阿里云安装CDH6.3.2并集成flink1.12
1.购买阿里云服务器,修改配置信息
如果有服务器可以跳过前面购买流程,如果没有服务器只是作为测试练习的话可使用抢占实例的服务器,一天几块钱(按小时使用时长收费)但是服务器有百分之0-3的回收率
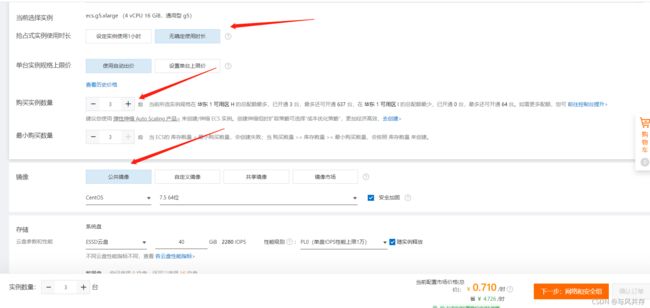
选择4核16GB的服务器,通用型g5最便宜所以选择这个

选择无确定使用时长。三台实例,镜像选择centos7.5,硬盘40GB
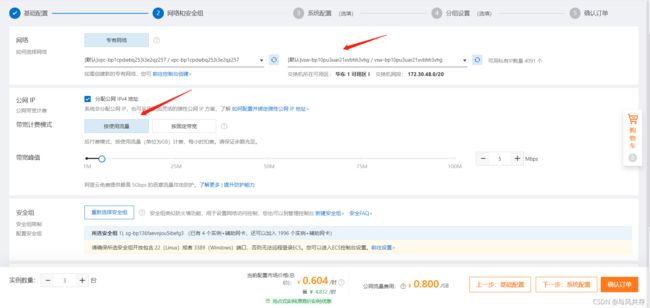
选择交换机所在地址,宽带峰值可自由调配,毕竟按流量收费
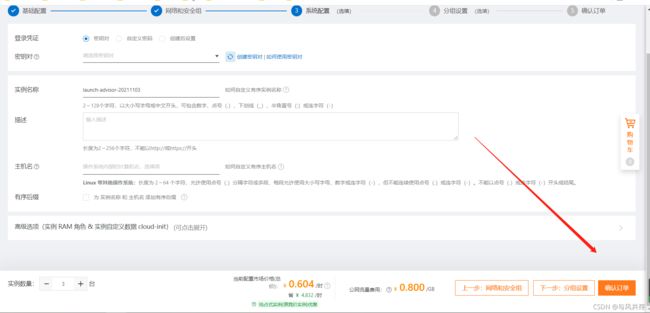
下一步确定订单
购买完成 8毛钱一个小时
在控制台看到服务器
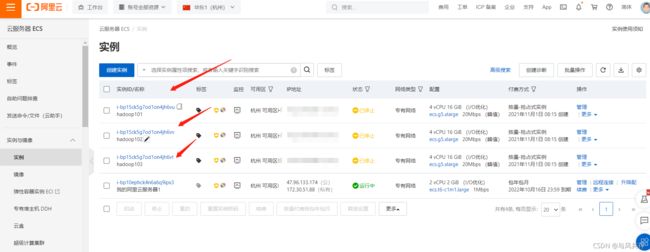
点击管理修改hostname 和机器名称

