在 Amazon SageMaker 上玩转 Stable Diffusion: 基于 Dreambooth 的模型微调

本文将以 Stable Diffusion Quick Kit 为例,详细讲解如何利用 Dreambooth 对 Stable Diffusion 模型进行微调,包括基础的 Stable Diffusion 模型微调知识,Dreambooth 微调介绍,并且使用 Quick Kit 通过一个 demo 演示微调效果。
01
Stable Diffusion 模型微调
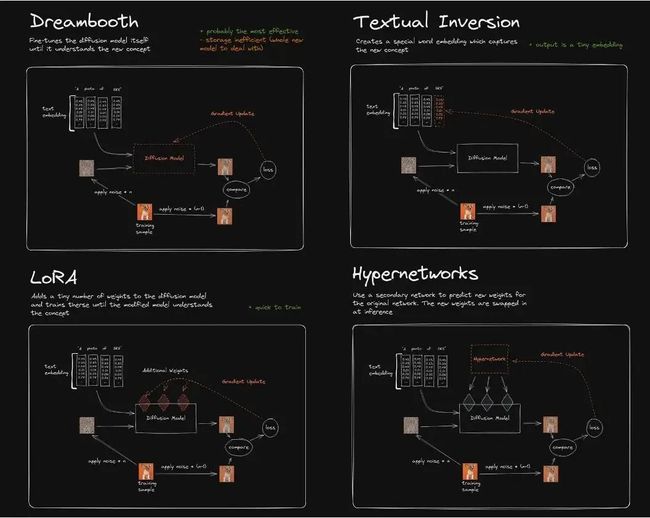
目前 Stable Diffusion 模型微调主要有4种方式:Dreambooth、LoRA (Low-Rank Adaptation of Large Language Models)、Textual Inversion、Hypernetworks。
它们的区别大致如下:
Textual Inversion (也称为 Embedding),它实际上并没有修改原始的 Diffusion 模型, 而是通过深度学习找到了和你想要的形象一致的角色形象特征参数,通过这个小模型保存下来。这意味着,如果原模型里面这方面的训练缺失的,其实你很难通过嵌入让它“学会”,它并不能教会 Diffusion 模型渲染其没有见过的图像内容。
Dreambooth 是对整个神经网络所有层权重进行调整,会将输入的图像训练进 Stable Diffusion 模型,它的本质是先复制了源模型,在源模型的基础上做了微调(fine tunning)并独立形成了一个新模型,在它的基本上可以做任何事情。缺点是,训练它需要大量 VRAM,目前经过调优后可以在 16GB 显存下完成训练。
LoRA 也是使用少量图片,但是它是训练单独的特定网络层的权重,是向原有的模型中插入新的网络层,这样就避免了去修改原有的模型参数,从而避免将整个模型进行拷贝的情况,同时其也优化了插入层的参数量,最终实现了一种很轻量化的模型调校方法。 LoRA 生成的模型较小、训练速度快,推理时需要 LoRA 模型+基础模型,LoRA 模型会替换基础模型的特定网络层,所以它的效果会依赖基础模型。
Hypernetworks 的训练原理与 LoRA 差不多,目前其并没有官方的文档说明,与 LoRA 不同的是,Hypernetwork 是一个单独的神经网络模型,该模型用于输出可以插入到原始 Diffusion 模型的中间层。 因此通过训练,我们将得到一个新的神经网络模型,该模型能够向原始 Diffusion 模型中插入合适的中间层及对应的参数,从而使输出图像与输入指令之间产生关联关系。
注: 图片来自网络资料
02
什么是 Dreambooth
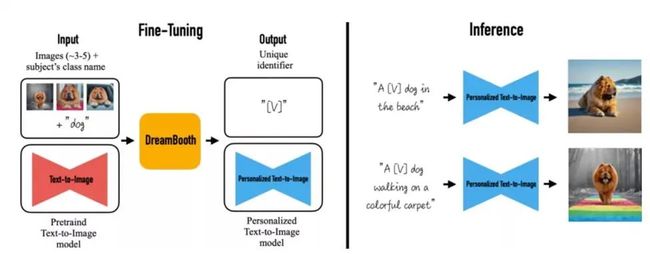
Stable Diffusion 模型可以实现文生图、图生图的丰富图像生成场景,但让一个真实的特定现实物体出现在图像中时,最先进的文本生成图像模型也很难保留其关键视觉特征,即它们缺乏模仿或再现给定参考集中主体外观的能力,此类模型输出域的表达性有限,即便使用 Textual Inversion 微调对对象进行精确文本描述,或者 hypernetwork 进行风格保持,它们也可能产生具有不同外观的实例。
DreamBooth 算法对 Imagen 模型进行了微调,从而实现了将现实物体在图像中真实还原的功能,通过少量实体物品图像的 fine-turning,使得原有的 SD 模型能对图像实体记忆保真,识别文本中该实体在原图像中的主体特征甚至主题风格,是一种新的文本到图像“个性化”(可适应用户特定的图像生成需求)扩散模型。
Dreambooth fine tuning 面临的问题和挑战
Dreambooth fine tuning 的原理,是通过少量输入图片,并且通过 instance_prompt 定义实体主体(e.g. toy cat/隆美尔)和 instance images 的 fine tuning 图像,以及提供一个定义场景或者主题 schema(e.g. 卡通,油画风格)class prevision 的 prompt 和 class image 图片,抽取原 SD 中 UNet、vae 网络,将 instance prompt 和 class preservation 的 prompt 与之绑定,以便后续生成的图片中只要有 instance 的 prompt 中的关键字 token,就保持输入 instance 图片里面的主体实体,并且保持该 class presevation 的图形定义的主题风格。
目前业界对 DreamBooth 做 fine tuning 主要为两种方式:
一是在 Stable Diffusion WebUI 可视话界面进行模型的选择,训练图片的上载及本地化的训练;
二是在第三方 IDE 平台如 colab notebook 上以脚本交互式开发的方式进行训练。
