顶刊TIP 2022!阿里提出:从分布视角出发理解和提升对抗样本的迁移性
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
阿里巴巴 AAIG 与浙江大学团队在对抗迁移攻击问题中,通过引入数据分布的视角出发,利用 score matching 对替代的判别式模型与数据分布进行对齐,从而在提到模型中引入更多的数据分布相关的信息,提升对抗样本的迁移能力。与现有最佳基于生成模型的攻击方法 TTP 成功率是 46.47%,而我们的方法可以达到 75.93% 的成功率,超过现有最佳方法 29.46%。我们的方法是目前有目标迁移性攻击效果最佳的方法。此外,我们也在谷歌识图上测试了我们迁移攻击算法的有效性。该工作“Towards Understanding and Boosting Adversarial Transferability from a Distribution Perspective” 目前已被TIP2022接收,本文将详细介绍该相应技术。
作者:朱尧,陈岳峰,李小丹等
论文地址:
https://arxiv.org/abs/2210.04213
开源地址:
https://github.com/alibaba/easyrobust
1. 背景
对抗样本近年来受到了越来越多深度学习研究者的重视。研究人员发现在输入样本上添加一个人眼难以察觉的微小扰动,就可以灾难性的改变神经网络的预测结果。这种被恶意修改过的输入样本被称为对抗样本。对抗样本具有迁移能力,即在源模型上产生的对抗样本,有概率可以攻击另一个模型架构、模型参数完全不同的目标深度模型。在实际测试中,目标模型的结构和参数往往是未知的,利用对抗样本的迁移能力,可以有效的验证模型的鲁棒性。
现有研究已经提出了很多方法来增强对抗迁移性,但是迁移性的原因依旧是未解之谜。
2. 难点
无目标攻击对抗样本的迁移性在源模型和目标模型结构相似时效果尚佳,但是如果模型结构差异较大时效果下降明显,如从 CNN 迁移到 ViT。
有目标攻击场景下,使用迭代方法产生的对抗样本的迁移性非常低,目前效果最佳的方法是基于生成模型的方法,需要针对每一个目标类别训练生成模型。
3. 现有假设
模型的结构会影响迁移性: 不同模型结构比如有跳连的模型ResNet,DenseNet;没有跳连的模型VGG;基于Transformer的模型ViT等等产生的对抗样本在迁移性上存在差异。
模型的准确性影响迁移性: 训练的更好的模型(准确性越高)可能具有更好的分类边界,从而产生更好的对抗样本。
使用数据增广提升对抗样本的迁移性: 在模型训练中往往使用数据增广提升模型的泛化性,这一类方法考虑对输入数据进行增广提升对抗样本的迁移性。
改进对抗样本生成算法提升迁移性:PGD是对抗攻击常用的方法,现有研究提出一些对PGD的改进方案来提升对抗样本的迁移性。
4. 从分布视角理解迁移性
在我们的工作中,我们没有像过去的文章一样从源模型产生对抗样本的过程以及源模型的分类边界上思考对抗样本的迁移性的问题。我们考虑到在做图像识别时,模型架构是多种多样的,但是它们都有一个共同的点--训练数据集是服从相同分布的。深度学习中有一个典型的假设“独立同分布”,即验证集的数据与训练集的数据虽然是独立的,但是是服从相同的数据分布的。不同模型都期待能够将属于特定分布的图像分类为特定类别,比如将来自于“猫”类别的图像预测为“猫”。但是如果样本是一个分布外样本(out-of-distribution),深度模型往往难以给出准确的预测。
