多库多表场景下使用 Amazon EMR CDC 实时入湖最佳实践
一、前言CDC(Change Data Capture) 从广义上讲所有能够捕获变更数据的技术都可以称为 CDC,但本篇文章中对 CDC 的定义限定为以非侵入的方式实时捕获数据库的变更数据。例如:通过解析 MySQL 数据库的 Binlog 日志捕获变更数据,而不是通过 SQL Query 源表捕获变更数据。 Hudi 作为最热的数据湖技术框架之一, 用于构建具有增量数据处理管道的流式数据湖。其核心的能力包括对象存储上数据行级别的快速更新和删除,增量查询(Incremental queries,Time Travel),小文件管理和查询优化(Clustering,Compactions,Built-in metadata),ACID 和并发写支持。Hudi 不是一个 Server,它本身不存储数据,也不是计算引擎,不提供计算能力。其数据存储在 S3(也支持其它对象存储和 HDFS),Hudi 来决定数据以什么格式存储在 S3(Parquet,Avro,…), 什么方式组织数据能让实时摄入的同时支持更新,删除,ACID 等特性。Hudi 通过 Spark,Flink 计算引擎提供数据写入, 计算能力,同时也提供与 OLAP 引擎集成的能力,使 OLAP 引擎能够查询 Hudi 表。从使用上看 Hudi 就是一个 JAR 包,启动 Spark, Flink 作业的时候带上这个 JAR 包即可。Amazon EMR 上的 Spark,Flink,Presto ,Trino 原生集成 Hudi, 且 EMR 的 Runtime 在 Spark,Presto 引擎上相比开源有2倍以上的性能提升。 在多库多表的场景下(比如:百级别库表),当我们需要将数据库(mysql,postgres,sqlserver,oracle,mongodb 等)中的数据通过 CDC 的方式以分钟级别(1minute+)延迟写入 Hudi,并以增量查询的方式构建数仓层次,对数据进行实时高效的查询分析时。我们要解决三个问题,第一,如何使用统一的代码完成百级别库表 CDC 数据并行写入 Hudi,降低开发维护成本。第二,源端 Schema 变更如何同步到 Hudi 表。第三,使用 Hudi 增量查询构建数仓层次比如 ODS->DWD->DWS (各层均是 Hudi 表),DWS 层的增量聚合如何实现。本篇文章推荐的方案是: 使用 Flink CDC DataStream API (非 SQL)先将 CDC 数据写入 Kafka,而不是直接通过 Flink SQL 写入到 Hudi 表,主要原因如下,第一,在多库表且 Schema 不同的场景下,使用 SQL 的方式会在源端建立多个 CDC 同步线程,对源端造成压力,影响同步性能。第二,没有 MSK 做 CDC 数据上下游的解耦和数据缓冲层,下游的多端消费和数据回溯比较困难。CDC 数据写入到 MSK 后,推荐使用 Spark Structured Streaming DataFrame API 或者 Flink StatementSet 封装多库表的写入逻辑,但如果需要源端 Schema 变更自动同步到 Hudi 表,使用 Spark Structured Streaming DataFrame API 实现更为简单,使用 Flink 则需要基于 HoodieFlinkStreamer 做额外的开发。Hudi 增量 ETL 在 DWS 层需要数据聚合的场景的下,可以通过 Flink Streaming Read 将 Hudi 作为一个无界流,通过 Flink 计算引擎完成数据实时聚合计算写入到 Hudi 表。
| 亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库! |
二、架构设计与解析
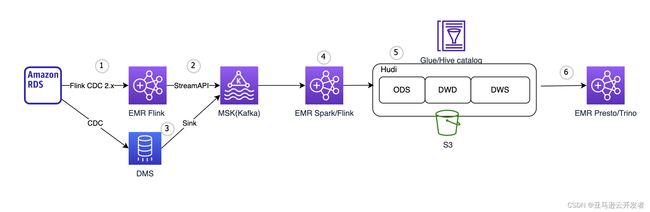
2.1 CDC 数据实时写入 MSK
图中标号1,2是将数据库中的数据通过 CDC 方式实时发送到 MSK (Amazon 托管的 Kafka 服务)。flink-cdc-connectors 是当前比较流行的 CDC 开源工具。它内嵌debezium 引擎,支持多种数据源,对于 MySQL 支持 Batch 阶段(全量同步阶段)并行,无锁,Checkpoint (可以从失败位置恢复,无需重新读取,对大表友好)。支持 Flink SQL API 和 DataStream API,这里需要注意的是如果使用 SQL API 对于库中的每张表都会单独创建一个链接,独立的线程去执行 binlog dump。如果需要同步的表比较多,会对源端产生较大的压力。在需要整库同步表非常多的场景下,应该使用 DataStream API 写代码的方式只建一个 binlog dump 同步所有需要的库表。另一种场景是如果只同步分库分表的数据,比如 user 表做了分库,分表,其表 Schema 都是一样的,Flink CDC 的 SQL API 支持正则匹配多个库表,这时使用 SQL API 同步依然只会建立一个 binlog dump 线程。需要说明的是通过 Flink CDC 可以直接将数据 Sink 到 Hudi, 中间无需 MSK,但考虑到上下游的解耦,数据的回溯,多业务端消费,多表管理维护,依然建议 CDC 数据先到 MSK,下游再从 MSK 接数据写入 Hudi。
2.2 CDC 工具对比