第一种方式只能在部署 Stable Diffusion WebUI 应用的单一服务器或主机上训练,无法与企业及客户的后台平台及业务集成;而第二种方式侧重于算法工程师个人在开发测试阶段进行模型实验探索,无法实现生产化工程化的部署。此外,以上两种方式训练 Dreambooth,还需要关注高性能算力机资源的成本(尤其对模型效果要求较高的场景,需要多达50张以上的 class images,显存容易 OOM)、基础模型和 fine tuning 后模型的存储和管理、训练超参的管理、统一的日志监控、训练加速、依赖 lib 编译打包等具体实施落地层面的一系列困难和挑战。
03
使用 SageMaker Training Job 进行 Dreambooth fine tuning
Amazon SageMaker 是一个一站式的机器学习集成开发平台,提供了广泛的功能来帮助用户轻松构建、训练和部署机器学习模型。在 training job 层面,SageMaker 可以拉取 V100、A100、T4 等各种类型 GPU 优化的算力机资源,通过 BYOC (Bring Your Own Container),BYOS (Bring Your Own Script) 等方式,允许用户使用自己的训练脚本或自定义容器镜像、灵活控制训练过程并使用自己的数据预处理和模型评估方法。此外,还可以通过自动超参数优化功能、分布式训练等 advance 的功能,从而使得用户能够在 SageMaker 中使用特定的框架和 lib 库,灵活性和可定制性的进行 Dreambooth 模型的 fine tuning 和调优,消除 WebUI 及 notebook 本地环境的局限,并和生产业务系统集成,实现工程化部署。
以下详细介绍了在 Amazon SageMaker 上,使用 BYOC 模式的 training Job,进行 Dreambooth fine tuning 的方式方法,并针对 Dreambooth 训练过程的显存开销、模型管理、超参等进行了优化实践,从而实现用户在自己的 ML 平台或业务系统的的工程化落地,并降低训练的整体 TCO。
Dreambooth fine tuning on SageMaker 技术方案
我们从模型拉取、训练图像输入、模型输出、训练任务类型几个方面讲解 Dreambooth 在 SageMaker 上 fine tuning 的技术实现:
模型拉取
Amazon 与 HuggingFace 有战略合作关系,因此在 SageMaker 的 training job 中,我们可以通过一个 diffuser 的 pipeline api,通过一个pretrained_model_name_or_path 超参变量,传入标准 huggingface model url 格式的模型 id(比如 runwayml/stable-diffusion-v1-5),或者模型文件目录(e.g. /opt/ml/model/stable-diffusion-v1.5/),SageMaker 会自动拉取 Huggingface 上的 model,不需要注册账号及传入 token 认证,代码示例如下:
model_dir='/opt/ml/input/fineturned_model/'
model = StableDiffusionPipeline.from_pretrained(
model_dir,
scheduler = DPMSolverMultistepScheduler.from_pretrained(model_dir, subfolder="scheduler"),
torch_dtype=torch.float16,
)左滑查看更多
训练图像输入
对于用于 fine tuning 的输入图像,SageMaker training job 提供方便的训练数据输入的方法,通过 inputs 参数,可以以字典方式设定输入图像的 channel 的名字(如:images),输入图像在 S3 的存储路径做为 value,则 SageMaker 训练任务时,会以将图像从 S3 下载下来放置到算力机的 /opt/ml/input/data/{channel} 目录下,代码示例如下:
images_s3uri = 's3://{0}/dreambooth/images/'.format(bucket)
inputs = {
'images': images_s3uri
}
estimator = Estimator(
role = role,
instance_count=1,
instance_type = instance_type,
image_uri = image_uri,
hyperparameters = hyperparameters,
environment = environment
)
estimator.fit(inputs)左滑查看更多
模型输出
