flink1.14 sql基础语法(二) flink sql表定义详解
flink1.14 sql基础语法(二) flink sql表定义详解
一、表的概念和类别
1.1 表的标识结构
每一个表的标识由 3 部分组成:
-
catalog name (常用于标识不同的“源”,比如 hive catalog,inner catalog 等)
-
database name(通常语义中的“库”)
-
table name (通常语义中的“表”)
package cn.yyds.sql;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Schema;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableDescriptor;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class _09_FlinkTableDb {
public static void main(String[] args) {
// 1、混合环境的创建
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 2、建表
TableDescriptor descriptor = TableDescriptor
.forConnector("kafka") // 指定连接器
.schema(
Schema.newBuilder() // 指定表结构
.column("id", DataTypes.INT())
.column("name", DataTypes.STRING())
.column("age", DataTypes.INT())
.column("gender", DataTypes.STRING())
.build()
)
.format("json")
.option("topic","kfa_person")
.option("properties.bootstrap.servers","centos01:9092")
.option("properties.group.id","g1")
.option("scan.startup.mode","earliest-offset")
.option("json.fail-on-missing-field","false")
.option("json.ignore-parse-errors","true")
.build();
Table table = tableEnv.from(descriptor);
// 注册在默认的catalog和默认的database中
tableEnv.createTemporaryView("kfa_person",table);
// 注册在默认的catalog和指定的database中
tableEnv.createTemporaryView("ods.kfa_person",table);
// 注册在指定的catalog和指定的database中(可以和hive整合,保存到mysql中)
tableEnv.createTemporaryView("hive_catalog.ods.kfa_person",table);
}
}
1个flinksql程序在运行时,tableEnvironment 通过持有一个 map 结构来记录所注册的 catalog;
public final class CatalogManager {
private static final Logger LOG = LoggerFactory.getLogger(CatalogManager.class);
private final Map<String, Catalog> catalogs;
private final Map<ObjectIdentifier, CatalogBaseTable> temporaryTables;
......
}
1.2 表和视图
Flinksql中的表,可以是 virtual的 (view 视图) 和 regular 的 (table 常规表)
-
table 描述了
一个物理上的外部数据源,如文件、数据库表、kafka 消息 topic -
view 则基于表创建,代表一个或多个表上的一段计算逻辑(就是对一段查询计划的逻辑封装);
不管是 table 还是 view,在 tableAPI 中得到的都是 Table 对象
1.3 临时和永久
临时表(视图) :
- 创建时带 temporary 关键字 (crate temporary view,createtemporary table)
永久表(视图) :
- 创建时不带 temporary 关键字 (create view ,create table )
临时表与永久表的本质区别: schema 信息是否被持久化存储
临时表(视图)
-
表 schema 只维护在所属 flink session
运行时内存中 -
当所属的 flink session 结束后表信息将不复存在,且该表无法在 flink session 间共享。
常规表(视图)
-
表 schema 可记录在外部持久化的元数据管理器中(比如 hive 的 metastore)
-
当所属 flink session 结束后,该表信息不会丢失,且在不同 flink session 中都可访问到该表的信息。
// sql 定义方式
tableEnv.executeSql("create view view_1 as select .. from projectedTable");
tableEnv.executeSql("create temporary view_2 as select .. from projectedTable");
tableEnv.executeSql("create table (id int,...) with ( 'connector'= ...)");
tableEnv.executeSql("create temporary table (id int,...) with ('connector'= ...)");
// table api方式
tenv.createTemporaryView("v_1", dataStreamschema);
tenv.createTemporaryView("v_1", table);
tenv.createTable("t_1", tableDescriptor);
tenv.createTemporaryTable("t_1", tableDescriptor);
二、表定义概览
2.1 Table Api创建

Table 对象获取方式解析:
-
从已注册的表
-
从 TableDescriptor (连接器/format/schema/options)
-
从 DataStream
-
从 Table 对象上的查询 api 生成
-
从测试数据
涉及的核心参数:
-
已注册的表名 (catalog name.database_name.object_name)
-
TableDescriptor (表描述器,核心是 connector 连接器)
-
Datastream(底层流)
-
测试数据值
package cn.yyds.sql;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Schema;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableDescriptor;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.kafka.clients.consumer.OffsetResetStrategy;
import static org.apache.flink.table.api.Expressions.$;
/**
* 创建table的几种方式
*
* 1、从已注册的表
* 2、从 TableDescriptor (连接器/format/schema/options)
* 3、从 DataStream
* 4、从 Table 对象上的查询 api 生成
* 5、从测试数据
*/
public class _04_TableCreate {
public static void main(String[] args) {
// 混合环境的创建
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 1、从 TableDescriptor (连接器/format/schema/options)
TableDescriptor descriptor = TableDescriptor
.forConnector("kafka") // 指定连接器
.schema(
Schema.newBuilder() // 指定表结构
.column("id", DataTypes.INT())
.column("name", DataTypes.STRING())
.column("age", DataTypes.INT())
.column("gender", DataTypes.STRING())
.build()
)
.format("json")
.option("topic","t_kafka_1")
.option("properties.bootstrap.servers","centos01:9092")
.option("properties.group.id","g1")
.option("scan.startup.mode","earliest-offset")
.option("json.fail-on-missing-field","false")
.option("json.ignore-parse-errors","true")
.build();
Table table1 = tableEnv.from(descriptor);
// 2、从已注册的表
Table table2 = tableEnv.from("t_kafka_1");
// 3、从 DataStream
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
// 设置订阅的目标主题
.setTopics("tp01")
// 设置消费者组id
.setGroupId("gp01")
// 设置kafka服务器地址
.setBootstrapServers("centos01:9092")
// 起始消费位移的指定:
// OffsetsInitializer.committedOffsets(OffsetResetStrategy.LATEST) 消费起始位移选择之前所提交的偏移量(如果没有,则重置为LATEST)
// OffsetsInitializer.earliest() 消费起始位移直接选择为 “最早”
// OffsetsInitializer.latest() 消费起始位移直接选择为 “最新”
// OffsetsInitializer.offsets(Map) 消费起始位移选择为:方法所传入的每个分区和对应的起始偏移量
.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.LATEST))
// 设置value数据的反序列化器
.setValueOnlyDeserializer(new SimpleStringSchema())
// 开启kafka底层消费者的自动位移提交机制