图中标号3,除了 flink-cdc-connectors 之外,DMS (Amazon Database Migration Services) 是 Amazon 托管的数据迁移服务,提供多种数据源 (mysql,oracle,sqlserver,postgres,mongodb,documentdb 等)的 CDC 支持,支持可视化的 CDC 任务配置,运行,管理,监控。因此可以选择 DMS 作为 CDC 的解析工具,DMS 支持将 MSK 或者自建 Kafka 作为数据投递的目标,所以 CDC 实时同步到 MSK 通过 DMS 可以快速可视化配置管理。当然除了 DMS 之外还有很多开源的 CDC 工具,也可以完成 CDC 的同步工作,但需要在 EC2 上搭建相关服务。下图列出了 CDC 工具的对比项,供大家参考

2.3 Spark Structured Streaming 多库表并行写 Hudi 及 Schema 变更
图中标号4,CDC 数据到了 MSK 之后,可以通过 Spark/Flink 计算引擎消费数据写入到 Hudi 表,我们把这一层我们称之为 ODS 层。无论 Spark 还是 Flink 都可以做到数据 ODS 层的数据落地,使用哪一个我们需要综合考量,这里阐述一些相对重要的点。首先对于 Spark 引擎,我们一定是使用 Spark Structured Streaming 消费 MSK 写入 Hudi,由于可以使用 DataFrame API 写 Hudi, 因此在 Spark 中可以方便的实现消费 CDC Topic 并根据其每条数据中的元信息字段(数据库名称,表名称等)在单作业内分流写入不同的 Hudi 表,封装多表并行写入逻辑,一个 Job 即可实现整库多表同步的逻辑。样例代码截图如下,完整代码点击 Github 获取
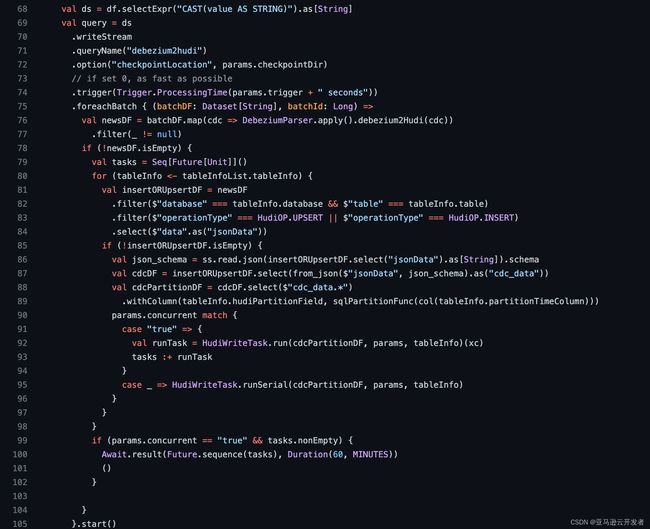
我们知道 CDC 数据中是带着 I(insert)、U(update)、D(delete) 信息的, 不同的 CDC 工具数据格式不同,但要表达的含义是一致的。使用 Spark 写入 Hudi 我们主要关注 U、D 信息,数据带着U信息表示该条数据是一个更新操作,对于 Hudi 而言只要设定源表的主键为 Hudi 的 recordKey,同时根据需求场景设定 precombineKey 即可。这里对 precombineKey 做一个说明,它表示的是当数据需要更新时(recordKey 相同), 默认选择两条数据中 precombineKey 的大保留在 Hudi 中。其实 Hudi 有非常灵活的 Payload 机制,通过参数 hoodie.datasource.write.payload.class 可以选择不同的 Payload 实现,比如 Partial Update (部分字段更新)的Payload实现 OverwriteNonDefaultsWithLatestAvroPayload,也可以自定义 Payload 实现类,它核心要做的就是如何根据 precombineKey 指定的字段更新数据。所以对于 CDC 数据 Sink Hudi 而言,我们需要保证上游的消息顺序,只要我们表中有能判断哪条数据是最新的数据的字段即可,那这个字段在 MySQL 中往往我们设计成数据更新时间 modify_time timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP 。如果没有类似字段,建议定义设计规范加上这个字段,否则就必须保证数据有序(这会给架构设计和性能带来更多的阻力),不然数据在 Hudi 中 Updata 的结果可能就是错的。对于带着 D 信息的数据,它表示这条数据在源端被删除,Hudi 是提供删除能力的,其中一种方式是当一条数据中包含 _hoodie_is_deleted 字段,且值为 true 是,Hudi 会自动删除此条数据,这在 Spark Structured Streaming 代码中很容易实现,只需在 map 操作实现添加一个字段且当数据中包含 D 信息设定字段值为 true 即可。
2.4 Flink StatementSet 多库表 CDC 并行写 Hudi
对于使用 Flink 引擎消费 MSK 中的 CDC 数据落地到 ODS 层 Hudi 表,如果想要在一个 JOB 实现整库多张表的同步,Flink StatementSet 来实现通过一个 Kafka 的 CDC Source 表,根据元信息选择库表 Sink 到 Hudi 中。但这里需要注意的是由于 Flink 和 Hudi 集成,是以 SQL 方式先创建表,再执行 Insert 语句写入到该表中的,如果需要同步的表有上百之多,封装一个自动化的逻辑能够减轻我们的工作,你会发现 SQL 方式写入 Hudi 虽然对于单表写入使用上很方便,不用编程只需要写 SQL 即可,但也带来了一些限制,由于写入 Hudi 时是通过 SQL 先建表,Schema 在建表时已将定义,如果源端 Schema 变更,通过 SQL 方式是很难实现下游 Hudi 表 Schema 的自动变更的。虽然在 Hudi 的官网并未提供 Flink DataStream API 写入 Hudi 的例子,但 Flink 写入 Hudi 是可以通过 HoodieFlinkStreamer 以 DataStream API 的方式实现,在 Hudi 源码中可以找到。因此如果想要更加灵活简单的实现多表的同步,以及 Schema 的自动变更,需要自行参照 HoodieFlinkStreamer 代码以 DataStream API 的方式写 Hudi。对于 I,U,D 信息,Flink 的 debezium ,maxwell,canal format 会直接将消息解析为 Flink 的 changelog 流,换句话说就是 Flink 会将 I,U,D 操作直接解析成 Flink 内部的数据结构 RowData,直接 Sink 到 Hudi 表即可,我们同样需要在 SQL 中设定 recordKey,precombineKey,也可以设定 Payload class 的不同实现类。
