RTC 音频质量评价和保障
导读:随着 5G 网络的普及以及疫情带来的影响,人们对实时音视频技术的应用场景会越来越多,包括会议、连麦、音视频通话、在线教育、远程医疗等,这些实时互动场景对 RTC 音频的质量提出了越来越高的要求。如何对 RTC 音频的效果开展测试,通过构建客观、标准、可重复的评价体系来保证好的音频传输质量,也成为目前比较紧急和重要的课题。
![]()
文|马建立 网易云信资深音视频测试工程师

理想的沟通模型
日常沟通中面对面的交流一般有比较好的效果,如果在一个安静的实验室内,减少环境的干扰和影响,会得到理想的沟通效果。我们再把这个模型抽象一下,大体可以看出有以下的特点:
环境安静:NR15 的底噪,相当于在极其安静的夜晚,人耳能不受到其他影响的干扰,集中注意力听目标人声。
适宜听音的混响环境:混响通常会影响听音者的理解程度,混响越大,语音的拖尾越长,可懂度也就越低。比如在混响较大的演唱厅,对于乐器和歌声来说,会有一定的美化效果,但是对于人的沟通交流是不利的。
语音清晰、自然:讲话者心理和生理都处在极佳的状态,发音清楚,频率均衡,语音流畅,语速适中。
声音大小适中:研究表明,音量对音质的影响是显著的,在其他条件一致的情况下,音量越大,主观听感越好。讲话者说话声音洪亮,在一定程度上能提升听音者的可懂度。
响应及时、沟通顺畅:在 RTC 的实时沟通中,延时也是一个非常重要的指标,一般来说,200ms 以内人的延时人的主观感觉无明显的障碍和迟滞感,200ms-400ms 能正常沟通,超过 400ms 就会有的迟滞感,更严重时会出现抢话的现象,直接影响通话的体验。在面对面的沟通场景下,时延只有 3ms 左右。

RTC 音量链路

上图是通过 RTC 实时沟通的两个人,从图上可以看出,讲话者 A 开始说话,声音经过空气传播、麦克风采集、A/D 转换、增强处理(降噪、回声消除、音量控制、去混响)、编码、打包传输、接收端解码、NetEQ、D/A 转换到下行播放,然后 B 听到声音。这是单工状态下的完整的声音传输的路径。
与理想的沟通模型相比,实际的 RTC 链路中存在多种类型的干扰和影响,比如环境影响、硬件影响、链路影响和网络影响,每个环节都有可能引入音频质量的下降。这些影响综合下来,会导致如下几个方面的声音的问题。
- 音量问题:无声、音量小、声音大导致的削波、刺耳等、忽大忽小。
- 回声类问题:漏回声、回声残留、语音损伤如压制、剪切、断续。
- 噪声类问题:噪声残留不平稳。
- 系统引入问题:杂音、电流音、popo音。
- 狭义的音质问题:语音模糊、语音失真、语音发闷、语音尖锐、机械音。
- 网络问题:卡顿、断续、快放、慢放、机械音。

