个条件选择数据。
我们通过在某个列上放置条件来选择数据,现在来添加更多的条件。我们将回到初始的数据框,并使用两个条件选择数据。df[(df['class']=='Iris-virginica')&(df['petal width']>2.2)]`
上述代码生成图1-13的输出。
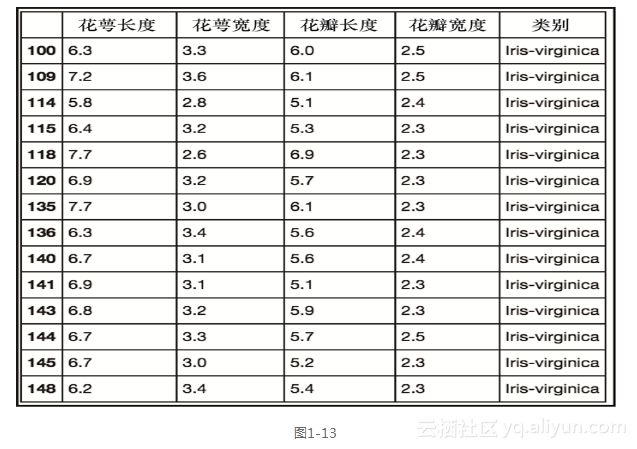
数据框现在只包含来自Iris-virginica类、而且花瓣宽度大于2.2的数据。
现在,让我们使用Pandas,从虹膜数据集中获取一些快速的描述性统计数据。
df.describe() ```
上述代码生成图1-14的输出。
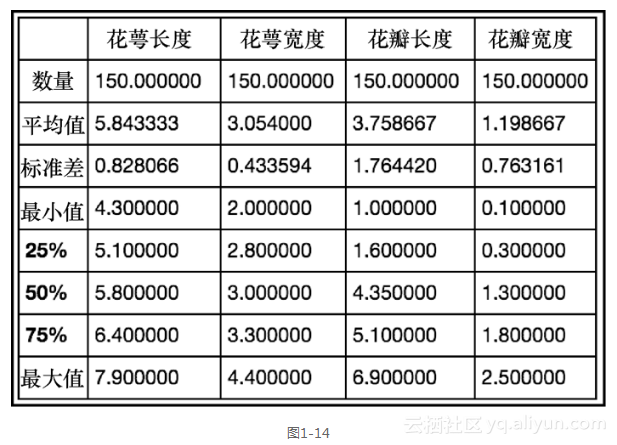 随着数据框的.describe()方法被调用,我们收到了各相关列的描述性统计信息(请注意,类别信息被自动删除了,因为它在这里是不相关的)。如果想要更为详细的信息,还可以传入自定义的百分比。
随着数据框的.describe()方法被调用,我们收到了各相关列的描述性统计信息(请注意,类别信息被自动删除了,因为它在这里是不相关的)。如果想要更为详细的信息,还可以传入自定义的百分比。df.describe(percentiles=[.20,.40,.80,.90,.95])`
上述代码生成图1-15的输出。

接下来,让我们检查这些特征之间是否有任何相关性。这可以通过在数据框上调用.corr()来完成。
df.corr() ```
上述代码生成图1-16的输出。
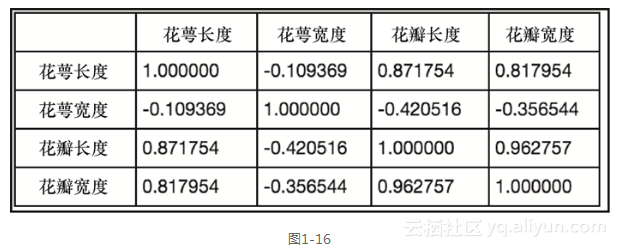 默认地,系统返回每个行-列对中的Pearson相关系数。通过传递方法的参数,还可以切换到Kendall's tau或Spearman's秩相关系数``(例如,.corr(method="spearman")或.corr(method="kendall"))``。
3.可视化
目前为止,我们已经看到如何选择数据框的某一部分,并从数据中获取汇总的统计信息,现在让我们学习如何通过可视化的方式来观测数据。不过首先要回答的问题是,为什么要花费心思进行可视化的视察呢?来看一个例子就能明白这是为什么了。
表1-1展示了四组不同序列的x值和y值的汇总统计。
默认地,系统返回每个行-列对中的Pearson相关系数。通过传递方法的参数,还可以切换到Kendall's tau或Spearman's秩相关系数``(例如,.corr(method="spearman")或.corr(method="kendall"))``。
3.可视化
目前为止,我们已经看到如何选择数据框的某一部分,并从数据中获取汇总的统计信息,现在让我们学习如何通过可视化的方式来观测数据。不过首先要回答的问题是,为什么要花费心思进行可视化的视察呢?来看一个例子就能明白这是为什么了。
表1-1展示了四组不同序列的x值和y值的汇总统计。
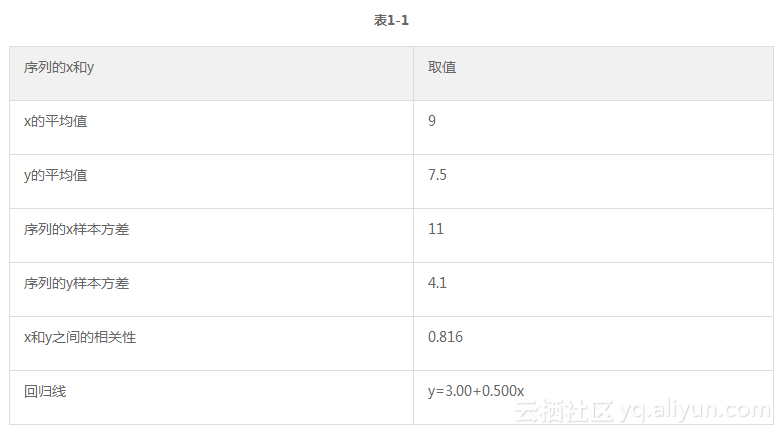 基于四组序列拥有相同的汇总统计,我们可能会认为这些系列的可视化看上去也是相似。我们当然是错误的,非常错误。这四个序列是安斯库姆四重奏的一部分,他们被刻意制造出来用于说明可视化数据检查的重要性。每个序列绘制在图1-17中。
显然,经过可视化的观察之后,我们不再会认为这些数据集是相同的。所以,现在我们能理解可视化的重要性了,下面来看看一对用于可视化的、很有价值的Python库。
基于四组序列拥有相同的汇总统计,我们可能会认为这些系列的可视化看上去也是相似。我们当然是错误的,非常错误。这四个序列是安斯库姆四重奏的一部分,他们被刻意制造出来用于说明可视化数据检查的重要性。每个序列绘制在图1-17中。
显然,经过可视化的观察之后,我们不再会认为这些数据集是相同的。所以,现在我们能理解可视化的重要性了,下面来看看一对用于可视化的、很有价值的Python库。
 Matplotlib库
我们将要看到的第一个库是matplotlib。这是Python绘图库的鼻祖了。最初人们创建它是为了仿效MATLAB的绘图功能,现在它自己已经发展成为特性完善的库了,并拥有超多的功能。对于那些没有MATLAB背景的使用者,可能很难理解所有这些部件是如何共同协作来创造图表的。
我们将所有的部件拆分为多个逻辑模块,便于大家理解都发生了些什么。在深入理解matplotlib之前,让我们先设置Jupyter记事本,以便看清每个图像。要做到这一点,需要将以下几行添加到import声明中。
Matplotlib库
我们将要看到的第一个库是matplotlib。这是Python绘图库的鼻祖了。最初人们创建它是为了仿效MATLAB的绘图功能,现在它自己已经发展成为特性完善的库了,并拥有超多的功能。对于那些没有MATLAB背景的使用者,可能很难理解所有这些部件是如何共同协作来创造图表的。
我们将所有的部件拆分为多个逻辑模块,便于大家理解都发生了些什么。在深入理解matplotlib之前,让我们先设置Jupyter记事本,以便看清每个图像。要做到这一点,需要将以下几行添加到import声明中。import matplotlib.pyplot as plt
plt.style.use('ggplot')
%matplotlib inline
import numpy as np`
第一行引入了matplotlib,第二行将风格设置为近似R中的ggplot库(这需要matplotlib 1.41),第三行设置插图,让它们在记事本中可见,而最后一行引入了numpy。本章稍后,我们将在一些操作中使用numpy。
现在,让我们使用下面的代码,在鸢尾花Iris数据集上生成第一个图:
fig, ax = plt.subplots(figsize=(6,4))