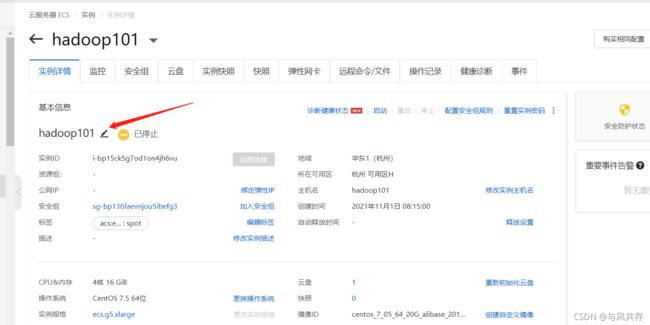

服务器名称改变

将三台服务器的共有ip和windows的host 进行配置

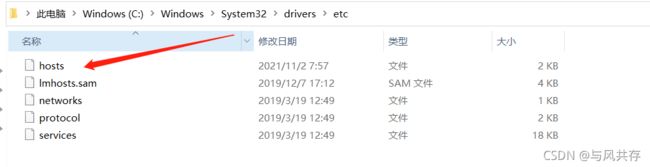
添加windows的host信息

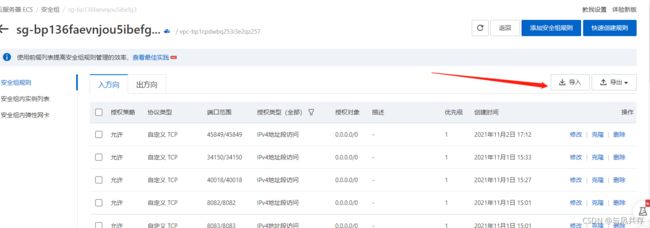
选择更多-网络和安全组-安全组配置
因为外网连接内网服务需要进行端口号开放

点击配置规则

授权对象为 开放的远程的ip 0.0.0.0/0为对所有远程用户开放
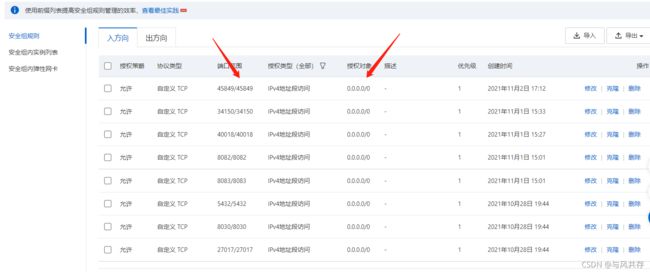
可以逐个添加需要用的ip

因为添加太过复杂本地有一份json的配置 直接导入即可

导入json文件
地址
https://blog.csdn.net/weixin_44067108/article/details/121126952
2.安装CDH
通过Xshell 或者其他远程工具 连接阿里云
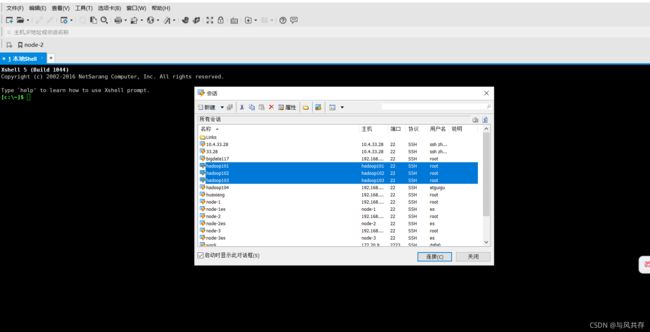
host为映射的host名字,密码为购买时配置的密码,如果密码忘记 可以选择重置密码
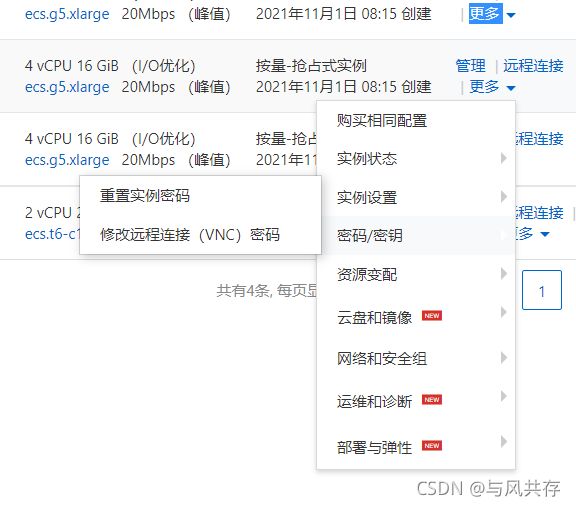
上传安装相关文件 可以网上寻找 因为CM官网已经收费(听说非常贵),可以网上寻找资源也可以私聊问我要资源

