一条更新SQL语句是如何执行的?
前言
在上篇文章《一条查询SQL语句是如何执行的?》 介绍了一些常用组件,一般是经过连接器、分析器、优化器、执行器等功能模块,最后到达存储引擎。本文是介绍一条更新语句如何执行,还会介绍一写其他组件,现在让我们开始吧。
Buffer Pool
我们知道在执行 sql 对某一行进行操作时,每次对磁盘操作其实是很慢的。为了解决这个问题,我们设置了一个缓冲池。这个缓冲池简单来说就是一块内存区域,这是InnoDB设置的,不是MySQL的服务端设置的。它存在的原因之一是为了避免每次都去访问磁盘,把最常访问的数据放在缓存里,提高数据的访问速度。
当读取数据的时候,要查找的数据所在的数据页在内存中时,则将结果返回。否则会把对应的数据页加载到内存中,然后再返回结果;对于写操作来说,如果要修改的行所在的数据页在内存中,则修改后返回对应的结果。如果不在的话,则会从磁盘里将该行所对应的数据页读到内存中再进行修改。
当内存的数据页和磁盘的数据不一致时候,我们把它叫做脏页。Innodb里面有专门的后台线程把Buffer Pool的数据写入到磁盘,每隔一段时间就一次性地把多个修改写入磁盘,这个动作就叫做刷脏。

缓冲池的存在可以减少磁盘 i/o 带来的开销,对于加载数据页这种无法避免的磁盘 i/o 来说,我们还可以再优化,那就是减少磁盘 i/o 的次数,这里就要讲到预读的概念。无论是操作系统也好,存储引擎也好,都有预读的概念,也就是说,当磁盘上的一块数据被读取的时候,很有可能它附近的位置也会马上被读取到,这个就叫做局部性原理。那么这样,我们干脆每次多读取一点,而不是用多少读多少。这个读取的最小单位叫做页,操作系统中页大小一般是4kb,而在InnoDB中,页的大小是16kb。
缓冲池默认是128M,既然大小是有限的,就会有数据满的时候,这时候就会采用LRU算法来淘汰不使用的页。

redo log
redo log叫做重做日志,因为刷脏不是实时的,对磁盘数据的修改也会落后于内存,这时如果进程或机器崩溃,会导致内存数据丢失,为了保证数据库本身的一致性和持久性,InnoDB维护了redo log。这个日志文件记录了所有对页面的修改操作,当崩溃恢复重启的时候,会重放redo log,将page恢复到崩溃前的状态,这个能力就叫做crash-safe。
redo log也是记录在磁盘的,同样是写磁盘,为什么不直接把数据更新到db file里去,这样不是多此一举吗?这么做的原因其实是刷盘是随机I/O,而记录日志是顺序I/O,顺序I/O的效率更高,本质上是数据集中存储和分散存储的区别。因此先把数据写入日志文件,在保证了内存数据的安全性的情况下,可以延迟刷盘时机,从而提高的系统的吞吐量。
redo log默认是2个文件,每个48M。
下图展示的是4个redo log,从头开始写,写到末尾就又回到开头循环写。write pos 是当前记录的位置,一边写一边后移,写到第 3 号文件末尾后就回到 0 号文件开头。checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件。write pos 和 checkpoint 之间的是空着的部分,可以用来记录新的操作,绿色部分。