trainning 之后,SageMaker 默认会将模型文件打包为 model.tar.gz,并上传到 S3 上以 trainning job 命名的子目录,客户的生产系统可以直接通过 API 获取该路径位置,从而方便实现模型管理和后续推理部署,如下所示:

训练方式
Amazon SageMaker 支持 BYOS、BYOC 两种模式进行模型训练,对于 Dreambooth 的模型训练,因为涉及 diffuser、huggingface、accelerate、xformers 等众多依赖的安装部署,且如 xformers、accelerate 一类的开源 lib 在各种 GPU 机型,各种 cuda、cudnn 版本下存在兼容性差异,很难通过直接 pip install 方式在算力机上安装部署,因此本方案使用 BYOC 方式,基于官方预置的 Pytorch、cuda、torchversion 等基础镜像,再通过源代码编译打包方式安装 xformers 等所需的 lib,扩展为客户自己生产上的 Dreambooth 训练容器镜像。
注意 xformers 在 Amazon G4dn,G5 上的编译安装,需要 cuda 11.7,torch 1.13以上版本,且 CUDA_ARCH_LIST 算力参数需要设置为8.0以上,否则编译会报该类型 GPU 算力不支持。
编译打包的 docker file 参考如下:
FROM pytorch/pytorch:1.13.0-cuda11.6-cudnn8-runtime
ENV PATH="/opt/ml/code:${PATH}"
ENV DEBIAN_FRONTEND noninteractive
RUN apt-get update
RUN apt-get install --assume-yes apt-utils -y
RUN apt update
RUN echo "Y"|apt install vim
RUN apt install wget git -y
RUN apt install libgl1-mesa-glx -y
RUN pip install opencv-python-headless
RUN mkdir -p /opt/ml/code
RUN pip3 install sagemaker-training
COPY train.py /opt/ml/code/
COPY ./sd_code/ /opt/ml/code/
RUN pip install -r /opt/ml/code/extensions/sd_dreambooth_extension/requirements.txt
ENV SAGEMAKER_PROGRAM train.py
RUN export TORCH_CUDA_ARCH_LIST="7.5 8.0 8.6" && export FORCE_CUDA="1" && pip install ninja triton==2.0.0.dev20221120 && git clone https://github.com/xieyongliang/xformers.git /opt/ml/code/repositories/xformers && cd /opt/ml/code/repositories/xformers && git submodule update --init --recursive && pip install -r requirements.txt && pip install -e .
ENTRYPOINT []左滑查看更多
打包后 push 到 Amazon ECR 镜像 repository 的脚本参考如下:
algorithm_name=dreambooth-finetuning-v3
account=$(aws sts get-caller-identity --query Account --output text)
# Get the region defined in the current configuration (default to us-west-2 if none defined)
region=$(aws configure get region)
fullname="${account}.dkr.ecr.${region}.amazonaws.com/${algorithm_name}:latest"
# If the repository doesn't exist in ECR, create it.
aws ecr describe-repositories --repository-names "${algorithm_name}" > /dev/null 2>&1
if [ $? -ne 0 ]
then
aws ecr create-repository --repository-name "${algorithm_name}" > /dev/null
fi
# Log into Docker
pwd=$(aws ecr get-login-password --region ${region})