ax.hist(df['petal width'], color='black');
ax.set_ylabel('Count', fontsize=12)
ax.set_xlabel('Width', fontsize=12)
plt.title('Iris Petal Width', fontsize=14, y=1.01)```
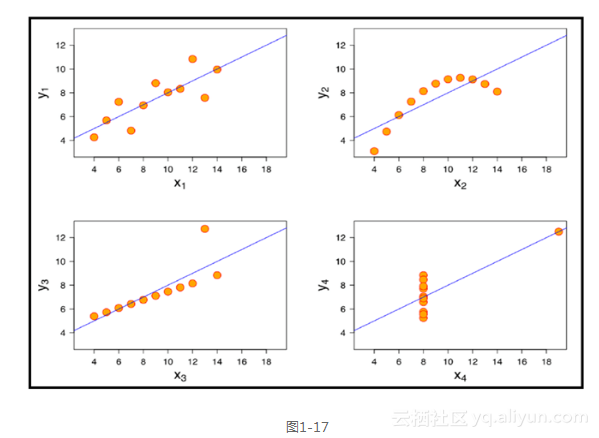
前面的代码生成图1-18中的输出。
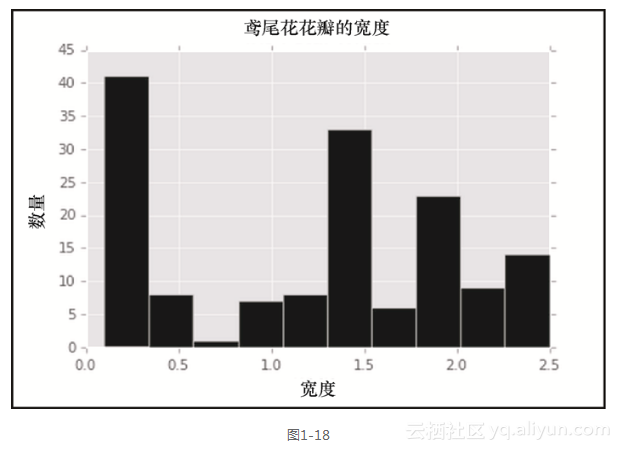 即使是在这个简单的例子中,也发生了很多事情,让我们来逐行分析。第一行创建了宽度为6英寸和高度为4英寸的一个插图。然后,我们通过调用.hist()并传入数据,依照iris数据框绘制了花瓣宽度的直方图。这里还将直方图中柱子的颜色设置为black(黑色)。接下来的两行分别在y轴和x轴上放置标签,最后一行为全图设置了标题。其中使用y轴的参数调整了标题在y轴方向相对于图片顶部的位置,并微微增加了默认字体的大小。这使得我们从花瓣宽度的数据得到了一个很漂亮的直方图。现在,让我们进一步扩展,为iris数据集的每一列生成直方图。
即使是在这个简单的例子中,也发生了很多事情,让我们来逐行分析。第一行创建了宽度为6英寸和高度为4英寸的一个插图。然后,我们通过调用.hist()并传入数据,依照iris数据框绘制了花瓣宽度的直方图。这里还将直方图中柱子的颜色设置为black(黑色)。接下来的两行分别在y轴和x轴上放置标签,最后一行为全图设置了标题。其中使用y轴的参数调整了标题在y轴方向相对于图片顶部的位置,并微微增加了默认字体的大小。这使得我们从花瓣宽度的数据得到了一个很漂亮的直方图。现在,让我们进一步扩展,为iris数据集的每一列生成直方图。fig, ax = plt.subplots(2,2, figsize=(6,4))
ax0.hist(df['petal width'], color='black');
ax0.set_ylabel('Count', fontsize=12)
ax0.set_xlabel('Width', fontsize=12)
ax0.set_title('Iris Petal Width', fontsize=14, y=1.01)
ax0.hist(df['petal length'], color='black');
ax0.set_ylabel('Count', fontsize=12)
ax0.set_xlabel('Lenth', fontsize=12)
ax0.set_title('Iris Petal Lenth', fontsize=14, y=1.01)
ax1.hist(df['sepal width'], color='black');
ax1.set_ylabel('Count', fontsize=12)
ax1.set_xlabel('Width', fontsize=12)
ax1.set_title('Iris Sepal Width', fontsize=14, y=1.01)
ax1.hist(df['sepal length'], color='black');
ax1.set_ylabel('Count', fontsize=12)
ax1.set_xlabel('Length', fontsize=12)
ax1.set_title('Iris Sepal Length', fontsize=14, y=1.01)
plt.tight_layout()`
上述代码的输出显示如图1-19所示。

显然,这不是最有效的编码方法,但是对于展示matplotlib是如何工作的很有用处。请注意,我们现在是通过ax数组来绘制四个子插图,而不是之前例子中的单一子插图对象ax。新增加的代码是调用plt.tight_layout(),该方法将很好地自动调整子插图,以避免排版上显得过于拥挤。
现在来看看matplotlib所提供的一些其他类型的画图模式。一个有用的类型是散点图。这里,我们将在x轴和y轴分布绘画花瓣宽度和花瓣长度。
fig, ax = plt.subplots(figsize=(6,6))
ax.scatter(df['petal width'],df['petal length'], color='green')
ax.set_xlabel('Petal Width')
ax.set_ylabel('Petal Length')
ax.set_title('Petal Scatterplot')```
上述的代码生成了图1-20所示的输出。
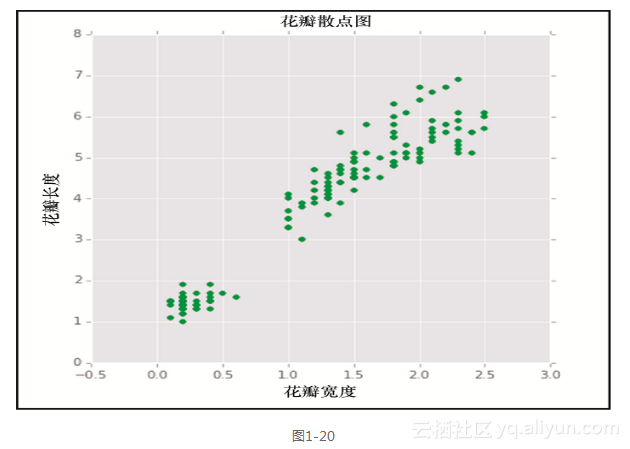 如前所述,我们可以添加多个子插图,来检视每个方面。
我们可以考察的另一种类型是简单的线图。这里来看看花瓣长度的插图。
如前所述,我们可以添加多个子插图,来检视每个方面。
我们可以考察的另一种类型是简单的线图。这里来看看花瓣长度的插图。fig, ax = plt.subplots(figsize=(6,6))
ax.plot(df['petal length'], color='blue')
ax.set_xlabel('Specimen Number')
ax.set_ylabel('Petal Length')
ax.set_title('Petal Length Plot')`
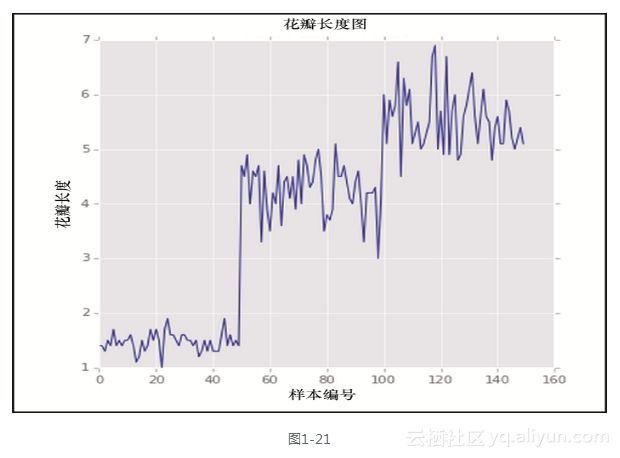
上述的代码生成了图1-21所示的输出。
基于这个简单的线图,我们已经可以看到对于每个类别存在鲜明的长度差别——请记住样本数据集在每个类别拥有50个排序的样例。这就告诉我们,花瓣长度很可能是用于区分类别的一个有用特征。