因此,我们提出应该从数据分布的视角来理解迁移性,如果无目标攻击能够使数据成为分布外样本,那么不同的模型都将难以识别该样本,这样的无目标攻击应该具有更强的迁移性;如果有目标攻击能够使数据成为目标分布内的样本,那么不同的模型都倾向于将该样本分类为目标类。
5. 我们的方法
根据我们的分析,从分布的视角产生对抗样本应该会具有更强的迁移性,无目标对抗攻击可以表达为:
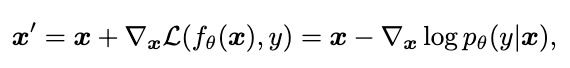
普通的对抗攻击旨在于最大化模型的分类损失,即最小化条件概率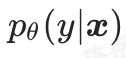 。朗之万动力学(SGLD)给出了一种使用梯度改变样本所属数据分布的方法:
。朗之万动力学(SGLD)给出了一种使用梯度改变样本所属数据分布的方法:
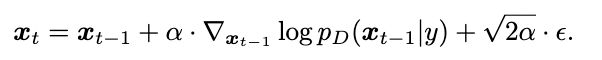
其中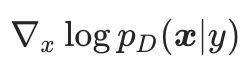 表示真实数据分布
表示真实数据分布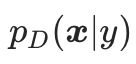 的梯度,从初识样本出发,沿着真实数据分布的梯度的方向优化样本,如果迭代次数t足够大,可以获得服从数据分布
的梯度,从初识样本出发,沿着真实数据分布的梯度的方向优化样本,如果迭代次数t足够大,可以获得服从数据分布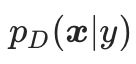 的样本。如果我们能够获得真实数据分布的梯度,那么我们可以利用这个梯度改变样本所属的数据分布,从而获得具有高迁移性的对抗样本。
的样本。如果我们能够获得真实数据分布的梯度,那么我们可以利用这个梯度改变样本所属的数据分布,从而获得具有高迁移性的对抗样本。
考虑到我们的难以获得准确的真实数据分布的梯度,在本文中我们提出最小化模型的梯度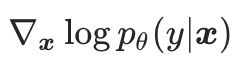 与真实数据分布的梯度
与真实数据分布的梯度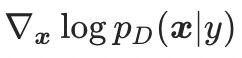 之间的距离,从而利用模型的梯度近似数据分布的梯度,这样产生的对抗样本也就可以对数据所属的分布进行改动:
之间的距离,从而利用模型的梯度近似数据分布的梯度,这样产生的对抗样本也就可以对数据所属的分布进行改动:
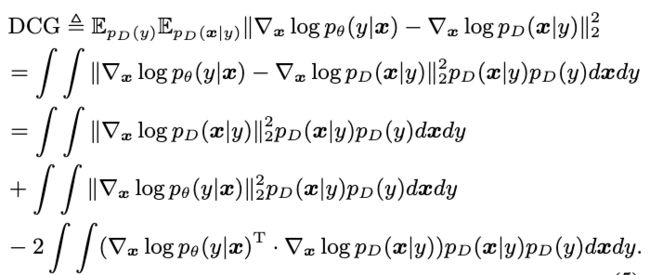
其中,第一项是仅仅与数据分布相关的,数据分布是固定的,因此这是一个常数;第二项是模型相关的不包含未知的数据分布的梯度,因此是容易计算的;第三项包含了模型的梯度,以及数据分布的梯度,我们使用分部积分的方法对其进行化简。最终可以得到这样的表达式:
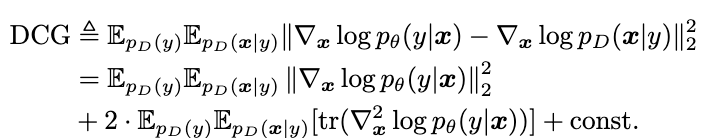
我们对现有模型进行微调,最小化DCG。微调后,模型的梯度与数据分布的梯度之间距离相比普通模型更小,我们使用模型的梯度来近似数据分布的梯度,因此基于梯度的对抗攻击方法可以在微调后的模型上生成改变了数据分布信息的对抗样本。
直观上看,我们的方法产生的有目标攻击,可以使对抗样本具有目标类别数据分布相关的信息:

我们将一张“青蛙”的图像攻击到“玉米”类别,从左到右逐渐增加攻击强度,可见普通的PGD对抗攻击产生的对抗样本更像噪声,而我们的方法产生的对抗样本中具有了目标类别的特征,图像中出现了一些玉米形状,这意味着我们的方法确实可以改变图像所属的数据分布,这可能导致不同模型都将该样本分类为目标攻击的类别,提升有目标攻击迁移性。