配置免密登录 在第一台进行 我的名字为hadoop101(安装在第一台)
ssh-keygen -t rsa
ssh-copy-id hadoop101
ssh-copy-id hadoop102
ssh-copy-id hadoop103
安装jdk
mkdir module
mkdir software
rpm -ivh oracle-j2sdk1.8-1.8.0+update181-1.x86_64.rpm
vim /etc/profile
加入下列配置
export JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera
export CLASSPATH=.: C L A S S P A T H : CLASSPATH: CLASSPATH:JAVA_HOME/lib
export PATH= P A T H : PATH: PATH:JAVA_HOME/bin
保存后 ,输入命令
source /etc/profile
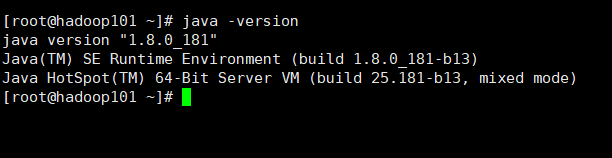
java -version
安装成功则显示
分发jdk
scp -r /usr/java/ hadoop102:/usr/
scp -r /usr/java/ hadoop103:/usr/
scp /etc/profile hadoop102:/etc/
scp /etc/profile hadoop103:/etc/
都输入 命令
source /etc/profile
java -version
安装MySQL
输入命令
yum install libaio
yum -y install autoconf
wget https://downloads.mysql.com/archives/get/p/23/file/MySQL-shared-compat-5.6.24-1.el6.x86_64.rpm
wget https://downloads.mysql.com/archives/get/p/23/file/MySQL-shared-5.6.24-1.el6.x86_64.rpm
rpm -ivh MySQL-shared-5.6.24-1.el6.x86_64.rpm
rpm -ivh MySQL-shared-compat-5.6.24-1.el6.x86_64.rpm
上传mysql-libs.zip到hadoop101的/opt/software目录,并解压文件到当前目录
yum install unzip
yum install unzip
安装MySQL服务端
进入到mysql-libs文件夹下
rpm -ivh MySQL-server-5.6.24-1.el6.x86_64.rpm
查看mysql产生的随机密码(第一次登陆mysql用)
cat /root/.mysql_secret
启动mysql
service mysql start
安装MySQL客户端
rpm -ivh MySQL-client-5.6.24-1.el6.x86_64.rp
mysql -uroot -p(输入随机到的密码)
SET PASSWORD=PASSWORD(‘自己要用的mysql密码’);
MySQL中user表中主机配置
use mysql;
select User, Host, Password from user;
设置访问的ip
update user set host=‘%’ where host=‘localhost’;
delete from user where host!=‘%’;
flush privileges;
安装mysql结束 进行退出
quit;
CM安装部署
MySQL中建相关CDH的库
GRANT ALL ON scm.* TO 'scm'@'%' IDENTIFIED BY 'scm';
CREATE DATABASE scm DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
CREATE DATABASE hive DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
CREATE DATABASE oozie DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
CREATE DATABASE hue DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
CM安装
将mysql-connector-java-5.1.27-bin.jar拷贝到/usr/share/java路径下,并重命名
tar -zxvf mysql-connector-java-5.1.27.tar.gz
cd mysql-connector-java-5.1.27
mv mysql-connector-java-5.1.27-bin.jar mysql-connector-java.jar
mkdir /usr/share/java
cp mysql-connector-java.jar /usr/share/java/
scp -r /usr/share/java/ hadoop102:/usr/share/
scp -r /usr/share/java/ hadoop103:/usr/share/