让我们来看看matplotlib库中最后一个类型的图表:条形图。这也许是最为常见的图表之一。这里将使用三类鸢尾花中每个特征的平均值绘制一个条形图,而且为了让其更有趣,我们将使用堆积条形图,它附带了若干新的matplotlib特性。
fig, ax = plt.subplots(figsize=(6,6))
bar_width = .8
labels = [x for x in df.columns if 'length' in x or 'width' in x]
ver_y = [df[df['class']=='Iris-versicolor'][x].mean() for x in labels]
vir_y = [df[df['class']=='Iris-virginica'][x].mean() for x in labels]
set_y = [df[df['class']=='Iris-setosa'][x].mean() for x in labels]
x = np.arange(len(labels))
ax.bar(x, vir_y, bar_width, bottom=set_y, color='darkgrey')
ax.bar(x, set_y, bar_width, bottom=ver_y, color='white')
ax.bar(x, ver_y, bar_width, color='black')
ax.set_xticks(x + (bar_width/2))
ax.set_xticklabels(labels, rotation=-70, fontsize=12);
ax.set_title('Mean Feature Measurement By Class', y=1.01)
ax.legend(['Virginica','Setosa','Versicolor'])```
上述的代码生成图1-22所示的输出。
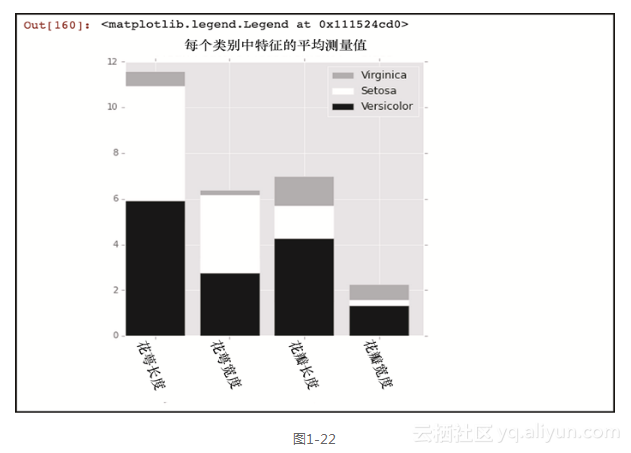 为了生成条形图,我们需要将x和y的值传递给.bar()方法。在这种情况下,x值将只是我们感兴趣的特征的长度的数组,在这个例子中是4,或者是数据框中列的数量。函数np.arange()是产生这个数值的简单方法,但也可以轻松地手动输入这个数组。由于我们不想在x轴显示1到4,因此调用了.set_xticklabels()方法并传入想要显示的列名。为了让x轴的标签对齐,我们还需要调整标签之间的间隔。这就是为什么将xticks设置为x加上bar_width值的一半,而我们先前已经将bar_width设置为0.8。这里y值来自每个类别中特征的平均值。然后,通过调用.bar()绘制每个插图。需要注意的是,我们为每个序列传入一个bottom参数,这个参数将该序列的y点最小值设置为其下面那个序列的y点最大值。这就能创建堆积条形图。最后,添加了一个图例来描述每个序列。按照从顶部到底部条形放置的顺序,我们依次在图例中插入了相应的名称。
Seaborn库
我们接下来将看到的可视化库被称为seaborn()。它是专门为统计可视化而创建的库。事实上,seaborn可以和pandas数据框完美地协作,框中的列是特征而行是观测的样例。这种数据框的风格被称为整洁的数据,而且它是机器学习应用中最常见的形式。
现在让我们来看看seaborn的能力。
为了生成条形图,我们需要将x和y的值传递给.bar()方法。在这种情况下,x值将只是我们感兴趣的特征的长度的数组,在这个例子中是4,或者是数据框中列的数量。函数np.arange()是产生这个数值的简单方法,但也可以轻松地手动输入这个数组。由于我们不想在x轴显示1到4,因此调用了.set_xticklabels()方法并传入想要显示的列名。为了让x轴的标签对齐,我们还需要调整标签之间的间隔。这就是为什么将xticks设置为x加上bar_width值的一半,而我们先前已经将bar_width设置为0.8。这里y值来自每个类别中特征的平均值。然后,通过调用.bar()绘制每个插图。需要注意的是,我们为每个序列传入一个bottom参数,这个参数将该序列的y点最小值设置为其下面那个序列的y点最大值。这就能创建堆积条形图。最后,添加了一个图例来描述每个序列。按照从顶部到底部条形放置的顺序,我们依次在图例中插入了相应的名称。
Seaborn库
我们接下来将看到的可视化库被称为seaborn()。它是专门为统计可视化而创建的库。事实上,seaborn可以和pandas数据框完美地协作,框中的列是特征而行是观测的样例。这种数据框的风格被称为整洁的数据,而且它是机器学习应用中最常见的形式。
现在让我们来看看seaborn的能力。import seaborn as sns
sns.pairplot(df, hue="class")`
仅仅通过这两行代码,我们就可以得到图1-23所示的输出。
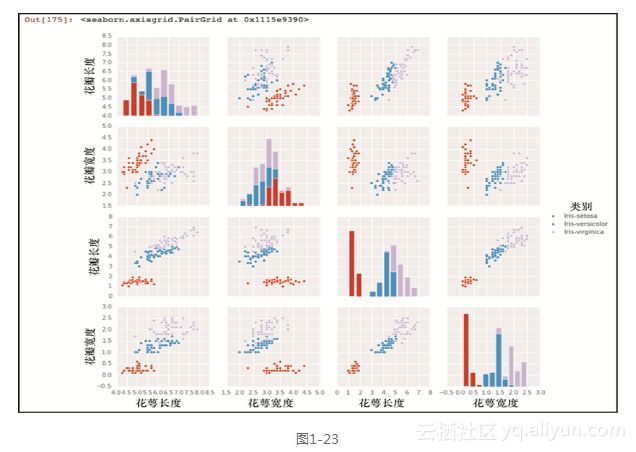
就在刚刚我们详细地讨论了matplotlib错综复杂的细微之处,而生成这张图的简单性却显而易见。仅仅使用了两行代码,所有的特征都已经被绘画出来,彼此对照并标上了正确的标签。那么,当seaborn使得这种可视化变得如此简单的时候,学习matplotlib是在浪费时间吗?幸运的是,情况并非如此,seaborn是建立在matplotlib之上的。事实上,我们可以使用所学的matplotlib知识来修改并使用seaborn。让我们来看看另一个可视化的例子。
fig, ax = plt.subplots(2, 2, figsize=(7, 7))
sns.set(style='white', palette='muted')
sns.violinplot(x=df['class'], y=df['sepal length'], ax=ax[0,0])
