Docker 部署一个简单的 Streamlit 应用程序
参考文献:Deploying a Simple Streamlit app using Docker | Engineering Education (EngEd) Program | Section
Docker 是一个虚拟化平台,旨在通过使用容器来创建、运行和部署应用程序。我们将使用 Docker 部署一个使用 Streamlit 构建的简单机器学习应用程序。
在本教程中,我们将首先创建一个简单的机器学习模型,将其保存到 pickle 文件中以加载到我们的平台中,然后使用 Streamlit 创建其界面。创建 Streamlit 应用程序后,我们将使用 docker 来部署它。
Streamlit简介
Streamlit 是一个框架,不同的机器学习工程师和数据科学家使用它从经过训练的模型构建 UI 和强大的机器学习应用程序。
通过为用户提供交互式界面,这些应用程序可用于可视化。
它提供了一种更简单的方法来构建图表、表格和不同的图形以满足您的应用程序的需求。它还可以利用已保存或选择到应用程序中的模型进行预测。
如何安装Streamlit
使用以下命令:
pip install streamlit
让我们构建streamlit应用程序
1、文件夹结构如下:
├── Dockerfile
├── demo.xlsx
├── drive_st_test.py
├── ml.xlsx
├── requirements.txt
├── 改善v_1.xlsx2、其中,Dockerfile文件内容如下
FROM python:3.7
WORKDIR /app
COPY requirements.txt ./requirements.txt
RUN pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
EXPOSE 8501
COPY . /app
ENTRYPOINT ["streamlit", "run"]
CMD ["drive_st_test.py"]
3.drive_st_test.py文件包含
######################
# Import libraries
######################
import pandas as pd
import numpy as np
import streamlit as st
import datetime
from datetime import datetime
from datetime import timedelta
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import seaborn as sns
from plotly import subplots
from plotly.subplots import make_subplots
import plotly.graph_objects as go
import plotly.express as px
import plotly.figure_factory as ff
#加载streamlit pyecharts
from pyecharts.charts import *
from pyecharts.faker import Faker
import streamlit_echarts
from pyecharts import options as opts
from pyecharts.globals import ThemeType
st.set_page_config(layout="wide")
######################
# Import data
######################
@st.cache(allow_output_mutation = True) #存入内存,速度变快
def load_data():
df=pd.read_excel('./demo.xlsx')
radar_df=pd.read_excel('./ml.xlsx')
improve=pd.read_excel('./改善v_1.xlsx')
return df,radar_df,improve
df,radar_df,improve=load_data()
df['tid_x']=df['tid_x'].astype('str')
df['gpstime_b_date']=df['gpstime_b'].apply(lambda x: x.strftime("%Y-%m-%d"))
df['gpstime_b_date']=pd.to_datetime(df['gpstime_b_date'])
######################
# Selected sidebar variables
######################
# id_list = df['tid_x'].unique()
# select_id = st.sidebar.selectbox("选择id",list(id_list))
# select_city = st.sidebar.selectbox("选择城市",list(['全国','武汉']))
# m_cut_list=df['m_cut'].unique()
# select_status = st.sidebar.selectbox("选择载重状态",list(m_cut_list))
######################
# Write some information
######################
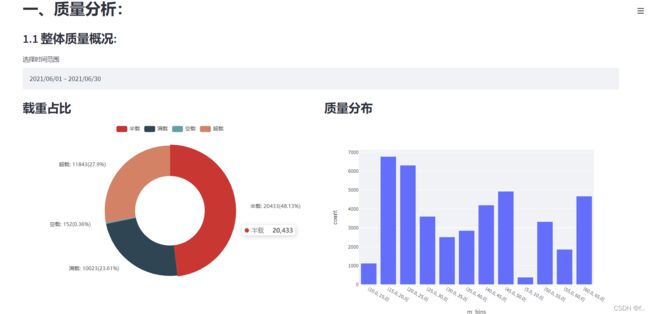
st.header('一、质量分析:') #车辆数 ,监控时长,重点关注车辆(规则)
st.subheader('1.1 整体质量概况:')
# Dates for date_input creation and delimitation
max_date = df['gpstime_b_date'].max()
min_date = df['gpstime_b_date'].min()
start_date = datetime(2021, 6, 1)
end_date = datetime(2021, 6, 30)
dates = st.date_input('选择时间范围', max_value=max_date, min_value=min_date, value=(start_date, end_date))
col1,col2=st.columns(2)
cond=(df['gpstime_b_date']>=pd.to_datetime(dates[0]))&(df['gpstime_b_date']<=pd.to_datetime(dates[1]))
tmp = df.loc[cond]