mkdir /opt/cloudera-manager
cd /opt/software/
tar -zxvf cm6.3.1-redhat7.tar.gz
cd cm6.3.1/RPMS/x86_64/
mv cloudera-manager-agent-6.3.1-1466458.el7.x86_64.rpm /opt/cloudera-manager/
mv cloudera-manager-server-6.3.1-1466458.el7.x86_64.rpm /opt/cloudera-manager/
mv cloudera-manager-daemons-6.3.1-1466458.el7.x86_64.rpm /opt/cloudera-manager/
cd /opt/cloudera-manager/
(3)安装cloudera-manager-daemons,安装完毕后多出/opt/cloudera目录
rpm -ivh cloudera-manager-daemons-6.3.1-1466458.el7.x86_64.rpm
cd /opt/
scp -r /opt/cloudera-manager/ hadoop102:/opt/
scp -r /opt/cloudera-manager/ hadoop103:/opt/
cd /opt/cloudera-manager/
rpm -ivh cloudera-manager-daemons-6.3.1-1466458.el7.x86_64.rpm
cd /opt/cloudera-manager/
rpm -ivh cloudera-manager-daemons-6.3.1-1466458.el7.x86_64.rpm
安装cloudera-manager-agent
yum install bind-utils psmisc cyrus-sasl-plain cyrus-sasl-gssapi fuse portmap fuse-libs /lib/lsb/init-functions httpd mod_ssl openssl-devel python-psycopg2 MySQL-python libxslt
rpm -ivh cloudera-manager-agent-6.3.1-1466458.el7.x86_64.rpm
yum install bind-utils psmisc cyrus-sasl-plain cyrus-sasl-gssapi fuse portmap fuse-libs /lib/lsb/init-functions httpd mod_ssl openssl-devel python-psycopg2 MySQL-python libxslt
rpm -ivh cloudera-manager-agent-6.3.1-1466458.el7.x86_64.rpm
yum install bind-utils psmisc cyrus-sasl-plain cyrus-sasl-gssapi fuse portmap fuse-libs /lib/lsb/init-functions httpd mod_ssl openssl-devel python-psycopg2 MySQL-python libxslt
rpm -ivh cloudera-manager-agent-6.3.1-1466458.el7.x86_64.rpm
安装agent的server节点(三台机器都修改)
vim /etc/cloudera-scm-agent/config.ini
server_host=hadoop101
安装cloudera-manager-server(不标明就是单台操作)
rpm -ivh cloudera-manager-server-6.3.1-1466458.el7.x86_64.rpm
上传CDH包导parcel-repo
CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel
CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel
manifest.json
将需要的文件资源(上面三个)上传到下面目录下
cd /opt/cloudera/parcel-repo
mv CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel.sha1 CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel.sha
修改server的db.properties
vim /etc/cloudera-scm-server/db.properties
com.cloudera.cmf.db.type=mysql
com.cloudera.cmf.db.host=hadoop101:3306
com.cloudera.cmf.db.name=scm
com.cloudera.cmf.db.user=scm
com.cloudera.cmf.db.password=scm
com.cloudera.cmf.db.setupType=EXTERNAL
启动server服务
/opt/cloudera/cm/schema/scm_prepare_database.sh mysql scm scm
/opt/cloudera/cm/schema/scm_prepare_database.sh mysql scm scm
启动agent节点(三台都启动)
systemctl start cloudera-scm-agent
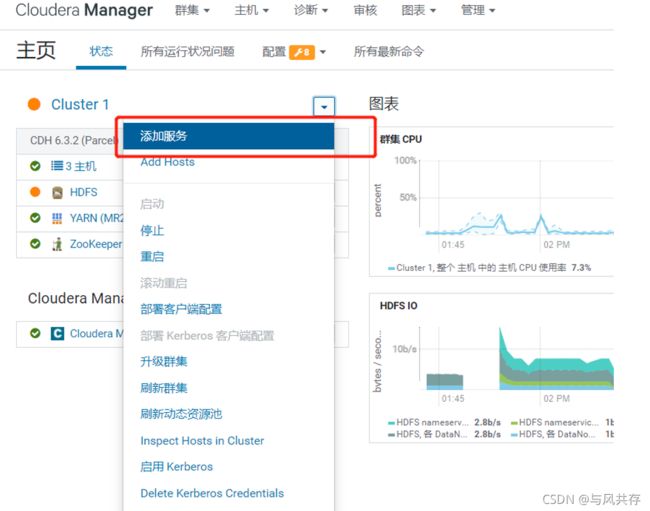
CM的集群部署
账号密码为 admin admin

集群安装




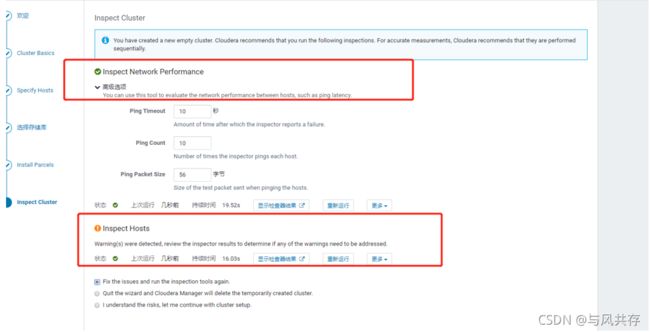
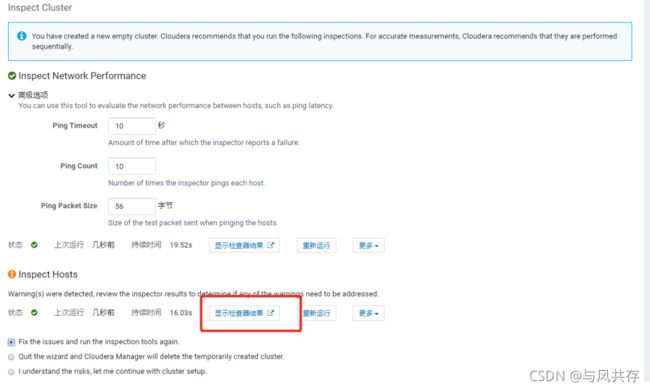