sns.violinplot(x=df['class'], y=df['sepal width'], ax=ax[0,1])
sns.violinplot(x=df['class'], y=df['petal length'], ax=ax[1,0])
sns.violinplot(x=df['class'], y=df['petal width'], ax=ax[1,1])
fig.suptitle('Violin Plots', fontsize=16, y=1.03)
for i in ax.flat:
plt.setp(i.get_xticklabels(), rotation=-90)
fig.tight_layout()```
以上代码行生成图1-24所示的输出。
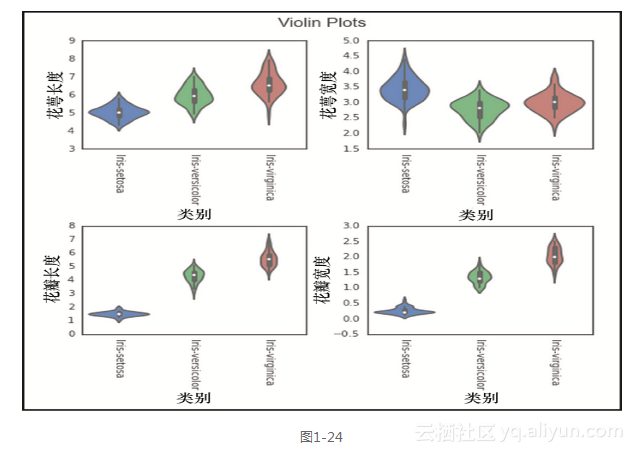 这里,我们为4个特征分别生成了小提琴图。小提琴图显示了特征的分布情况。例如,我们可以很容易地看到类别irissetosa的花瓣长度高度聚集在1~2厘米之间,而类别iris-virginica分散在4~7厘米之间。我们还可以看到,之前在构建matplotlib图形时使用了许多相同的代码。这里主要的区别在于加入了sns.plot()调用来取代之前的ax.plot()调用 。我们还使用了fig.suptitle()方法,在所有的子图上添加了一个总标题,而不是在每个单独的子图上各自添加标题。另一个明显的添加部分,是每个子图的遍历取代了之前xticklabels的轮换。我们调用ax.flat(),遍历每个子图的轴,并使用.setp()设置特定的属性。这可以让我们不再需要像之前matplotlib子图代码那样,单独地敲打ax[0][0]…ax[1][1],并设置属性。
我们在这里使用的图是一个很好的开始,但是你可以使用matplotlib和seaborn创建上百种不同风格的图形。我强烈建议深入研究这两个库的文档,这将是非常值得的。
####1.2.3 准备
我们已经学到了很多有关检查数据的内容,现在让我们开始学习如何处理和操作数据。这里你将了解 pandas的Series.map()、Series.apply()、DataFrame.apply()、DataFrame.applymap()和 DataFrame.groupby()方法。这些对于处理数据而言是非常有价值的,而且在特征工程的机器学习场景下特别有用,我们将在后面的章节详细地讨论这个概念。
1.Map
Map方法适用于序列数据,所以在我们的例子中将用它来转变数据框的某个列,它就是一个pandas的序列 。假设我们觉得类别的名字太长了,并且希望使用特殊的3字母代码系统对其进行编码。为了实现这点,我们将使用map方法并将一个Python字典作为其参数。这里将为每个单独的鸢尾花类型传入替换的文本。
这里,我们为4个特征分别生成了小提琴图。小提琴图显示了特征的分布情况。例如,我们可以很容易地看到类别irissetosa的花瓣长度高度聚集在1~2厘米之间,而类别iris-virginica分散在4~7厘米之间。我们还可以看到,之前在构建matplotlib图形时使用了许多相同的代码。这里主要的区别在于加入了sns.plot()调用来取代之前的ax.plot()调用 。我们还使用了fig.suptitle()方法,在所有的子图上添加了一个总标题,而不是在每个单独的子图上各自添加标题。另一个明显的添加部分,是每个子图的遍历取代了之前xticklabels的轮换。我们调用ax.flat(),遍历每个子图的轴,并使用.setp()设置特定的属性。这可以让我们不再需要像之前matplotlib子图代码那样,单独地敲打ax[0][0]…ax[1][1],并设置属性。
我们在这里使用的图是一个很好的开始,但是你可以使用matplotlib和seaborn创建上百种不同风格的图形。我强烈建议深入研究这两个库的文档,这将是非常值得的。
####1.2.3 准备
我们已经学到了很多有关检查数据的内容,现在让我们开始学习如何处理和操作数据。这里你将了解 pandas的Series.map()、Series.apply()、DataFrame.apply()、DataFrame.applymap()和 DataFrame.groupby()方法。这些对于处理数据而言是非常有价值的,而且在特征工程的机器学习场景下特别有用,我们将在后面的章节详细地讨论这个概念。
1.Map
Map方法适用于序列数据,所以在我们的例子中将用它来转变数据框的某个列,它就是一个pandas的序列 。假设我们觉得类别的名字太长了,并且希望使用特殊的3字母代码系统对其进行编码。为了实现这点,我们将使用map方法并将一个Python字典作为其参数。这里将为每个单独的鸢尾花类型传入替换的文本。df['class'] = df['class'].map({'Iris-setosa': 'SET', 'Iris-virginica':
'VIR', 'Iris-versicolor': 'VER'})
df`
前面的代码生成图1-25的输出。
下面来看看这里做了些什么。我们在现有class列的每个值上运行了map的方法。由于每个值都能在Python字典中找到,所以它会被添加到被返回的序列。我们为返回序列赋予了相同的class名,所以它替换了原有的class列。如果我们选择了一个不同的名字,例如short class,那么这一列会被追加到数据框,然后我们将有初始的class列外加新的short class列。
我们还可以向map方法传入另一个序列或函数,来执行对某个列的转变,但这个功能在apply 方法也是可用的,下面这节会讨论该方法。字典的功能是map方法所独有的,这也是选择map而不是apply进行单列转变的最常见原因。现在让我们来看看apply方法。
