ClickHouse MergeTree表引擎和建表语句
1. Clickhouse使用场景
ClickHouse是由俄罗斯Yandex公司开发的、面向列的数据库管理系统(DBMS),主要面向OLAP场景,用于在线分析处理查询,可以使用SQL查询实时生成数据分析结果。列式存储的好处就是当我们对列进行聚合等操作时,效率会大大优于行式存储,而且由于每一列的类型都是相同的,所以对于数据存储更容易进行压缩,而且可以对不同类型的列选择更合适的压缩算法,节约资源。
clickhouse的设计也处处体现了俄罗斯的暴力美学,它不仅仅是一个数据库,还是一个数据库管理系统,后面我们在介绍基于SQL的用户管理、权限管理、资源管理,以及clickhouse本身在数据压缩、并行化计算等方面的特色,就会明白为什么会说clickhouse是一个数据库管理系统了。
clickhouse虽然在很多方面表现出了优异的性能,尤其是是在大数据量情况下的高效查询效率(ck和其他数据库的查询性能比较,可参考官方测试,但也并不意味着就适合所有数据库使用场景。ck的使用场景如下:
- 数据量较大。在ck官网的测试数据案例以及诸多大厂的实践中,数据量至少都是在百万条以上(大多数都是亿级)。如果使用传统数据库,如mysql、oracle、pg等数据库已经可以满足业务需求,那么就没必要强行引入ck,而且ck对用户暴露了很多使用配置,对开发人员的要求更高,运维成本更高。
- ck的请求绝大多数都是读请求。换句话说就是写请求很少,或者说不频繁(插入数据都是集中写)。例如,网站的行为日志分析,可以在凌晨把前一天的数据同步到ck中。当然,这并不是说ck的写入数据性能很弱,只是不适合细水长流的写操作。
- 批量(> 1000行)更新,而不是单个行更新,或者根本就没有更新/修改操作。这也是ck和hive类似,但是又不同的地方。hive不支持alter、delete语句修改数据,ck支持此类操作,但是非常不建议针对极少数数据、频繁的做alter操作,尤其是在服务器比较忙碌的时候。最好是和hive一样,对分区做增删操作。
- 读取很多行,但只提取了列的一小部分。换句话说就是,我的表很大、列很宽,但是每次查询的时候只使用其中部分字段,按需索取,所以如果不是必要,不建议在ck中使用 select * 的操作,尤其是宽表。
- 宽表,即有很多列。换句话说就是数据在写入ck之前,已经打宽,避免在ck内做表关联操作,并不是说ck不支持join操作,只是相对查询而言性能会受影响(实际上ck的大表和小表join也并不比其他关系型数据库差)。
- 查询相对较少(通常每台服务器每秒有数百个查询,甚至更少),这也就意味着ck不能直接作为业务系统的查询数据库,尤其是面向C端用户的业务系统,这主要是ck对服务器的CPU消耗极高导致的。所以ck多用在监控数据分析、日志分析、业务数据分析等场景,服务于平台和企业内部,例如,电商平台需要监控每三分钟刷新的热销商品销量排行。
- 对于简单的查询,大约允许50毫秒的延迟。这是由于ck的稀疏索引导致的,使得ck对于通过键检索单行的点查询不那么有效。不同于hash索引,使用 where = * 条件可以直接定位到要查的数据,稀疏索引是通过对数据排序,然后建立等距采样点得到的,所以即使是 = 精准查询,也要多次比较得到。
- 列中的数据相对较小,多为数字和短字符串。例如,URL、销量等。如果存文章、图片甚至视频就不合适了。
- 在处理单个查询时需要高吞吐量(每台服务器每秒可处理数十亿行)。例如6中的热销商品监控。
- 事务不是必须的。这是ck和mysql等数据库一个极大的不同点,ck不支持事务,也就说无法保证数据一致性。好消息是Yandex已经把事务支持排在远期目标了。
- 对数据一致性要求低。一方面是因为ck不支持事务,还有一方面是因为ck的副本表在同步数据的时候不能保证数据一致性。例如,修改了副本A的数据,副本B的数据还没有完全同步好,此时如果分别查了副本A和副本B的数据,结果就不一致了。而且因为没有事务支持,如果是插入一万条记录,在写入三千条的时候,来了一个查询,查询结果是会把三千条涵盖进去的。所以ck在写入数据的时候为了保证数据一致性,有一种方案就是先建立一个临时表保存要插入的数据,然后把原表的历史数据也同步到临时表中,再rename原表为备份表、rename临时表为正式表,这样就可以保证数据一致性了,如果有问题只需要把备份表再rename为正式表就可以回滚了。