总结:
- redo log是Innodb存储引擎实现的,并不是所有的存储引擎都有的。支持崩溃恢复是Innodb的一个特性。
- redo log不是记录数据页更新之后的状态,而是记录在某个数据页上做了什么修改,属于物理日志。
- redo log的大小是固定的,前面的内容会被覆盖,一但写满,就会触发buffer pool到磁盘的同步,以便腾出空间给后面的修改。
undo log
除了redo log之外,还有一个跟修改有关的日志,叫做undo log。redo log和undo log与事务密切相关,统称为事务日志。undo log叫做撤销日志或者回滚日志,记录了事务发生之前的数据状态,分为insert undo log和update undo log。如果修改数据时出现异常,可以用undo log来实现回滚操作,保持原子性。
可以理解为undo log记录的是反向操作。比如insert会记录delete,update会记录update原来的值,跟redo log记录在哪个物理页面做了什么操作不同,所以叫做逻辑格式的日志。
undo的一些设置:

binlog
Server 层也有自己的日志,称为 binlog归档日志。最开始 MySQL 里并没有 InnoDB 引擎。MySQL 自带的引擎是 MyISAM,但是 MyISAM 没有 crash-safe 的能力,binlog 日志只能用于归档。而 InnoDB 是另一个公司以插件形式引入 MySQL 的,既然只依靠 binlog 是没有 crash-safe 能力的,所以 InnoDB 使用另外一套日志系统——也就是 redo log 来实现 crash-safe 能力。
redo log 是物理日志,记录的是在某个数据页上做了什么修改;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如 给 ID=2 这一行的 c 字段加 1。binlog以事件的形式记录了所有的DDL和 DML语句。
redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
binlog可以做数据恢复,在开启了binlog功能的情况下,我们可以把binlog导出成SQL语句,把所有的操作重放一遍。binlog另一个功能就是做主从复制,它的原理就是从服务器读取主服务器的binlog,然后执行一遍。
一条更新SQL是如何执行的
介绍了上面这么多的功能,现在我们再来看一条更新语句是如何执行的?
update user set name=‘aaa’ where id=1;
整个执行过程如下:
- 执行器先通过存储引擎找到 id=1 这一行数据。ID 是主键,引擎直接用树搜索找到这一行。如果 ID=1 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据,把name改成aaa,再调用存储引擎接口写入这行新数据。
- 存储引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
- 执行器收到这个通知后记录 binlog,并把 binlog 写入磁盘。
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交commit状态,更新完成。
整个流程图如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rQIcBu0c-1653816518587)(https://p1-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/3c8cbe305eb442a08fa4652d37a1eeb6~tplv-k3u1fbpfcp-watermark.image?)]
写binlog和redo log采用的是两阶段提交。
InnoDB架构
https://dev.mysql.com/doc/refman/5.7/en/innodb-architecture.html

我们看这张架构图一共分两个部分,一个是内存区域,一个是磁盘区域。内存区域有Buffer Pool、Change Buffer、Adaptive Hash、Log Buffer四个组件。
Buffer Pool上面介绍过了。
Change Buffer
当需要更新一个数据页时,如果数据页在内存中就直接更新,而如果这个数据页还没有在内存中的话,在不影响数据一致性的前提下,InooDB 会将这些更新操作缓存在 change buffer 中,这样就不需要从磁盘中读入这个数据页了。在下次查询需要访问这个数据页的时候,将数据页读入内存,然后执行 change buffer 中与这个页有关的操作。通过这种方式就能保证这个数据逻辑的正确性。
前提是没有使用唯一索引,对于唯一索引来说,所有的更新操作都要先判断这个操作是否违反唯一约束性,而这必须要将数据页读入内存才能判断,如果都已经读入到内存了,那就没有必要时用change buffer 了。
5.5之前叫Insert Buffer插入缓冲,现在也能支持delete和update。将 change buffer 中的操作应用到原数据页,得到最新结果的过程称为 merge。除了访问这个数据页会触发 merge 外,系统有后台线程会定期 merge。在数据库正常关闭(shutdown)的过程中,也会执行 merge 操作。
如果数据库大部分索引都是非唯一索引,并且业务是写多读少,不会在写数据后立刻读取,就可以使用Change Buffer(写缓冲)。可以通过调大这个值,来扩大Change的大小,以支持写多读少的业务场景。Change Buffer 默认占 Buffer Pool 的比例是25%。