// 它会把最新的消费位移提交到kafka的consumer_offsets中
// 就算把自动位移提交机制开启,KafkaSource依然不依赖自动位移提交机制
// (宕机重启时,优先从flink自己的状态中去获取偏移量<更可靠>)
.setProperty("auto.offset.commit", "true")
.build();
// env.addSource(); // 接收的是 SourceFunction接口的 实现类
DataStreamSource<String> streamSource = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kfk-source");// 接收的是 Source 接口的实现类
Table table3 = tableEnv.fromDataStream(streamSource);
// 4、从 Table 对象上的查询 api 生成
Table table4 = table1.groupBy($("gender"))
.select($("gender"), $("age").avg().as("avg_age"));
// 5、从测试数据
Table table5 = tableEnv.fromValues(
DataTypes.ROW(
DataTypes.FIELD("id", DataTypes.INT()),
DataTypes.FIELD("name", DataTypes.STRING()),
DataTypes.FIELD("info", DataTypes.MAP(DataTypes.STRING(), DataTypes.STRING())),
DataTypes.FIELD("ts1", DataTypes.TIMESTAMP(3)),
DataTypes.FIELD("ts3", DataTypes.TIMESTAMP_LTZ(3))
),
Row.of(1, "a", null, "2023-02-02 13:00:00.200", 1654236105000L)
);
}
}
2.2 Table Sql创建
注册 sql表 (视图)方式
-
从已存在的 datastream 注册
-
从已存在的 Table 对象注册
-
从 TableDescriptor (连接器)注册
-
执行 Sql 的 DDL 语句来注册
package cn.yyds.sql;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Schema;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableDescriptor;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.kafka.clients.consumer.OffsetResetStrategy;
/**
* 注册 sql表 (视图)方式
* 从已存在的 datastream 注册
* 从已存在的 Table 对象注册
* 从 TableDescriptor (连接器)注册
* 执行 Sql 的 DDL 语句来注册
*/
public class _04_SqlCreate {
public static void main(String[] args) {
// 混合环境的创建
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 1、从 TableDescriptor (连接器)注册
TableDescriptor descriptor = TableDescriptor
.forConnector("kafka") // 指定连接器
.schema(
Schema.newBuilder() // 指定表结构
.column("id", DataTypes.INT())
.column("name", DataTypes.STRING())
.column("age", DataTypes.INT())
.column("gender", DataTypes.STRING())
.build()
)
.format("json")
.option("topic","t_kafka_1")
.option("properties.bootstrap.servers","centos01:9092")
.option("properties.group.id","g1")
.option("scan.startup.mode","earliest-offset")
.option("json.fail-on-missing-field","false")
.option("json.ignore-parse-errors","true")
.build();
tableEnv.createTable("kfk_person",descriptor);
// 2、从已存在的 datastream 注册
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
// 设置订阅的目标主题
.setTopics("tp01")
// 设置消费者组id
.setGroupId("gp01")
// 设置kafka服务器地址
.setBootstrapServers("centos01:9092")
// 起始消费位移的指定:
.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.LATEST))
// 设置value数据的反序列化器
.setValueOnlyDeserializer(new SimpleStringSchema())
.setProperty("auto.offset.commit", "true")
.build();
DataStreamSource<String> streamSource = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kfk-source");// 接收的是 Source 接口的实现类
tableEnv.createTemporaryView("kfk_source",streamSource);
// 3、从已存在的 Table 对象注册
Table table = null;
tableEnv.createTemporaryView("k_table",table);
// 4、执行 Sql 的 DDL 语句来注册
tableEnv.executeSql("create table t_kafka_1(\n" +
" id int,\n" +
" name string,\n" +
" age int,\n" +
" gender string\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 't_kafka_1',\n" +
" 'properties.bootstrap.servers' = 'centos01:9092',\n" +
" 'properties.group.id' = 'g1',\n" +
" 'format' = 'json',\n" +
" 'scan.startup.mode' = 'earliest-offset',\n" +
" 'json.fail-on-missing-field' = 'false',\n" +
" 'json.ignore-parse-errors' = 'true'\n" +
")");
}
}
三、Catalog详解
3.1 catalog概念
catalog 就是一个元数据空间,简单说就是记录、获取元数据(表定义信息)的实体。
flink sql 在运行时,可以拥有多个 catalog,它们由 catalogManager 模块来注册、管理。
CatalogManager 中可以注册多个元数据空间。
1、环境创建之初,就会初始化一个默认的元数据空间
-
空间名称: default_catalog
-
空间实现类: GenericInMemoryCatalog(基于内存)
public class GenericInMemoryCatalog extends AbstractCatalog {
public static final String DEFAULT_DB = "default";
// 用于记录 本catalog空间所有database
private final Map<String, CatalogDatabase> databases;
// 用于记录 本catalog空间所有table
private final Map<ObjectPath, CatalogBaseTable> tables;
......
}
2、用户还可以向环境中注册更多的 catalog,如下代码新增注册了一个 hivecatalog
// 创建hive元数据空间的实现对象
HiveCatalog hiveCatalog = new HiveCatalog("hive", "default", "d:/conf/hiveconf");
// 将hive的元数据对象注册到环境中
tableEnv.registerCatalog("hive_catalog",hiveCatalog);
注意:需要导入jar包,并把hive-site.xml的配置文件放入到hiveconf目录下
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-sql-connector-hive-3.1.2_2.12artifactId>
<version>${flink.version}version>
dependency>
3.2 临时表与永久表的底层差异
结论 1: 如果选择 hive 元数据空间来创建表、视图,则
-
永久表(视图)的元信息,都会被写入 hive 的元数据管理器中,从而可以实现永久存
-
在临时表(视图)的元信息,并不会写入 hive 的元数据管理其中,而是放在 catalogManager 的一个 temporaryTables 的内存 hashmap 中记录
-
临时表空间中的表名(全名) 如果与 hive 空间中的表名相同,则查询时会优先选择临时表空间的表
结论 2: 如果选择 GenericInMemoryCatalog 元数据空间来创建表、视图,则
-
永久表(视图)的元信息,都会被写入 GenericInMemoryCatalog 的元数据管理器中(
内存中) -
临时表(视图)的元信息,放在 catalogManager 的一个 temporaryTables 的内存 hashmap 中记
3.3 理解Hive catalog
flink sql利用 hive catalog 来建表 (查询、修改、删除表),本质上只是利用了 hive 的 metastore 服务
更具体来说,flinksql 只是把 flinksal 的表定义信息,按照 hive 元数据的形式,托管到 hive 的 metastore中而已。
当然,hive 中也能看到这些托管的表信息,但是,并不能利用它底层的 mapreduce 或者 spark 引擎来查询这些表
因为 mapreduce 或者 spark 引擎,并不能理解 flinksql 表定义中的信息,也无法为这些定义信息提供相应的组件去读取数据(比如,mr 或者 spark 就没有 flinksql 中的各种 connector 组件)
四、表定义详解
定义表时所需的核心要素
-