2.5 Flink Streaming Read 模式读 Hudi 实现 ODS 层聚合
图中标号5,数据通过 Spark/Flink 落地到 ODS 层后,我们可能需要构建 DWD 和 DWS 层对数据做进一步的加工处理,(DWD 和 DWS 并非必须的,根据你的场景而定,你可以直接让 OLAP 引擎查询 ODS 层的 Hudi 表)我们希望能够使用到 Hudi 的增量查询能力,只查询变更的数据来做后续 DWD 和 DWS 的 ETL,这样能够加速构建同时减少资源消耗。对于 Spark 引擎,在 DWD 层如果仅仅是对数据做 map,fliter 等相关类型操作,是可以使用增量查询的,但如果 DWD 层的构建有 Join 操作,是无法通过增量查询实现的,只能全表(或者分区)扫描。DWS 层的构建如果聚合类型的操作没有去重,窗口类型的操作,只是 SUM, AVG,MIN, MAX 等类型的操作,可以通过增量查询之后和目标表做 Merge 实现,反之,只能全表(或者分区)扫描。 对于 Flink 引擎来构建 DWD 和 DWS, 由于 Flink 支持 Hudi 表的 streaming read, 在 SQL 设定 read.streaming.enabled= true,changelog.enabled=true 等相关流式读取的参数即可。设定后 Flink 把 Hudi 表当做了一个无界的 changelog 流表,无论怎样做 ETL 都是支持的, Flink 会自身存储状态信息,整个 ETL 的链路是流式的。
2.6 OLAP 引擎查询 Hudi 表
图中标号6, EMR Hive/Presto/Trino 都可以查询 Hudi 表,但需要注意的是不同引擎对于查询的支持是不同的,参见官网,这些引擎对于 Hudi 表只能查询,不能写入。 关于 Schema 的自动变更,首先 Hudi 自身是支持 Schema Evolution,我们想要做到源端 Schema 变更自动同步到 Hudi 表,通过上文的描述,可以知道如果使用 Spark 引擎,可以通过 DataFrame API 操作数据,通过 from_json 动态生成 DataFrame,因此可以较为方便的实现自动添加列。如果使用 Flink 引擎上文已经说明想要自动实现 Schema 的变更,通过 HoodieFlinkStreamer 以DataStream API 的方式实现 Hudi 写入的同时融入 Schema 变更的逻辑。
三、EMR CDC 整库同步 Demo
接下的 Demo 操作中会选择 RDS MySQL 作为数据源,Flink CDC DataStream API 同步库中的所有表到 Kafka,使用 Spark 引擎消费 Kafka 中 binlog 数据实现多表写入 ODS 层 Hudi,使用 Flink 引擎以 streaming read 的模式做 DWD 和 DWS 层的 Hudi 表构建。
3.1 环境信息
EMR 6.6.0
Hudi 0.10.0
Spark 3.2.0
Flink 1.14.2
Presto 0.267
MySQL 5.7.343.2 创建源表
在 MySQL 中创建 test_db 库及 user,product,user_order 三张表,插入样例数据,后续 CDC 先加载表中已有的数据,之后源添加新数据并修改表结构添加新字段,验证 Schema 变更自动同步到 Hudi 表。
-- create databases
create database if not exists test_db default character set utf8mb4 collate utf8mb4_general_ci;
use test_db;
-- create user table
drop table if exists user;
create table if not exists user
(
id int auto_increment primary key,
name varchar(155) null,
device_model varchar(155) null,
email varchar(50) null,
phone varchar(50) null,
create_time timestamp default CURRENT_TIMESTAMP not null,
modify_time timestamp default CURRENT_TIMESTAMP null on update CURRENT_TIMESTAMP
)charset = utf8mb4;
-- insert data
insert into user(name,device_model,email,phone) values
