【Python实战】2022年中国富豪榜出炉,首富竟是他......教你一键采集榜单并做可视化效果图(今天是拉仇恨的一天鸭~)
前言
哈喽,我是你们的栗子同学~
今天是拉仇恨的一天:
教大家一键采集(爬虫+数据分析基础实战)新CaiFu中国500富人榜,中国首富竟然是他......
所有文章完整的素材+源码都在
粉丝白嫖源码福利,请移步至CSDN社区或文末公众hao即可免费。

我看了看,翻了翻
和往年一样
依然没有找到我的名字

下面就是我给大家长脸的时候了,我这技术还是有丢丢用的给大家娱乐娱乐一下还是ojbK了
的。好了画布多不说,说多了都是泪,直接开始今天的内容吧~

正文
一、运行环境
1)环境
python 3.8 运行代码 pycharm 辅助敲代码
爬虫: Python 3.8 Pycharm数据分析: Python 3.8 jupyter notebook2)模块使用
爬虫:
requests >>> pip install requests 数据请求
csv <表格文件> 内置模块 保存数据 数据分析 :
pandas
pyecharts
win + R 输入cmd 输入安装命令 pip install 模块名
(如果你觉得安装速度比较慢, 你可以切换国内镜像源)3)第三方模块安装
pip install 模块名 镜像源安装 pip install -i pypi.douban.com/simple/ +模块名 Python 安
装包 安装教程视频 pycharm 社区版 专业版 及 激活码免费找我拿即可 !
(各种版本的都有,可以一整套直接分享滴~)
二、爬虫思路
1)爬虫采集网上数据资源:
网址: https://www.xcf.cn/zhuanti/ztzz/hdzt1/500frb/index.html
2)数据来源分析:
<重要点> 通过开发者工具进行抓包分析 --> 数据所对应链接地址是那个
1. 打开开发者工具: F12 / fn+F12 / 右键点击检查选择network 。
2. 点击第二页: 数据所对应:
https://service.ikuyu.cn/XinCaiFu2/pcremoting/bdListAction.do?
method=getPage&callback=jsonpCallback&sortBy=&order=&type=4&keyword=&pa
geSize=15&year=2022&pageNo=2&from=jsonp&_=1680086650173 3)代码实现步骤: <固定模板>
1. 发送请求, 模拟浏览器对于url地址发送请求
2. 获取数据, 获取服务器返回响应数据
3. 解析数据, 提取我们想要的数据内容
4. 保存数据, 把数据保存表格文件里面 Excel csv 数据库 json文件 文本也可以
三、代码展示
爬虫主程序——
"""
# 导入数据数据请求模块
import requests
# 导入正则模块
import re
# 导入json
import json
# 导入格式化输出模块
from pprint import pprint
# 导入csv模块
import csv
# 创建文件 open函数
f = open('data.csv', mode='a', encoding='utf-8', newline='')
# 配置f文件对象 fieldnames 字段名 表头
csv_writer = csv.DictWriter(f, fieldnames=[
'姓名',
'财富(亿元)',
'主要公司',
'相关行业',
'公司总部',
'性别',
'年龄',
])
# 写入表头
csv_writer.writeheader()
"""
1. 发送请求, 模拟浏览器对于url地址发送请求
- 请求链接
找到之后直接复制
- 模拟浏览器 <防止反爬>
headers 请求头 --> 复制
I. 字典数据类型 <构建完整键值对>
- 发送请求 <请求方式方法>
get --> 开发者工具显示 请求方法GET
想要本节课代码吗? 你想要本节课录播吗?
课堂多发言 多互动 --> 课后给可以发给你
响应对象 表示请求成功
多页数据采集:
分析请求url地址变化规律
根据变化规律, 构建每一页请求链接
"""
for page in range(1, 35):
# 请求链接
url = f'https://service.ikuyu.cn/XinCaiFu2/pcremoting/bdListAction.do?method=getPage&callback=jsonpCallback&sortBy=&order=&type=4&keyword=&pageSize=15&year=2022&pageNo={page}&from=jsonp&_=1680086650173'
# 模拟浏览器
headers = {
# User-Agent 用户代理, 表示浏览器基本身份信息
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 发送请求
response = requests.get(url=url, headers=headers)
"""
2. 获取数据, 获取服务器返回响应数据
知识点:
- response.text 和 response.json() 区别
- 正则表达式提取数据
正则表达返回列表数据, [0] 提取列表索引位置为0的元素, 也就是提取第一个元素
- 列表索引取值
- json模块的使用
3. 解析数据, 提取我们想要的数据内容
字典取值
print(index) # 打印字典数据 返回一行
pprint(index) # 打印字典数据 返回多行
.*? --> 通配符 可以匹配任意字符 (除了\n换行符以外)
"""
# 正则匹配数据
html_data = re.findall('jsonpCallback\((.*?)\)', response.text)[0]
# 转换数据类型
json_data = json.loads(html_data)
# for循环遍历, 提取列表元素
for index in json_data['data']['rows']:
# 创建字典 --> 字典取值
dit = {
'姓名': index['name'],
'财富(亿元)': index['assets'],
'主要公司': index['company'],
'相关行业': index['industry'],
'公司总部': index['addr'],
'性别': index['sex'],
'年龄': index['age'],
}
# 写入数据
csv_writer.writerow(dit)
print(dit)  四、效果展示
四、效果展示
1)爬虫效果