- 每个查询都有一个大表。除了他以外,其他的表都很小。即尽量不要做大表和大表关联的操作。
- 查询结果明显小于源数据。换句话说,数据被过滤或聚合,因此结果适合单个服务器的RAM。
2. ClickHouse表引擎
ClickHouse支持不同的表引擎,主要有MergeTree家族表引擎、Log家族表引擎、集成表引擎,以及一些特殊的表引擎。表引擎的主要作用是:
- 决定数据存储的方式和位置,向何处写入,从何处读取。如Log引擎数据是存在内存中。
- 支持哪些查询以及如何支持。例如,有些功能只有MergeTree系列表引擎才支持。
- 并发数据访问。
- 索引的使用(如果存在)。
- 是否可以执行多线程请求。
- 数据复制参数。
其中MergeTree家族的表引擎是ClickHouse数据存储能力的核心,它们为弹性和高性能数据检索提供了大多数特性:列式存储、自定义分区、稀疏主索引、二级索引等。
3. MergeTree引擎建表语句
MergeTree表引擎是MergeTree家族表引擎最具代表性的表引擎,也是使用最为广泛的表引擎。MergeTree表引擎可以被认为是单节点ClickHouse实例的默认表引擎,因为它适用于各种各样的用例。建表语句如下:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2,
...
PROJECTION projection_name_1 (SELECT <COLUMN LIST EXPR> [GROUP BY] [ORDER BY]),
PROJECTION projection_name_2 (SELECT <COLUMN LIST EXPR> [GROUP BY] [ORDER BY])
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr
[DELETE|TO DISK 'xxx'|TO VOLUME 'xxx' [, ...] ]
[WHERE conditions]
[GROUP BY key_expr [SET v1 = aggr_func(v1) [, v2 = aggr_func(v2) ...]] ] ]
[SETTINGS name=value, ...]
- ClickHouse的建表语句和hive类似,而且ck也是库名和用户名相互独立的。ck环境启动以后会有一个默认的default库,所以在创建表的时候,如果不指定库名,默认就是在default库下面创建。
- ON CLUSTER 表示在哪个集群上创建表,只有在分布式环境中才会使用,单节点表不需要考虑。和hive不同,ck在创建分布式表和副本表的时候需要在每个节点上单独执行建表语句(分布式表需要先创建local表),对于一个很大的集群,如果每次建表都要在所有节点上执行,无疑是很麻烦的,而且一般情况下为了做HA、负载均衡,并且方便使用,只会对应用端暴露一个负载虚拟IP,就无法在每个节点上执行建表语句,此时就可以在ck的配置文件中创建一个同步DDL语句的集群(需要依赖zookeeper),这样一旦执行DDL语句就可以通过zookeeper同步到所有节点上执行。
- ck的建表语句字段定义格式和其他关系型数据库一样,也是 字段名+字段类型 定义,也可以设置默认值,过期时间等。ck的数据类型可参考官网介绍。
- ENGINE = MergeTree() 表示定义表引擎是 MergeTree ,其他表引擎也是如此,只是名称和参数不同。在一些历史版本中,可能会见到带参数的MergeTree引擎建表语句,只是把后面的分区等建表参数作为了MergeTree()的参数而已,ck已经废弃了这种用法。
- PARTITION BY 定义分区字段,和hive一样,MergeTree表的不同分区数据也是存在不同的目录中,和hive每个分区数据是有不同的小文件组成不同,MergeTree的分区数据一般是有不同的列数据文件组成的,后面会详细介绍。
