数据结构
终身受益的700个网站【史上最全】——建议收藏“卑微的小丑”总有一个可以帮助你!!!
https://blog.csdn.net/liu17234050/article/details/105092333
目录:
第一章: 数据结构绪论
1.什么是程序
2.逻辑结构&物理结构的区别用法
3.顺序存储&链式存储的区别用法
第二章:算法
1.定义
2.特性
3.算法时间效率度量
4.时间复杂度&空间复杂度的区别用法
第三章:线性表
1.定义
2.顺序存储结构&链式存储结构的区别和用法
第四章:栈与队列
1.什么是栈
(1) 栈顶(top)
(2)栈底(bottom)
(3) 空栈
2. 顺序栈&链栈
(1) 顺序栈
(2)链栈
(3)两者示意图如下所示:
(4)顺序栈&链栈的异同
A:同【时间复杂度】
B:异【空间性能】
3.栈的内部实现原理
4.递归
(1) 定义
(2)条件:
(3)斐波那契数列(Fibonacci)
5.栈的数学表达式的求值
6.队列(queue)
(1)定义
(2)对头
(3)队尾
第五章:数组和广义表
第六章:串【字符串】
1.定义
2.串的逻辑结构
3.串的存储结构
(1)串的顺序存储结构
(2)串的链式存储结构
第七章:树
1.定义
2.特点【根节点-子树-子节点】
3.线性结构&树结构的区别用法
4.二叉树
(1)定义
(2)特点
(3)五种基本形态
(4)五种特性【理解】
(5)二叉树的四种遍历方式【前序遍历-中序遍历-后序遍历-层序遍历】
(6) 赫夫曼编码
A:定义
a: 路径和路径长度
b: 结点的权及带权路径长度
c: 树的带权路径长度
补充:数据结构——哈夫曼(Huffman)树+哈夫曼编码
第八章:图(Graph)
1:定义
2:线性表&树&图的【数据元素名称-有无结点-内部之间的关系】的区别
3:图的五种种类【无向图-有向图-简单图-完全无向图-有向完全图】
4:权
(1)定义
(2)图形化解释
5.环
(1)定义
(2)图形化解释
6.特性
A: 连通
B:简单路径
C:强连通图
D: 强连通分量
E:生成树
F:有向树
G:森林
7.图的两种遍历【深度优先遍历-广度优先遍历】的区别用法
8.最小生成树连通网的两种算法区别和用法【普里姆(Prim)算法-克鲁斯卡尔(Kruskal)算法】
9. AOV 网(Activity On Vertext Network)
10.拓扑序列
对 AOV 网进行拓扑排序的基本思路是:
11: AOE 网(Activity On Edge Network)
A:始点或源点
B:终点或汇点
C:路径长度
D:关键路径
E:关键活动
第九章:动态内存管理
第十章:查找
1.查找表(Search Table)
2.关键字(Key)
(1)键值
(2)关键码
(3)关键字(Primary Key)
(4)次关键字(Secondary Key)
3.查找
(1)定义
(2)静态查找表&动态查找表的区别用法【顺序查找-线性查找-折半查找-二分查找-有序表查找-插值查找-斐波那契查找-索引顺序表查找-分块查找】
4.索引
(1)定义
(2)按照结构分类
(3)三种线性索引&两种表【稠密索引-分块索引-倒排索引-多重表-倒排表】
5.二叉排序树【 二叉查找树】
(1)定义
(2)目的
(3)存储方式
A:定义
B:执行插入或删除操作时
C:查找操作时
D:查找次数最少
E:查找次数最多
F:二叉排序树的形状
G:解决二叉排序树的形状问题
H:深度
I:时间复杂度
J:平衡二叉树(AVL 树)
(4)平衡二叉树
(5)平衡因子 BF(Balance Factor)
(6)平衡二叉树
(7)最小不平衡子树
(8)平衡二叉树实现原理
6.多路查找树(muitl-way search tree)
(1)分析
(2)定义
(3)四中常见的多路查找树【2-3 树$2-3-4 树$B 树$B+ 树】的区别用法
7.散列技术
(1)定义
(2)散列表【哈希表(Hash table)】
(3)散列地址
(4)散列函数设计原则
A:计算简单:
B:散列地址分布均匀:
(5)构造散列函数的六种方法【直接定址法-数字分析法-平方取中法-折叠法-除留余数法-随机数法】
(6)处理散列冲突的四种方法【开放定址法-再散列函数法-链地址法-公共溢出区法】
(7)散列表性能分析
A:散列函数是否均匀:
B:处理冲突的方法:
C:散列表的装填因子:
第十一章:内部排序
1.定义
2.多个关键的排序最终都可以转化为单个关键字的排序
3.排序的稳定性
4.内排序&外排序
(1)内排序
(2)外排序
5.影响内排序的三个方面
(1)时间性能
A:比较
B:移动
(2)辅助空间
(3)算法的复杂性
6.C 语言中的十四种内部排序算法
第十二章:外部排序
1.外部排序定义
2.外部排序的基本思路
举例:
3.外部排序算法
(1)定义
(2)外部排序算法由两个阶段构成
(3)2-路平衡归并
举例:
(4)5-路归并
4.多路平衡归并排序(胜者树、败者树)算法
(1)引入
(2)败者树实现内部归并
(3)胜者树
(4)败者树
(5)败者树内部归并的具体实现
5.置换-选择排序算法
1.引入
(2)图解
(3)操作过程
(4)置换选择排序算法的具体实现
6.最佳归并树
(1)思考
(2)举例参考
7.“虚段”的归并树
(1)引入
(2)如何判断是否需要增加虚段,以及增加多少虚段
十三:文件
==================================================================================
参考文件:
《大话数据结构课本》
《[数据结构课本(C语言版)].严蔚敏_吴伟民.扫描版》
《数据结构与算法分析课本》
参考书籍(word+ppt版本)地址:
链接:https://pan.baidu.com/s/1725YDUPVfIXRl8U4QnY0pA
提取码:750y
参考视频地址:
【C语言描述】《数据结构和算法》(小甲鱼)99集:推荐学习-《推荐》
https://www.bilibili.com/video/av21828275/
【青岛大学-王卓】数据结构与算法基础(40个小时) 173集:推荐学习-《推荐》
https://www.bilibili.com/video/av82837069?from=search&seid=16668239479775468624
==================================================================================
什么是数据结构:
是数据之间存在一种或多种特定关系的数据元素集合
为编写出一个“好”的程序,必须分析待处理对象的特性及各处理对象之间存在的关系
这也就是研究数据结构的意义所在
知识结构图:
https://www.processon.com/view/5cf5d469e4b0da05395d5143#map
第一章: 数据结构绪论
1.什么是程序
程序 = 数据结构 + 算法
2.逻辑结构&物理结构的区别用法
https://blog.csdn.net/liu17234050/article/details/104251163
3.顺序存储&链式存储的区别用法
https://blog.csdn.net/liu17234050/article/details/104251282
==================================================================================
第二章:算法
1.定义
算法是解决特定问题求解步骤的描述
在计算机中表现为指令的有限序列
并且每条指令表示一个或多个操作
简而言之,算法是描述解决问题的方法
2.特性
输入、输出、有穷性、确定性和可行性
好的算法:应该具有正确性,可读性,健壮性,高效率和低存储量的特征
3.算法时间效率度量
(1)可以忽略加法常数
O(2n + 3) = O(2n)
(2)与最高次项相乘的常数可忽略
O(2n^2) = O(n^2)
(3) 最高次项的指数大的,函数随着 n 的增长,结果也会变得增长得更快
O(n^3) > O(n^2)
(4)判断一个算法的(时间)效率时,函数中常数和其他次要项常常可以忽略,而更应该关注主项(最高阶项)的阶数
-
O(
2n^
2) = O(n^
2+
3n+
1)
-
O(n^
3) > O(n^
2)
4.时间复杂度&空间复杂度的区别用法
https://blog.csdn.net/liu17234050/article/details/104251507
==================================================================================
第三章:线性表