表名 (catalog_name.database_name.object_name)
-
TableDescriptor
TableDescriptor 核心要素
-
Schema 表结构(字段)
-
Format 数据格式
-
Connector 连接器
-
Option 连接器参数
4.1 Schema字段定义详解
4.1.1 physical column(物理字段)
物理字段: 源自于外部存储系统本身 schema 中的字段
如 kafka 消息的 key、value (json 格式)中的字段;mysql表中的字段…
-- 一些连接器需要设置主键,例如upsert-kafka,因为支持change-log流
-- 单字段主键约束语法
id INT PRIMARY KEY NOT ENFORCED ,
name STRING
-- 多字段主键约束语法:
id,
name,
PRIMARY KEY(id,name) NOT ENFORCED
4.1.2 computed column(表达式字段)
表达式字段(逻辑字段) : 在物理字段上施加一个 sql 表达式,并将表达式结果定义为一个字段。
4.1.3 metadata column(元数据字段)
元数据字段: 来源于 connector 从外部存储系统中获取到的 外部系统元信息
比如,kafka 的消息,通常意义上的数据内容是在 record 的 key 和 value 中的,而实质上 (底层角度来看), kafka 中的每一条 record,不光带了 key 和 value 数据内容,还带了这条record 所属的 topic,所属的 partition,所在的 offset,以及 record 的 timetamp 和 timestamp 类型等“元信息”。
fink 的 connector 可以获取并暴露这些元信息,并允许用户将这些信息定义成 flinksal表中的字段
官网中可以查到暴露的元数据字段
比如kafka元数据字段: https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/kafka/

// DDL方式
tableEnv.executeSql("create table t_kafka_person(\n" +
" id int, -- 物理字段\n" +
" name string, -- 物理字段\n" +
" nick string, -- 物理字段\n" +
" age int, -- 物理字段\n" +
" big_age as age + 10, -- 表达式字段\n" +
" my_offset bigint METADATA FROM 'offset', --元数据字段,来自kafka\n" +
" ts TIMESTAMP_LTZ(3) METADATA FROM 'timestamp', --元数据字段,来自kafka\n" +
" gender string\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 't_kafka_2',\n" +
" 'properties.bootstrap.servers' = 'centos01:9092',\n" +
" 'properties.group.id' = 'g1',\n" +
" 'format' = 'json',\n" +
" 'scan.startup.mode' = 'earliest-offset',\n" +
" 'json.fail-on-missing-field' = 'false',\n" +
" 'json.ignore-parse-errors' = 'true'\n" +
")");
// API 方式
TableDescriptor descriptor = TableDescriptor
.forConnector("kafka") // 指定连接器
.schema(
Schema.newBuilder() // 指定表结构
.column("id", DataTypes.INT()) //column是物理字段
.column("name", DataTypes.STRING()) //column是物理字段
.column("nick", DataTypes.STRING()) //column是物理字段
.column("age", DataTypes.INT()) //column是物理字段
.column("gender", DataTypes.STRING()) //column是物理字段
.columnByExpression("big_age","age + 10") // 声明表达式字段
.columnByMetadata("my_offset",DataTypes.BIGINT(),"offset") // 声明元数据字段
// 声明元数据字段 isVirtual表示,当这个表被当作sink表时候,该字段是否出现在schema中
.columnByMetadata("ts",DataTypes.TIMESTAMP_LTZ(3),"timestamp",true)
/*.primaryKey("id")*/ // 主键约束,upsert-kafka需要填写主键
.build()
)
.format("json")
.option("topic","t_kafka_2")
.option("properties.bootstrap.servers","centos01:9092")
.option("properties.group.id","g1")
.option("scan.startup.mode","earliest-offset")
.option("json.fail-on-missing-field","false")
.option("json.ignore-parse-errors","true")
.build();
4.2 format概述
connector 连接器在对接外部存储时,根据外部存储中的数据格式不同,需要用到不同的 format 组件
format 组件的作用就是:告诉连接器,如何解析外部存储中的数据及映射到表 schema
format 组件的使用要点
-
导入 format 组件的 jar 包依赖
-
指定 format 组件的名称
-
设置 format 组件所需的参数(不同 format 组件有不同的参数配置需求)
官网:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/formats/overview/

4.2.1 json format
官网:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/formats/json/
1、需要引入依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-jsonartifactId>
<version>1.14.4version>
dependency>
2、常用参数
| 参数 | 是否必须 | 默认值 | 类型 | 描述 |
|---|---|---|---|---|
| format | required | (none) | String | 组件名json |
| json.fail-on-missing-field | optional | false | Boolean | 缺失字段是否失败 |
| json.ignore-parse-errors | optional | false | Boolean | 是否忽略json解析错误 |
| json.timestamp-format.standard | optional | 'SQL' |
String | json中timestamp类型字段格式 |
| json.map-null-key.mode | optional | 'FAIL' |
String | 可选值'FAIL', 'DROP' ,'LITERAL' |
| json.map-null-key.literal | optional | ‘null’ | String | 替换null的字符串 |
3、数据类型映射
| Flink SQL type | JSON type |
|---|---|
CHAR / VARCHAR / STRING |
string |
BOOLEAN |
boolean |
BINARY / VARBINARY |
string with encoding: base64 |
DECIMAL |
number |
TINYINT |
number |
SMALLINT |
number |
INT |
number |
BIGINT |
number |
FLOAT |
number |
DOUBLE |
number |
DATE |
string with format: date |
TIME |
string with format: time |
TIMESTAMP |
string with format: date-time |
TIMESTAMP_WITH_LOCAL_TIME_ZONE |
string with format: date-time (with UTC time zone) |
INTERVAL |
number |
ARRAY |
array |
MAP / MULTISET |
object |
ROW |
object |
4、使用案例(复杂json解析)
package cn.yyds.sql;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* 文件中有如下的数据:
*
* {"id":10, "name":"tom", "age":28, "ts":"2023-03-02 00:00:00.000"}
*/
public class _10_JsonFormatTest1 {
public static void main(String[] args) {
// 创建环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
tableEnv.executeSql("create table t_kafka_p(\n" +
" id int,\n" +
" name string,\n" +
" age int,\n" +
" ts TIMESTAMP(3)\n" +
") WITH (\n" +
" 'connector' = 'filesystem',\n" +
" 'path' = 'file:///D:/works/flink-live/files/sql-data/test1.txt',\n" +
" 'format' = 'json',\n" +
" 'json.ignore-parse-errors' = 'true'\n" +
")");
tableEnv.executeSql("select * from t_kafka_p").print();
}
}
+----+-------------+--------------------------------+-------------+-------------------------+
| op | id | name | age | ts |
+----+-------------+--------------------------------+-------------+-------------------------+
| +I | 10 | tom | 28 | 2023-03-02 00:00:00.000 |