每台服务器执行
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo never > /sys/kernel/mm/transparent_hugepage/enabled
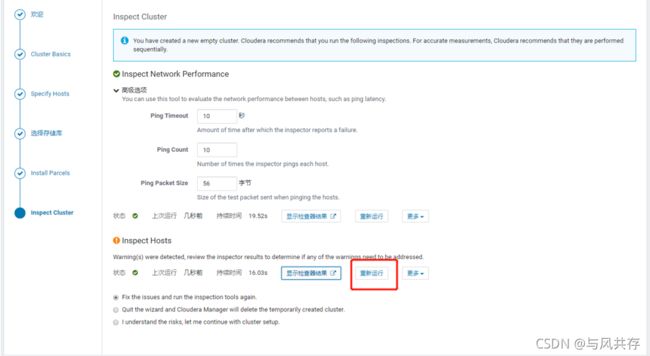






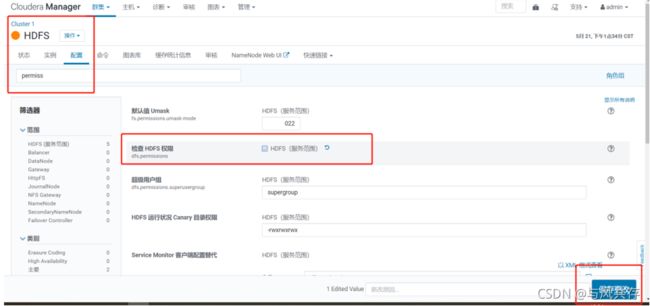
关闭HDFS中的权限检查:dfs.permissions。


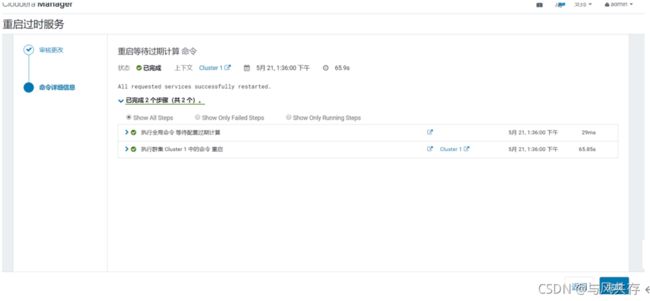
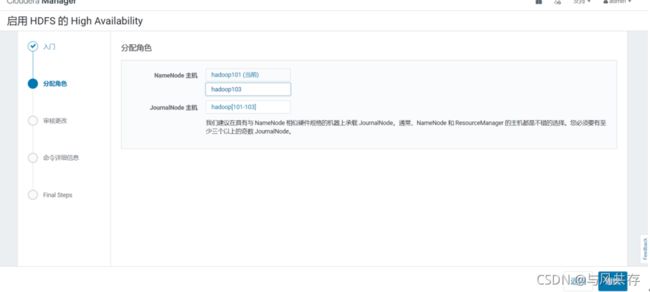
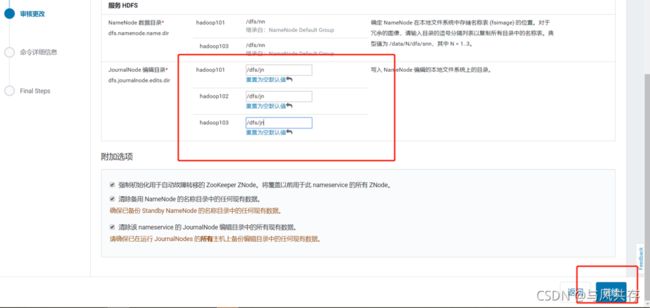
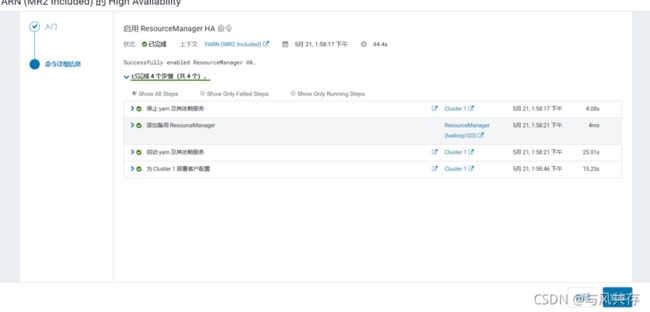
配置NameNode HA