1.定义
零个或多个数据元素的有限序列
2.顺序存储结构&链式存储结构的区别和用法
https://blog.csdn.net/liu17234050/article/details/104252533
==================================================================================
第四章:栈与队列
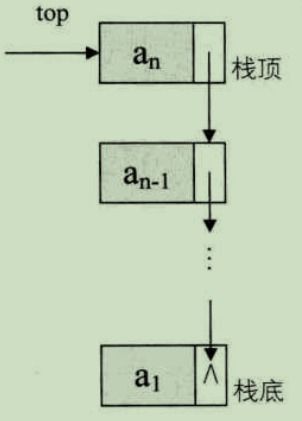
1.什么是栈
是限定仅在表尾(栈顶)进行插入和删除操作的线性表
栈又称为 后进先出(Last In First Out) 的线性表,简称 LIFO 结构
(1) 栈顶(top)
我们把允许插入和删除的一端称为 栈顶
(2)栈底(bottom)
另一端称为 栈底
(3) 空栈
不含任何任何数据元素的栈称为 空栈
2. 顺序栈&链栈
栈 是线性表的特例,其具备先进后出 FILO 特性
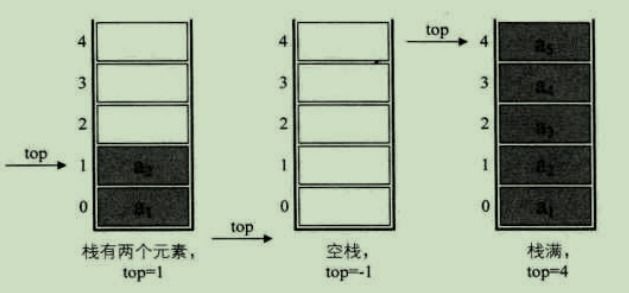
(1) 顺序栈
可以使用线性表的顺序存储结构(即数组)实现栈,将之称之为 顺序栈
(2)链栈
可以使用单链表结构实现栈,将之称之为 链栈
(3)两者示意图如下所示:
(4)顺序栈&链栈的异同
A:同【时间复杂度】
顺序栈和链栈的时间复杂度均为
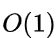
B:异【空间性能】
a:顺序栈
顺序栈需要事先确定一个固定的长度(数组长度)
可能存在内存空间浪费问题,但它的优势是存取时定位很方便
b:链栈
要求每个元素都要配套一个指向下个结点的指针域
增大了内存开销,但好处是栈的长度无限
因此,如果栈的使用过程中元素变化不可预料,有时很小,有时很大,那么最好使用链栈
反之,如果它的变化在可控范围内,则建议使用顺序栈
3.栈的内部实现原理
栈的内部实现原理其实就是数组或链表的操作
而之所以引入 栈 这个概念,是为了将程序设计问题模型化
用高层的模块指导特定行为(栈的先进后出特性),划分了不同关注层次,使得思考范围缩小
更加聚焦于我们致力解决的问题核心,简化了程序设计的问题
4.递归
(1) 定义
在运行的过程中调用自己
每个递归定义必须至少有一个条件,使得当满足条件时,递归不再进行
(2)条件:
1. 子问题须与原始问题为同样的事,且更为简单;
2. 不能无限制地调用本身,须有个出口,化简为非递归状况处理
(3)斐波那契数列(Fibonacci)
指的是这样一个数列:1、1、2、3、5、8、13、21、……,即当前位置的值为前面两项之和
用数学表达式表达如下:

如果我们直接将按上面的公式用代码进行翻译,如下所示:
-
int
fbi(const int n){
-
int
i;
-
int
ret;
-
int
last1 = 0;
-
int
last2 = 1;
-
if
(n == 0){
-
ret =
0;
-
}else
if (n == 1){
-
ret =
1;
-
}else{
-
for(i =
2; i <= n; ++i){
-
ret =
last1 + last2;
-
last1 =
last2;
-
last2 =
ret;
-
}
-
}
-
return
ret;
-
}
但是如果我们使用递归方式实现,则会更加简洁:
-
int fbi(const int n){
-
if (n <
2){
-
return n ==
0 ?
0 :
1;
-
}
-
return fbi(n
-1) + fbi(n
-2);
-
}
使用递归,简洁之余,还更加契合其数学公式的定义
5.栈的数学表达式的求值
其原理是通过将 中缀表达式(即标准的四则运算表达式) 以特定操作进行进栈出栈操作
得到一个对应的 后缀表达式(也称为逆波兰(Reverse Polish Notation,PRN)表示)
然后将该后缀表达式再次通过特定操作进行出栈入栈操作,即可得到运算结果
6.队列(queue)
(1)定义
是只允许在一端进行插入操作,而在另一端进行删除操作的线性表
队列 是一种 先进先出(First In First Out) 的线性表
(2)对头
允许删除的一端称为对头
(3)队尾
允许插入的一端称为队尾
线性表有顺序存储和链式存储,栈是线性表,所以有这两种存储方式
同样,队列作为一种特殊的线性表,也同样存在这两种存储方式
==================================================================================
第五章:数组和广义表
学习地址:
http://c.biancheng.net/data_structure/array_list/
==================================================================================
第六章:串【字符串】
1.定义
串(string) 是由零个或多个字符组成的有限序列,又名叫 字符串
2.串的逻辑结构
串 的逻辑结构和线性表很相似
不同之处在于串针对的是字符集
也就是串中的元素都是字符
因此,对于串的基本操作与线性表是有很大差别的
线性表更关注的是单个元素的操作,比如查找一个元素,插入或删除一个元素
但串中更多的是查找子串位置,得到指定位置子串,替换子串等操作
3.串的存储结构
串 的存储结构与线性表相同,分为两种:
(1)串的顺序存储结构
串的顺序存储结构是用 一组地址连续的存储单元 来存储串中的字符序列。一般是用定长数组来定义
由于是定长数组,因此就会存在一个预定义的最大串长度
一般可以将实际的串长度值保存在数组 0 下标位置,也可以放在数组最后一个下标位置
也有些语言使用在串值后面加一个不计入串长度的结束标记符(比如\0)
来表示串值得终结,这样就无需使用数字进行记录
(2)串的链式存储结构
对于串的链式存储结构,与线性表是相似的
但由于串结构的特殊性(结构中的每个元素数据都是一个字符)
如果也简单地将每个链结点存储一个字符,就会存在很大的空间浪费
因此,一个结点可以考虑存放多个字符
如果最后一个结点未被占满时,可以使用 "#" 或其他非串值字符补全

串的链式存储结构除了在链接串与串操作时有一定的方便之外
总的来说不如顺序存储灵活,性能也不如顺序存储结构好
==================================================================================
第七章:树
1.定义
树是
个结点的有限集
当 时称为空树
时称为空树
树 其实也是一种递归的实现,即树的定义之中还用到了树的概念
2.特点【根节点-子树-子节点】
在任意一棵非空树中:
(1)且仅有一个特定的结点:根结点(Root)
(2)当 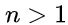 时,其余结点可分为
时,其余结点可分为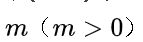 个互不相交的有限集
个互不相交的有限集

其中每一个集合本身又是一棵树,并且称为根的 子树(SubTree)
其图示如下所示:

(3)根结点大于 0
时根结点是唯一的,不可能同时存在多个根结点
(4)子结点大于 0 时,子树的个数没有限制,但它们一定是互不相交的
时,子树的个数没有限制,但它们一定是互不相交的
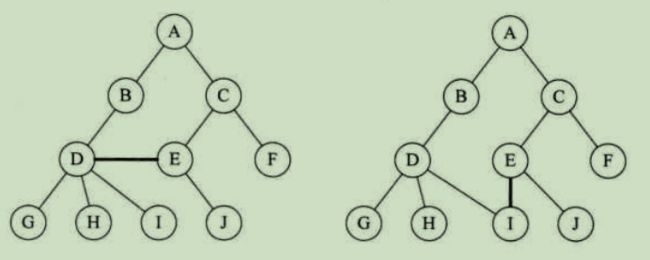
下图所示的结构就不符合树的定义,因为它们都有相交的子树:
3.线性结构&树结构的区别用法
https://blog.csdn.net/liu17234050/article/details/104256016
单独使用顺序存储结构(即数组)无法很好地实现树的存储概念,不过如果充分利用顺序存储和链式存储结构的特点,则完全可以实现对数的存储结构的表示
4.二叉树
(1)定义
二叉树(Binary Tree):是
个结点的有限集合
该集合或者为空集(称为空二叉树)
或者由一个根结点和两棵互不相交的
分别称为根结点的左子树和右子树的二叉树组成
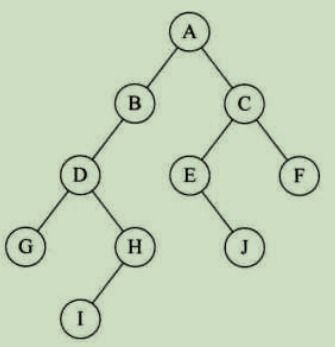
(2)特点
A:每个结点最多只能有两棵子树
B:左子树和右子树是有顺序的,次序不能任意颠倒
C: 即使树中某结点只有一棵子树,也要区分它是左子树还是右子树
(3)五种基本形态
A:空二叉树
B:只有一个跟结点
C:根结点只有左子树
D:根结点只有右子树
E:根结点既有左子树又有右子树
(4)五种特性【理解】
A:在二叉树的第
层上至多有
个结点
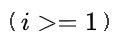
比如第一层是根结点,只有一个;第二层有两个:根结点的左子树和右子树···
B:深度为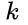 的二叉树至多有
的二叉树至多有 个结点
个结点
比如深度为 1,则至多只有 1 个结点,即根结点;深度为 2,则至多只有 3 个结点:根结点,根结点的左子树,根结点的右子树···
C:对任何一棵二叉树 如果其叶子结点点数为
如果其叶子结点点数为  ,度(即子结点数)为 2 的结点数为
,度(即子结点数)为 2 的结点数为 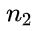 ,则
,则 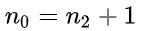
D:具有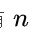 个结点的完全二叉树的深度为
个结点的完全二叉树的深度为 表示不大于
表示不大于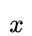 的最大整数
的最大整数
E:如果对一棵树有 个结点的完全二叉树(其深度为
个结点的完全二叉树(其深度为 的结点按层序编号(从第 1 层到第
的结点按层序编号(从第 1 层到第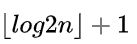 层,每层从左到右),对任一结点
层,每层从左到右),对任一结点  有:
有:
a:.如果 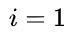 ,则结点
,则结点 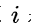 是二叉树的根,无双亲;如果
是二叉树的根,无双亲;如果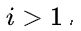 则其双亲是结点
则其双亲是结点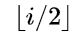
b:如果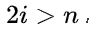 ,则结点
,则结点 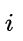 无左孩子(结点
无左孩子(结点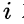 为叶子结点);否则其左孩子是结点
为叶子结点);否则其左孩子是结点
c:如果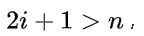 则结点
则结点 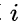 无右孩子;否则其右孩子是结点
无右孩子;否则其右孩子是结点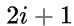
前面提及到顺序存储对数这种一对多的关系结构实现起来是比较困难的
但是对于二叉树,由于它的特殊性,使得用顺序存储结构也可以实现
(5)二叉树的四种遍历方式【前序遍历-中序遍历-后序遍历-层序遍历】
https://blog.csdn.net/liu17234050/article/details/104256408
(6) 赫夫曼编码
树,森林看似复杂
其实它们都可以转化为简单的二叉树来处理
这样就使得面对树和森林的数据结构时,编码实现成为了可能
最基本的压缩编码方法:赫夫曼编码
A:定义
给定n个权值作为n个叶子结点
构造一棵二叉树,若树的带权路径长度达到最小,则这棵树被称为哈夫曼树

a: 路径和路径长度
定义:在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径
通路中分支的数目称为路径长度
若规定根结点的层数为1,则从根结点到第L层结点的路径长度为L-1。
-
例子:100和80的路径长度是1,
-
50
和30的路径长度是2,
-
20
和10的路径长度是3。
b: 结点的权及带权路径长度
定义:若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权
结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积
-
例子:节点20的路径长度是3,
-
它的带权路径长度=
路径长度
*
权
=
3
*
20
=
60
。
c: 树的带权路径长度
定义:树的带权路径长度规定为所有叶子结点的带权路径长度之和,记为WPL。
例子:示例中,树的WPL= 1*100 + 2*50 + 3*20 + 3*10 = 100 + 100 + 60 + 30 = 290。
比较下面两棵树:

上面的两棵树都是以{10, 20, 50, 100}为叶子节点的树。
左边的树WPL=2*10 + 2*20 + 2*50 + 2*100 = 360 右边的树WPL=350
左边的树WPL > 右边的树的WPL。
你也可以计算除上面两种示例之外的情况,但实际上右边的树就是{10,20,50,100}对应的哈夫曼树
补充:数据结构——哈夫曼(Huffman)树+哈夫曼编码
==================================================================================
第八章:图(Graph)
1:定义
由顶点的有穷非空集合和顶点之间边的集合组成
通常表示为: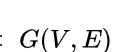
其中,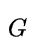 表示一个图
表示一个图
 是图
是图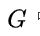 中的顶点的集合
中的顶点的集合
 是图
是图 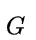 中边的集合
中边的集合
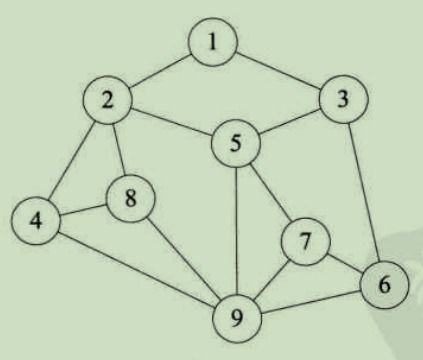
A:在线性表中
数据元素之间是被串起来的,仅有线性关系
每个数据元素只有一个直接前驱和一个直接后驱
B:在树形结构中
数据元素之间有着明显的层次关系
并且每一层上的数据元素可能和下一层中多个元素相关
但只能和上一层中一个元素相关
C:图是一种较线性表和树更加复杂的数据结构
在图形结构中,结点之间的关系可以是任意的
图中任意两个数据元素之间都可能相关
2:线性表&树&图的【数据元素名称-有无结点-内部之间的关系】的区别
https://blog.csdn.net/liu17234050/article/details/104256952
3:图的五种种类【无向图-有向图-简单图-完全无向图-有向完全图】
https://blog.csdn.net/liu17234050/article/details/104258272
4:权
(1)定义
有些图的边或弧具有与它相关的数字,这种 与图的边或弧相关的数叫做权(Weight)
这些权可以表示从一个顶点到另一个顶点的距离或耗费
这种带权的图通常称为网(Network)
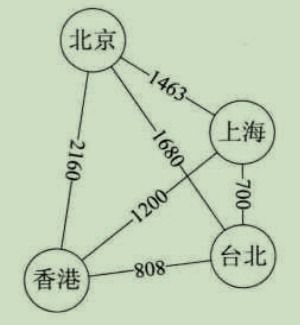
(2)图形化解释
图就是一张带权的图
即标识中国四大城市的直线距离的网
此图中的权就是两地的距离
图结构中,路径的长度是路径上的边或弧的数据
第一个顶点到最后一个顶点相同的路径称为 回环 或 环(Cycle)
序列中顶点不重复出现的路径称为 简单路径
5.环
(1)定义
除了第一个顶点和最后一个顶点之外
其余顶点不重复出现的回路,称为 简单回路 或 简单环
(2)图形化解释
下图所示两个图粗线都构成环
左侧的环只有第一个顶点和最后一个顶点都是 B
其余顶点没有重复出现,因此其是一个简单环
而右侧的环,由于顶点 C 的重复
因此它就不是简单环了