+----+-------------+--------------------------------+-------------+-------------------------+
复杂json类型的解析
{
"id":1238123899121,
"name":"hank",
"date":"2022-10-14",
"obj":{
"time1":"12:12:43Z",
"str":"sfasfafs",
"lg":2324342345
},
"arr":[
{
"f1":"f1str11",
"f2":134
},
{
"f1":"f1str22",
"f2":555
}
],
"time":"12:12:43Z",
"timestamp":"2022-10-14T12:12:43Z",
"map":{
"flink":123
},
"mapinmap":{
"inner_map":{
"key":234
}
}
}
-- 复杂json解析的表定义
CREATE TABLE json_source (
id BIGINT,
name STRING,
`date` DATE,
obj ROW<time1 TIME,str STRING,lg BIGINT>,
arr ARRAY<ROW<f1 STRING,f2 INT>>,
`time` TIME,
`timestamp` TIMESTAMP(3),
`map` MAP<STRING,BIGINT>,
mapinmap MAP<STRING,MAP<STRING,INT>>,
proctime as PROCTIME()
) WITH (
'connector' = 'filesystem',
'path' = 'file:///D:\doit\works\flink-live\files\sql-data\test3.txt',
'format' = 'json',
'json.ignore-parse-errors' = 'true'
);
-- 从表中获取数据
-- 注意数组index从1开始
select id, name,`date`,obj.str,arr[1].f1,`map`['flink'],mapinmap['inner_map']['key'] from json_source;
4.2.2 csv format
官网: https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/formats/csv/
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-csvartifactId>
<version>1.14.4version>
dependency>
参数解释
| 参数 | 是否必须 | 默认值 | 类型 | 描述 |
|---|---|---|---|---|
| format | required | (none) | String | csv |
| csv.field-delimiter | optional | , |
String | 分割符 |
| csv.allow-comments | optional | false | Boolean | 是否允许注释'默认#开头注释' |
| csv.ignore-parse-errors | optional | false | Boolean | 是否忽略解析错误 |
| csv.array-element-delimiter | optional | ; |
String | 数组元素之间分隔符 |
| csv.escape-character | optional | (none) | String | 转义字符 |
| csv.null-literal | optional | (none) | String | null的字面量字符串 |
4.3 watermark和时间属性
时间属性定义,主要是用于各类基于时间的运算操作(如基于时间窗口的查询计算)。
4.3.1 eventTime和watermark定义
核心要点:
-
需要一个 timestamp(3)类型字段(可以是物理字段,也可以是表达式字段,也可以是元数据字段)
-
需要用一个 watermarkExpression 来指定 watermark 策略
package cn.yyds.sql;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Schema;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class _11_SqlWatermark {
public static void main(String[] args) {
// 创建环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// guid,uuid,eventId,pageId,ts
DataStreamSource<String> sourceStream = env.socketTextStream("centos04", 9999);
SingleOutputStreamOperator<EventBean> mapStream = sourceStream.map(line -> {
String[] arr = line.split(",");
return new EventBean(Integer.parseInt(arr[0]), arr[1], arr[2], arr[3], Long.parseLong(arr[4]));
});
// 分配wm
SingleOutputStreamOperator<EventBean> wmStream = mapStream.assignTimestampsAndWatermarks(
WatermarkStrategy.<EventBean>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<EventBean>() {
@Override
public long extractTimestamp(EventBean eventBean, long l) {
return eventBean.getTs();
}
})
);
// 转换为table
Table table = tableEnv.fromDataStream(wmStream,
Schema.newBuilder()
// 声明表达式字段,并声明为 processing time 属性字段
// .columnByExpression("pt","proctime()")
// 声明表达式字段
.columnByExpression("rt","to_timestamp_ltz(ts, 3)")
// 将 rt 字段指定为 event time 属性字段,并基于它指定 watermark 策略: = rt
.watermark("rt","rt")
// 将 rt 字段指定为 event time 属性字段,并基于它指定 watermark 策略: = rt-8s
.watermark("rt","rt - interval '8' second")
// 将 rt 字段指定为 event time 属性字段,并沿用“源头流”的 watermark
.watermark("rt","source_watermark()")
.build()
);
table.printSchema();
}
}
-- DDL方式定义水位线
-- {"id":1,"eventId":"e1","ts":1679754806020,"pageId":"p01"}
--加上水位线及处理时间
create table t_kafka_wm(
id int,
eventId string,
ts bigint,
pageId string, -- 物理字段
pt as PROCTIME(), -- 声明处理时间
wc_time as TO_TIMESTAMP_LTZ(ts, 3), -- 表达式字段,将long转换为TIMESTAMP_LTZ
WATERMARK FOR wc_time AS wc_time - INTERVAL '5' SECOND -- 水位线
) WITH (
'connector' = 'kafka',
'topic' = 't_kafka_3',
'properties.bootstrap.servers' = 'centos01:9092',
'properties.group.id' = 'g1',
'format' = 'json',
'scan.startup.mode' = 'earliest-offset',
'json.fail-on-missing-field' = 'false',
'json.ignore-parse-errors' = 'true'
)
4.3.2 processing time
定义一个表达式字段,并用表达式 proctime() 将其声明为 processing time 即可;
// 转换为table
Table table = tableEnv.fromDataStream(wmStream,
Schema.newBuilder()
// 声明表达式字段,并声明为 processing time 属性字段
.columnByExpression("pt","proctime()")
.build()
)
4.3.3 表和流之间水位线的传递
4.3.3.1 流转表的时候
流转表的过程中,无论“源流”是否存在 watermark,都不会自动传递 watermark
如需时间运算(如时间窗口等),需要在转换定义中显式声明 watermark 策略
- 先设法定义一个
timestamp(3)或者timestamp_ltz(3)类型的字段 (可以来自于数据字段,也可以来自于一个元数据: rowtime)
rt as to_timestamp_ltz(ts,3) -- 从一个bigint中得到timestamp(3)类型的字段
rt timestamp(3) metadata from 'rowtime'
- 然后基于该字段,用 watermarkExpression 声明 watermark 策略
watermark for rt AS rt - interval '1' second
watermark for rt AS source_watermark() -- 代表使用底层流的 watermark 策略
4.3.3.2 表转流的时候
源表定义了 wartermark 策略,则将表转成流时,将会自动传递源表的 watermark。
/**
* 前提:table是一个存在watermark的表对象
*/
tableEnv.toDataStream(table)
.process(new ProcessFunction<Row, String>() {
@Override
public void processElement(Row value, Context ctx, Collector<String> out) throws Exception {
long watermark = ctx.timerService().currentWatermark();
System.out.println(watermark + "=>" + value);
}
}).print();
4.4 connector详解
-
connector 通常是用于对接外部存储建表(源表或目标表)时的映射器、桥接器