docker login --username AWS -p ${pwd} ${account}.dkr.ecr.${region}.amazonaws.com
# Build the docker image locally with the image name and then push it to ECR
# with the full name.
mkdir -p ./sd_code/extensions
cd ./sd_code/extensions/ && git clone https://github.com/qingyuan18/sd_dreambooth_extension.git
cd ../../
docker build -t ${algorithm_name} ./ -f ./dockerfile_v3 > ./docker_build.log
docker tag ${algorithm_name} ${fullname}
docker push ${fullname}
rm -rf ./sd_code左滑查看更多
Dreambooth on SageMaker fine tuning 优化
1
从 WebUI 插件剥离
DreamBooth 最早是由 Google 文献资料,在 HuggingFace 的 colab notebook 示例代码上开源,详见 github 上相关资料,后续有众多 folk 并基于该版本的扩展和更新,目前最完善的一个版本是做成 stable diffusion WebUI 插件的开源脚本,该插件封装了更多的操控训练的超参和优化手段,可以集成 lora 权重,并支持 WebUI 需要的 checkpoint 的格式,详见 github 上 sd_extentions 的代码。
github 上相关资料:
https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb#scrollTo=rscg285SBh4M
github 上 sd_extentions 的代码:
https://github.com/d8ahazard/sd_dreambooth_extension
如上文所述,SD WebUI 无法和后端业务系统整合,因此我们需要将其从 WebUI 插件方式剥离,根据基础模型、输入图像、instance prompt、class prompt 等标准输入和 fine tuning 后模型输出,独立封装成单独的模型训练程序。

要从 WebUI 插件剥离,主要以下几方面需要处理:
插件代码有各种 WebUI 前端界面组件绑定的操作及数据交互耦合在一起,如原始代码的 shared,保存的是 web 页面的输入的各种训练参数。
if shared.force_cpu:
import modules.shared
no_safe = modules.shared.cmd_opts.disable_safe_unpickle
modules.shared.cmd_opts.disable_safe_unpickle = True左滑查看更多
mytqdm 类,为 web 页面提示进度条相关状态信息:
from helpers.mytqdm import mytqdm左滑查看更多
此类代码这在工程化的后台训练 job 中是不必要的,我们把前端页面传参的部分,统一整理为 hyperparameter 超参,以便在 main 主体中通过 python 的 parse_args lib 解析和获取,另外把页面展示信息相关这些代码去掉。
清理后的 sd_extentions 代码可以参见 https://github.com/qingyuan18/sd_dreambooth_extension.git,可以看到这里面只保留了核心 train 训练模块,webui.py、helper、shard 等前端耦合相关代码都已经清理。
训练任务参数传递
SageMaker Training Job 支持模型超参的传递和解析。在 API 中,将刚才提到的原始插件代码中 model_path、 model_name、instance_prompt、class_prompt 等参数,封装在一个 json 字符串的键值对格式中,再通过 estimator API 传递给 Training Job,在 SageMaker 训练算力机内部,会解析为—key value 的标准 args 传参模式,这样在训练代码中,就可以通过 python parse_args lib 进行解析和处理了,参考如下代码示例:
hyperparameters = {
'model_name':'aws-trained-dreambooth-model',
'mixed_precision':'fp16',
'pretrained_model_name_or_path': model_name,
'instance_data_dir':instance_dir,
'class_data_dir':class_dir,
'with_prior_preservation':True,
'models_path': '/opt/ml/model/',
'manul_upload_model_path':s3_model_output_location,
'instance_prompt': instance_prompt,
……}
estimator = Estimator(
role = role,
instance_count=1,
instance_type = instance_type,
image_uri = image_uri,
hyperparameters = hyperparameters
)左滑查看更多
WebUI 输入的模型