- PRIMARY KEY 定义主键字段,一般是通过ORDER BY字段定义,不单独定义,除非是和ORDER BY字段不同时才会单独定义主键字段,且必须是ORDER BY前面的字段,和其他数据库不同的是MergeTree的主键字段是可以重复的。
- ORDER BY 定义排序字段,也是MergeTree引擎最为重要的建表参数,通过建表语句也可以发现,其他定义字段都不是必须的,只有ORDER BY是必须的,当然如果实在不需要定义ORDER BY字段,可以使用 ORDER BY tuple() 语法建表。在使用insert … select 语句插入数据时,如果想保证数据存储顺序和插入顺序一致,除了不指定ORDER BY外,还需要设置 max_insert_threads = 1。如果没有定义主键字段,ORDER BY 字段就是主键,使用中多是不单独定义PRIMARY KEY,但是在 CollapsingMergeTree 和 SummingMergeTree 表引擎中,分开定义主键和排序键可能会更有意义。需要注意,即使单独定义主键和排序列,主键列也要位于排序列的前面。MergeTree 表数据的存储顺序就是按照 ORDER BY 字段顺序存储的,因为ck采用的是稀疏索引,所以定义合适的 ORDER BY 字段对于查询效率尤为重要。默认情况下ck的主键不能为空,可以通过设置allow_nullable_key选项,允许主键为空,但是强烈建议不要这样做,尤其在<= 21.8版本中,可能会导致数据库崩溃。

如图1,有一个ORDER BY CounterID, Date 的 MergeTree表,ck在存储数据的时候首先按照ORDER BY顺序存储数据,然后按照等距(图1是每七条记录)采样一组主键元素,并把采样数据单独保存为一个文件。这样在查询的时候只需要先在主键数据文件进行查找,找到对应块的偏移距离,然后按照偏移量到数据文件中对应的块查找就可以了。例如,查找 CounterID in (‘a’, ‘h’) 的数据,会首先检索出 0、1、2、6、7号块的数据,然后再筛选2、6、7块中符合条件的数据(0、1块数据显然都是符合的)。 - SAMPLE BY 采样字段,一般在对数据结果准确性要求不高的时候使用,比如计算平均值,如果数据量较大,只会对定义的采样字段采样数据计算,但是采样字段必须定义在主键中,如 SAMPLE BY intHash32(UserID) ORDER BY (CounterID, EventDate, intHash32(UserID))。
- TTL 定义数据有效期,和redis类似,redis作为缓存服务器可以存储具有时间有效期特性的数据,如验证码数据。ck可以定义列级TTL,也可以定义表级TTL,如果是列级TTL,则该列值到期后会被置为默认值,如果所有列都到期,则删除,注意TTL列不能作为键,创建TTL列表:
CREATE TABLE example_table
(
d DateTime,
a Int TTL d + INTERVAL 1 MONTH,
b Int TTL d + INTERVAL 1 MONTH,
c String
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(d)
ORDER BY d;
相对于列级TTL,一般更常用表级TTL,可用来存储对历史数据不再关注的数据,而且表TTL可以把过期数据移动到磁盘或者卷(关于卷和磁盘的区别参见10),例如在训练模型进行在线迁移学习的时候,会一直使用新数据优化模型,不再关注历史数据等。创建表级TTL表:
CREATE TABLE example_table
(
d DateTime,
a Int
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(d)
ORDER BY d
TTL d + INTERVAL 1 MONTH [DELETE],
d + INTERVAL 1 WEEK TO VOLUME 'aaa',
d + INTERVAL 2 WEEK TO DISK 'bbb';
- SETTINGS 用来设置一些附加参数,大多数情况下都不需要设置,可能用到的参数如下:
- index_granularity 索引粒度(按行),默认是8192,即每8192行数据采样一条索引数据,例如,图1的索引粒度是7.