6.特性
A: 连通
图中顶点间存在 路径,两顶点存在路径则说明是 连通 的
B:简单路径
如果路径最终回到起始点则成为 环,当中不重复叫 简单路径
C:强连通图
若任意两顶点都是连通的,则图就是 连通图,有向则称为 强连通图
D: 强连通分量
图中有子图,若子图极大连通则就是 连通分量,有向的则称为 强连通分量
E:生成树
无向图中连通且 个顶点
个顶点 条边叫 生成树
条边叫 生成树
F:有向树
有向图中一顶点入度为0
其余顶点入度为1的叫 有向树
G:森林
一个有向图由若干棵有向树构成生成 森林
由于图的结构比较复杂,任意两个顶点之间都可能存在联系
因此无法以数据元素在内存中的物理位置来表示元素之间的关系
也就是说,图不可能用简单的顺序存储结构(即数组)来表示
而多重链表尽管可以实现图结构(即以一个数据域和多个指针域组成的结点表示图中的一个顶点)
但是却存在内存浪费或操作不便的问题
因此,图存储结构最终还是得通过结合顺序存储和链式存储才能做到比较好地实现
7.图的两种遍历【深度优先遍历-广度优先遍历】的区别用法
https://blog.csdn.net/liu17234050/article/details/104258892
8.最小生成树连通网的两种算法区别和用法【普里姆(Prim)算法-克鲁斯卡尔(Kruskal)算法】
https://blog.csdn.net/liu17234050/article/details/104262387
9. AOV 网(Activity On Vertext Network)
在一个表示工程的有向图中
用顶点表示活动
用弧表示活动之间的优先关系
这样的有向图为顶点表示活动的网,我们成为 AOV 网(Activity On Vertext Network)
AOV 网中的弧表示活动之间存在的某种制约关系,同时 AOV 网中不能存在回路
10.拓扑序列
设
是一个具有
个顶点的有向图
 中的顶点序列
中的顶点序列
满足若从顶点  到
到 有一条路径
有一条路径
则在顶点序列中顶点  必在顶点
必在顶点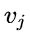 之前
之前
则我们将这样的顶点序列称为一个 拓扑序列
所谓 拓扑排序,其实就是对一个有向图构造拓扑序列的过程
对 AOV 网进行拓扑排序的基本思路是:
A:从 AOV 网中选择一个入度为 0 的顶点输出
B:然后删去此顶点
C:并删除以此顶点为尾的弧
D:继续重复此步骤
E:直到输出全部顶点
或者 AOV 网中不存在入度为 0 的顶点为止
11: AOE 网(Activity On Edge Network)
在一个表示工程的带权有向图中
用顶点表示事件
用有向边表示活动
用边上的权值表示活动的持续时间
这种有向图的边表示活动的网
我们称之为 AOE 网(Activity On Edge Network)
A:始点或源点
我们把 AOE 网中没有入边的顶点称为始点或源点
B:终点或汇点
没有出边的顶点称为终点或汇点
由于一个工程,总有一个开始,一个结束,所以正常情况下,AOE 网只有一个源点一个汇点
C:路径长度
我们把路径上各个活动所持续的时间之和称为 路径长度
D:关键路径
从源点到汇点具有最大长度的路径叫 关键路径
E:关键活动
在关键路径上的活动叫关键活动
==================================================================================
第九章:动态内存管理
学习地址:
http://c.biancheng.net/data_structure/memory/
==================================================================================
第十章:查找
1.查找表(Search Table)
由同一类型的数据元素(或记录)构成的集合
2.关键字(Key)

(1)键值
是数据元素中的某个数据项的值,又称为 键值,用它可以标识一个数据元素
(2)关键码
也可以标识一个记录的某个数据项(字段),我们称为 关键码
(3)关键字(Primary Key)
若此关键字可以唯一地标识一个记录,则称此关键字为主关键字
(4)次关键字(Secondary Key)
而对于那些可以识别多个数据元素(或记录)的关键字,我们称为 次关键字
3.查找
(1)定义
就是根据给定的某个值,在查找表中确定一个其关键字等于给定值得数据元素(或记录)
从逻辑上来说,查找所基于的数据结构是集合
集合中的记录之间没有本质关系
可是要想获得较高的查找性能
我们就不能不改变数据元素之间的关系
在存储时可以将查找集合组织成表,树等结构
比如,对于静态查找表来说,我们不妨应用线性表结构来组织数据
这样可以使用顺序查找算法,如果再对主关键字排序,则可以应用折半查找等技术进行高效的查找
(2)静态查找表&动态查找表的区别用法【顺序查找-线性查找-折半查找-二分查找-有序表查找-插值查找-斐波那契查找-索引顺序表查找-分块查找】
https://blog.csdn.net/liu17234050/article/details/104264637
4.索引
(1)定义
就是把一个关键字与它对应的记录相关联的过程(关键字=记录)
数据结构的最终目的就是提高数据的处理速度
索引是为了加快查找速度而设计的一种数据结构
一个索引由若干个索引项构成
每个索引项至少应包含关键字和其对应的记录在存储器中的位置等信息
索引技术是组织大型数据库以及磁盘文件的一种重要技术
(2)按照结构分类
索引按照结构可以分为:线性索引,树形索引和多级索引
(3)三种线性索引&两种表【稠密索引-分块索引-倒排索引-多重表-倒排表】
https://blog.csdn.net/liu17234050/article/details/104266787
假设查找的数据集是普通的顺序存储
那么插入操作(插入到末尾)和删除操作(删除记录后记录向前移相对耗时
但如果只把删除的元素与最后一个元素互换
然后表记录数减一,则很高效)的效率是可以接受的
但是顺序存储表由于无序会造成查找效率很低
如果查找的数据集是有序线性表,并且是顺序存储的
那么其查找(二分法,插值法,斐波那契···)效率很高
但是由于有序,在插入和删除操作上,就需要耗费大量的时间
5.二叉排序树【 二叉查找树】
而使用 二叉排序树 这种存储结构时,就可以实现对动态查找表的高效插入,删除和查找操作
(1)定义
二叉排序树(Binary Sort Tree):又称为 二叉查找树
它或者是一棵空树
或者是具有下列性质的二叉树:
A:若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值
B:若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值
C:它的左、右子树也分别为二叉排序树
(2)目的
构造一棵 二叉排序树 的目的,其实并不是为了排序
而是为了提高查找和插入删除关键字的速度
不管怎么说,在一个有序数据集上的查找,速度总是要快于无序的数据集的
而二叉排序树这种非线性的结构
也有利于插入和删除的实现
(3)存储方式
A:定义
二叉排序树 是以链接的方式存储
B:执行插入或删除操作时
保持了链接存储结构在执行插入或删除操作时不用移动元素的有点(只需修改链接指针)
插入和删除的时间性能比较好
C:查找操作时
而对于二叉排序树的查找,走的就是从根结点到要查找的结点的路径
其比较次数等于给定值得结点在二叉排序树的层数
D:查找次数最少
极端情况下,查找次数最少为 1 次
即根结点就是要找的结点
E:查找次数最多
最多也不会超过树的深度
也就是说,二叉排序树的查找性能取决于二叉排序树的形状
F:二叉排序树的形状
很可惜的是,二叉排序树的形状是不确定的(想象下极端的右斜树或左斜树)
G:解决二叉排序树的形状问题
对于这个问题,解决方案就是让二叉排序树左右子树是比较平衡的
H:深度
即其深度与完全二叉树相同,均为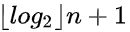
I:时间复杂度
那么查找的时间复杂度就为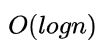
J:平衡二叉树(AVL 树)
近似二分查找,这种结构就称为 平衡二叉树
(4)平衡二叉树
(Self-Balancing Binary Search Tree 或 Height-Balanced Binary Search Tree)
是一种二叉排序树
其中每一个结点的左子树和右子树的高度差至多等于 1
(5)平衡因子 BF(Balance Factor)
将二叉树上结点的左子树深度减去右子树深度的值称为 平衡因子 BF
(6)平衡二叉树
上所有结点的平衡因子只可能是 -1、0 和 1
只要二叉树上有一个结点的平衡因子的绝对值大于 1,则该二叉树就是不平衡的
(7)最小不平衡子树
距离插入结点最近的,且平衡因子的绝对值大于 1 的结点为根的子树,我们称为 最小不平衡子树
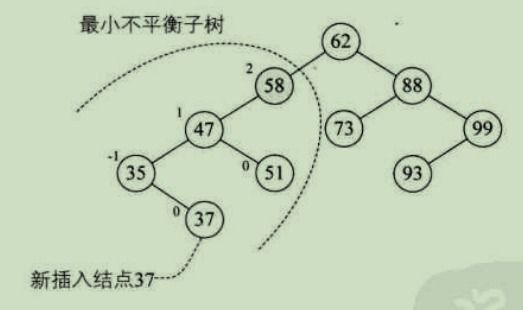
如上图所示,当新插入结点 37 时
距离它最近的平衡因子绝对值超过 1 的结点是 58
(58 的左子树高度为 2,右子树高度为 0)
所以从 58 开始以下的子树为最小不平衡子树
(8)平衡二叉树实现原理
平衡二叉树构建的基本思想就是在构建二叉树排序树的过程中
每当插入一个结点时
先检查是否因插入而破坏了树的平衡性
若是,则找出最小不平衡子树
在保持二叉排序树特性的前提下
调整最小不平衡子树中各结点之间的链接关系
进行相应的旋转,使之成为新的平衡子树
6.多路查找树(muitl-way search tree)
(1)分析
对于 树 来说,一个结点只能存储一个元素
那么在元素非常多的时候,就会使得要么树的度非常大(结点拥有子树的个数的最大值)
要么树的高度非常大,甚至两者都必须足够大才行
这就使得内存存取外存次数非常多
这显然成了时间效率上的瓶颈
这迫使我们要打破每一个结点只存储一个元素的限制,为此引入了多路查找树的概念
(2)定义
其每一个结点的孩子树可以多于两个
且每一个结点处可以存储多个元素
由于它是查找树,因此所有元素之间存在某种特定的排序关系(即其是有序的)
(3)四中常见的多路查找树【2-3 树$2-3-4 树$B 树$B+ 树】的区别用法
https://blog.csdn.net/liu17234050/article/details/104270364
7.散列技术
(1)定义
是在记录的存储位置和它的关键字之间建立一个确定的对应关系
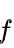
使得每个关键字 key 对应一个存储位置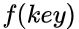
查找时,根据这个确定的对应关系找到给定值 key 的映射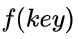
若查找集合中存在这个记录,则必定在 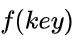 的位置上
的位置上
这里我们把这种对应关系 称为 散列函数,又称为 哈希(Hash)函数
称为 散列函数,又称为 哈希(Hash)函数
散列技术 既是一种存储方法,也是一种查找方法
通过 散列函数 计算关键字散列地址
并按此散列地址存储对应记录查找时
通过同样的 散列函数 计算关键字散列地址,按此地址访问对应记录
(2)散列表【哈希表(Hash table)】
采用散列技术将记录存储在一块连续的存储空间中
则这块连续存储空间称为 散列表 或 哈希表
(3)散列地址
那么关键字对应的记录存储位置我们称为 散列地址
(4)散列函数设计原则
A:计算简单:
散列函数的计算时间不应该超过其他查找技术与关键字比较的时间
B:散列地址分布均匀:
防止散列冲突最好的办法就是尽量让散列地址均匀地分布在存储空间中
这样可以保证存储空间的有效利用,并减少为处理冲突而耗费的时间
(5)构造散列函数的六种方法【直接定址法-数字分析法-平方取中法-折叠法-除留余数法-随机数法】
https://blog.csdn.net/liu17234050/article/details/104270709
(6)处理散列冲突的四种方法【开放定址法-再散列函数法-链地址法-公共溢出区法】
https://blog.csdn.net/liu17234050/article/details/104271343
(7)散列表性能分析
A:散列函数是否均匀:
散列函数的好坏直接影响着出现冲突的频繁程度
由于不同的散列函数对同一组随机的关键字,产生冲突的可能性是相同的
因此可以不考虑它对平均查找长度的影响
B:处理冲突的方法:
相同的关键字,相同的散列函数,但处理冲突的方法不同,会使得平均查找长度不同
比如线性探测处理冲突可能会产生堆积
显然就没有二次探测法好
而链地址法处理冲突不会产生任何堆积
因而具有更佳的平均查找性能
C:散列表的装填因子:
所谓的装填因子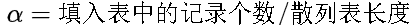
 标志着散列表的装满的程度
标志着散列表的装满的程度
当填入表中的记录越多
 就越大,产生冲突的可能性就越大
就越大,产生冲突的可能性就越大
比如假设散列表长度是 12,而填入表中的记录个数为 11,那么此时的装填因子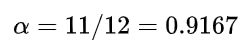
因此再填入最后一个关键字产生冲突的可能性就非常之大
也就是说,散列表的平均查找长度取决于装填因子
而不是取决于查找集合中的记录个数
不管记录个数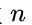 有多大
有多大
我们总可以选择一个合适的装填因子以便将平均查找长度限定在一个范围之内
此时我们散列查找的时间复杂度就真的是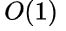
通常我们都是将散列表的空间设置得比查找集合大
此时虽然是浪费了一定的空间,但换来的是查找效率的大大提升
总的来说,还是非常值得的
==================================================================================
第十一章:内部排序
1.定义
排序 的依据是关键字之间的大小关
即对同一个记录集合(数据集合)
针对不同的关键字进行排序
可以得到不同的序列
(注:此处的关键字可以是记录的主关键字,也可以是此关键字,甚至是若干数据项的组合)
2.多个关键的排序最终都可以转化为单个关键字的排序
比如,现在要对学生的成绩进行排序
排序规则为按总分降序排序,若总分分数相同,按主科(语数英)总分数进行降序排序
直接的思路肯定是先进行总分排序,然后遇到总分相同的,就进行主科总分排序
但是还可以使用一个技巧来实现一次排序即可完成上述组合排序问题:
-
例如,把总分与主科总分当成字符串首尾拼接到一起
-
(注意如果主科成绩不够三位,则需在前面补零)
-
-
(比如:甲,乙两人的总分都为
753
,其中,
-
甲的理科总分为
229
,
-
而乙的理科总分为
236
,
-
-
则甲的拼接为:"753229",
-
乙的拼接为:"753236",
-
-
比较这两个拼接字符串即可直接(一次性)
-
直到乙排在甲前面(乙
>
甲)
3.排序的稳定性
假设
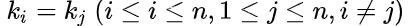
且在排序前的序列中 领先于
领先于 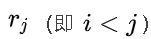
如果排序后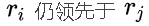
则称所用的排序方法是 稳定的
反之,若可能使得排序后的序列中  则称所用的排序方法是 不稳定的
则称所用的排序方法是 不稳定的
-
如下图所示:
-