('customer-01','dm-01','[email protected]','188776xxxxx'),
('customer-02','dm-02','[email protected]','166776xxxxx');
-- create product table
drop table if exists product;
create table if not exists product
(
pid int not null primary key,
pname varchar(155) null,
pprice decimal(10,2) ,
create_time timestamp default CURRENT_TIMESTAMP not null,
modify_time timestamp default CURRENT_TIMESTAMP null on update CURRENT_TIMESTAMP
)charset = utf8mb4;
-- insert data
insert into product(pid,pname,pprice) values
('1','prodcut-001',125.12),
('2','prodcut-002',225.31);
-- create order table
drop table if exists user_order;
create table if not exists user_order
(
id int auto_increment primary key,
oid varchar(155) not null,
uid int ,
pid int ,
onum int ,
create_time timestamp default CURRENT_TIMESTAMP not null,
modify_time timestamp default CURRENT_TIMESTAMP null on update CURRENT_TIMESTAMP
)charset = utf8mb4;
-- insert data
insert into user_order(oid,uid,pid,onum) values
('o10001',1,1,100),
('o10002',1,2,30),
('o10001',2,1,22),
('o10002',2,2,16);
-- select data
select * from user;
select * from product;
select * from user_order;
3.3 Flink CDC 发送数据到 Kafka
使用 DataStream API 编写 CDC 同步程序。样例代码 Github
# 创建topic
kafka-topics.sh --create --zookeeper ${zk} --replication-factor 2 --partitions 8 --topic cdc_topic
# 下载代码,编译打包
mvn clean package -Dscope.type=provided -DskipTests
# 也可以使用已经打好的包,进入EMR主节点,执行命令
wget https://dxs9dnjebzm6y.cloudfront.net/tmp/emr-flink-cdc-1.0-SNAPSHOT.jar
# disalbe check-leaked-classloader
sudo sed -i -e '$a\classloader.check-leaked-classloader: false' /etc/flink/conf/flink-conf.yaml
# 启动flink cdc 发送数据到Kafka
sudo flink run -m yarn-cluster \
-yjm 1024 -ytm 2048 -d \
-ys 4 -p 8 \
-c com.aws.analytics.MySQLCDC \
/home/hadoop/emr-flink-cdc-1.0-SNAPSHOT.jar \
-b xxxxx.amazonaws.com:9092 \
-t cdc_topic_001 \
-c s3://xxxxx/flink/checkpoint/ \
-l 30 -h xxxxx.rds.amazonaws.com:3306 -u admin \
-P admin123456 \
-d test_db -T test_db.* \
-p 4 \
-e 5400-5408
# 相关的参数说明如下
MySQLCDC 1.0
Usage: MySQLCDC [options]
-c, --checkpointDir
checkpoint dir
-l, --checkpointInterval
checkpoint interval: default 60 seconds
-b, --brokerList
kafka broker list,sep comma
-t, --sinkTopic kafka topic
-h, --host mysql hostname, eg. localhost:3306
-u, --username mysql username
-P, --pwd mysql password
-d, --dbList cdc database list: db1,db2,..,dbn
