【数据结构与算法】1.2 数据结构与算法分析
先来看一道题:
在一个1000000个元素的列表中,随机检索一个数据,请问需要多长时间?
import timeit
import random
arr = [i for i in range(1000000)]
target = random.choice(arr)
print('target:\t',target)
def traverse(array,target):
'''随机查找'''
for number in array:
if target == number:
return number
return False
def binary_search_normal(array,data):
'''二分查找法 - 非递归实现'''
start, end = 0, len(array) - 1
while start <= end:
mid_index = (start + end) // 2
if array[mid_index] == data:
return array.index(data)
if data > array[mid_index]:
start = mid_index + 1
else:
end = mid_index - 1
return False
setup1 = """
from __main__ import traverse;
import random;
array = [i for i in range(1000000)];
target = random.choice(array)
"""
setup2 = '''
from __main__ import binary_search_normal;
import random;
arr = [i for i in range(1000000)];
target = random.choice(array)
'''
timer1 = timeit.Timer(stmt = "traverse(array,target)",
setup = setup1)
timer2 = timeit.Timer(stmt = "binary_search_normal(array,target)",
setup = setup2)
print("traverse: %f" % timer1.timeit(number = 100))
print("binary : %f" % timer2.timeit(number = 100))
输出结果如下
traverse:1.750101
binary:0.2475221.2.1 算法效率衡量
执行时间反映算法效率
对于同一问题,我们给出了两种解决算法,在两种算法的实现中,我们对程序执行的时间进行了测算,发现两段程序执行的时间相差悬殊(1.750101秒相比于0.247522秒),由此我们可以得出结论:实现算法的执行时间可以反映出算法的效率,即算法的优劣。
单靠时间值绝对可信吗?
假设我们将第二次尝试的算法程序运行在一台配置古老性能低下的计算机中,情况会如何?很可能运行的时间并不会比在我们的电脑中运行算法一的1.750101秒快多少。
单纯依靠运行的时间来比较算法的优劣并不一定是客观准确的!
程序的运行离不开计算机环境(包括硬件和操作系统),这些客观原因会影响程序运行的速度并反映在程序的执行时间上,那么如何才能客观的评价一个算法的优劣呢?
1.2.2 时间复杂度与“大O计法”
我们假定计算机执行算法每一个基本操作的时间是固定的一个时间单位,那么有多少个基本操作就代表会花费多少时间单位,显然对于不同的机器环境而言,确切的单位时间是不同的,但是对于算法进行多少个基本操作(即花费多少时间单位)在规模数量级上却是相同的,由此可以忽略机器环境的影响而客观的反映算法的时间效率。
对于算法的时间效率,我们可以用“大O记法”来表示。
“大O记法”:对于单调的整数函数f,如果存在一个整数函数g和实常数c>0,使得对于充分大的n总有f(n)<=c * g(n),就说函数g是f的一个渐进函数(忽略常数),记为f(n)=O(g(n))。也就是说,在趋向无穷的极限意义下,函数f的增长速度受到函数g的约束,也即函数f与函数g特征相似。