2.Apply
Apply的方法让我们既可以在数据框上工作,也可以在序列上工作。我们将从一个也能使用map的例子开始,然后再讨论只能使用apply的示例。
继续使用iris数据框,让我们根据花瓣的宽度来创建新的列。之前我们看到花瓣宽度的平均值为1.3。现在,在数据框中创建一个新的列——宽花瓣,它包含一个基于petal width列的二进制值。如果花瓣宽度等于或宽于中值,那么我们将其编码为1,而如果它小于中值,我们将其编码为0。为了实现这点,这里将在petal width这列使用apply方法。
df['wide petal'] = df['petal width'].apply(lambda v: 1 if v >= 1.3 else 0)
df ```
前面的代码生成图1-26所示的输出。
 这里发生了几件事情,让我们一步一步来看。首先,我们为所要创建的列名简单地使用了列选择的语法,向数据框追加一个新的列,在这个例子中是wide petal。我们将这个新列设置为apply方法的输出。这里在petal width列上运行apply,并返回了wide petal列的相应值。Apply方法作用于petal width列的每个值。如果该值大于或等于1.3,函数返回1;否则,返回0。这种类型的转换在机器学习领域是相当普遍的特征工程转变,所以最好熟悉如何执行它。
现在让我们来看看如何在数据框上使用apply,而不是在一个单独的序列上。现在将基于petal area来创建一个新的特征。
这里发生了几件事情,让我们一步一步来看。首先,我们为所要创建的列名简单地使用了列选择的语法,向数据框追加一个新的列,在这个例子中是wide petal。我们将这个新列设置为apply方法的输出。这里在petal width列上运行apply,并返回了wide petal列的相应值。Apply方法作用于petal width列的每个值。如果该值大于或等于1.3,函数返回1;否则,返回0。这种类型的转换在机器学习领域是相当普遍的特征工程转变,所以最好熟悉如何执行它。
现在让我们来看看如何在数据框上使用apply,而不是在一个单独的序列上。现在将基于petal area来创建一个新的特征。df['petal area'] = df.apply(lambda r: r['petal length'] * r['petal width'],
axis=1)
df `
前面的代码生成图1-27的输出。
请注意,这里不是在一个序列上调用apply,而是在整个数据框上。此外正是由于在整个数据框上调用了apply,我们传送了axis=1的参数来告诉pandas,我们要对行运用函数。如果传入了axis=0,那么该函数将对列进行操作。这里,每列都是被顺序地处理,我们选择将petal length的值和petal width的值相乘。得到的序列就将成为数据框中的petal area列。这种能力和灵活性使得pandas成为了数据操作不可或缺的工具。
3.Applymap
我们已经学习了列的操作,并解释了如何在行上运作,不过,假设你想对数据框里所有的数据单元执行一个函数,那又该怎么办呢?这时applymap就是合适的工具了。这里看一个例子。
df.applymap(lambda v: np.log(v) if isinstance(v, float) else v) ```
前面的代码生成图1-28的输出。
 在这里,我们在数据框上调用了applymap,如果某个值是float类型的的实例,那么就会获得该值的对数(np.log()利用numpy库返回该值)。这种类型的检查,可以防止系统返回一个错误信息,或者是为字符串型的class列或整数形的wide petal列返回浮动值。Applymap的常见用法是根据一定的条件标准来转变或格式化每一个单元。
4.Groupby
现在,让我们来看一个非常有用,但对于新pandas用户往往难以理解的操作——数据框.groupby()方法。我们将逐步分析若干例子,来展示这个最为重要的功能。
这个groupby操作就如其名——它基于某些你所选择的类别对数据进行分组。让我们使用iris数据集来看一个简单的例子。这里将回到之前的步骤,重新导入最初的iris数据集,并运行第一个groupby操作。
在这里,我们在数据框上调用了applymap,如果某个值是float类型的的实例,那么就会获得该值的对数(np.log()利用numpy库返回该值)。这种类型的检查,可以防止系统返回一个错误信息,或者是为字符串型的class列或整数形的wide petal列返回浮动值。Applymap的常见用法是根据一定的条件标准来转变或格式化每一个单元。
4.Groupby
现在,让我们来看一个非常有用,但对于新pandas用户往往难以理解的操作——数据框.groupby()方法。我们将逐步分析若干例子,来展示这个最为重要的功能。
这个groupby操作就如其名——它基于某些你所选择的类别对数据进行分组。让我们使用iris数据集来看一个简单的例子。这里将回到之前的步骤,重新导入最初的iris数据集,并运行第一个groupby操作。df.groupby('class').mean()`
前面的代码生成图1-29所示的输出。
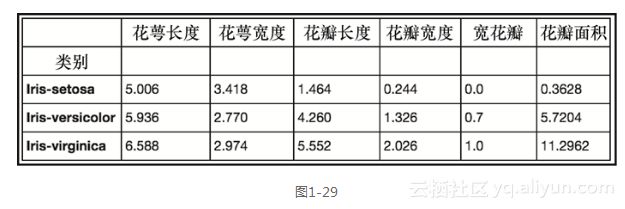
系统按照类别对数据进行了划分,并且提供了每个特征的均值。让我们现在更进一步,得到每个类别完全的描述性统计信息。
df.groupby('class').describe()```
前面的代码生成图1-30所示的输出。
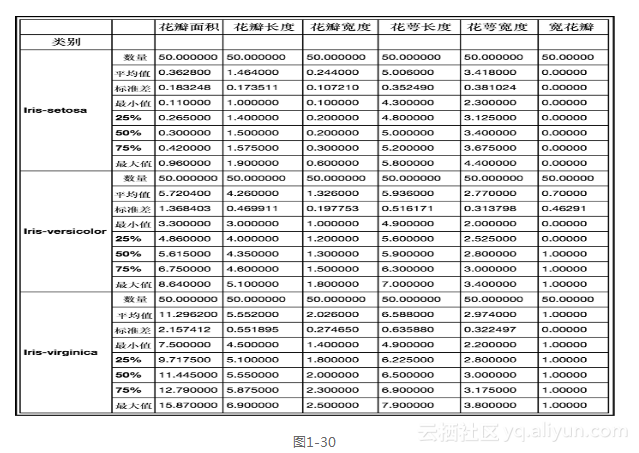 现在我们可以看到每个class完整的分解。再来看看其他一些可执行的groupby操作。之前,我们看出花瓣长度和宽度在不同类之间有一些比较明显的区别,这里让我们看看如何使用groupby来发现这一点。