为 ckpt 格式(现在最新的 WebUI 为 safetensor 格式),而 diffuser 训练时 from_pretrained 加载的 model pipeline 为 Stable Diffusion 的 model path 或者本地路径格式(默认为目录路径,目录下有 vae、unet、tokenizationer 等子模型目录,每个子模型目录下为独立的 torch pt 格式文件(后缀.bin))。
如果客户生产环境中,是 ckpt 格式的单个模型文件(如从 civit.ai 站点下载的模型),那么我们可以通过 diffuser 官方提供的转换脚本 ,将其从 ckpt 格式转为 diffuser 目录格式,以便同样的代码在生产环境中进行加载,脚本使用示例如下:
python convert_original_stable_diffusion_to_diffusers.py —checkpoint_path ./models_ckpt/768-v-ema.ckpt —dump_path ./models_diffuser左滑查看更多
如上— dump_path 输出即为 diffuser 格式目录,该目录下展开可以看到各个 vae、unet、text_encoder 的子模型目录文件。

2
输出模型管理
SageMaker 的模型训练算力机目录结构如下:

训练后的模型,会默认输出到 /opt/ml/model/ 目录下,SageMaker Training Job 完成后,会将这个目录下的 model 文件打包为 tar.gz 文件,并上传到训练任务的 S3 路径。对于 Stable Diffusion 这样的复合模型,存在多个子目录,每个子目录的模型文件都是独立的 bin 格式,每个 h 模型文件有4、5G 以上,SageMaker 自动打包和 upload 到 S3 会耗时太长。
因此我们加入一个 manul_upload_model_path 参数,指定训练后的模型文件手工上传的 S3 路径,训练结束后通过 S3 SDK 递归方式上传整个模型目录到指定 S3,让 SageMaker 不再打包 model.tar.gz。
参考代码示例如下:
def upload_directory_to_s3(local_directory, dest_s3_path):
bucket,s3_prefix=get_bucket_and_key(dest_s3_path)
for root, dirs, files in os.walk(local_directory):
for filename in files:
local_path = os.path.join(root, filename)
relative_path = os.path.relpath(local_path, local_directory)
s3_path = os.path.join(s3_prefix, relative_path).replace("\\", "/")
s3_client.upload_file(local_path, bucket, s3_path)
print(f'File {local_path} uploaded to s3://{bucket}/{s3_path}')
for subdir in dirs:
upload_directory_to_s3(local_directory+"/"+subdir,dest_s3_path+"/"+subdir)
s_pipeline.save_pretrained(args.models_path)
### manually upload trained db model dirs to s3 path#####
#### to eliminate sagemaker tar process#####
print(f"manul_upload_model_path is {args.manul_upload_model_path}")
upload_directory_to_s3(args.models_path,args.manul_upload_model_path)左滑查看更多
通过该优化,SageMaker 上的 Dreambooth training,800 steps 训练由1小时提升到30分钟左右。
3
GPU 显存优化
对于 Dreambooth 这样的大模型 fine tuning 训练,成本是需要考虑的重要因素,Amazon 提供了各种 GPU 机型的算力机资源,其中 G4dn 机型是性价比最高的,且在几乎所有 Amazon 的区域中都有资源。
但 g4dn 机型只有单张 16G 显存的英伟达 T4 显卡,Dreambooth 要重训练 unet、vae 网络,来保留先验损失权重,当需要更高保真度的 Dreambooth fine tuning,会多达数十张图片的输入数据,1000 step 的训练过程,整个网络尤其是 unet 网络的图形加噪及降噪等处理,很容易造成显存 OOM 导致训练任务失败。
为了保障客户在 16G 显存的成本优势机型上能够 train Dreambooth 模型,我们做了这几部分的优化,从而使得 Dreambooth fine tuning 在 SageMaker 上只需要 G4dn.xlarge 的机型,数百到3000的 training steps 都可以完成训练,大幅度降低了客户训练 Dreambooth 的成本。
调整 fine tuning 组件
在 Stable Difussion 模型中,text_encoder 是 CLIP 子模型的文本编码器,对于 instance prompt/class prompt 不是长文本的情况下,Dreambooth 不需要重新训练文本编码器,因为我们调整了一些规则,如果发现显存小于 16G,关闭 text_encoder 部分的重训练。如果显存更低,则自动启用开启 8bit Adam 优化器,以及 fp16 半精度梯度数据格式。如果显存更小,甚至直接 offload 到 CPU 训练。
代码示例如下:
print(f"Total VRAM: {gb}")