2)保存在Excel
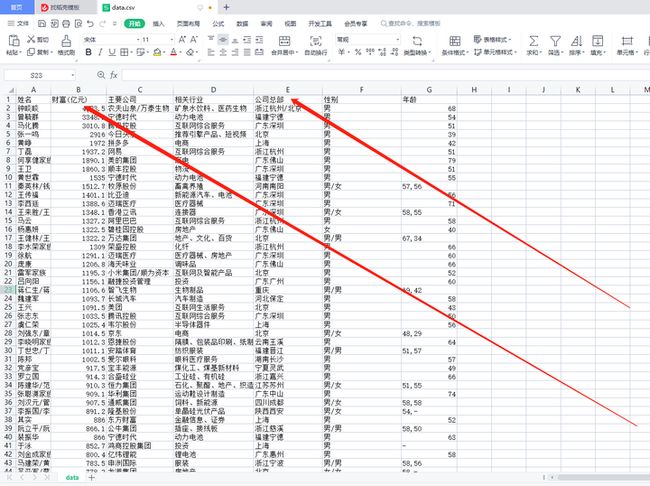
3)数据分析效果
可视化导入数据
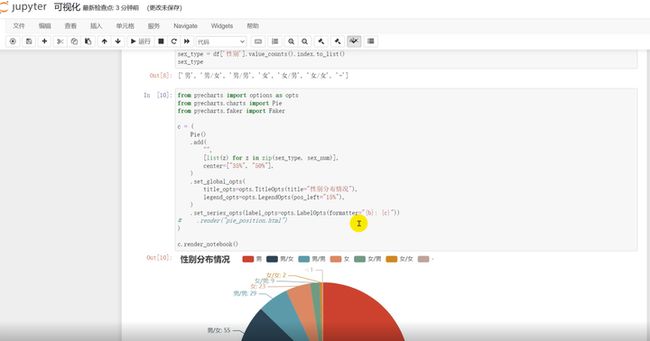
性别分布情况可视化
总结
没想到中国首富竟是钟睒睒,还是大家耳熟能详的农夫山泉的总经理鸭~
知道了新知识,哈哈哈,好啦~今天的内容到这里就写完啦,我们下期再见!
✨完整的素材源码等:可以滴滴我吖!或者点击文末hao自取免费拿的哈~
推荐往期文章——
项目1.3 高清壁纸爬虫
【Python实战】美哭你的极品壁纸推荐|1800+壁纸自动换?美女动漫随心选(高清无码)
项目0.9 【Python实战】WIFI密码小工具,甩万能钥匙十条街,WIFI任意连哦~(附源码)
项目1.0 【Python实战】再分享一款商品秒杀小工具,我已经把压箱底的宝贝拿出来啦~
项目0.1 宝藏拼图神秘上线,三种玩法刷爆朋友圈—玩家直呼太上瘾了。
文章汇总——
Python文章合集 | (入门到实战、游戏、Turtle、案例等)
(文章汇总还有更多你案例等你来学习啦~源码找我即可免费!)