我们的方法产生的无目标攻击可以获得与原始样本数据分布不同的样本,深度模型对于与训练集同分布的验证样本有良好的分类准确度,但是面对分布外样本可能束手无策,因此我们的方法可以大幅度提升无目标攻击的迁移性:
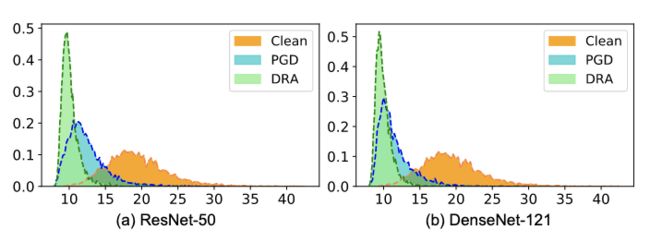
这幅图像中我们使用基于能量分数的分布外样本检测方法来判断样本的分布,横坐标是得分,纵坐标是百分百,得分小的样本被认为是分布外样本。可见我们的方法(DRA)产生的对抗样本与原始数据分布差异更大,因此会使得不同的目标模型都难以识别该样本,增强了对抗样本的无目标攻击迁移性。
6. 实验结果
与现有方法相比我们的方案在无目标攻击和有目标攻击场景下都带来了大幅度的效果提升。
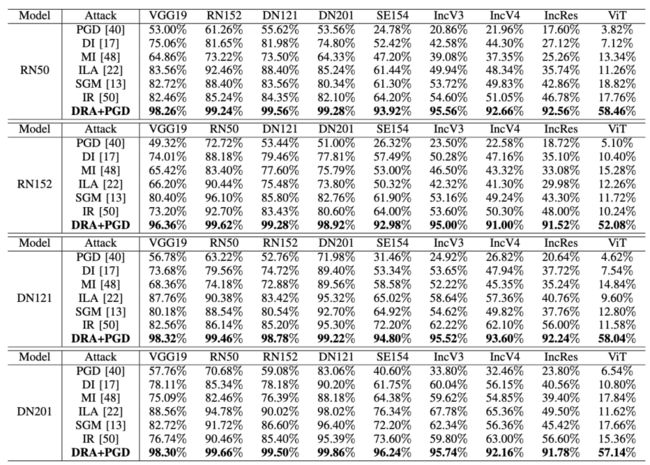
无目标攻击
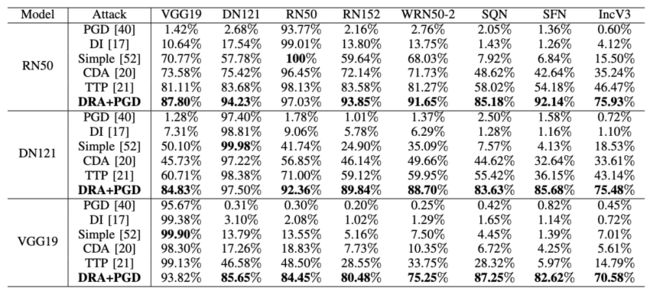
我们的方法在对抗迁移性上相比现有方法在某些场景下具有40%以上的提升,从ResNet-50源模型产生对抗样本迁移到ViT模型上,现有效果最好的方法攻击成功率是18.82%,而我们的方法攻击成功率是58.46%,效果提升了39.64%。我们的方法是目前无目标迁移性攻击效果最佳的方法。
有目标攻击
有目标攻击相对于无目标攻击是一个较难的问题,现有的基于迭代的攻击方法在有目标攻击场景下成功率较低,TTP和CDA是基于生成模型的攻击方法,它们为每一个目标类别训练相应的模型来生成对抗样本。当从ResNet-50源模型产生对抗样本,攻击Inception V3目标模型时,现有最佳迭代攻击算法Simple成功率是15.50%,现有最佳基于生成模型的攻击方法TTP成功率是46.47%,而我们的方法可以达到75.93%的成功率,超过现有最佳方法29.46%。我们的方法是目前有目标迁移性攻击效果最佳的方法。
攻击谷歌识图
我们的方法可以成功的产生有目标攻击对抗样本欺骗谷歌识图等真实世界中的计算机视觉系统,比如下图中的仓鼠和狐狸,谷歌识图以很高的概率将它们误分为目标类别“玉米”。

7. 总结
迁移对抗攻击可以从已知结构和参数的源模型上产生对抗样本来黑盒的攻击未知的目标模型,这对于验证模型的鲁棒性是一种高效的方案,有利于我们更好的理解模型和鼓励我们创建更安全的模型。目前,对抗攻击为什么具有迁移性还处在一个众说纷纭的阶段,与过去从模型的视角分析迁移性不同,我们从数据本身出发,从数据分布的视角给出了对抗样本迁移性的一种理解,根据我们的理解,我们提出了微调源模型来最小化模型的梯度与数据分布的梯度之间的距离,从而可以利用模型的梯度近似数据分布的梯度,这样基于梯度的攻击方法可以改变样本所属的数据分布,实验表明我们的方案是目前迁移性最佳的攻击方法,在某些场景下可以超过现有方法40%以上。
关于我们
AAIG安全实验室致力于人工智能特别是深度学习的前沿技术研究与应用实践,实现可靠、可信、可用的人工智能系统。目前实验室成员包含十余名算法工程师,在TPAMI、NeurIPS、ICLR、CVPR、TIP、ICCV、ECCV、EMNLP、IEEE S&P、USENIX Security、CCS等学术会议上和期刊上发表多篇高水平论文,累计申请专利多项,参与多项国际国内技术标准制定,荣获中国人工智能大赛深度伪造视频检测A级证书。主要研究方向包括:人工智能安全性、鲁棒性、可解释性、公平性、迁移性、隐私保护和因果推理等,从基础理论研究和技术创新两方面。与清华、中科院、浙大、上交、中科大等国内知名高校建立学术合作关系。实验室目前正在招聘研究型实习生,对人工智能安全方向有兴趣的可以发简历到:[email protected]。
整理不易,请点赞和在看