-
connector 本质上是对 flink 的 table source /table sink 算子的封装
连接器使用的核心要素
-
1、导入连接器jar 包依赖
-
2、指定连接器类型名
-
3、指定连接器所需的参数 (不同连接器有不同的参数配置需求)
-
4、获取连接器所提供的元数据
flink1.14支持的连接器

4.4.1 kafka连接器
产生的数据以及能接受的数据流,是 append-only 流 (只有 +I 这种 changemode)
所需依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka_2.12artifactId>
<version>1.14.4version>
dependency>
入门案例
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
)
复杂案例
解析kafka生产者产生具有key以及headers的数据
package cn.yyds.sql;
import com.alibaba.fastjson.JSONObject;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.header.Header;
import org.apache.kafka.common.header.internals.RecordHeader;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.*;
/**
* 生产者生产数据
*/
public class _12_KafkaProducer {
public static void main(String[] args) throws InterruptedException {
// 泛型 K: 要发送的数据中的key
// 泛型 V: 要发送的数据中的value
// 隐含之意: kafka中的 message,是 Key-value结构的 (可以没有key)
Properties props = new Properties();
// 因为kafka底层的存储是没有类型维护机制的,用户所发的所有数据类型,都必须变成 序列化后的byte[]
// 所以,kafka的producer需要一个针对用户要发送的数据类型的序列化工具类
// 且这个序列化工具类,需要实现kafka所提供的序列工具接口: org.apache.kafka.common.serialization.Serializer
props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "centos01:9092,centos02:9092,centos03:9092");
props.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.setProperty(ProducerConfig.ACKS_CONFIG, "all"); // 消息发送应答级别
// 构造一个生产者客户端
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 检查是否发送成功的消费者命令:
// kafka-console-consumer.sh --bootstrap-server centos01:9092 --topic abcd
for(int i = 0; i < 10; i++){
// 将业务数据封装成客户端所能发送的封装格式
// 0->abc0
// 1->abc1
List<Header> headers = new ArrayList<>();
headers.add(new RecordHeader("k1", "v1".getBytes()));
JSONObject jsonObject = new JSONObject();
jsonObject.put("guid",i);
jsonObject.put("pageId","page" + i);
jsonObject.put("eventId","e" + i);
jsonObject.put("eventTime",System.currentTimeMillis());
ProducerRecord<String, String> message = new ProducerRecord<>("abcd", 0, "key_" + (i % 3), jsonObject.toJSONString(),headers);
// 调用客户端去发送
// 数据的发送动作在producer的底层是异步线程去异步发送的
producer.send(message);
Thread.sleep(100);
}
// 关闭客户端
producer.close();
}
}
{"eventId":"e0","eventTime":1680615780889,"guid":0,"pageId":"page0"}
{"eventId":"e1","eventTime":1680615781420,"guid":1,"pageId":"page1"}
{"eventId":"e2","eventTime":1680615781521,"guid":2,"pageId":"page2"}
{"eventId":"e3","eventTime":1680615781622,"guid":3,"pageId":"page3"}
{"eventId":"e4","eventTime":1680615781724,"guid":4,"pageId":"page4"}
{"eventId":"e5","eventTime":1680615781825,"guid":5,"pageId":"page5"}
{"eventId":"e6","eventTime":1680615781925,"guid":6,"pageId":"page6"}
{"eventId":"e7","eventTime":1680615782027,"guid":7,"pageId":"page7"}
{"eventId":"e8","eventTime":1680615782129,"guid":8,"pageId":"page8"}
{"eventId":"e9","eventTime":1680615782229,"guid":9,"pageId":"page9"}
·
-- 解析kafka
create table t_kafka_w(
guid int,
pageId string,
eventId string,
eventTime bigint,
msgkey string,
`partition` bigint METADATA VIRTUAL,
`offset` bigint METADATA VIRTUAL,
`headers` MAP<string,bytes> METADATA FROM 'headers'
) WITH (
'connector' = 'kafka',
'topic' = 'abcd',
'properties.bootstrap.servers' = 'centos01:9092',
'properties.group.id' = 'g1',
--'format' = 'json',
'key.format' = 'raw', -- 解析key用raw
'key.fields' = 'msgkey',
'value.format' = 'json', -- 解析value用json
-- 解析key的值是,要加上 'value.fields-include' = 'EXCEPT_KEY' 参数
-- 不然这个 key_field列也会被当成 value 的一部分参与 value 的解析,从而导致解析不出来数据
'value.fields-include' = 'EXCEPT_KEY',
'scan.startup.mode' = 'earliest-offset'
)
-- 查找数据
select guid,pageId,eventId,eventTime,msgkey,`partition`,`offset`,cast(headers['k1'] as string) as headers_value from t_kafka_w
+----+-------------+--------------------------------+--------------------------------+----------------------+--------------------------------+----------------------+----------------------+--------------------------------+
| op | guid | pageId | eventId | eventTime | msgkey | partition | offset | headers_value |
+----+-------------+--------------------------------+--------------------------------+----------------------+--------------------------------+----------------------+----------------------+--------------------------------+
| +I | 0 | page0 | e0 | 1680615780889 | key_0 | 0 | 0 | v1 |
| +I | 1 | page1 | e1 | 1680615781420 | key_1 | 0 | 1 | v1 |
| +I | 2 | page2 | e2 | 1680615781521 | key_2 | 0 | 2 | v1 |
| +I | 3 | page3 | e3 | 1680615781622 | key_0 | 0 | 3 | v1 |
| +I | 4 | page4 | e4 | 1680615781724 | key_1 | 0 | 4 | v1 |
| +I | 5 | page5 | e5 | 1680615781825 | key_2 | 0 | 5 | v1 |
| +I | 6 | page6 | e6 | 1680615781925 | key_0 | 0 | 6 | v1 |
| +I | 7 | page7 | e7 | 1680615782027 | key_1 | 0 | 7 | v1 |
| +I | 8 | page8 | e8 | 1680615782129 | key_2 | 0 | 8 | v1 |
| +I | 9 | page9 | e9 | 1680615782229 | key_0 | 0 | 9 | v1 |
4.4.2 upsert kafka连接器
所需依赖和kafka相同。
作为source
根据所定义的主键,将读取到的数据转换为 +I/-U/+U 记录,如果读到 null,则转换为-D 记录。
-- kafka 中假设有如下数据
1,zs,18
1,zs,28
-- kafka-connector产生出 appendonly 流
+I[1,zs,18]
+I[1,zs,28]
-- upsert-kafka-connector 产生出 upsert 模式的 changelog 流
+I [1,zs,18]
-U [1,zs,18]