4.内排序&外排序
据在排序过程中待排序的记录是否全部被放置在内存中,排序分为:内排序 和 外排序
(1)内排序
是在排序整个过程中,待排序的所有记录全部被放置在内存中
内排序分为:插入排序,交换排序,选择排序 和 归并排序
(2)外排序
是由于排序的记录个数太多,不能同时放置在内存
整个排序过程需要在内外存之间多次交互数据才能进行
5.影响内排序的三个方面
(1)时间性能
在内排序中,主要进行两种操作:比较 和 移动
A:比较
是指关键字之间的比较,这是做排序最基本的操作
B:移动
是指记录从一个位置移动到另一个位置
事实上,移动可以通过改变记录的存储方式来予以避免
高效率的内排序算法应该是具有尽可能少的关键字比较次数和尽可能少的记录移动次数
(2)辅助空间
辅助内存空间是除了存放待排序所占用的存储空间之外
执行算法所需要的其他存储空间
(3)算法的复杂性
此处指的是算法本身的复杂度
而不是指算法的时间复杂度
6.C 语言中的十四种内部排序算法
https://blog.csdn.net/liu17234050/article/details/104217658
==================================================================================
第十二章:外部排序
1.外部排序定义
外部排序指的是大文件的排序
即待排序的记录存储在外存储器上
待排序的文件无法一次装入内存,需要在内存和外部存储器之间进行多次数据交换,以达到排序整个文件的目的
外部排序最常用的算法是多路归并排序
即将原文件分解成多个能够一次性装入内存的部分
分别把每一部分调入内存完成排序
然后,对已经排序的子文件进行多路归并排序
2.外部排序的基本思路
1)按可用内存的大小
把外存上含有n个记录的文件分成若干个长度为L的子文件
把这些子文件依次读入内存,并利用有效的内部排序方法对它们进行排序
再将排序后得到的有序子文件重新写入外存
2)对这些有序子文件逐趟归并
使其逐渐由小到大,直至得到整个有序文件为止
举例:
假设有一个72KB的文件,其中存储了18K个整数,磁盘中物理块的大小为4KB,将文件分成18组,每组刚好4KB
首先通过18次内部排序,把18组数据排好序,得到初始的18个归并段R1~R18,每个归并段有1024个整数。
然后对这18个归并段使用4路平衡归并排序:
第1次归并:产生5个归并段
R11 R12 R13 R14 R15
其中
R11是由{R1,R2,R3,R4}中的数据合并而来
R12是由{R5,R6,R7,R8}中的数据合并而来
R13是由{R9,R10,R11,R12}中的数据合并而来
R14是由{R13,R14,R15,R16}中的数据合并而来
R15是由{R17,R18}中的数据合并而来
把这5个归并段的数据写入5个文件:
foo_1.dat foo_2.dat foo_3.dat foo_4.dat foo_5.dat
第2次归并:从第1次归并产生的5个文件中读取数据,合并,产生2个归并段
R21 R22
其中R21是由{R11,R12,R13,R14}中的数据合并而来
其中R22是由{R15}中的数据合并而来
把这2个归并段写入2个文件
bar_1.dat bar_2.dat
第3次归并:从第2次归并产生的2个文件中读取数据,合并,产生1个归并段
R31
R31是由{R21,R22}中的数据合并而来
把这个文件写入1个文件
foo_1.dat
此即为最终排序好的文件。
3.外部排序算法
(1)定义
外部排序算法,即要借助外部存储器对数据进行排序的算法,包括置换平衡归并排序算法、置换选择排序算法等
外部排序算法的实现,其实就是将体积大的数据分割为内存容得下的多份数据
然后分别使用内部排序算法进行排序,最后进行整合
和内部排序算法不同,外部排序算法的主要影响因素在于读写内存的次数
而当待排序的文件比内存的可使用容量还大时
文件无法一次性放到内存中进行排序
需要借助于外部存储器(例如硬盘、U盘、光盘)
(2)外部排序算法由两个阶段构成
(1)按照内存大小,将大文件分成若干长度为 l 的子文件(l 应小于内存的可使用容量)
然后将各个子文件依次读入内存,使用适当的内部排序算法对其进行排序
(排好序的子文件统称为“归并段”或者“顺段”)
将排好序的归并段重新写入外存,为下一个子文件排序腾出内存空间;
(2)对得到的顺段进行合并,直至得到整个有序的文件为止。
(3)2-路平衡归并
举例:
有一个含有 10000 个记录的文件,但是内存的可使用容量仅为 1000 个记录,毫无疑问需要使用外部排序算法,具体分为两步:
- 将整个文件其等分为 10 个临时文件(每个文件中含有 1000 个记录),然后将这 10 个文件依次进入内存,采取适当的内存排序算法对其中的记录进行排序,将得到的有序文件(初始归并段)移至外存。
- 对得到的 10 个初始归并段进行如图 1 的两两归并,直至得到一个完整的有序文件
如图 1所示有 10 个初始归并段到一个有序文件- 共进行了 4 次归并,每次都由 m 个归并段得到 ⌈m/2⌉ 个归并段
- 这种归并方式被称为 2-路平衡归并
注意:此例中采用了将文件进行等分的操作,还有不等分的算法
注意:在实际归并的过程中,由于内存容量的限制不能满足同时将 2 个归并段全部完整的读入内存进行归并
只能不断地取 2 个归并段中的每一小部分进行归并
通过不断地读数据和向外存写数据,直至 2 个归并段完成归并变为 1 个大的有序文件。
对于外部排序算法来说
影响整体排序效率的因素主要取决于读写外存的次数
即访问外存的次数越多,算法花费的时间就越多,效率就越低
计算机中处理数据的为中央处理器(CPU)
如若需要访问外存中的数据
只能通过将数据从外存导入内存,然后从内存中获取
同时由于内存读写速度快,外存读写速度慢的差异,更加影响了外部排序的效率
(4)5-路归并
对于同一个文件来说,对其进行外部排序时访问外存的次数同归并的次数成正比
即归并操作的次数越多,访问外存的次数就越多
图 1 中使用的是 2-路平衡归并的方式,举一反三
还可以使用 3-路归并、4-路归并甚至是 10-路归并的方式,图 2 为 5-路归并的方式:

对比 图 1 和图 2可以看出
对于 k-路平衡归并中 k 值得选择,增加 k 可以减少归并的次数
从而减少外存读写的次数,最终达到提高算法效率的目的
除此之外,一般情况下对于具有 m 个初始归并段进行 k-路平衡归并时
归并的次数为:s=⌊logkm ⌋(其中 s 表示归并次数)
从公式上可以判断出,想要达到减少归并次数从而提高算法效率的目的,可以从两个角度实现:
- 增加 k-路平衡归并中的 k 值;
- 尽量减少初始归并段的数量 m,即增加每个归并段的容量;
其增加 k 值的想法引申出了一种外部排序算法:多路平衡归并算法
增加数量 m 的想法引申出了另一种外部排序算法:置换-选择排序算法
4.多路平衡归并排序(胜者树、败者树)算法
(1)引入
但是经过计算得知,如果毫无限度地增加 k 值
虽然会减少读写外存数据的次数
但会增加内部归并的时间,得不偿失
为了避免在增加 k 值的过程中影响内部归并的效率
在进行 k-路归并时可以使用“败者树”来实现
该方法在增加 k 值时不会影响其内部归并的效率
(2)败者树实现内部归并
败者树是树形选择排序的一种变形,本身是一棵完全二叉树
(3)胜者树
在树形选择排序一节中
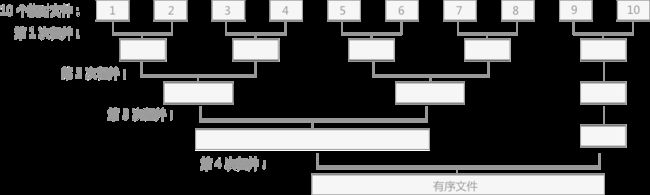
对于无序表{49,38,65,97,76,13,27,49}创建的完全二叉树如图 1 所示
构建此树的目的是选出无序表中的最小值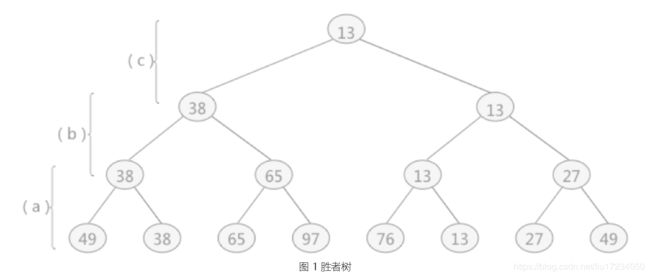
这棵树与败者树正好相反,是一棵“胜者树”
因为树中每个非终端结点(除叶子结点之外的其它结点)中的值都
表示的是左右孩子相比较后的较小值(谁最小即为胜者)
例如叶子结点 49 和 38 相对比,由于 38 更小
所以其双亲结点中的值保留的是胜者 38
然后用 38 去继续同上层去比较,一直比较到树的根结点
(4)败者树
而败者树恰好相反,其双亲结点存储的是左右孩子比较之后的失败者,而胜利者则继续同其它的胜者去比较
胜者树和败者树的区别就是:
胜者树中的非终端结点中存储的是胜利的一方
败者树中的非终端结点存储的是失败的一方
而在比较过程中,都是拿胜者去比较