主观测试方法

最早的主观测试以两个人通话为主,A 和 B 建立起 RTC 的链接,通过分别或者同时讲话,还原真实场景的用户使用场景,主要关注的以下 3 个维度。
Listening Quality:听音者的音质,是单工的使用场景,比如 A 在讲话,B 听到的声音的质量,就是 Listening Quality,Listening Quality 描述了大部分情况下的语音质量,也是最基础的部分,目前业界已有的客观评价方法和手段基本上都是基于 Listening Quality。
Talking Quality:讲话者的音质,是讲话人自己听到的声音质量,与回声、侧音掩蔽、本地的环境都有一定的关系。
Conversation Quality:对话音质,除了包含 A/B 两个人的 Listening Quality 和 Talking Quality,还跟双工通话有关系,主要的影响因素有回声双讲和端到端延时。
主观测试关注的维度
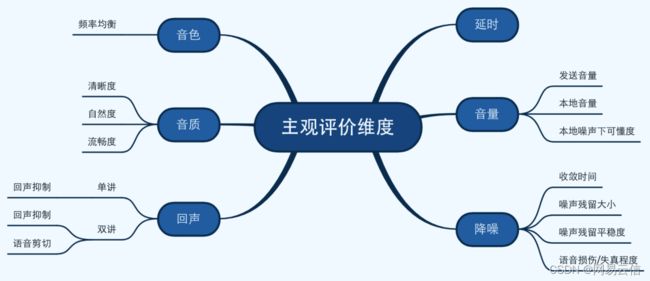
主观测试要关注的点如上图所示,分为音质、音色、音量、延时、回声、降噪等几个大的方面。
音色
音色又称之为音品,是听觉感到的声音的特色,音色主要决定于声音的频谱。在 RTC 的链路中,影响声音的频率响应主要是麦克风的频率特性、中间处理如 EQ、高低通滤波、以及音量控制的算法(DRC/AGC)、扬声器/耳机得到频响等。不同人的发声频率分布也有差异,一般来说男性声音低频多,声音浑厚或者偏闷,女性或者小孩有更多的高频成分,声音明亮甚至有些尖锐。
音质:音质分为 3 个维度,清晰度、流畅度和自然度。
- 清晰度在音频领域也叫可懂度。表示对语义内容的理解程度,影响可懂度的方面有很多,比如:语音中混入噪声使得语音听不清楚,导致可懂度下降;语音中有大混响,导致语音拖尾,听不清楚。
- 流畅度表示语音的连续程度。直接影响的因素有:网络环境差导致语音断续、卡顿、丢字等;QoS 调整导致的声音快放、慢放;回声和降噪等算法导致的语音损伤。
- 自然度表示与原始语音的相似程度。影响自然度的典型问题有:算法处理引入的失真;扬声器的非线性失真;声音放大过多造成的削波、过载等。
音量
对于 RTC 的 SDK 供应商来说,面临的最大挑战是设备多样性,不同的平台(Mac、Windows、Android、iOS、Web),以及不同机型和不同的外接设备,不同的机型或者设备采集、播放音量差异大。音量控制的策略在于能够保证不同平台设备之间的一致性,保证用户能够听到足够大小的声音,且不会显性的带来音质损伤和下降。
噪声
降噪算法的目的在于去除环境或者设备引入的噪声干扰,尽可能多的还原人声,提升信噪比。实际的降噪算法在处理噪声的过程中,都不可避免的、或多或少的损伤音质。因此评价降噪主要从两个方面考虑:
- 噪声的抑制水平。包括收敛时间、抑制力度、残留平稳性等。
- 语音的损伤程度。好的降噪算法总是能够在这两者之间达到一个相对的平衡,既能有效的抑制噪声,又没有明显的损伤语音。
回声
回声消除是 RTC 链路中比较重要的一个模块,目的是消除设备的回声,保证顺畅的通话体验。评价回声也主要从两个点出发:
- 回声的抑制力度。回声是否有残留。
- 对近端语音的损伤情况。在 RTC 的应用场景,回声也与设备、平台、机型和外接设备关系很大,因此回声的测试需要覆盖 TOP 机型。
延时
网络传输中音频对抗丢包的算法如 FEC、RED、ARQ,以及对抗丢包的算法如 Jitter Buffer 等,都会产生额外的延时,导致端到端的延时增大,对于实时沟通交流带来负面的影响和体验下降。尤其是对于一些低时延的场景来说,端到端延时是一个衡量弱网对抗性能的重要指标。
主观测试的痛点
目前 RTC 音频的主流评价方式主要依靠主观测试和听音,这种方式对于人的专业能力要求比较高,而且效率比较低。主要有以下几个方面的痛点:
- 可重复性差:主观测试很难保证两次测试的一致,比如声场环境的变化、说话人发音变化、音量大小变化、与设备之间的距离差异等等,不可控因素太多,没办法得到准确的对比测试结果。
- 测试效率低:主观测试需要两个人全程参与,长时间的测试无论听音还是发声,都会产生疲劳和懈怠感,且需要根据用例切换场景,测试效率非常低。
- 测试覆盖率低:因为效率的问题,实测只能覆盖有限的场景和有限的链路组合,通常来说只能保证重点场景。且测试人员本身的声音有局限性,没有办法覆盖更多种类的人声。
- 主观因素影响大:声音是很主观的东西,同一段声音在不同人的听感不尽相同,单个人的测试结果有可能会导致结论有失偏颇。且人的发声和听音,与生理和心理的状态有着极大的关系,同一个人在不同时间段会给出截然不同的判断和结论。
针对以上的痛点问题,网易云信目前在音频效果的评价和测试上,打造了一套从实验室构建、环境模拟、采集播放、评价方法端到端的客观评价方法。