-T, --tbList cdc table list: db1.*,db2.*,db3.tb*...,dbn.*
-p, --parallel cdc source parallel
-s, --position cdc start position: initial or latest,default: initial
-e, --serverId cdc server id
# 消费Kafka topic 观察数据
./kafka_2.12-2.6.2/bin/kafka-console-consumer.sh --bootstrap-server $brok --topic cdc_topic_001 --from-beginning |jq .
3.4 Spark 消费 CDC 数据整库同步
# 整库同步样例代码 https://github.com/yhyyz/emr-hudi-example/blob/main/src/main/scala/com/aws/analytics/Debezium2Hudi.scala
# 下载代码,编译打包
mvn clean package -Dscope.type=provided -DskipTests
# 也可以使用已经打好的包,进入EMR主节点,执行命令
wget https://dxs9dnjebzm6y.cloudfront.net/tmp/emr-hudi-example-1.0-SNAPSHOT-jar-with-dependencies.jar
# 执行如下命令提交作业,命令中设定-s hms,hudi表同步到Glue Catalog
spark-submit --master yarn \
--deploy-mode client \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 2 \
--num-executors 2 \
--conf "spark.dynamicAllocation.enabled=false" \
--conf "spark.serializer=org.apache.spark.serializer.KryoSerializer" \
--conf "spark.sql.hive.convertMetastoreParquet=false" \
--jars /usr/lib/hudi/hudi-spark-bundle.jar,/usr/lib/spark/external/lib/spark-avro.jar \
--class com.aws.analytics.Debezium2Hudi /home/hadoop/emr-hudi-example-1.0-SNAPSHOT-jar-with-dependencies.jar \
-e prod -b xxxxx.amazonaws.com:9092 \
-t cdc_topic_001 -p emr-cdc-group-02 -s true \
-o earliest \
-i 60 -y cow -p 10 \
-c s3://xxxxx/spark-checkpoint/emr-hudi-cdc-005/ \
-g s3://xxxxx/emr-hudi-cdc-005/ \
-r jdbc:hive2://localhost:10000 \
-n hadoop -w upsert \
-s hms \
--concurrent false \
-m "{\"tableInfo\":[{\"database\":\"test_db\",\"table\":\"user\",\"recordKey\":\"id\",\"precombineKey\":\"modify_time\",\"partitionTimeColumn\":\"create_time\",\"hudiPartitionField\":\"year_month\"},
{\"database\":\"test_db\",\"table\":\"user_order\",\"recordKey\":\"id\",\"precombineKey\":\"modify_time\",\"partitionTimeColumn\":\"create_time\",\"hudiPartitionField\":\"year_month\"},{\"database\":\"test_db\",\"table\":\"product\",\"recordKey\":\"pid\",\"precombineKey\":\"modify_time\",\"partitionTimeColumn\":\"create_time\",\"hudiPartitionField\":\"year_month\"}]}"
# 相关参数说明如下:
Debezium2Hudi 1.0
Usage: spark ss Debezium2Hudi [options]
-e, --env env: dev or prod
-b, --brokerList
kafka broker list,sep comma
-t, --sourceTopic
kafka topic
-p, --consumeGroup
kafka consumer group
-s, --syncHive whether sync hive,default:false