时间复杂度:假设存在函数g,使得算法A处理规模为n的问题示例所用时间为T(n)= O(g(n)),则称O(g(n))为算法A的渐进时间复杂度,简称时间复杂度,记为T(n)
如何理解“大O记法”
对于算法进行特别具体的细致分析虽然很好,但在实践中的实际价值有限,对于算法的时间性质和空间性质,最重要的是其数量级和趋势,这些是分析算法效率的重要部分。而计量算法基本操作数量的规模函数中那些常量因子可以忽略不计。例如,可以认为![]() 和
和![]() 属于同一个量级,如果两个算法处理同样规模实例的代价分别为这两个函数,就认为他们的效率差不多,都为
属于同一个量级,如果两个算法处理同样规模实例的代价分别为这两个函数,就认为他们的效率差不多,都为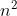 级。
级。
常见时间复杂度
| 执行次数函数举例 | 阶 | 非正式术语 |
| 1 2 | O(1) | 常数阶 |
| 2n+3 | O(n) |
线性阶 |
| O() |
平方阶 | |
5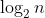 +20 +20 |
O(logn) | 对数阶 |
| 2n+3n+19 |
O(nlogn) | nlogn阶 |
O( ) ) |
立方阶 | |
| O(2n) | 指数阶 |
注意,经常将(以2为底的对数) 简写成logn
常见时间复杂度之间的关系:
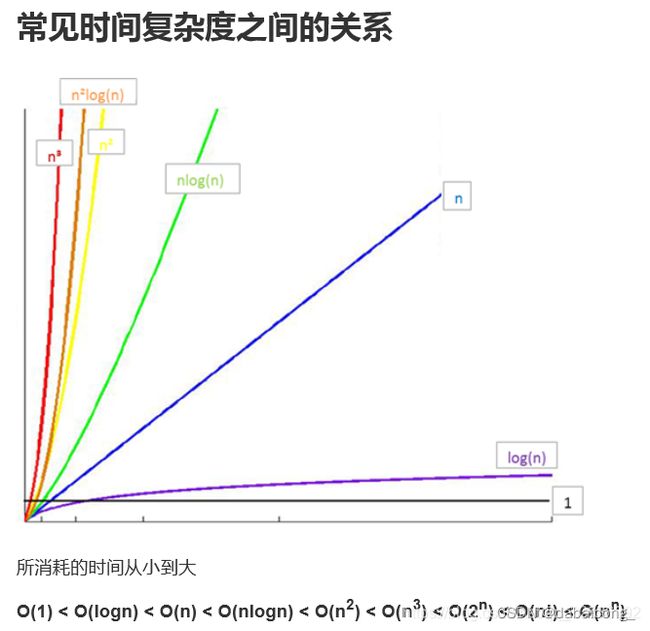
O(1) < O(logn) < O(n) < O(n) 分析算法时,存在几种可能的考虑: 算法完成工作最少需要多少基本操作:即最优时间复杂度 算法完成工作最多需要多少基本操作:即最坏时间复杂度 算法完成工作平均需要多少基本操作,即平均时间复杂度 对于最优时间复杂度,其价值不大,因为他没有提供什么有用信息,其反映的只是最乐观最理想的情况,没有参考价值。 对于最坏时间复杂度,提供了一种保证,表明算法在此种程度的基本操作中一定能完成工作。 对于平均时间复杂度,是对算法的一个全面评价,因此他完整全面的反映了这个算法的性质,但另一方面,这种衡量并没有保证,不是每个计算都能在这个基本操作内完成。而且,对于平均情况的计算,也会因为应用算法的实例分布可能并不均匀而难以计算。 因此,我们主要关注算法的最坏情况,亦即最坏时间复杂度。 1、基本操作,即只有常数项,认为其时间复杂度为O(1) 2、顺序结构,时间复杂度按加法进行计算 3、循环结构,时间复杂度按乘法进行计算 4、分支结构,时间复杂度取最大值 5、判断一个算法的效率时,往往只需要关注操作数量的最高次项,其他次要项和常数项可以忽略 6、在没有特殊说明时,我们所分析的算法的时间复杂度都是指最坏时间复杂度 类似于时间复杂度的讨论,一个算法的空间复杂度S(n),定义为该算法所耗费的存储空间,它也是问题规模n的函数。 渐进空间复杂度也常常简称为空间复杂度。 空间复杂度(SpaceComplexity)是对一个算法在运行过程中临时占用存储空间大小的量度。 算法的时间复杂度和空间复杂度合称为算法的复杂度。 timeit 模块 timeit模块可以用来测试一小段python代码的执行速度。 Timer是测量小段代码执行速度的类。 stmt参数是要测试的代码语句(statment); setup参数是运行代码时需要的设置; timer参数是一个定时器函数,与平台有关。 Timer类中测试语句执行速度的对象方法,number参数是测试代码时的测试次数,默认为1000000次。方法返回执行代码的平均耗时,一个float类型的秒数,最坏时间复杂度
时间复杂度的几条基本计算规则
空间复杂度
1.2.3 内置类型性能分析
class timeit.Timer(stmt = 'pass',setup = 'pass',timer = timeit.Timer.timeit(number = 1000000)