+U [1,zs,28]
作为sink
-
对于 -U/+U/+I 记录,都以正常的 append 消息写入 kafka
-
对于-D 记录,则写入一个 null 到 kafka 来表示 delete 操作:
案例
package cn.yyds.sql;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class _13_UpsertKafka {
public static void main(String[] args) {
// 创建环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 创建测试数据
Table table = tableEnv.fromValues(
DataTypes.ROW(
DataTypes.FIELD("province", DataTypes.STRING()),
DataTypes.FIELD("user_id", DataTypes.STRING())
),
Row.of("sh","u001"),
Row.of("sh","u002"),
Row.of("sh","u003")
);
tableEnv.createTemporaryView("s_source",table);
// 创建upsert-kafka sink表
tableEnv.executeSql("create table t_upsert_kafka_w(\n" +
" province string,\n" +
" pv bigint, \n" +
" primary key(province) not enforced -- 需要设置主键字段 \n" +
") WITH (\n" +
" 'connector' = 'upsert-kafka',\n" +
" 'topic' = 't_upsert_kafka',\n" +
" 'properties.bootstrap.servers' = 'centos01:9092',\n" +
" 'key.format' = 'csv',\n" +
" 'value.format' = 'csv'\n" +
")");
tableEnv.executeSql("insert into t_upsert_kafka_w select province,count(distinct user_id) as uv from s_source group by province");
/**
*+----+--------------------------------+----------------------+
* | op | province | uv |
* +----+--------------------------------+----------------------+
* | +I | sh | 1 |
* | -U | sh | 1 |
* | +U | sh | 2 |
* | -U | sh | 2 |
* | +U | sh | 3 |
* +----+--------------------------------+----------------------+
*/
// 从kafka读取结果
tableEnv.executeSql("select * from t_upsert_kafka_w").print();
}
}
4.4.3 jdbc连接器
jdbc connector作为source有如下特性
-
可作为scan source,底层产生bounded stream
-
可作为 lookup source,底层是“事件驱动"式查询。可以将jdbc连接器作为一个维表进行时态关联。
具体可参考:flink1.14 sql基础语法(一) flink sql表查询详解
jdbc connector作为sink有如下特性
-
可作为 Batch 模式的sink
-
可作为Stream模式下的append sink和upsert sink
所需依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-jdbc_2.12artifactId>
<version>1.14.4version>
dependency>
根据所连接的数据库不同,还需要相应的 jdbc 驱动,比如连接 mysql
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.49version>
dependency>
幂等写出
-
jdbc connector 可以利用目标数据库的特性,实现幂等写出
-
幂等写出可以避免在 failover 发生后的可能产生的数据重复
实现幂等写出,本身并不需要对jdbc connector 做额外的配置,只需要指定主键字段,jdbc connector 就会利用目标数据库的 upsert 语法,来实现幂等写出。
package cn.yyds.sql;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class _14_UpsertJdbcSink {
public static void main(String[] args) {
// 创建环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
Table table = tableEnv.fromValues(
DataTypes.ROW(
DataTypes.FIELD("province", DataTypes.STRING()),
DataTypes.FIELD("user_id", DataTypes.STRING())
),
Row.of("sh","u001"),
Row.of("sh","u002"),
Row.of("sh","u003")
);
tableEnv.createTemporaryView("s_source",table);
// 创建jdbc sink表
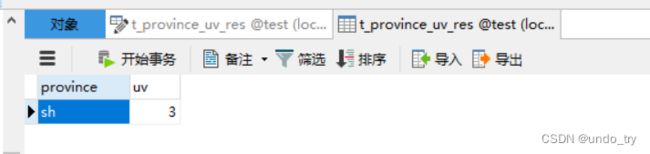
tableEnv.executeSql("create table t_province_uv(\n" +
" province string,\n" +
" uv bigint, \n" +
" primary key(province) not enforced \n" +
") with(\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://localhost:3306/test?serverTimezone=UTC',\n" +
" 'table-name' = 't_province_uv_res',\n" +
" 'driver' = 'com.mysql.jdbc.Driver',\n" +
" 'username' = 'root',\n" +
" 'password' = 'root'\n" +
")");
tableEnv.executeSql("insert into t_province_uv select province,count(distinct user_id) as uv from s_source group by province");
/**
* +----+--------------------------------+----------------------+
* | op | province | uv |
* +----+--------------------------------+----------------------+
* | +I | sh | 3 |
* +----+--------------------------------+----------------------+
*/
// 从kafka读取结果
tableEnv.executeSql("select * from t_province_uv").print();
}
}
分区并行读取 (partitioned scan)
jdbc connector 持有一个多并行度的 source task,因而可以多并行度加快表数据的读取
通过设置如下参数即可实现多并行读取
-
scan.partition.column: 划分并行任务的参照列
-
scan.partition.num: 任务并行数
-
scan.partition.lower-bound: 首分区的参照字段最小值
-
scan.partition.upper-bound: 末分区的参照字段最大值
分区参照字段必须是: numeric, date,或 timestamp 类型
4.4.4 filesystem连接器
filesystem connector 表特性
-
可读可写
-
作为 source 表时,支持持续监视读取目录下新文件,且每个新文件只会被读取一次
-
作为 sink 表时,支持 多种文件格式、分区、文件滚动、压缩设置等功能
CREATE TABLE MyUserTable (
column_name1 INT,
column_name2 STRING,
...
part_name1 INT,
part_name2 STRING
)
PARTITIONED BY (part_name1, part_name2)
WITH (
'connector' = 'filesystem', -- 必填: 指定连接器名称
'path' = 'file:///path/to/whatever', -- 必填: 目录路径
'format' = '...', -- 必填: 文件系统连接器要求指定一个format格式化
'partition.default-name' = '...', -- 可选: 如果动态分区字段值为null/空字符串,则使用指定的默认分区名称
'sink.shuffle-by-partition.enable' = '...', --可选:在sink阶段开启对动态分区文件数据的shuffle,开启之后可以减少写出文件的数量,但是有可能造成数据倾斜。默认为false。
...
);
1、分区文件
文件系统分区支持使用标准的hive format格式,而且,它不要求分区被预注册在表的catalog中。分区通过目录结构来进行发现和推断。比如,下面基于目录的表分区将会被推断为包含日期和小时分区。
path
└── datetime=2019-08-25
└── hour=11
├── part-0.parquet
├── part-1.parquet
└── hour=12
├── part-0.parquet
└── datetime=2019-08-26
└── hour=6
├── part-0.parquet
12345678910
使用insert overwrite覆盖一个分区表时,只有相关联的分区被覆盖,而不是整张表。
2、文件format
文件系统连接器支持多种format格式:
- CSV: RFC-4180. 未压缩
- JSON: 注意,文件系统的JSON格式并不是标准的JSON文件,而是未压缩的newline delimited JSON。
- Avro: Apache Avro. 支持通过配置avro.codec来支持压缩。
- Parquet: Apache Parquet. 兼容Hive.
- Orc: Apache Orc. 兼容Hive.
- Debezium-JSON: debezium-json.
- Canal-JSON: canal-json.
- Raw: raw.