如图 2 所示为一棵 5-路归并的败者树
其中 b0—b4 为树的叶子结点
分别为 5 个归并段中存储的记录的关键字
ls 为一维数组,表示的是非终端结点,其中存储的数值表示第几归并段(例如 b0 为第 0 个归并段)
ls[0] 中存储的为最终的胜者,表示当前第 3 归并段中的关键字最小
当最终胜者判断完成后
只需要更新叶子结点 b3 的值,即导入关键字 15
然后让该结点不断同其双亲结点所表示的关键字进行比较
败者留在双亲结点中,胜者继续向上比较
注意:为了防止在归并过程中某个归并段变为空
处理的办法为:
可以在每个归并段最后附加一个关键字为最大值的记录
这样当某一时刻选出的冠军为最大值时
表明 5 个归并段已全部归并完成
(因为只要还有记录,最终的胜者就不可能是附加的最大值)
(5)败者树内部归并的具体实现
-
#include
-
#define k 5
-
#define MAXKEY 10000
-
#define MINKEY -1
-
typedef
int LoserTree[k];
//表示非终端结点,由于是完全二叉树,所以可以使用一维数组来表示
-
typedef
struct {
-
int key;
-
}ExNode,External[k+
1];
-
External b;
//表示败者树的叶子结点
-
//a0-a4为5个初始归并段
-
int a0[]={
10,
15,
16};
-
int a1[]={
9,
18,
20};
-
int a2[]={
20,
22,
40};
-
int a3[]={
6,
15,
25};
-
int a4[]={
12,
37,
48};
-
//t0-t4用于模拟从初始归并段中读入记录时使用
-
int t0=
0,t1=
0,t2=
0,t3=
0,t4=
0;
-
//沿从叶子结点b[s]到根结点ls[0]的路径调整败者树
-
void Adjust(LoserTree ls,int s){
-
int t=(s+k)/
2;
-
while (t>
0) {
-
//判断每一个叶子结点同其双亲结点中记录的败者的值相比较,调整败者的值,其中 s 一直表示的都是胜者
-
if (b[s].key>b[ls[t]].key) {
-
int swap=s;
-
s=ls[t];
-
ls[t]=swap;
-
}
-
t=t/
2;
-
}
-
//最终将胜者的值赋给 ls[0]
-
ls[
0]=s;
-
}
-
//创建败者树
-
void CreateLoserTree(LoserTree ls){
-
b[k].key=MINKEY;
-
//设置ls数组中败者的初始值
-
for (
int i=
0; i
-
ls[i]=k;
-
}
-
//对于每一个叶子结点,调整败者树中非终端结点中记录败者的值
-
for (
int i=k
-1; i>=
0; i--) {
-
Adjust(ls, i);
-
}
-
}
-
//模拟从外存向内存读入初始归并段中的每一小部分
-
void input(int i){
-
switch (i) {
-
case
0:
-
if (t0<
3) {
-
b[i].key=a0[t0];
-
t0++;
-
}
else{
-
b[i].key=MAXKEY;
-
}
-
break;
-
case
1:
-
if (t1<
3) {
-
b[i].key=a1[t1];
-
t1++;
-
}
else{
-
b[i].key=MAXKEY;
-
}
-
break;
-
case
2:
-
if (t2<
3) {
-
b[i].key=a2[t2];
-
t2++;
-
}
else{
-
b[i].key=MAXKEY;
-
}
-
break;
-
case
3:
-
if (t3<
3) {
-
b[i].key=a3[t3];
-
t3++;
-
}
else{
-
b[i].key=MAXKEY;
-
}
-
break;
-
case
4:
-
if (t4<
3) {
-
b[i].key=a4[t4];
-
t4++;
-
}
else{
-
b[i].key=MAXKEY;
-
}
-
break;
-
default:
-
break;
-
}
-
}
-
//败者树的建立及内部归并
-
void K_Merge(LoserTree ls){
-
//模拟从外存中的5个初始归并段中向内存调取数据
-
for (
int i=
0; i<=k; i++) {
-
input(i);
-
}
-
//创建败者树
-
CreateLoserTree(ls);
-
//最终的胜者存储在 is[0]中,当其值为 MAXKEY时,证明5个临时文件归并结束
-
while (b[ls[
0]].key!=MAXKEY) {
-
//输出过程模拟向外存写的操作
-
printf(
"%d ",b[ls[
0]].key);
-
//继续读入后续的记录
-
input(ls[
0]);
-
//根据新读入的记录的关键字的值,重新调整败者树,找出最终的胜者
-
Adjust(ls,ls[
0]);
-
}
-
}
-
int main(int argc, const char * argv[]) {
-
LoserTree ls;
-
K_Merge(ls);
-
return
0;
-
}
运行结果:
6 9 10 12 15 15 16 18 20 20 22 25 37 40 48
5.置换-选择排序算法
1.引入
上一节介绍了增加 k-路归并排序中的 k 值来提高外部排序效率的方法
而除此之外,还有另外一条路可走
即减少初始归并段的个数,也就是本章第一节中提到的减小 m 的值
m 的求值方法为:m=⌈n/l⌉(n 表示为外部文件中的记录数,l 表示初始归并段中包含的记录数)
如果要想减小 m 的值,在外部文件总的记录数 n 值一定的情况下,只能增加每个归并段中所包含的记录数 l
而对于初始归并段的形成,就不能再采用上一章所介绍的内部排序的算法
因为所有的内部排序算法正常运行的前提是所有的记录都存在于内存中
而内存的可使用空间是一定的,如果增加 l 的值,内存是盛不下的
(2)图解
例如已知初始文件中总共有 24 个记录,假设内存工作区最多可容纳 6 个记录
按照之前的选择排序算法最少也只能分为 4 个初始归并段
而如果使用置换—选择排序
可以实现将 24 个记录分为 3 个初始归并段,如图 1 所示:

(3)操作过程
置换—选择排序算法的具体操作过程为:
- 首先从初始文件中输入 6 个记录到内存工作区中;
- 从内存工作区中选出关键字最小的记录,将其记为 MINIMAX 记录;
- 然后将 MINIMAX 记录输出到归并段文件中;
- 此时内存工作区中还剩余 5 个记录,若初始文件不为空,则从初始文件中输入下一个记录到内存工作区中;
- 从内存工作区中的所有比 MINIMAX 值大的记录中选出值最小的关键字的记录,作为新的 MINIMAX 记录;
- 重复过程 3—5,直至在内存工作区中选不出新的 MINIMAX 记录为止,由此就得到了一个初始归并段;
- 重复 2—6,直至内存工作为空,由此就可以得到全部的初始归并段。
拿图 1 中的初始文件为例,首先输入前 6 个记录到内存工作区,其中关键字最小的为 29,所以选其为 MINIMAX 记录,同时将其输出到归并段文件中,如下图所示:

此时初始文件不为空,所以从中输入下一个记录 14 到内存工作区中,然后从内存工作区中的比 29 大的记录中,选择一个最小值作为新的 MINIMAX 值输出到 归并段文件中,如下图所示:

初始文件还不为空,所以继续输入 61 到内存工作区中,从内存工作区中的所有关键字比 38 大的记录中,选择一个最小值作为新的 MINIMAX 值输出到归并段文件中,如下图所示:

如此重复性进行,直至选不出 MINIMAX 值为止,如下图所示:

当选不出 MINIMAX 值时,表示一个归并段已经生成
则开始下一个归并段的创建,创建过程同第一个归并段一样
在上述创建初始段文件的过程中,需要不断地在内存工作区中选择新的 MINIMAX 记录
即选择不小于旧的 MINIMAX 记录的最小值
此过程需要利用“败者树”来实现
同上一节所用到的败者树不同的是,在不断选择新的 MINIMAX 记录时
为了防止新加入的关键字值小的的影响
每个叶子结点附加一个序号位
当进行关键字的比较时,先比较序号,序号小的为胜者
序号相同的关键字值小的为胜者
(4)置换选择排序算法的具体实现
-
#include
-
#define MAXKEY 10000
-
#define RUNEND_SYMBOL 10000 // 归并段结束标志
-
#define w 6 // 内存工作区可容纳的记录个数
-
#define N 24 // 设文件中含有的记录的数量
-
typedef
int KeyType;
// 定义关键字类型为整型
-
// 记录类型
-
typedef
struct{
-
KeyType key;
// 关键字项
-
}RedType;
-
typedef
int LoserTree[w];
// 败者树是完全二叉树且不含叶子,可采用顺序存储结构
-
typedef
struct
-
{
-
RedType rec;
/* 记录 */
-
KeyType key;
/* 从记录中抽取的关键字 */
-
int rnum;
/* 所属归并段的段号 */
-
}RedNode, WorkArea[w];
-
// 从wa[q]起到败者树的根比较选择MINIMAX记录,并由q指示它所在的归并段
-
void Select_MiniMax(LoserTree ls,WorkArea wa,int q){
-
int p, s, t;
-
// ls[t]为q的双亲节点,p作为中介
-
-
for(t = (w+q)/
2,p = ls[t]; t >
0;t = t/
2,p = ls[t]){
-
// 段号小者 或者 段号相等且关键字更小的为胜者
-
if(wa[p].rnum < wa[q].rnum || (wa[p].rnum == wa[q].rnum && wa[p].key < wa[q].key)){
-
s=q;
-
q=ls[t];
//q指示新的胜利者
-
ls[t]=s;
-
}
-
}
-
ls[
0] = q;
// 最后的冠军
-
}
-
//输入w个记录到内存工作区wa,建得败者树ls,选出关键字最小的记录,并由s指示其在wa中的位置。
-
void Construct_Loser(LoserTree ls, WorkArea wa, FILE *fi){
-
int i;
-
for(i =
0; i < w; ++i){
-
wa[i].rnum = wa[i].key = ls[i] =
0;
-
}
-
for(i = w -
1; i >=
0; --i){
-
fread(&wa[i].rec,
sizeof(RedType),
1, fi);
// 输入一个记录
-
wa[i].key = wa[i].rec.key;
// 提取关键字
-
wa[i].rnum =
1;
// 其段号为"1"
-
Select_MiniMax(ls,wa,i);
// 调整败者树
-
}
-
}
-
// 求得一个初始归并段,fi为输入文件指针,fo为输出文件指针。
-
void get_run(LoserTree ls,WorkArea wa,int rc,int *rmax,FILE *fi,FILE *fo){
-
int q;
-
KeyType minimax;
-
// 选得的MINIMAX记录属当前段时
-
while(wa[ls[
0]].rnum == rc){
-
q = ls[
0];
// q指示MINIMAX记录在wa中的位置
-
minimax = wa[q].key;
-
// 将刚选得的MINIMAX记录写入输出文件
-
fwrite(&wa[q].rec,
sizeof(RedType),
1, fo);
-
// 如果输入文件结束,则虚设一条记录(属"rmax+1"段)
-
if(feof(fi)){
-
wa[q].rnum = *rmax+
1;
-
wa[q].key = MAXKEY;
-
}
else{
// 输入文件非空时
-
// 从输入文件读入下一记录
-
fread(&wa[q].rec,
sizeof(RedType),
1,fi);
-
wa[q].key = wa[q].rec.key;
// 提取关键字
-
if(wa[q].key < minimax){
-
// 新读入的记录比上一轮的最小关键字还小,则它属下一段
-
*rmax = rc+
1;
-
wa[q].rnum = *rmax;
-
}
else{
-
// 新读入的记录大则属当前段
-
wa[q].rnum = rc;
-
}
-
}
-
// 选择新的MINIMAX记录
-
Select_MiniMax(ls, wa, q);
-
}
-
-
}
-
//在败者树ls和内存工作区wa上用置换-选择排序求初始归并段
-
void Replace_Selection(LoserTree ls, WorkArea wa, FILE *fi, FILE *fo){
-
int rc, rmax;
-
RedType j;
-
j.key = RUNEND_SYMBOL;
-
// 初建败者树
-
Construct_Loser(ls, wa, fi);
-
rc = rmax =
1;
//rc指示当前生成的初始归并段的段号,rmax指示wa中关键字所属初始归并段的最大段号
-
-
while(rc <= rmax){
// "rc=rmax+1"标志输入文件的置换-选择排序已完成
-
// 求得一个初始归并段
-
get_run(ls, wa, rc, &rmax, fi, fo);
-
fwrite(&j,
sizeof(RedType),
1,fo);
//将段结束标志写入输出文件
-
rc = wa[ls[
0]].rnum;
//设置下一段的段号
-
}
-
}
-
void print(RedType t){
-
printf(
"%d ",t.key);
-
}
-
int main(){
-
RedType a[N]={
51,
49,
39,
46,
38,
29,
14,
61,
15,
30,
1,
48,
52,
3,
63,
27,
4,
13,
89,
24,
46,
58,
33,
76};
-
RedType b;
-
FILE *fi,*fo;
//输入输出文件
-
LoserTree ls;
// 败者树
-
WorkArea wa;
// 内存工作区
-
int i, k;
-
fo = fopen(
"ori",
"wb");
//准备对 ori 文本文件进行写操作
-
//将数组 a 写入大文件ori
-
fwrite(a,
sizeof(RedType), N, fo);
-
fclose(fo);
//关闭指针 fo 表示的文件
-
fi = fopen(
"ori",
"rb");
//准备对 ori 文本文件进行读操作
-
printf(
"文件中的待排序记录为:\n");
-
for(i =
1; i <= N; i++){
-
// 依次将文件ori的数据读入并赋值给b
-
fread(&b,
sizeof(RedType),
1,fi);
-
print(b);
-
}
-
printf(
"\n");
-
rewind(fi);
// 使fi的指针重新返回大文件ori的起始位置,以便重新读入内存,产生有序的子文件。
-
fo = fopen(
"out",
"wb");
-
// 用置换-选择排序求初始归并段
-
Replace_Selection(ls, wa, fi, fo);
-
fclose(fo);
-
fclose(fi);
-
fi = fopen(
"out",
"rb");
-
printf(
"初始归并段各为:\n");
-
do{
-
k = fread(&b,
sizeof(RedType),
1, fi);
//读 fi 指针指向的文件,并将读的记录赋值给 b,整个操作成功与否的结果赋值给 k
-
if(k ==
1){
-
if(b.key ==MAXKEY){
//当其值等于最大值时,表明当前初始归并段已经完成
-
printf(
"\n\n");
-
continue;
-
}
-
print(b);
-
}
-
}
while(k ==
1);
-
return
0;
-
}
运行结果为:
-
文件中的待排序记录为:
-
51
49
39
46
38
29
14
61
15
30
1
48
52
3
63
27
4
13
89
24
46
58
33
76
-
初始归并段各为:
-
29
38
39
46
49
51
61
-
-
1
3
14
15
27
30
48
52
63
89
-
-
4
13
13
24
33
46
58
76
6.最佳归并树
(1)思考
本节带领大家思考一个问题:
无论是通过等分还是置换-选择排序得到的归并段
如何设置它们的归并顺序
可以使得对外存的访问次数降到最低?
(2)举例参考
例如,现有通过置换选择排序算法所得到的 9 个初始归并段
其长度分别为:9,30,12,18,3,17,2,6,24
在对其采用 3-路平衡归并的方式时可能出现如图 1 所示的情况:

提示:图 1 中的叶子结点表示初始归并段,各自包含记录的长度用结点的权重来表示;非终端结点表示归并后的临时文件
假设在进行平衡归并时,操作每个记录都需要单独进行一次对外存的读写
那么图 1 中的归并过程需要对外存进行读或者写的次数为:
(9+30+12+18+3+17+2+6+24)*2*2=484(图 1 中涉及到了两次归并,对外存的读和写各进行 2 次)
从计算结果上看,对于图 1 中的 3 叉树来讲,其操作外存的次数恰好是树的带权路径长度的 2 倍
对于如何减少访问外存的次数的问题,就等同于考虑如何使 k-路归并所构成的 k 叉树的带权路径长度最短
若想使树的带权路径长度最短,就是构造赫夫曼树【只要其带权路径长度最短,亦可以称为赫夫曼树】
若对上述 9 个初始归并段构造一棵赫夫曼树作为归并树,如图 2 所示:

依照图 2 所示,其对外存的读写次数为:
(2*3+3*3+6*3+9*2+12*2+17*2+18*2+24*2+30)*2=446
通过以构建赫夫曼树的方式构建归并树,使其对读写外存的次数降至最低
(k-路平衡归并,需要选取合适的 k 值,构建赫夫曼树作为归并树)
所以称此归并树为最佳归并树
7.“虚段”的归并树
(1)引入
上述图 2 中所构建的为一颗真正的 3叉树(树中各结点的度不是 3 就是 0)
而若 9 个初始归并段改为 8 个,在做 3-路平衡归并的时候就需要有一个结点的度为 2
对于具体设置哪个结点的度为 2,为了使总的带权路径长度最短,正确的选择方法是:附加一个权值为 0 的结点(称为“虚段”)
例如图 2 中若去掉权值为 30 的结点,其附加虚段的最佳归并树如图 3 所示:
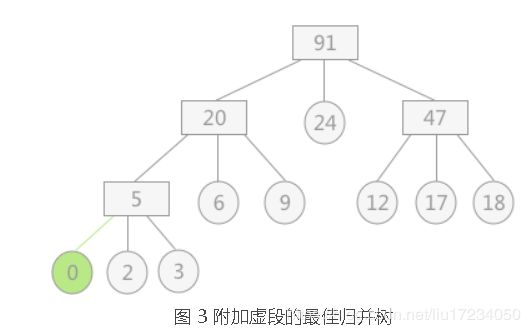
注意:虚段的设置只是为了方便构建赫夫曼树,在构建完成后虚段自动去掉即可
(2)如何判断是否需要增加虚段,以及增加多少虚段
-
在一般情况下,对于 k–路平衡归并来说
-
-
若 (m-
1)
MOD(k-
1)=
0,则不需要增加虚段
-
-
否则需附加 k-(m-
1)
MOD(k-
1)-
1 个虚段
为了提高整个外部排序的效率,本章分别从以上两个方面对外部排序进行了优化:
- 在实现将初始文件分为 m 个初始归并段时,为了尽量减小 m 的值,采用置换-选择排序算法,可实现将整个初始文件分为数量较少的长度不等的初始归并段
- 同时在将初始归并段归并为有序完整文件的过程中,为了尽量减少读写外存的次数,采用构建最佳归并树的方式,对初始归并段进行归并,而归并的具体实现方法是采用败者树的方式
==================================================================================
十三:文件
https://blog.csdn.net/liu17234050/article/details/104297177
==================================================================================