- index_granularity_bytes 索引粒度(按字节),默认是10Mb,表示自适应间隔大小的特性,即根据每一批写入数据的体量大小,动态划分间隔(part)大小。
- min_index_granularity_bytes 允许的最小索引粒度(按字节),默认值是 1024 b,防止意外地创建index_granularity_bytes非常小的保护机制。
- enable_mixed_granularity_parts 开启或者关闭index_granularity_bytes ,对于行数据很大的表,开启此选项可提升查询效率。
- storage_policy (存储策略):MergeTree家族表引擎可以在多个块设备上存储数据,这对于区分冷热场景的数据查询降低成本非常有用。例如,对于电商数据,最近半年的数据查询频率会比较高,响应要快,可以使用SSD存储,半年以上的数据(长尾数据),查询很少,可以响应慢一些,也就是可以使用低成本的存储介质,如HDD。
在继续介绍之前,首先区分几个概念:
① disk(磁盘):挂载到文件系统的块设备。
② default disk:服务器中指定的存储路径。
③ volume(卷):相同disk的有序集合,类似于JBOD。
④ Storage policy(存储策略):一组volume以及在volume之间移动数据的规则。
ck支持设置按照分区移动数据,也可以通过alter语句手动执行:
ALTER TABLE hits MOVE PART '20190301_14343_16206_438' TO VOLUME 'slow'
ALTER TABLE hits MOVE PARTITION '2019-09-01' TO DISK 'fast_ssd'
如果想通过配置实现数据的自动转移,可参考官方文档在配置文件中设置。
关于ck服务器的存储策略和资源信息可通过 system.storage_policies 和 system.disks 表查看。
- min_bytes_for_wide_part, min_rows_for_wide_part 数据文件中可以以宽格式存储的最小片段(part)字节/行数。宽格式指不同的列存储在不同的文件中,这也是默认的存储格式,对于一些小表,可以设置该值,使得所有列存储在同一个文件中,从而增加小而频繁的插入性能。
- max_partitions_to_read 限制一个查询中可以访问的最大分区数,默认是不限制。
4. MergeTree表数据存储结构
前面我们已经介绍了分区、索引粒度、order by等概念,接下来我们具体介绍clickhouse是怎么存储数据的。首先看一下clickhouse的目录结构:

和数据存储相关的目录主要是 data 和 metadata 目录,其中 metadata 目录是保存元数据的目录,结构如下:

可以发现metadata目录保存的数据就是建库和建表语句信息,default.sql 是create db sql,default目录下是default库中所有表的建表sql文件。
回到clickhouse根目录下的data目录,data目录下也是按照库名分为不同的子目录,例如default目录对应的就是default库,default目录下又按照表分为了不同的子目录。
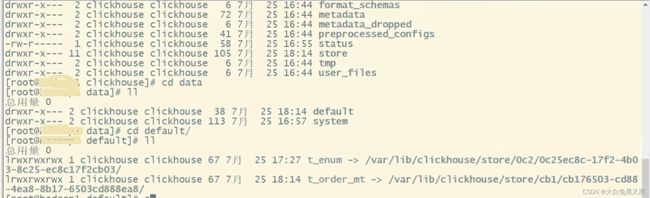
通过上面两幅图可以发现,clickhouse的实际存储目录是 store 目录,只是store目录下都是一些不直观的id文件,不便于观察,因此做了软连接映射到data和metadata目录。
上面的存储结构是clickhouse的存储目录结构,并不是mergetree独有的,下面我们来介绍mergetree引擎表的存储结构。
clickhouse对分区的处理和hive一样,也是通过目录来隔离的,但是目录名称略有不同,命名格式为 {0}{1}{2}_{3} ,其中 {0}是分区名(分区id),{1}是分区目录内最小的数据块编号(minblocknum),{2}是分区目录内最大的数据块编号(maxblocknum),{3}是目前合并的层级(level)。对于没有分区的表,数据都存在一个分区id为 all 的目录内,例如目录名为: all_1_1_0,对于有分区的表,如果分区是日期或者整型类型,则分区id就是分区字段值,如果是其他类型,则取hash值作为分区id,例如分区目录名为:20220301_1_1_0。为什么会存在数据块编号和合并层级呢?因为 mergetree 在写入数据的时候并不是直接写入原始分区内的,而是先写入临时分区,然后在空闲的时候合并分区(或者手动执行optimize语句触发合并),合并后的分区minblocknum取同一分区内的minblocknum最小值、maxblocknum取同一分区内的maxblocknum最大值、level取同一分区内的level最大值加1(level也隐含表示合并次数),这也是mergetree 名称的由来。例如对于合并前分区目录如下:
20220301_1_1_0
20220301_2_2_0
20220301_3_3_0
合并后就是:20220301_1_3_1。
再解释一下分区block的概念,blocknum从1开始,每当创建一个新的分区目录时,新分区的minblocknum和maxblocknum都是一样的,并且是原有maxblocknum最大值加1。
※ 注意:这里需要注意区分block和上文提到且下文要详细介绍的自适应索引粒度的压缩块part不是一个概念。
接下来我们看一下每个分区内部的文件:
# 基础文件
checksums.txt
columns.txt
count.txt
partition.dat
primary.idx
default_compression_codec.txt
# 窄格式(compact)存储数据文件
data.bin
data.mrk 或者 data.mrk3
minmax_{分区列名}.idx
# 宽格式(wide)存储数据文件
{column1_name}.bin
{column1_name}.mrk 或者 {column1_name}.mrk2
minmax_{column1_name}.idx
...