3、Source
file system 连接器在单个表中可以被用于读取单个文件,或者是整个目录。
当使用目录作为 source 路径时,目录中的文件并没有定义好的读取顺序。
目录监控
默认情况下,file system 连接器是有界的,该连接器只会读取一次配置的目录,然后关闭它。
你可以通过配置 option source.monitor-interval 选项配置持续的目录监控:
| Key | 默认值 | 类型 | 描述 |
|---|---|---|---|
| source.monitor-interval | (none) | Duration | source 检查新文件的时间间隔,该数值必须大于0。每个文件都会使用他们自己的路径作为唯一标识符,并且在被发现后处理一次。已经被处理过的文件集合会在整个 source 的生命周期内被保存到 state 中,因此他们和 source state 一起被持久化到 checkpoint 和 savepoint 中。 更小的时间间隔意味着文件会更快被发现,但是会对文件系统或对象存储进行更频繁的文件列出或目录遍历。如果没有配置该选项,则提供的路径将只会被扫描一次,此时该 source 将会是有界的。 |
可用元数据
下面的连接器元数据可以通过被定义为表的元数据字段来访问,所有的元数据都是只读的。
| Key | 数据类型 | 描述 |
|---|---|---|
| file.path | STRING NOT NULL | 输入文件的路径 |
| file.name | STRING NOT NULL | 文件名称,他是距离文件路径根目录最远的元素。 |
| file.size | BIGINT NOT NULL | 文件的字节数。 |
| file.modification-time | TIMESTAMP_LTZ(3) NOT NULL | 文件的修改时间。 |
下面的代码片段展示了 CREATE TABLE 案例如何访问元数据属性:
CREATE TABLE MyUserTableWithFilepath (
column_name1 INT,
column_name2 STRING,
`file.path` STRING NOT NULL METADATA
) WITH (
'connector' = 'filesystem',
'path' = 'file:///path/to/whatever',
'format' = 'json'
)
4、Streaming Sink
文件系统连接器基于Streaming File Sink 写入记录到文件以支持文件系统连接器流式写入。行编码格式支持csv和json。块编码格式支持parquet、orc和avro。
可以通过sql直接写入,插入流数据到不分区的表中。如果是分区表,可以配置分区关联操作。
滚动策略
数据通过分区目录会被切分为多个文件。每个分区将包含其对应sink子任务接收到数据之后写入的至少一个文件,正在处理的文件将会根据配置的滚动策略来关闭并成为分区中的一个文件。文件的滚动策略基于大小、文件可以被打开的最大超时时间间隔来配置。
| Key | 要求 | 是否可被传递 | 默认值 | 类型 | 描述 |
|---|---|---|---|---|---|
| sink.rolling-policy.file-size | 可选 | 是 | 128MB | MemorySize | 滚动之前文件的最大大小。 |
| sink.rolling-policy.rollover-interval | 可选 | 是 | 30 min | Duration | 被滚动之前,一个文件可以保持打开的最大时间间隔(默认为30分钟,以避免产生很多小文件)。通过 sink.rolling-policy.check-interval 选项来控制检查的频率。 |
| sink.rolling-policy.check-interval | 可选 | 是 | 1 min | Duration | 滚动策略的检查时间间隔。该选项基于 sink.rolling-policy.rollover-interval 选项来控制检查文件是否可以被滚动。 |
注:对于块格式(parquet、orc、avro),滚动策略将会根据checkpoint间隔来控制大小和他们的数量,checkpoint决定文件的写入完成。
注:对于行格式(csv、json),如果想查看文件是否在文件系统中存在,并且不想等待过长的时间,则可以在连接器配置 sink.rolling-policy.file-size 和 sink.rolling-policy.rollover-interval ,并且在flink-conf.yaml中设置 execution.checkpointing.interval 参数。
对于其他的格式(avro、orc),可以只在flink-conf.yaml中配置execution.checkpointing.interval参数。
文件压缩
文件系统sink支持文件压缩,该特性允许应用程序设置更小的checkpoint间隔,而不会产生很多的文件。
| Key | 要求 | 是否可被传递 | 默认值 | 类型 | 描述 |
|---|---|---|---|---|---|
| auto-compaction | 可选 | 否 | false | Boolean | 是否在流slink中开启自动压缩。数据将会被写入临时文件。checkpoint完成之后,通过checkpoint生成的临时文件将会被压缩。临时文件在被压缩之前是不可见的。 |
| compaction.file-size | 可选 | 是 | (none) | Boolean | 压缩的目标文件大小,默认值为滚动文件大小。 |
如果开启,文件压缩将会基于目标文件大小合并多个小文件为大文件。在生产生运行文件压缩时,需要注意以下问题:
- 只有单个checkpoint中的文件可以被合并,因此,至少有和checkpoint次数相同的文件被生成。
- 文件在被合并之前是不可见的,因此文件可见时间为:checkpoint间隔+压缩时间。
- 如果压缩运行时间过长,则将会造成任务的反压,并且增加checkpoint的时间。
5、分区提交
通常来说,写入分区之后通知下游应用程序是非常必要的。比如:增加分区信息到hive的元数据,或者是在分区目录中写入一个 _SUCCESS 文件。文件系统sink连接器提供了分区提交特性,以允许配置自定义策略。提交行为基于合并的触发器和策略。
Trigger触发器:分区提交的时间可以通过水印或处理时间来确定。
Policy策略:如何提交一个分区,支持通过success文件和元数据提交,也可以自定义实现策略。比如触发hive的指标分区,或者是和并小文件等等。
注:分区提交只在动态分区插入时起作用。
分区提交触发器
定义何时提交分区,提供分区提交触发器:
| Key | 要求 | 是否可被传递 | 默认值 | 类型 | 描述 |
|---|---|---|---|---|---|
| sink.partition-commit.trigger | 可选 | 是 | process-time | String | 分区提交触发的类型: process-time:基于机器时间,既不需要分区时间提取,也不需要水印生成。一旦当前系统时间超过了分区创建时的系统时间加上指定的delay延迟就会提交分区。 partition-time:基于分区字段值提取的时间,要求生成水印。当水印超过了分区值提取的时间加上delay延迟时提交水印。 |
| sink.partition-commit.delay | 可选 | 是 | 0 s | Duration | 分区在延迟时间到达之前不会提交。如果是按天分区,则应该是1 d,如果是按小时分区,则应该是1 h。 |
| sink.partition-commit.watermark-time-zone | 可选 | 是 | UTC | String | 转换long类型的水印值为TIMESTAMP类型是使用的时区,转换之后的水印时间戳将被用于和分区时间计算,以决定分区是否应该被提交。 该选项只有在 sink.partition-commit.trigger 选项设置为 partition-time 时起作用。如果该选项没有被正确配置,比如source的rowtime被定义为TIMESTAMP_LTZ字段,但是该选项没有配置,则用户将会延迟几小时之后看到提交的分区。 默认值为UTC,这意味着水印需要被定义为TIMESTAMP字段,或者是不被定义。如果水印被定义为TIMESTAMP_LTZ字段,则水印时区为会话时区。该选项值可以是完全名称,比如America/Los_Angeles,或者是自定义的时区id,比如GMT+08:00。 |
有两种触发器类型:
- 第一个是分区的处理时间,既不要求分区时间提取,也不要求水印生成。该触发器根据分区的创建时间和当前系统时间触发分区提交。该触发器更常用,但不是很精确。比如,数据延迟或失败,将会导致不成熟的分区提交。
- 第二个是根据水印和从分区中提取的时间来触发分区提交。该触发器要求任务有水印生成,并且分区根据时间来划分,比如按小时或按天分区。
如果想要下游尽快看到新分区,而不管数据写入是否完成:
- ‘sink.partition-commit.trigger’=‘process-time’ (默认值)
- ‘sink.partition-commit.delay’=‘0s’ (默认值),分区一旦写入数据,将会立即提交。注:分区可能会被提交多次。
如果想要下游在数据写入完成之后看到分区,并且job任务有水印生成,则可以通过分区值来提取时间:
- ‘sink.partition-commit.trigger’=‘partition-time’
- ‘sink.partition-commit.delay’=‘1h’ (如果分区为小时分区,则使用 1h,取决于分区时间类型)这是提交分区更准确的方式。它将尝试在数据写入完成之后再提交分区。
如果想要下游在数据写入完成之后看到分区,但是没有水印,或者是无法从分区值提取时间:
- ‘ink.partition-commit.trigger’=‘process-time’ (默认值)