标准实验室
上图是网易云信的声学实验室,主要的设备和硬件配置如下所示:
- 头肩模拟器:内置嘴部模拟器和经过较准的耳部模拟器(符合 IEC 60318–4/ITU‐T Rec. P.57 Type 3.3 标准)的人体模型,可以真实再现普通成年人头部和躯干的声学特性,进行精准的双耳声学信号 采集和嘴部发声。
- 4* 高保真音响:构造均匀的散射声场,在线模拟并回放不同场景和信噪比的噪声环境。
- 多路声卡:支持同时8入8出的声音采集和播放,满足多种音频测试的场景设置。
- 4路电信号接口:支持多人语音测试 和 回声单双讲测试。
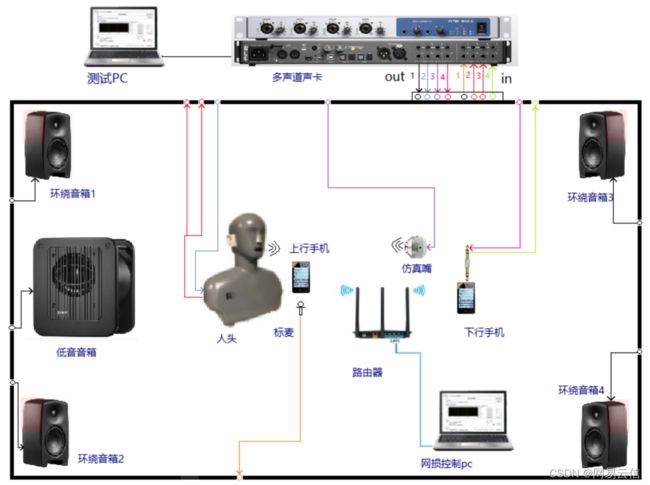
通过构建专业的音频测试实验室,满足音频自动化测试/竞品分析评测/版本间基线效果快速对比测试的需求,获得可重复的客观测试结果,同时能够满足研发音频算法仿真和原型验证的需求。还可以一人完成 3A 主观测试:降噪、音质、回声单双讲测试。目前 AI 算法越来越多,数据是 AI 类算法的关键,有了声学实验室和噪声模拟系统,通过编写自动化脚本的方式,可以实现 AI 数据自动采集和标注,大大降低数据购买和标记成本。目前云信的声学实验室组网如上图所示,实验室的引入提升了开发和测试的专业度,主要有以下方面的应用:
- 自动化测试:客观的 3A 自动化测试,如回声测试、噪声测试,可模拟多人入会场景。
- AI 数据自动化采集:开源的语音、目标噪声分别通过人头和噪声回放系统播放,在目标端或者平台上回录,录制的过程中可以打标签,同时解决序列采集和标记的问题。
- 主观测试:定量的播放环境和安静的听音环境。
- 其它:机型覆盖测试、机型适配、算法原型优化验证。