现在我们可以看到每个class完整的分解。再来看看其他一些可执行的groupby操作。之前,我们看出花瓣长度和宽度在不同类之间有一些比较明显的区别,这里让我们看看如何使用groupby来发现这一点。df.groupby('petal width')['class'].unique().to_frame()`
前面的代码生成图1-31所示的输出。
在这个例子中,我们通过和每个唯一类相关联的花瓣宽度,对类别进行分组。这里测量组的数量还是可管理的,但是如果这个数量将要增大很多,那么我们很可能需要将测量分割为不同的范围。正如之前看到的,这点可以使用apply方法来完成。

现在来看一个自定义的聚集函数。
df.groupby('class')['petal width']\
.agg({'delta': lambda x: x.max() - x.min(), 'max': np.max, 'min': np.min})```
前面的代码生成图1-32所示的输出。
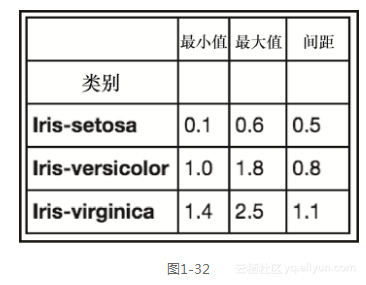 在这段代码中,我们根据类别来分组花瓣宽度的时候,使用np.max和np.min这两个函数(两个np函数来自numpy库),以及返回最大花瓣宽度减去最小花瓣宽度的lambda函数。这些都以字典的形式,传递给.agg()方法,以此返回一个将字典键值作为列名的数据框。可以仅仅运行函数本身或者传递函数的列表,不过列的名称所含信息量就更少了[1]。
我们只是刚刚接触了groupby方法的一些功能,还有很多东西要学习,所以我建议你阅读这里的文档:http://pandas.pydata.org/pandas-docs/stable/。
对于准备阶段中如何操纵和准备数据,我们现在有了扎实的基本理解,而下一步就是建模。这里即将讨论Python机器学习生态系统中最为主要的一些库。
####1.2.4 建模和评估
对于统计建模和机器学习,Python有许多很优秀的、文档详实的库供选择。下面只谈及最流行的几个库。
1.Statsmodels
我们要介绍的第一个库是statsmodels(``http://statsmodels.sourceforge.net/``)。
Statsmodels是用于探索数据、估计模型,并运行统计检验的Python包。在这里,让我们使用它来构建一个简单的线性回归模型,为setosa类中花萼长度和花萼宽度之间的关系进行建模。
首先,通过散点图来目测这两者的关系。
在这段代码中,我们根据类别来分组花瓣宽度的时候,使用np.max和np.min这两个函数(两个np函数来自numpy库),以及返回最大花瓣宽度减去最小花瓣宽度的lambda函数。这些都以字典的形式,传递给.agg()方法,以此返回一个将字典键值作为列名的数据框。可以仅仅运行函数本身或者传递函数的列表,不过列的名称所含信息量就更少了[1]。
我们只是刚刚接触了groupby方法的一些功能,还有很多东西要学习,所以我建议你阅读这里的文档:http://pandas.pydata.org/pandas-docs/stable/。
对于准备阶段中如何操纵和准备数据,我们现在有了扎实的基本理解,而下一步就是建模。这里即将讨论Python机器学习生态系统中最为主要的一些库。
####1.2.4 建模和评估
对于统计建模和机器学习,Python有许多很优秀的、文档详实的库供选择。下面只谈及最流行的几个库。
1.Statsmodels
我们要介绍的第一个库是statsmodels(``http://statsmodels.sourceforge.net/``)。
Statsmodels是用于探索数据、估计模型,并运行统计检验的Python包。在这里,让我们使用它来构建一个简单的线性回归模型,为setosa类中花萼长度和花萼宽度之间的关系进行建模。
首先,通过散点图来目测这两者的关系。fig, ax = plt.subplots(figsize=(7,7))
ax.scatter(df'sepal width', df'sepal length')
ax.set_ylabel('Sepal Length')
ax.set_xlabel('Sepal Width')
ax.set_title('Setosa Sepal Width vs. Sepal Length', fontsize=14,
y=1.02)`
前面的代码生成图1-33所示的输出。
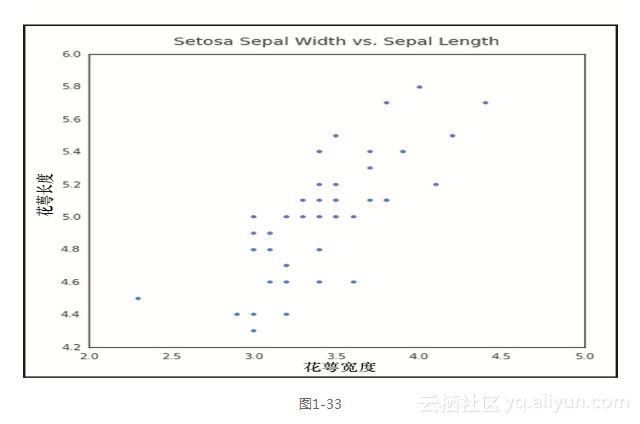
我们可以看到,似乎有一个正向的线性关系,也就是说,随着花萼宽度的增加,花萼长度也会增加。接下来我们使用statsmodels,在这个数据集上运行一个线性回归模型,来预估这种关系的强度。
import statsmodels.api as sm
y = df['sepal length'][:50]
x = df['sepal width'][:50]
X = sm.add_constant(x)
results = sm.OLS(y, X).fit()
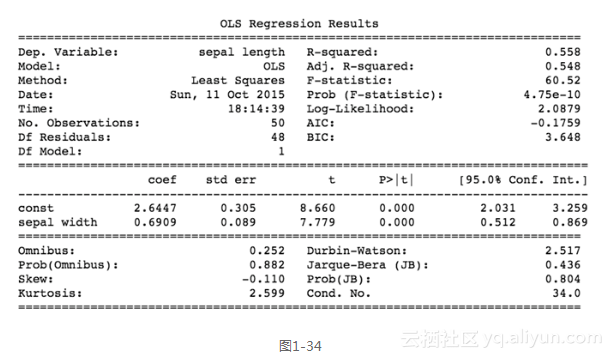
print(results.summary()) ```
前面的代码生成图1-34所示的输出。
图1-34所示的屏幕截图显示了这个简单回归模型的结果。由于这是一个线性回归,该模型的格式为Y = Β0+Β1X,其中B0为截距而B1是回归系数。在这里,最终公式是Sepal Length = 2.6447 + 0.6909 × Sepal Width。我们也可以看到,该模型的R2值是一个可以接受的0.558,而p值 (Prob)是非常显著的——至少对于这个类而言。