with col1:
st.subheader('载重占比')
tmp_m=tmp.groupby('m_cut')['m_cut'].agg(['count']).reset_index()
c = (
Pie()
.add("", [list(z) for z in zip(tmp_m['m_cut'].tolist(), tmp_m['count'].tolist())])
.set_global_opts(title_opts=opts.TitleOpts(title="质量分布"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
d = (
Pie()
.add(
"",
[list(z) for z in zip(tmp_m['m_cut'].tolist(), tmp_m['count'].tolist())],
radius=["40%", "75%"],
)
.set_global_opts(
#title_opts=opts.TitleOpts(title="质量分布"),
# legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}({d}%)"))
)
streamlit_echarts.st_pyecharts(d,height=400)
with col2:
st.subheader('质量分布')
#密度图太卡
# fig = ff.create_distplot(tmp['m'].values.reshape(1,-1), ['m'],bin_size=2.0)
# st.plotly_chart(fig,use_column_width=True)
bins=np.linspace(5,75,15)
tmp['m_bins']=pd.cut(tmp['m'],bins)
tmp['m_bins']=tmp['m_bins'].astype('str')
tmp1=tmp.groupby('m_bins')['m_bins'].agg(['count']).reset_index()
fig = px.bar(tmp1, x="m_bins",y="count")
st.plotly_chart(fig)
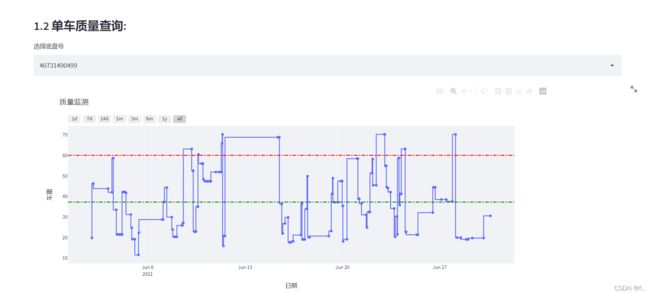
st.subheader('1.2 单车质量查询:')
#button1 = st.button('导入车辆计算')
id_list = df['tid_x'].unique()
select_id = st.selectbox("选择底盘号",list(id_list))
tmp_m = df[df['tid_x']==select_id]
tmp_m['最终使用m'] = round(tmp_m['最终使用m'],2)
# c = (
# Line()
# .add_xaxis(tmp_m['gpstime_b'].tolist())
# .add_yaxis("质量", tmp_m['最终使用m'].tolist(),is_step=True,
# # ,is_connect_nones=True
# markline_opts=opts.MarkLineOpts(
# data=[
# opts.MarkLineItem(type_="average", name="平均值"),
# opts.MarkLineItem(y=60, name="60以上")
# ]
# ),
# )
# .set_global_opts(title_opts=opts.TitleOpts(title="质量监测"))
# )
# streamlit_echarts.st_pyecharts(c,height=500)
def time_series(tmp_m):
"""
plots a time series to compare pace and heart rate values over time,
with an adjustable range for the last month, last six months, year-to-date and all time
"""
ts = tmp_m.copy()
ts.sort_values(by='gpstime_b',inplace=True)
fig = go.Figure()
fig.add_trace(
go.Scatter(x=ts['gpstime_b'], y=ts['最终使用m'],
mode='lines+markers',
name='lines',
line_shape='vh')
)
fig.update_xaxes(
title_text="日期",
rangeselector=dict(
buttons=list([
dict(count=1, label="1d", step="day", stepmode="backward"),
dict(count=7, label="7d", step="day", stepmode="backward"),
dict(count=14, label="14d", step="day", stepmode="backward"),
dict(count=1, label="1m", step="month", stepmode="backward"),
dict(count=3, label="3m", step="month", stepmode="backward"),
dict(count=6, label="6m", step="month", stepmode="backward"),
#dict(count=1, label="YTD", step="year", stepmode="todate"),
dict(count=1, label="1y", step="year", stepmode="backward"),
dict(step="all")
])
)
)
fig.update_yaxes(title='车重')
m_mean = ts['最终使用m'].mean()
fig.update_layout(
title_text="质量监测",
template='plotly_white',
# yaxis=dict(
# title='Pace',
# tickformat='%M:%S'
# )
width=1200,height=500,
shapes=[dict(
type= 'line',
line = dict(color='red', dash='dashdot'),
yref= 'y', y0= 60, y1= 60,
xref= 'paper', x0= 0, x1= 1,
),
dict(
type= 'line',
line = dict(color='green', dash='dashdot'),