- ‘sink.partition-commit.delay’=‘1h’ (如果分区为小时分区,则使用 1h,取决于分区时间类型)尝试准确的提交分区,但是迟到的数据或者是失败将会导致不成熟的分区提交。
迟到数据处理:支持写入分区的记录将会被写入已经提交的分区,并且该分区提交将会被再次触发。
默认提取器基于分区属性和时间戳默认组成。也可以通过实现 PartitionTimeExtractor 接口来完全自定义分区提取器。
public class HourPartTimeExtractor implements PartitionTimeExtractor {
@Override
public LocalDateTime extract(List<String> keys, List<String> values) {
String dt = values.get(0);
String hour = values.get(1);
return Timestamp.valueOf(dt + " " + hour + ":00:00").toLocalDateTime();
}
}
分区提交策略
分区提交策略定义分区提交时执行哪些操作
- 第一个是元数据,只有hive表支持元数据策略,文件系统通过目录结构管理分区。
- 第二个是success文件,在分区对一个的目录下写一个空文件。
| Key | 要求 | 是否可被传递 | 默认值 | 类型 | 描述 |
|---|---|---|---|---|---|
| sink.partition-commit.policy.kind | 可选 | 是 | (none) | String | 指定提交分区并通知下游应用程序,该分区已经完成写入并可进行读取的策略。 metastore:将分区写入元数据。只有hive表支持元数据策略,文件系统通过目录结构来管理分区。 success-file:在目录中增加 _success 文件。这两个方式可以同时配置: metastore,success-file custom:使用策略类创建一个提交策略。 支持配置多个策略:metastore,success-file。 |
| sink.partition-commit.policy.class | 可选 | 是 | (none) | String | 实现了PartitionCommitPolicy接口的分区提交策略实现类。只在自定义custom提交策略中起作用。 |
| sink.partition-commit.success-file.name | 可选 | 是 | _SUCCESS | String | success-file分区提交的文件名称,默认为: _SUCCESS 。 |
6、sink并行度
写入文件到外部文件系统的并行度(包括hive),可以通过表的option选项来配置,流模式和批模式都支持这么做。
默认情况下,slink的并行度和上游链在一起的算子并行度一致。如果配置了和上游算子不同的并行度,则写入文件算子的并行度将使用配置的并行度。
| Key | 要求 | 是否可被传递 | 默认值 | 类型 | 描述 |
|---|---|---|---|---|---|
| sink.parallelism | 可选 | 否 | (none) | Integer | 将文件写入外部文件系统的并行度。数值应该大于0,否则将抛出异常。 |
注:目前,配置sink并行度只支持上游算子为仅插入INERT-ONLY类型的变更日志模式,否则将抛出异常。
7、完整案例
下面的例子展示文件系统连接器如何通过流查询从kafka读取数据,然后写入文件系统,并且通过批查询从文件系统中读取写入的数据。
CREATE TABLE kafka_table (
user_id STRING,
order_amount DOUBLE,
log_ts TIMESTAMP(3),
WATERMARK FOR log_ts AS log_ts - INTERVAL '5' SECOND
) WITH (...);
CREATE TABLE fs_table (
user_id STRING,
order_amount DOUBLE,
dt STRING,
`hour` STRING
) PARTITIONED BY (dt, `hour`) WITH (
'connector'='filesystem',
'path'='...',
'format'='parquet',
'sink.partition-commit.delay'='1 h',
'sink.partition-commit.policy.kind'='success-file'
);
-- streaming sql, insert into file system table
INSERT INTO fs_table
SELECT
user_id,
order_amount,
DATE_FORMAT(log_ts, 'yyyy-MM-dd'),
DATE_FORMAT(log_ts, 'HH')
FROM kafka_table;
-- 批式sql,查询指定分区下的数据
SELECT * FROM fs_table WHERE dt='2020-05-20' and `hour`='12';
如果水印定义在TIMESTAMP_LTZ类型的字段上,并且被用于分区提交时间,则sink.partition-commit.watermark-time-zone配置必须设置为会话时间分区,否则分区提交将会晚几个小时。
CREATE TABLE kafka_table (
user_id STRING,
order_amount DOUBLE,
ts BIGINT, -- 毫秒值
ts_ltz AS TO_TIMESTAMP_LTZ(ts, 3),
WATERMARK FOR ts_ltz AS ts_ltz - INTERVAL '5' SECOND -- 在TIMESTAMP_LTZ字段上定义水印
) WITH (...);
CREATE TABLE fs_table (
user_id STRING,
order_amount DOUBLE,
dt STRING,
`hour` STRING
) PARTITIONED BY (dt, `hour`) WITH (
'connector'='filesystem',
'path'='...',
'format'='parquet',
'partition.time-extractor.timestamp-pattern'='$dt $hour:00:00',
'sink.partition-commit.delay'='1 h',
'sink.partition-commit.trigger'='partition-time',
'sink.partition-commit.watermark-time-zone'='Asia/Shanghai', -- 表名用户配置的时区为:'Asia/Shanghai'
'sink.partition-commit.policy.kind'='success-file'
);
-- 流式sql,插入数据到文件系统
INSERT INTO fs_table
SELECT
user_id,
order_amount,
DATE_FORMAT(ts_ltz, 'yyyy-MM-dd'),
DATE_FORMAT(ts_ltz, 'HH')
FROM kafka_table;
-- 批式sql,查询指定分区下的数据
SELECT * FROM fs_table WHERE dt='2020-05-20' and `hour`='12';
4.4.5 第三方连接器
例如:flink-doris-connector
create table cdc_mysql_source(
id int,
name varchar,
primary key(id) not enforced
)with(
'connector' = 'mysql-cdc',
'hostname' = 'centos01',
'port' = '3306',
'username' = 'root',
'password' = 'root',
'database-name' = 'test',
'table-name' = 't_test'
)
-- 支持删除事件同步(sink.enable-delete='true'),需要 Doris 表开启批量删除功能
CREATE TABLE doris_sink (
id INT,
name STRING
) WITH (
'connector' = 'doris',
'fenodes' ='centos01:8030',
'table.identifier' = 'test.t_test',
'username' = 'root',
'password' = 'root',
'sink.properties.format' = 'json',
'sink.properties.strip_outer_array' = 'true',
'sink.enable-delete' = 'true'
)
insert into doris_sink select id,name from cdc_mysql_source;
flink-hudi-connector
-- 1、创建测试表
CREATE TABLE sourceT (
uuid varchar(20),
name varchar(10),
age int,
ts timestamp(3),
`partition` varchar(20)
) WITH (
'connector' = 'datagen',
'rows-per-second' = '1'
);
create table t2(
uuid varchar(20),
name varchar(10),
age int,
ts timestamp(3),
`partition` varchar(20)
)
with (
'connector' = 'hudi',
'path' = '/tmp/hudi_flink/t2',
'table.type' = 'MERGE_ON_READ'
);
-- 2、执行插入
insert into t2 select * from sourceT;