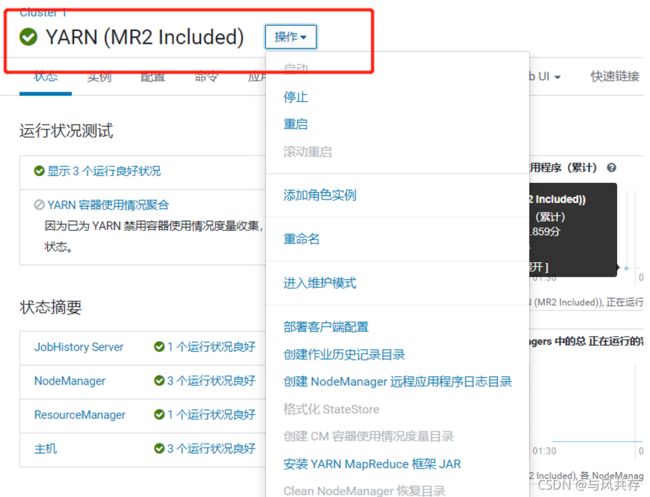

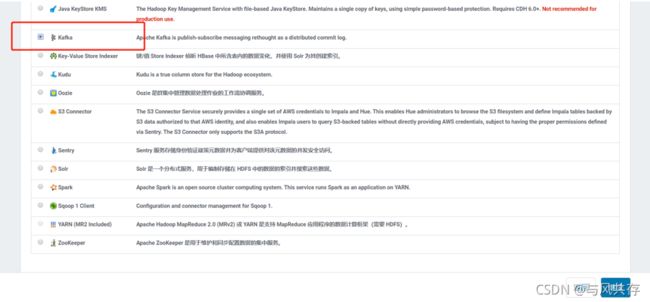
Kafka安装




Hive安装






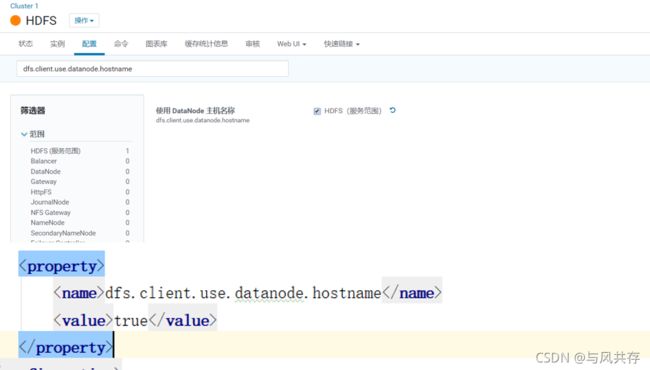
在阿里云环境下 Hadoop集群必须用域名访问,不能用IP访问,开启如下配置dfs.client.use.datanode.hostname
将每个任务容器默认大小从1G调大至4G,当前集群环境下每个节点的物理内存为8G,设置每个yarn可用每个节点内存为7G
修改yarn.scheduler.maximum-allocation-mb 每个任务容器内存所需大小

修改yarn.nodemanager.resource.memory-mb每个节点内存所需大小 修改为15G
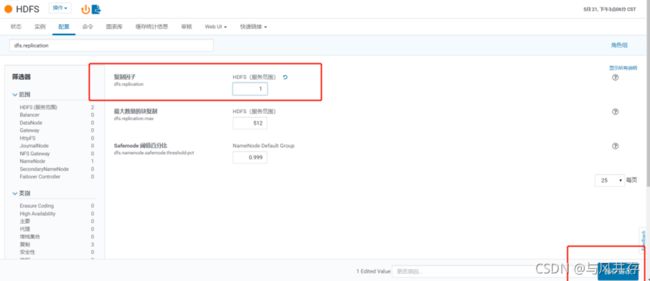
修改HDFS副本数(测试环境副本数改为1)
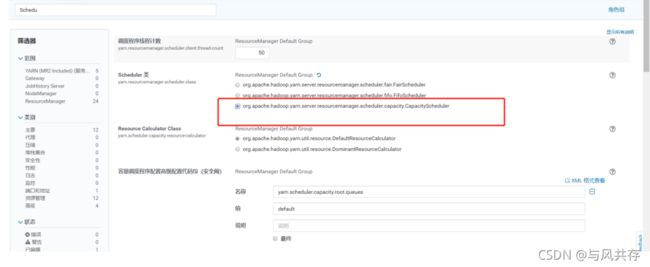
CDH默认公平调度器,修改为容量调度器
安装flink
需要上传的文件