yref= 'y', y0= m_mean, y1= m_mean,
xref= 'paper', x0= 0, x1= 1,
)]
)
return fig
fig=time_series(tmp_m)
st.plotly_chart(fig)
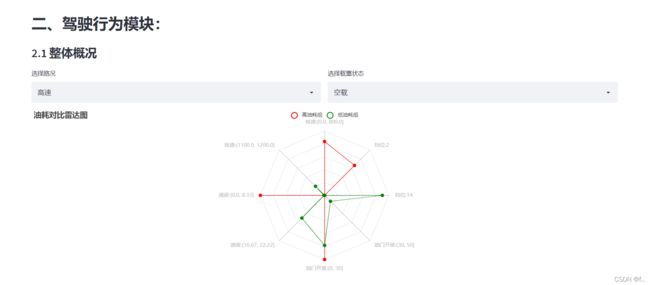
st.header('二、驾驶行为模块:')
st.subheader('2.1 整体概况')
col1,col2=st.columns(2)
with col1:
row_type_list=radar_df['row_type'].unique()
select_row_type = st.selectbox("选择路况",list(row_type_list))
with col2:
m_list=radar_df['m'].unique()
select_m = st.selectbox("选择载重状态",list(m_list))
cond=(radar_df['row_type']==select_row_type)&(radar_df['m']==select_m)
tmp = radar_df[cond]
v1 = [tmp['val_high'].tolist()]
v2 = [tmp['val_low'].tolist()]
schema = [opts.RadarIndicatorItem(name=i, max_=1) for i in tmp['index'].values ]
c = (
Radar()
.add_schema(
schema=schema
)
.add("高油耗组", v1, color="red")
.add("低油耗组", v2, color="green")
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
# legend_opts=opts.LegendOpts(selected_mode="single"),
title_opts=opts.TitleOpts(title="油耗对比雷达图"),
)
# .set_series_opts(label_opts=opts.LabelOpts(is_show=False))
# .set_global_opts(title_opts=opts.TitleOpts(title="Radar-空气质量"))
)
streamlit_echarts.st_pyecharts(c,height=400)
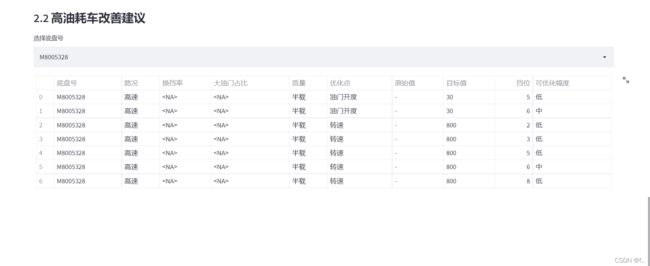
st.subheader('2.2 高油耗车改善建议')
#单元格合并待优化
id_list = improve['底盘号'].unique()
select_id = st.selectbox("选择底盘号",list(id_list))
car_better_df = improve.loc[improve['底盘号']==select_id].drop(['Unnamed: 0'],axis=1)
# car_better_df = improve.groupby(['底盘号','路况','质量','换挡率','大油门占比','优化点','原始值','目标值','挡位','可优化幅度'])['可优化幅度'].agg(['count']).reset_index()
# car_better_df=car_better_df.set_index(['底盘号','路况','质量'])
st.table(car_better_df)
4.requirements.txt 包含.py文件中所有需要的python依赖包
pandas
numpy
streamlit
datetime
matplotlib
seaborn
plotly
pyecharts
streamlit_echarts
5.构建 Docker 镜像
- 我们使用以下命令构建,然后是“.” 运行当前目录。
docker build -t streamlitapp:latest .- 您还可以使用以下命令来指定文件。
docker build -t streamlitapp:latest .f Dockerfile
- 输出将如下所示。
Sending building context to the Docker daemon 34.90kb
Step 1/8 : FROM python:3.8
--->d6568b1g3y4h
Step 2/8 : WORKDIR /app
--->Using Cache
--->25cyf5dfpbfd
Step 3/8 : COPY requirements.txt ./requirements.txt
--->Using Cache
--->52jdf5dffbfd
Step 4/8 : RUN pip install -r requiremts.txt
--->Using Cache
--->81cdf5dffedf
Step 5/8 : EXPOSE 8501
--->Using Cache
--->62d29afd9eb
Step 6/8 : COPY ./app
--->9rraeb07t4d
Step 6/8 : EXPOSE 8501
--->4b2ap4h557cc
Step 7/8 : ENTRYPOINT ["streamlit", "run"]
--->2egaeb07tdte
Removing intermediate container 5ta3824edte
---> 65dv092efstfu
step 8/8 : CMD ["drive_st_test.py"]
Successfully built 65dv092efstfu
Successfully tagged streamlitapp:latest
- 使用以下命令查看所有图像。
docker image ls
- 输出如图所示。
REPOSITORY TAG IMAGE ID CREATED SIZE
streamlitapp latest 65dv092efstfu 2 minutes ago 1.24GB
- 创建容器
docker run -p 8501:8501 streamlitapp:latest
结果:
gv092e0ff6btdte593a7dad8e50ef01f7t3e89fy41816624gdted7fu1h1bid1o它还会在以下 url 中启动我们的 streamlit 应用程序:
- 网络网址:http://172.17.0.2.8501
- 外部网址:https://193.106.63.249:8501
有了这个,Streamlit 应用程序现在与 docker 一起部署。
6.最终结果
streamlit其实是通过python实现一个web界面的可交互的数据分析报告,还是比较强大的。