 现在让我们使用结果对象来绘制回归线。
现在让我们使用结果对象来绘制回归线。fig, ax = plt.subplots(figsize=(7,7))
ax.plot(x, results.fittedvalues, label='regression line')
ax.scatter(x, y, label='data point', color='r')
ax.set_ylabel('Sepal Length')
ax.set_xlabel('Sepal Width')
ax.set_title('Setosa Sepal Width vs. Sepal Length', fontsize=14,
y=1.02)
ax.legend(loc=2)`
前面的代码生成图1-35所示的输出。
通过绘制results.fittedvalues,我们可以获取从模型所得的回归线。
在statsmodels包中,还有一些其他的统计函数和测试模块,我希望你能去探索它们。对于Python中标准的统计建模而言,这是一个非常有用的包。接下来,让我们开始学习Python机器学习包中的王者:scikit-learn。
2.scikit-learn
scikit-learn是一个令人惊喜的Python库,作者们为其设计了无与伦比的文档,为几十个算法提供了统一的API接口。它建立在Python科学栈的核心模块之上,也就是NumPy、SciPy、pandas和matplotlib。scikit-learn覆盖的一些领域包括:分类、回归、聚类、降维、模型选择和预处理。

我们来看看几个例子。首先,使用iris数据建立一个分类器,然后学习如何利用scikit-learn 的工具来评估得到的模型。
在scikit-learn中打造机器学习模型的第一步,是理解数据应该如何构建。独立变量应该是一个数字型的n×m纬的矩阵X、一个因变量y和n×1维的向量。该y向量可以是连续的数字,也可以是离散的数字,还可以是离散的字符串类型。然后将这些向量传递到指定分类器的.fit()方法。这是使用scikit-learn最大的好处,每个分类器都尽最大可能地使用同样的方法。如此一来,它们的交换使用易如反掌。
让我们来看看在第一个例子中,如何实现。
from sklearn.ensemble import RandomForestClassifier
from sklearn.cross_validation import train_test_split
clf = RandomForestClassifier(max_depth=5, n_estimators=10)
X = df.ix[:,:4]
y = df.ix[:,4]
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=.3)
clf.fit(X_train,y_train)
y_pred = clf.predict(X_test)
rf = pd.DataFrame(list(zip(y_pred, y_test)), columns=['predicted',
'actual'])
rf['correct'] = rf.apply(lambda r: 1 if r['predicted'] ==
r['actual'] else 0, axis=1)
rf```
前面的代码生成图1-36的输出。
 现在,让我们来看看下面的代码。
``
rf['correct'].sum()/rf['correct'].count()``
这会生成图1-37的输出。
现在,让我们来看看下面的代码。
``
rf['correct'].sum()/rf['correct'].count()``
这会生成图1-37的输出。
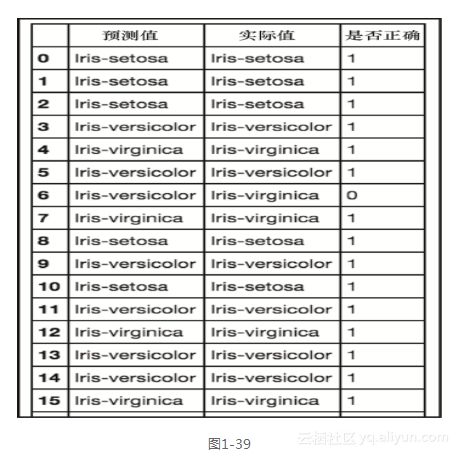
 在前面的几行代码中,我们建立、训练并测试了一个分类器,它在Iris数据集上具有95%的准确度。这里逐项分析每个步骤。在代码的前两行,我们做了几个导入,前两个是从scikit-learn,值得庆幸的是在import语句中其名字缩短为sklearn了。第一个导入的是一个随机森林分类器,第二个导入的是一个将数据分成训练组和测试组的模块。出于某些原因,这种数据切分在机器学习应用的构建中是很关键的。我们将在以后的章节讨论这些,现在只需要知道这是必需的。模块train_test_split还会打乱数据的先后顺序,这也是非常重要的,因为原有的顺序可能包含误导实际预测的信息。
在这本书中,我们将使用最新的Python版本,撰写本书的时候是版本3.5。如果你使用的Python是版本2.x,你需要添加额外的import语句,让整数的除法和Python 3.x中的一样运作。没有这一行,你的准确度将被报告为0,而不是95%。该行是:
在前面的几行代码中,我们建立、训练并测试了一个分类器,它在Iris数据集上具有95%的准确度。这里逐项分析每个步骤。在代码的前两行,我们做了几个导入,前两个是从scikit-learn,值得庆幸的是在import语句中其名字缩短为sklearn了。第一个导入的是一个随机森林分类器,第二个导入的是一个将数据分成训练组和测试组的模块。出于某些原因,这种数据切分在机器学习应用的构建中是很关键的。我们将在以后的章节讨论这些,现在只需要知道这是必需的。模块train_test_split还会打乱数据的先后顺序,这也是非常重要的,因为原有的顺序可能包含误导实际预测的信息。
在这本书中,我们将使用最新的Python版本,撰写本书的时候是版本3.5。如果你使用的Python是版本2.x,你需要添加额外的import语句,让整数的除法和Python 3.x中的一样运作。没有这一行,你的准确度将被报告为0,而不是95%。该行是:from future import division`