将上传的资源移动到相应的目录下
jar包及文件放在 /opt/cloudera/csd/
其他放在 /opt/cloudera/parcel-repo```
进入到/opt/cloudera/parcel-repo/ 及 /opt/cloudera/csd/ 目录下,验证文件上传是否正确
激活 parcel包
在添加服务前需要重启cm-server
在cm-server机器上执行:
systemctl restart cloudera-scm-server
启用flink(我的电脑安装过了)


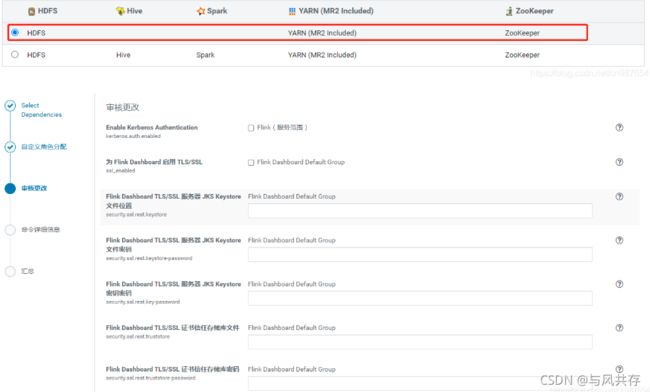
配置调整
这个是因为需要配置此组件的环境变量:
返回cm主界面—>选择flink-yarn组件—>选择配置—>搜索”环境”,添加如下配置
HADOOP_CONF_DIR=/etc/hadoop/conf
HADOOP_CLASSPATH=/opt/cloudera/parcels/CDH/jars/*
HADOOP_USER_NAME=flink

source /etc/profile
创建2个kafka的topic
kafka-topics --zookeeper hadoop102:2181 --create --replication-factor 2 --partitions 3 --topic basead
kafka-topics --zookeeper hadoop102:2181 --create --replication-factor 2 --partitions 10 --topic member
kafka-console-producer --topic basead --broker-list hadoop101:9092,hadoop102:9092,hadoop103:9092
kafka-console-consumer --bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092 --topic member
一个生产者一个消费者

编写flink代码


打包

将打包的文件上传至服务器


启动任务

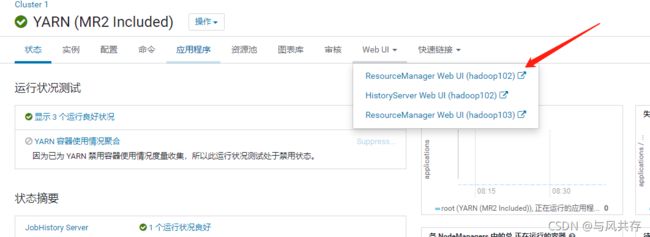
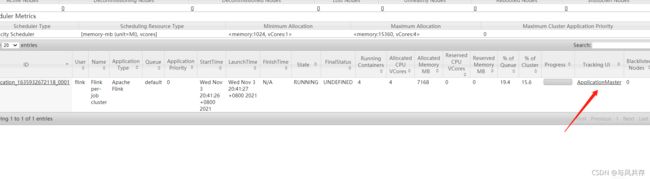
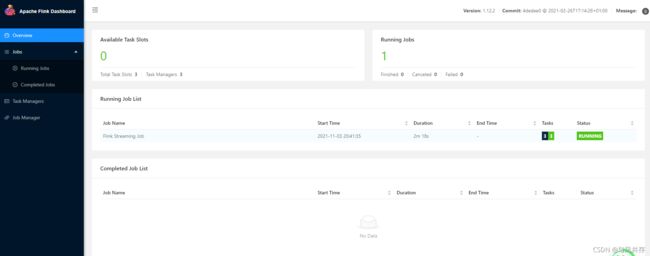
输入

kafka输出
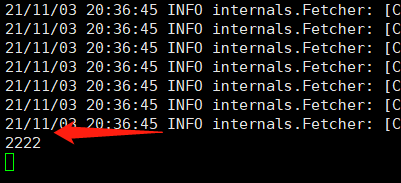

flink任务跑成功了完成