在NLP项目中使用Hugging Face的Datasets 库
数据科学是关于数据的。网络上有各种来源可以为您的数据分析或机器学习项目获取数据。最受欢迎的来源之一是 Kaggle,我相信我们每个人都必须在我们的数据旅程中使用它。
最近,我遇到了一个新的来源来为我的 NLP 项目获取数据,我很想谈谈它。这是 Hugging Face 的数据集库,一个快速高效的库,可以轻松共享和加载数据集和评估指标。因此,如果您从事自然语言理解 (NLP) 工作并希望为下一个项目提供数据,那么 Hugging Face 就是您的最佳选择。
Hugging Face 是自然语言处理 (NLP) 技术的开源提供商。您可以使用最先进的Hugging Face 模型(在 Transformers 库下)来构建和训练您自己的模型。
根据 Hugging Face 网站,Datasets 库目前拥有 100 多个公共数据集。 数据集不仅有英语,还有其他语言和方言。 它支持大多数这些数据集的数据加载器,并且只需一行代码就可以实现,这使得加载数据成为一项轻松的任务。 根据网站上提供的信息,除了可以轻松访问数据集之外,该库还有以下有趣的功能:
- 在大型数据集的发展使得数据集自然地将用户从 RAM 限制中解放出来,所有数据集都使用高效的零序列化成本后端 (Apache Arrow) 进行内存映射。
- 智能缓存:永远不要将数据处理多次。
- 轻量级和快速的透明和 pythonic API(多处理/缓存/内存映射)。
- 与 NumPy、pandas、PyTorch、Tensorflow 2 和 JAX 的内置互操作性。
在本文中,我将展示我们通常在数据科学或分析任务中执行的一些步骤,以了解我们的数据或将我们的数据转换为所需的格式。所以,让我们快速深入这个库并编写一些简单的 Python 代码。请注意,本文仅涵盖数据集而非指标。
数据集版本:1.7.0
使用pip安装
from datasets import list_datasets, load_dataset
from pprint import pprint从数据集库中,我们可以导入list_datasets来查看这个库中可用的数据集列表。打印模块提供了“漂亮打印”的功能。
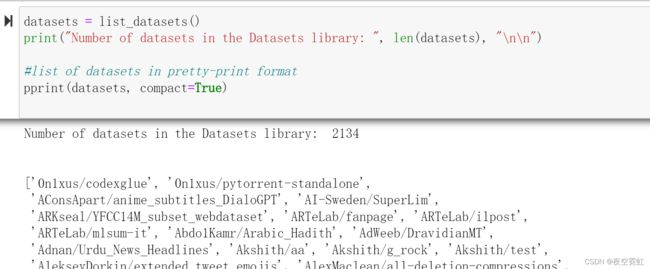
截至2021年12月9日,数据集库有928个数据集。我们可以使用以下代码看到可用的数据集列表:
datasets = list_datasets()
print("Number of datasets in the Datasets library: ", len(datasets), "\n\n")
#list of datasets in pretty-print format
pprint(datasets, compact=True)运行结果:
数据属性:
#dataset attributes
squad = list_datasets(with_details=True)[datasets.index('Avishekavi/Avi')]
#calling the python dataclass
pprint(squad.__dict__)
加载数据集:
squad_dataset = load_dataset('squad')

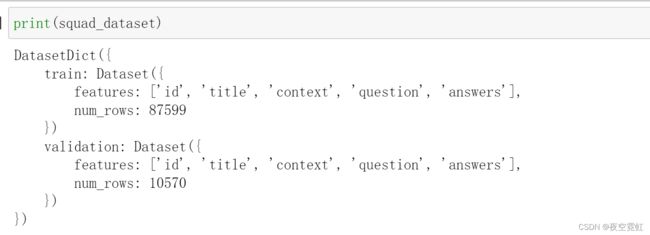
数据集分为两部分:训练和验证。
feature对象包含关于列的信息——列名,我们还可以看到每次拆分的行数(num_rows)。
分割为训练集和验证集:
squad_train = load_dataset('squad', split='train')
squad_valid = load_dataset('squad', split='validation')看下训练集的大小:
print("Length of training set: ", len(squad_train))
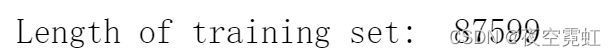
查看训练集中的一个示例:
print("First example from the dataset: \n")
pprint(squad_train[0])

数据集中数据对象的字段属性:
print("Features: ")
print(squad_train.features)
print("Column names: ", squad_train.column_names)
Features: {'id': Value(dtype='string', id=None), 'title': Value(dtype='string', id=None), 'context': Value(dtype='string', id=None), 'question': Value(dtype='string', id=None), 'answers': Sequence(feature={'text': Value(dtype='string', id=None), 'answer_start': Value(dtype='int32', id=None)}, length=-1, id=None)} Column names: ['id', 'title', 'context', 'question', 'answers']
print("Number of rows: ", squad_train.num_rows)
print("Number of columns: ", squad_train.num_columns)
print("Shape: ", squad_train.shape)Number of rows: 87599 Number of columns: 5 Shape: (87599, 5)
hugging face官网:
Hugging Face – The AI community building the future.
squad数据集:
Tasks: extractive-qa 抽取式问答,即给定文章和问题,机器需要在文章中找到答案对应的区域(span),给出开始位置和结束位置,区域的长度通常不会限制。
Task Categories: question-answering
Languages: en
Multilinguality: monolingual 多语言:单语
Size Categories: 10K Licenses: cc-by-4.0 Language Creators: crowdsourcedfound Annotations Creators: crowdsourced Source Datasets: extended|wikipedia Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable. 斯坦福问答数据集 (SQuAD) 是一个阅读理解数据集,由众包工作者对一组维基百科文章提出的问题组成,其中每个问题的答案都是来自相应阅读段落或问题的一段文本或跨度,也可能无法回答。