在import语句之后,第一行看上去很奇怪的代码实例化了我们的分类器,这个例子中是随机森林分类器。这里选择一个使用10个决策树的森林,而每棵树最多允许五层的判定深度。如此实施的原因是为了避免过拟合(overfitting),我们将在后面的章节中深入讨论这个话题。
接下来的两行创建了X矩阵和y向量。初始的iris数据框包含四个特征:花瓣的宽度和长度,以及花萼的宽度和长度。这些特征被选中并成为独立特征矩阵X。最后一列,iris类别的名称,就成为了因变的y向量。
然后这些被传递到train_test_split方法,该方法将数据打乱并划分为四个子集,X_train,X_test,y_train和y_test。参数test_size被设置为0.3,这意味着数据集的30%将被分配给X_test和y_test部分,而其余的将被分配到训练的部分,X_train和y_train。
接下来,使用训练数据来拟合我们的模型。一旦模型训练完毕,再通过测试数据来调用分类器的预测方法。请记住,测试数据是分类器没有处理过的数据。预测的返回结果是预估标签的列表。然后,我们创建对应实际标签与预估标签的数据框。最终,我们加和正确的预测次数,并将其除以样例的总数,从而看出预测的准确率。现在让我们看看哪些特征提供了最佳的辨别力或者说预测能力。
f_importances = clf.feature_importances_f_names = df.columns[:4]
f_std = np.std([tree.feature_importances_ for tree in
clf.estimators_], axis=0)
zz = zip(f_importances, f_names, f_std)
zzs = sorted(zz, key=lambda x: x[0], reverse=True)
imps = [x[0] for x in zzs]
labels = [x[1] for x in zzs]
errs = [x[2] for x in zzs]
plt.bar(range(len(f_importances)), imps, color="r", yerr=errs,
align="center")
plt.xticks(range(len(f_importances)), labels); ```
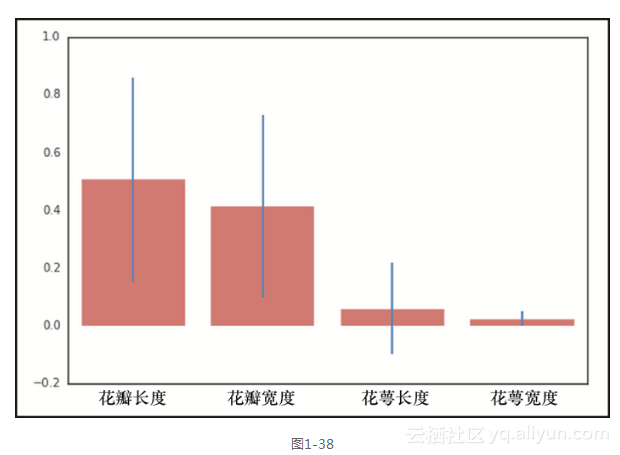
从图1-38可以看出,正如我们根据之前可视化分析所作出的预期,花瓣的长度和宽度对于区分iris的类别而言,具有更好的辨别力。不过,这些数字究竟来自哪里?随机森林有一个名为.feature_importances_的方法,它返回特征在决策树中划分叶子节点的相对能力。如果一个特征能够将分组一致性地、干净拆分成不同的类别,那么它将具有很高的特征重要性。这个数字的总和将始终为1。也许你注意到,在这里我们已经包括了标准差,它将有助于说明每个特征有多么的一致。这是如此生成的:对于每个特征,获取每10棵决策树的特征重要性,并计算标准差。
 现在,让我们看看另一个使用scikit-learn的例子。现在,切换分类器并使用支持向量机(SVM)。
现在,让我们看看另一个使用scikit-learn的例子。现在,切换分类器并使用支持向量机(SVM)。from sklearn.multiclass import OneVsRestClassifier
from sklearn.svm import SVC
from sklearn.cross_validation import train_test_split
clf = OneVsRestClassifier(SVC(kernel='linear'))
X = df.ix[:,:4]
y = np.array(df.ix[:,4]).astype(str)
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=.3)
clf.fit(X_train,y_train)
y_pred = clf.predict(X_test)
rf = pd.DataFrame(list(zip(y_pred, y_test)), columns=['predicted',
'actual'])
rf['correct'] = rf.apply(lambda r: 1 if r['predicted'] ==
r['actual'] else 0, axis=1)
rf`
前面的代码生成图1-39的输出。
现在,让我们执行下面这行代码。
``
rf['correct'].sum()/rf['correct'].count()``
前面的代码生成图1-40的输出。

这里,我们将模型切换为支持向量机,而没有改变代码的本质。唯一的变化是引入了SVM而不是随机森林,以及实例化分类器的那一行代码(标签y需要一个小小的格式改变,这是因为SVM无法像随机森林分类器那样,将这些标签解释为NumPy的字符串)。
这些仅仅是scikit-learn能力的一小部分,但它应该可以说明这个伟大的工具对于机器学习应用而言强大的功能和力量。还有许多其他的机器学习库,我们在这里没有机会讨论,不过会在后面的章节中探讨,这里我强烈建议,如果你是第一次使用机器学习库,而又想要一个强大的通用工具,scikit-learn将是你明智的选择。
1.2.5 部署
将一个机器学习模型放入生产环境时,有许多可用的选项。它基本上取决于应用程序的性质。部署小到在本地机器上运行cron作业,大到在Amazon EC2实例上部署全面的实现。
这里不会深入具体实施的细节,不过全书中我们将有机会研究不同的部署实例。