-o, --startPos kafka start pos latest or earliest,default latest
-m, --tableInfoJson
table info json str
-i, --trigger default 300 second,streaming trigger interval
-c, --checkpointDir
hdfs dir which used to save checkpoint
-g, --hudiEventBasePath
hudi event table hdfs base path
-y, --tableType hudi table type MOR or COW. default COW
-t, --morCompact
mor inline compact,default:true
-m, --inlineMax inline max compact,default:20
-r, --syncJDBCUrl
hive server2 jdbc, eg. jdbc:hive2://localhost:10000
-n, --syncJDBCUsername
hive server2 jdbc username, default: hive
-p, --partitionNum
repartition num,default 16
-w, --hudiWriteOperation
hudi write operation,default insert
-u, --concurrent
write multiple hudi table concurrent,default false
-s, --syncMode sync mode,default jdbc, glue catalog set dms
-z, --syncMetastore
hive metastore uri,default thrift://localhost:9083
# 下图可以看到表已经同步到Glue Catalog ,数据已经写入到S3 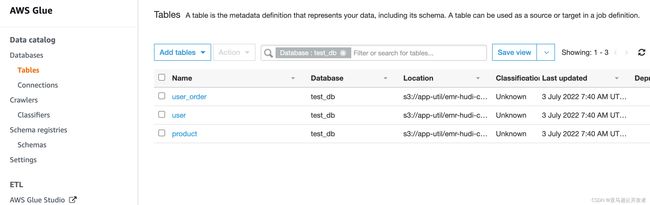
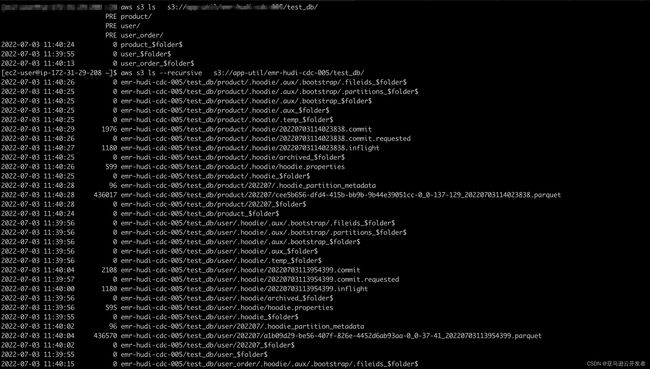
-- 向MySQL的user表中添加一列,并插入一条新数据, 查询hudi表,可以看到新列和数据已经自动同步到user表,注意以下SQL在MySQL端执行
alter table user add column age int
insert into user(name,device_model,email,phone,age) values
('customer-03','dm-03','[email protected]','199776xxxxx',18); 
3.5 Flink Streaming Read 实时聚合
# 注意最后一个参数,-t 是把/etc/hive/conf/hive-site.xml 加入到classpath,这样hudi执行表同步到Glue是就可以加入加载到这个配置,配置中的关键是 hive.metastore.client.factory.class = com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory,这样就可以加载用到Glue的Catalog实现. 如果EMR集群启动时就选择了Glue Metastore,该文件中/etc/hive/conf/hive-site.xml 已经配置了AWSGlueDataCatalogHiveClientFactory. 如果启动EMR没有选择Glue Metastore,还需要同步数据到Glue,需要手动加上。
# 注意替换为你的S3 Bucket
checkpoints=s3://xxxxx/flink/checkpoints/datagen/
flink-yarn-session -jm 1024 -tm 4096 -s 2 \
-D state.backend=rocksdb \
-D state.checkpoint-storage=filesystem \
-D state.checkpoints.dir=${checkpoints} \
-D execution.checkpointing.interval=5000 \
-D state.checkpoints.num-retained=5 \
-D execution.checkpointing.mode=EXACTLY_ONCE \
-D execution.checkpointing.externalized-checkpoint-retention=RETAIN_ON_CANCELLATION \
-D state.backend.incremental=true \
-D execution.checkpointing.max-concurrent-checkpoints=1 \
-D rest.flamegraph.enabled=true \
-d \
-t /etc/hive/conf/hive-site.xml
# 启动Flink sql client
/usr/lib/flink/bin/sql-client.sh embedded -j /usr/lib/hudi/hudi-flink-bundle.jar shell
