实践数据湖iceberg 第三课 在sqlclient中,以sql方式从kafka读数据到iceberg
实践数据湖iceberg 第三课 在sqlclient中,以sql方式从kafka读数据到iceberg
在sqlclient中,以sql方式从kafka读数据到iceberg
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 实践数据湖iceberg 第三课 在sqlclient中,以sql方式从kafka读数据到iceberg
- 环境说明
- 1. 启动带hive和kafka功能的flink-sql
- 2. 创建一个hive datalog,来存放iceberg文件
- 3 .catalog下创建数据库和表
- 4. 创建生产者,消费者
- 5. 把数据写入到iceberg表
- 6.写入失败分析
- 总结(问题排查思路)
环境说明
从实践中了解hive catalog 的特点
环境说明:
flink1.11.6
iceberg 0.11
kafka2.12_2.4.1
1. 启动带hive和kafka功能的flink-sql
[root@hadoop101 software]# bin/sql-client.sh embedded -j /opt/software/iceberg-flink-runtime-0.11.1.jar -j /opt/software/flink-sql-connector-hive-2.3.6_2.11-1.11.0.jar -j /opt/software/flink-sql-connector-kafka_2.11-1.11.6.jar shell
2. 创建一个hive datalog,来存放iceberg文件
CREATE CATALOG hive_catalog WITH (
'type'='iceberg',
'catalog-type'='hive',
'uri'='thrift://hadoop101:9083',
'clients'='5',
'property-version'='1',
'hive-conf-dir'='/opt/module/hive/conf'
);
Flink SQL> show catalogs;
default_catalog
hive_catalog
创建hadoop catalog
CREATE CATALOG hadoop_catalog WITH (
'type'='iceberg',
'catalog-type'='hadoop',
'warehouse'='hdfs://ns/user/hive/warehouse/iceberg_hadoop_catalog',
'property-version'='1'
);
3 .catalog下创建数据库和表
代码如下(示例):
创建数据库
use catalog hive_catalog
create database iceberg_db;
创建表:
create table `hive_catalog`.`iceberg_db`.`ib_test_log`(
data String
);
4. 创建生产者,消费者
[root@hadoop102 kafka]# kafka-console-consumer.sh --topic test_log --bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092
生产者随意生产数据
[root@hadoop101 ~]# kafka-console-producer.sh --topic test_log --broker-list hadoop101:9092,hadoop102:9092
#5. 检查生产者的数据是否能读取到
Flink SQL> select data from default_catalog.source.kafka_test_log;
[INFO] Result retrieval cancelled.
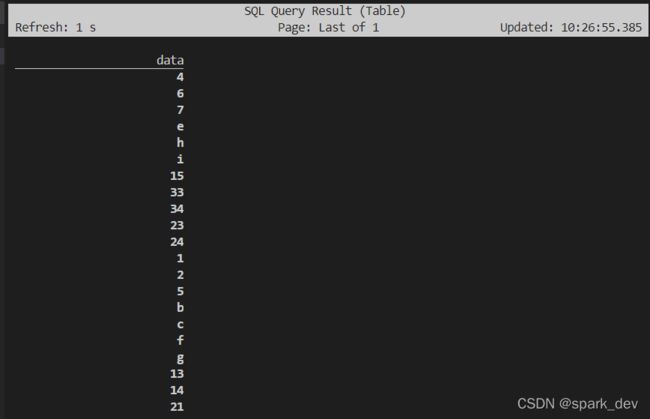
很确定能读取到
5. 把数据写入到iceberg表
insert into hive_catalog.iceberg_db.ib_test_log select data from default_catalog.source.kafka_test_log;
发现hdfs上的表,数据目录大小一直都是0,但生产者在不断写入数据,topic名称也检查了。
6.写入失败分析
一开始,觉得是catalog不对,重新定义catalog,(kafka表没有加catalog和database前缀,如下图)
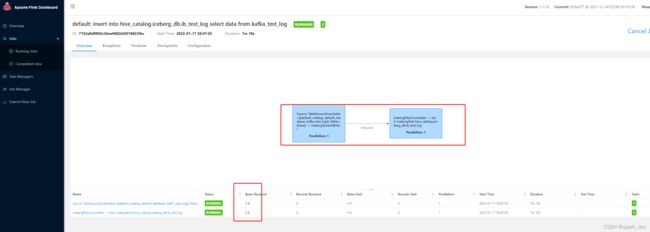
重新定义kafka的catalog后,还是读取不到。
给kafka表定义一个catalog和database, 发现还是读不到数据,bytes received还是0
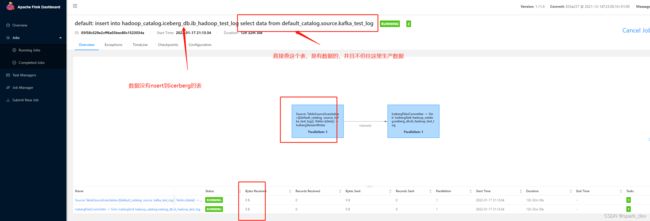
taskManager日志

TaskManager的stack信息,的确有在select数据,难道没有select到?