# 二级索引文件
- checksums.txt 校验文件,主要保存文件的大小和hash值。
- columns.txt 列信息文件,保存列数量、列名、列类型
- count.txt 计数文件,保存当前分区下的总记录数,所以mergetree表查询数量是很快的
- partition.dat 保存当前分区下分区表达式最终生成值
- primary.idx 主键及索引文件,保存数据如图1中的marks,在内存中常驻,查询速度较快。
- 数据存储文件: 数据存储文件分为两种,一种为窄格式(compact),一种为宽格式(wide),区别见第三节min_bytes_for_wide_part, min_rows_for_wide_part 参数解释。
对于小文件,或者频繁有小批量数据插入的情况,mergetree为了提高写效率,可以通过设置min_bytes_for_wide_part/min_rows_for_wide_part 参数使得bin文件只有一个,即所有列都保存在一个文件中。如果一个批次写入的数据小于 min_bytes_for_wide_part/min_rows_for_wide_part,则生成的临时分区文件就是compact格式,也就是说同一个逻辑分区的不同临时分区可能既有wide格式的数据,也有compact格式的数据,也可以查询 system.parts 表,查看part信息。
bin文件:存储压缩数据的二进制文件
mrk文件:标记文件,当我们通过主键查询一条记录时,首先通过primary.idx 文件和主键的mrk文件找到记录位置,然后再通过mrk文件找到其他列在对应bin文件中的位置,然后读数据。为什么还要单独维护一个mrk文件呢?因为bin文件是按照粒度(part)压缩存储的,而且不同类型的列使用的压缩算法可以不同。mrk2、mrk3分别是wide、compact格式下的自适应索引标记文件,详细解释在下一节介绍。 - minmax_{column_name}.idx 列最大、最小值文件,包括分区列,所以MergeTree表统计min/max值效率也很高,而且min/max idx文件可以提升查询效率,例如如果按月分区,可能当前分区内只有1~20日的数据,如果查询24日的数据,和分区列最大值比较后就可以直接返回空了。
- 二级索引文件只有在设置二级索引时才会出现,主要是为了提升非主键字段的查询效率,我们将在后面的文章中详细介绍。
※ 附录:MergeTree引擎本质是在LSM Tree基础上做了简化,去掉了 MemTable 和 Log,也就是写入数据时不经过缓存直接写入磁盘,所以不建议频繁的小批量写入。在新版clickhouse中除了引入min_rows_for_wide_part外,还引入了WAL(预写日志,防止MemTable丢失),具体表现为 min_rows_for_compact_part 参数。
当写入数据小于 min_rows_for_compact_part 时,不会生成分区目录,会有一个独立于所有分区外的 wal.bin 文件,如果执行OPTIMIZE语句,会生成新的分区目录文件。min_rows_for_compact_part就是In-Memory part与Compact part之间的行数阈值,一次写入的数据行数大于此值,就会按照传统方式直接向磁盘flush形成Compact part(或者Wide part),不保存在内存中,也不会写WAL。反之,则会将数据保留成In-Memory part,并同时写入WAL,在下一次发生merge时再进行flush。同理,也存在min_bytes_for_compact_part参数,即In-Memory part与Compact part之间的大小阈值。这两个参数默认也都为0,表示禁用In-Memory part和WAL。WAL的大小也不是无限增长的,write_ahead_log_max_bytes 参数用于限制wal.bin的大小。
WAL虽提高了写性能,但是无疑也牺牲了读性能,所以在使用时需要权衡,对于例如只在凌晨进行频繁计算写操作,其他时间进行读操作的场景就比较适合。
※ 注意:Hive分区目录内的数据会被划分为一个个按照序号命名的小文件,本质上数据是存储在Hdfs上的,而Hdfs的存储是按照文件块(一般默认128M)管理的,所以HIve存储能力在分布式节点上的横向扩展是通过Hdfs实现的。MergeTree表的分区目录是针对本地数据(一个节点)而言的,其在多节点上的横向扩展存储是通过分片来实现的,和Hive不同,后面在介绍分布式表的文章中,我们会详细说明。