if 24 > gb >= 16:
attention = "xformers"
not_cache_latents = False
train_text_encoder = True
use_ema = True
if 16 > gb >= 10:
train_text_encoder = False
use_ema = False
if gb < 10:
use_cpu = True
use_8bit_adam = False
mixed_precision = 'no'左滑查看更多
使用 xformers
formers 是开源的训练加速的框架,通过存储不同层的参数,每个子层动态加载显存,以及优化了自注意力机制和跨层的信息传递等方法,可以在不影响训练速度的情况大幅降低显存。
在 Dreambooth 训练过程中,将 attention 关注度由默认的 flash 改为 xformer,对比开启 xformers 前后的 GPU 显存情况,可以看到该方法明显降低了显存使用。
开启 Xformers 前:
***** Running training *****
Instantaneous batch size per device = 1
Total train batch size (w. parallel, distributed & accumulation) = 1
Gradient Accumulation steps = 1
Total optimization steps = 1000
Training settings: CPU: False Adam: True, Prec: fp16, Grad: True, TextTr: False EM: True, LR: 2e-06 LORA:False
Allocated: 10.5GB
Reserved: 11.7GB左滑查看更多
开启 Xformers 后:
***** Running training *****
Instantaneous batch size per device = 1
Total train batch size (w. parallel, distributed & accumulation) = 1
Gradient Accumulation steps = 1
Total optimization steps = 1000
Training settings: CPU: False Adam: True, Prec: fp16, Grad: True, TextTr: False EM: True, LR: 2e-06 LORA:False
Allocated: 5.5GB
Reserved: 5.6GB左滑查看更多
其他优化参数
‘PYTORCH_CUDA_ALLOC_CONF’:‘max_split_size_mb:32′对于显存碎片化引起的 CUDA OOM,可以将 PYTORCH_CUDA_ALLOC_CONF 的 max_split_size_mb 设为较小值。
train_batch_size’:1每次处理的图片数量,如果 instance images 或者 class image 不多的情况下(小于10张),可以把该值设置为1,减少一个批次处理的图片数量,一定程度降低显存使用。
‘sample_batch_size’: 1和 train_batch_size 对应,一次进行采样加噪和降噪的批次吞吐量,调低该值也对应降低显存使用。
not_cache_latents 另外,Stable Diffusion 的训练,是基于 Latent Diffusion Models,原始模型会缓存 latent,而我们主要是训练 instance prompt, class prompt 下的正则化,因此在 GPU 显存紧张情况下,我们可以选择不缓存 latent,最大限度降低显存占用。
‘gradient_accumulation_steps’ 梯度更新的批次,如果训练 steps 较大,比如1000,可以增大梯度更新的步数,累计到一定批次再一次性更新,该值越大,显存占用越高,如果希望降低显存,可以在牺牲一部分训练时长的前提下减少该值。注意如果选择了重新训练文本编码器 text_encode,不支持梯度累积,且多 GPU 的机器上开启了 accelerate 的多卡分布式训练,则批量梯度更新 gradient_accumulation_steps 只能设置为1,否则文本编码器的重训练将被禁用。
Stable Diffusion Quick Kit Dreambooth 模型微调演示
演示中我们使用了一个猫玩具的4张图片,通过工具进行了512×512统一尺寸裁剪。

然后进入提前创建好的 SageMaker notebook,克隆 Quick Kit 仓库,git clone https://github.com/aws-samples/sagemaker-stablediffusion-quick-kit,打开 fine-tuning/dreambooth/stablediffusion_dreambooth_finetuning.zh.ipynb, 一步一步按照 notebook 提示进行操作。
#使用了zwx作为触发词, 模型训练好之后我们使用这个词来生成图
instance_prompt="photo\ of\ zwx\ toy"
class_prompt="photo\ of\ a\ cat toy"
#notebook训练代码说明
#设置超参
environment = {
'PYTORCH_CUDA_ALLOC_CONF':'max_split_size_mb:32',
'LD_LIBRARY_PATH':"${LD_LIBRARY_PATH}:/opt/conda/lib/"
}
hyperparameters = {
'model_name':'aws-trained-dreambooth-model',
'mixed_precision':'fp16',