"Kafka Fetcher for Source: TableSourceScan(table=[[default_catalog, source, kafka_test_log]], fields=[data]) -> IcebergStreamWriter (1/1)" Id=2405 RUNNABLE
at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:269)
at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:93)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86)
- locked sun.nio.ch.Util$3@19f5e8f7
- locked java.util.Collections$UnmodifiableSet@744f2387
- locked sun.nio.ch.EPollSelectorImpl@2180e63e
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)
at org.apache.flink.kafka.shaded.org.apache.kafka.common.network.Selector.select(Selector.java:794)
at org.apache.flink.kafka.shaded.org.apache.kafka.common.network.Selector.poll(Selector.java:467)
at org.apache.flink.kafka.shaded.org.apache.kafka.clients.NetworkClient.poll(NetworkClient.java:547)
...
Number of locked synchronizers = 1
- java.util.concurrent.locks.ReentrantLock$FairSync@2402c423
"Legacy Source Thread - Source: TableSourceScan(table=[[default_catalog, source, kafka_test_log]], fields=[data]) -> IcebergStreamWriter (1/1)" Id=2401 WAITING on java.lang.Object@12863204
at java.lang.Object.wait(Native Method)
- waiting on java.lang.Object@12863204
at java.lang.Object.wait(Object.java:502)
at org.apache.flink.streaming.connectors.kafka.internal.Handover.pollNext(Handover.java:73)
at org.apache.flink.streaming.connectors.kafka.internal.KafkaFetcher.runFetchLoop(KafkaFetcher.java:137)
at org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase.run(FlinkKafkaConsumerBase.java:823)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:110)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:66)
at org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.run(SourceStreamTask.java:266)
"Thread-2084" Id=2404 TIMED_WAITING on java.util.LinkedList@1fd868c8
at java.lang.Object.wait(Native Method)
- waiting on java.util.LinkedList@1fd868c8
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:418)
"OutputFlusher for Source: TableSourceScan(table=[[default_catalog, source, kafka_test_log]], fields=[data]) -> IcebergStreamWriter" Id=2400 TIMED_WAITING
at java.lang.Thread.sleep(Native Method)
at org.apache.flink.runtime.io.network.api.writer.RecordWriter$OutputFlusher.run(RecordWriter.java:328)
"IcebergFilesCommitter -> Sink: IcebergSink hive_catalog.iceberg_db.ib_test_log (1/1)" Id=2399 WAITING on java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject@394fdc1b
at sun.misc.Unsafe.park(Native Method)
- waiting on java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject@394fdc1b
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
at org.apache.flink.streaming.runtime.tasks.mailbox.TaskMailboxImpl.take(TaskMailboxImpl.java:136)
at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.processMail(MailboxProcessor.java:313)
at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:188)
at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:608)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:574)
...
总结(问题排查思路)
什么原因造成呢?看官网是这么做的,看网上其他博客,都能正常获取到数据(他们为什么这么顺利完成这个写入 demo?)。
其实以为是自己的kafka,flink版本不一致,kafka是2.11的scala,flink,iceberg是2.12的,但也没有代码报错,我还是统一更改为2.12的scala版本,还是不行 (排除了版本不一致问题)。
还是说明原因呢?
把hive catalog改为hadoop catalog也不行(排除是hive的问题)。
是否是flink对应的kafka版本不一致呢? 换个kafka版本,校验看看