5. MergeTree自适应索引粒度
在第3节我们介绍索引粒度的时候提到了两个参数:index_granularity (按行,默认8192)、index_granularity_bytes(按字节,默认10Mb),在第4节介绍标记文件时也提到了两种标记格式:mrk和mrk2/mrk3,为什么会有两种形式呢?这就和MergeTree自适应索引粒度有关。
在clickhouse的早期版本中,采用的是固定值索引,默认 index_granularity = 8192,也就是每隔8192行数据 primary.idx 就保存一个稀疏索引标记。
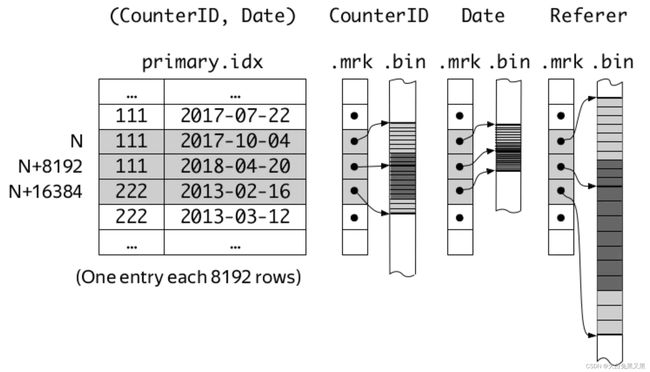
如果建表的时候设置index_granularity_bytes=0, 关闭自适应索引,那么稀疏索引粒度和一个压缩块(part)还是8192行,生成的标记文件是mrk文件。对于类型为UInt8类型的字段,mrk文件的内容格式如下:
0 0
0 8192
0 16384
0 24576
0 32768
0 40960
0 49152
0 57344
19423 0
19423 8192
19423 16384
19423 24576
19423 32768
19423 40960
19423 49152
19423 57344
45658 0
45658 8192
45658 16384
45658 24576
mrk文件共有两列,第一列表示该行所在的数据块(part)在对应bin文件中的起始偏移量,第二列表示该行在数据块解压后在part内部的偏移量,单位均为字节,因为U8Int刚好一个字节,所以可以看到第二列都是8192的倍数,为什么每个part内是8个稀疏索引偏移量呢?因为bin文件的压缩规则是每个part压缩前大小是64K~1M (参数min_compress_block_size和max_compress_block_size),8 * 8192 / 1024=64K,刚好切割为一个part压缩存储。如果一个索引粒度对应的数据超过1M,则会被切分为多个part压缩存储。一个压缩块有两部分数据组成:头文件和需要压缩的数据,头文件大小为9字节,包括:压缩算法(1字节UInt8)、压缩后大小(4字节UInt32)、压缩前大小(4字节UInt32)。
※ 附录:压缩算法编号:
LZ4:0x82
ZSTD: 0x90
Multiple: 0x91
Delta: 0x92
这种索引标记对于像整型、短字符串等数据是比较友好的,但是如果存储的数据比较大,就会造成一个固定索引粒度内数据太大,影响写入新数据的效率。为此,clickhouse引入了自适应索引粒度功能,主要表现就是一个索引粒度(间隔)的行数不再是固定的,并且自适应索引粒度默认是开启的(index_granularity_bytes参数)。
index_granularity_bytes表示每隔指定的文件大小生成索引和标记,与index_granularity共同作用,即只要满足两个条件之一即生成,索引间隔会出现小于8192的情况。一旦出现了自适应的数据,mrk文件就会改为mrk2/mrk3。下面是一个mrk2文件的内容:
[root@ck-test001 201403_1_32_3]# od -An -l -j 0 -N 2048 --width=24 Age.mrk2
0 0 1120
0 1120 1120
0 2240 1120
0 3360 1120
0 4480 1120
0 5600 1120
0 6720 1120
0 7840 352
0 8192 1111
0 9303 1111
0 10414 1111
0 11525 1111
0 12636 1111
0 13747 1111
0 14858 1111
0 15969 415
0 16384 1096
...... ...... ......
17694 0 1102
17694 1102 1102
17694 2204 1102
17694 3306 1102
17694 4408 1102
17694 5510 1102
17694 6612 956
17694 7568 1104
# ......
可以发现数据有三列,前两列和mrk文件内容一致,第三列是相邻两个标记位置之间相隔的行数。在索引粒度大于index_granularity_bytes 或者索引位置是index_granularity整数倍时都会记入标记文件。