'pretrained_model_name_or_path': model_name,
'instance_data_dir':instance_dir,
'class_data_dir':class_dir,
'with_prior_preservation':True,
'models_path': '/opt/ml/model/',
'instance_prompt': instance_prompt,
'class_prompt':class_prompt,
'resolution':512,
'train_batch_size':1,
'sample_batch_size': 1,
'gradient_accumulation_steps':1,
'learning_rate':2e-06,
'lr_scheduler':'constant',
'lr_warmup_steps':0,
'num_class_images':50,
'max_train_steps':300,
'save_steps':100,
'attention':'xformers',
'prior_loss_weight': 0.5,
'use_ema':True,
'train_text_encoder':False,
'not_cache_latents':True,
'gradient_checkpointing':True,
'save_use_epochs': False,
'use_8bit_adam': False
}
hyperparameters = json_encode_hyperparameters(hyperparameters)
#启动sagemaker training job
from sagemaker.estimator import Estimator
inputs = {
'images': f"s3://{bucket}/dreambooth/images/"
}
estimator = Estimator(
role = role,
instance_count=1,
instance_type = instance_type,
image_uri = image_uri,
hyperparameters = hyperparameters,
environment = environment
)
estimator.fit(inputs)左滑查看更多
训练任务启动日志:
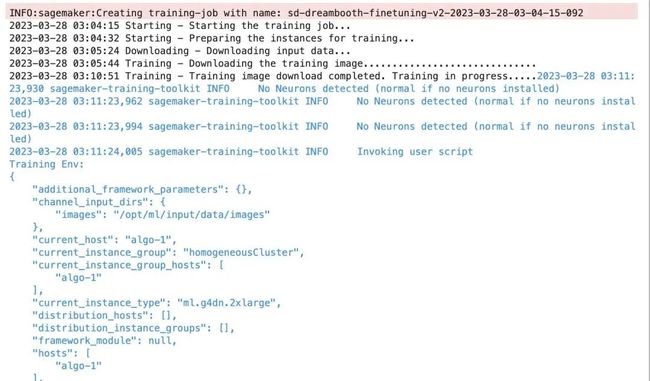
训练时间大约在40分钟左右,也可以通过控制台 SageMaker Training Job 查看 CloudWatch 日志,训练结束后会自动把模型上传到 S3。
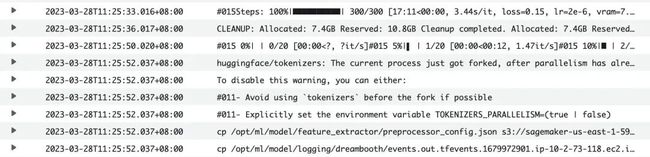


训练完成后可以使用 Quick Kit 推理 notebook 将训练好的模型加载到 SageMaker 进行推理,训练好的模型测试如下:

04
结论
综上所述,本文介绍 Dreambooth 的业务需求及技术原理,通过在 Amazon SageMaker 上 BYOC 方式的 Training Job 解决方案,以及显存、模型管理、超参等的优化实践,实现了 Dreambooth fine tuning 的生产化运行。文中脚本代码及笔记本训练示例,可做为用户基于 Stable Diffusion 的 AIGC ML 平台的工程化的基础。
05
附录
Stable Diffusion Quick Kit github:
https://github.com/aws-samples/sagemaker-stablediffusion-quick-kit
Stable Diffusion Quick Kit Dreambooth 微调文档:
https://catalog.us-east-1.prod.workshops.aws/workshops/1ac668b1-dbd3-4b45-bf0a-5bc36138fcf1/zh-CN/4-configuration-stablediffusion/4-4-find-tuning-notebook
Dreambooth 论文:
https://dreambooth.github.io/
Dreambooth 原始开源 github: https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb#scrollTo=rscg285SBh4M
Huggingface diffuser 格式转换工具:
https://github.com/huggingface/diffusers/tree/main/scripts
Stable diffusion webui dreambooth extendtion 插件:
https://github.com/d8ahazard/sd_dreambooth_extension.git
Facebook xformers 开源:
https://github.com/facebookresearch/xformers
本篇作者

唐清原
亚马逊云科技数据分析解决方案架构师,负责 Amazon Data Analytic 服务方案架构设计以及性能优化,迁移,治理等 Deep Dive 支持。10+数据领域研发及架构设计经验,历任 Oracle 高级咨询顾问,咪咕文化数据集市高级架构师,澳新银行数据分析领域架构师职务。在大数据,数据湖,智能湖仓,及相关推荐系统 MLOps 平台等项目有丰富实战经验。

粟伟
亚马逊云科技资深解决方案架构师,专注游戏行业,开源项目爱好者,致力于云原生应用推广、落地。具有15年以上的信息技术行业专业经验,担任过高级软件工程师,系统架构师等职位,在加入亚马逊云科技之前曾就职于 Bea、Oracle、IBM 等公司。

听说,点完下面4个按钮
就不会碰到 bug 了!