客观测试标准
实验室主要是提供了客观可重复的测试环境,硬件设备支持自定义的采集和播放,除此之外,目前网易云信的音频实验室还引入了客观的测试标准,作为最终数据的评价方法。音频测试标准按照不同维度有不同的划分。
主观/客观
主观是基于人类的主观评价,客观方法是用模型来计算和评估语音质量。典型的主观评测标准如P.800,客观的语音质量评测方法如 PESQ。
有参考/无参考
完全参考/无参考 (FR/NR) 描述所用测量算法的类型。FR 算法有两个信号:原始信号和失真信号。NR 算法只需要一个失真信号。典型的 FR 算法是例如 PESQ。典型的 NR 测量是 P.563,NR 方法也常被称为“单端”测试。
感知/非感知
通常,此类测量算法会尝试对人类感知进行建模。感知建模不仅用于质量的评估。其他著名的感知算法例如使用感知模型的 MP3 或 AAC 用于压缩音乐。非感知指标是一般的物理或技术指标,例如电平或信噪比。
基于感知模型的客观标准
基于感知模型的客观指标最经典也是应用最广泛的是有源客观语音质量测试标准 p.86x 系列,也是就常说的 PESQ/POLQA,是一种典型的有参考的语音评价标准, PESQ/POLQA 总的思路是:对原始信号(参考信号)和通过测试系统的信号进行电平调整到标准听觉电平,再用输入滤波器模拟标准电话听筒进行滤波。
对通过电平调整和滤波后的两个信号在时间上对准,并进行听觉变换,这个变换包括对系统中线性滤波和增益变化的补偿和均衡。两个听觉变换后的信号之间的不同作为扰动(即差值),分析扰动曲面提取出两个失真参数,在频率和时间上累积起来,映射到对主观平均意见分的预测值。POLQA 相对于 PESQ 做了大量精度的优化,使得客观测试结果与主观测试结果的一致性更高,在语音评测方面有个非常广泛的应用。

自动化测试
POLQA 自动化测试
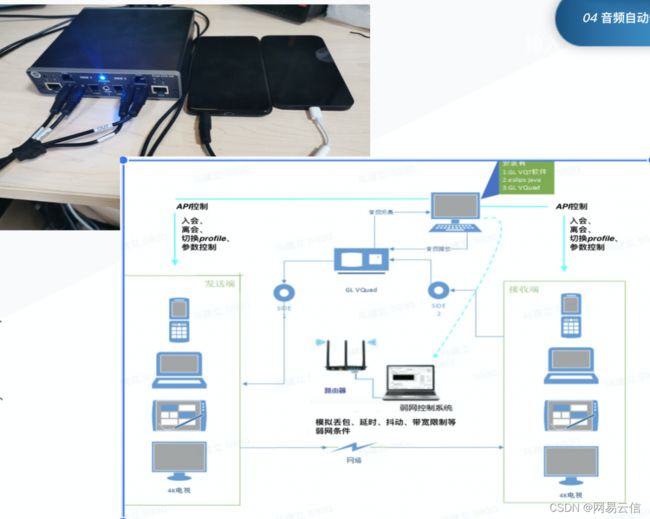
网络测试中,为减少硬件采集播放和声学链路的影响采用电信号链路的测试。发送端和接受端的两台设备使用 3.5mm 的音频线与声卡连接。此外,有一套 TC 系统来提供网损环境,被测试的两台设备接入 TC 的 Router,通过脚本控制两端设备的丢包、延时、抖动和带宽。
如上图所示,测试主机通过声卡将信号发送给测试设备 A,测试设备经过本端的 RTC 音频处理后,经过网络传输发送到接收端设备 B,在这个过程中,通过弱网系统实时添加不同类型和程度的网损。声卡接收到测试设备 B 的信号,通过与原始信号的比对和分析,来衡量 RTC 对于弱网对抗模块的性能。
- 支持 Android 端、iOS 端、Windows 端、Mac 端、Web 端的互通测试;
- 使用 TC 脚本自动化控制网络环境;
- 使用 API 自动化控制入会、切换 profile、参数控制、离开会议;
- 自动化获取测试过程中的码率、丢包、卡顿等打点信息作为辅助标准;
- 一键执行,生成版本基线报告;
3A 客观自动化

网易云信目前基于实验室搭建了端到端的 3A 自动化测试,架构框图如上图所示,主要分为用例管理层、API/UI 控制层、采集和播放、自动校准、分析与计算、数据和报告几个大的模块。主要用于回声、噪声和音量控制的综合评价,目前在版本基线测试、版本迭代对比、竞品对比等测试环节中应用。
作者介绍
马建立,网易云信资深音视频测试工程师,网易云信音视频媒体实验室核心成员,负责音频测试质量体系建设和音视频质量保障工作。