-- user表,开启streaming read, changelog.enalbe=true
set sql-client.execution.result-mode=tableau;
CREATE TABLE `user`(
id string,
name STRING,
device_model STRING,
email STRING,
phone STRING,
age string,
create_time STRING,
modify_time STRING,
year_month STRING
)
PARTITIONED BY (`year_month`)
WITH (
'connector' = 'hudi',
'path' = 's3://xxxxx/emr-hudi-cdc-005/test_db/user/',
'hoodie.datasource.write.recordkey.field' = 'id',
'table.type' = 'COPY_ON_WRITE',
'index.bootstrap.enabled' = 'true',
'read.streaming.enabled' = 'true',
'read.start-commit' = '20220607014223',
'changelog.enabled' = 'false',
'read.streaming.check-interval' = '1'
);
# 实时查询数据
select * from `user`;
# 在MySQL中修改user表中id=3的name为new-customer-03,注意以下SQL在MySQL端执行
update user set name="new-customer-03" where id=3;
# 在Flink 端可以可以看到数据变更 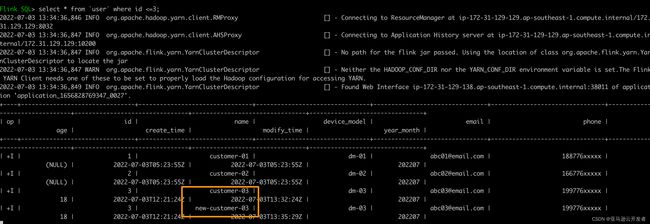
-- Flink聚合操作Sink到Hudi表
-- batch
CREATE TABLE user_agg(
num BIGINT,
device_model STRING
)WITH(
'connector' = 'hudi',
'path' = 's3://xxxxx/emr-cdc-hudi/user_agg/',
'table.type' = 'COPY_ON_WRITE',
'write.precombine.field' = 'device_model',
'write.operation' = 'upsert',
'hoodie.datasource.write.recordkey.field' = 'device_model',
'hive_sync.database' = 'dws',
'hive_sync.enable' = 'true',
'hive_sync.table' = 'user_agg',
'hive_sync.mode' = 'HMS',
'hive_sync.use_jdbc' = 'false',
'hive_sync.username' = 'hadoop'
);
insert into user_agg select count(1) as num, device_model from `user` group by device_model;
# 动态参数打开,对user_agg表进行streaming读取,查看实时变化结果
set table.dynamic-table-options.enabled=true;
select * from user_agg/*+ OPTIONS('read.streaming.enabled'='true','read.start-commit' = '20220607014223')*/
# 可以在MySQL源端多添加几条数据,查看数据结果,注意以下SQL在MySQL端执行
insert into user(name,device_model,email,phone,age) values ('customer-03','dm-03','[email protected]','199776xxxxx',18); 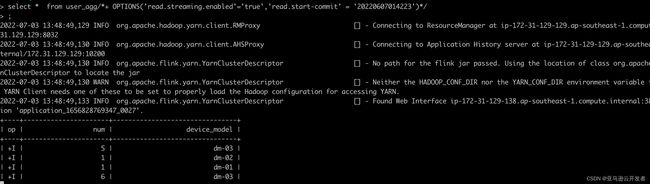
四、总结
本篇文章讲解了如何通过 EMR 实现 CDC 数据入湖及 Schema 的自动变更。通过 Flink CDC DataStream API 先将整库数据发送到 MSK,这时 CDC 在源端只有一个 binlog dump 线程,降低对源端的压力。使用 Spark Structured Streaming 动态解析数据写入到 Hudi 表来实现 Shema 的自动变更,实现单个 Job 管理多表 Sink, 多表情况下降低开发维护成本,可以并行或者串行写多张 Hudi 表,元数据同步 Glue Catalog。使用 Flink Hudi 的 Streaming Read 模式实现实时数据 ETL,满足 DWD 和 DWS 层的实时 Join 和聚合的需求。Amazon EMR 环境中原生集成 Hudi, 使用 Amazon EMR 轻松构建了整库同步的 Demo。
本篇作者

潘超
亚马逊云科技数据分析解决方案架构师。负责客户大数据解决方案的咨询与架构设计,在开源大数据方面拥有丰富的经验。工作之外喜欢爬山。
文章来源:多库多表场景下使用 Amazon EMR CDC 实时入湖最佳实践