Adaptive Hash Index
索引是放在磁盘的,这里把Hash索引放在内存。
Redo Log Buffer
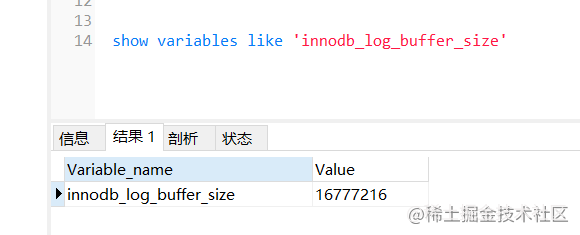
我们知道redo log是存储在磁盘的,但是也不是每次都直接写入磁盘,在Buffer Pool里面有一块内存区域Log Buffer专门用来保存即将要写入日志文件的数据,默认是16M,它一样是为了减少磁盘IO。
那么Log Buffer什么时候写入磁盘?log buffer写入磁盘的时机是由一个参数控制的,默认是1。

innodb_flush_log_at_trx_commit值为0

innodb_flush_log_at_trx_commit值为1
innodb_flush_log_at_trx_commit值为2

下面我们来看下磁盘区域,里面主要是各种各样的表,叫做Table space。表空间可以看做是InnoDB存储引擎逻辑结构的最高层,所有的数据都存放在表空间中。InnoDB的表空间分为5大类。
System tablespace
默认情况下InnoDB存储引擎有一个共享表空间,即/var/lib/mysql/ibdata1文件,也叫系统表空间。系统表空间里包含数据字典,双写缓冲区,Change Buffer和Undo Logs,如果没有指定file-per-table,也包含用户创建的表和索引数据。
数据字典由内部系统表组成,存储表和索引的元数据(定义信息)。双写缓冲区是做什么用的?我们知道InnoDB的页大小默认为16K,操作系统的页是4k,从InnoDB写到磁盘的时候要分4次写。

如果存储引擎在写入页的数据到磁盘时发生了宕机,可能出现页只写了一部分的情况,刚写入了4K或8K数据,那么就不能保证该操作的原子性,称为部分页面写问题(Partial Write Page) 。此时就引入了双写缓存区的机制,当发生极端情况时,可以从系统表空间的Double Write Buffer【磁盘上】进行恢复,相当于是一个副本,通过它来实现数据页的可靠性。

Chang Buffer就是内存中的Chang Buffer同步到磁盘的。在默认的情况下,所有的表空间共享一个系统表空间,这个文件会越来越大,而且它的空间不会收缩。
file-per-table tablespaces
我们可以让每张表独占一个表空间,这个开关通过innodb_file_per_table设置,默认开启。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2hKvDHV6-1653816518608)(https://p6-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/173fc3cdbe374270a5849c5951e276c7~tplv-k3u1fbpfcp-watermark.image?)]
开启后,则每张表会开辟一个表空间,这个文件就是数据目录下的idb文件,例如/var/lib/mysql/jack/user_innodb.ibd,存放表的索引和数据。
但是其他类的数据,如回滚信息undo log,插入缓冲索引页,系统事务信息,双写缓冲区double write buffer等还是存放在原来的共享表空间内。
general tablespaces
通用表空间也是一种共享的表空间,跟ibdata1类似。可以创建一个通用的表空间,用来存储不同数据库的表,数据路径和文件可以自定义。
CREATE TABLESPACE jacktablespace ADD DATAFILE ‘/my/tablespace/directory/ts1.ibd’ FILE_BLOCK_SIZE = 16k ENGINE =innodb;
创建表的时候可以指定表空间
CREATE TABLE t1 (c1 INT PRIMARY KEY) TABLESPACE jacktablespace;
不同表空间的数据是可以移动的,用alter修改表空间
ALTER TABLE t2 TABLESPACE jacktablespace;
删除表空间需要先删除里面所以元素
drop table t1
drop table t2
drop tablespace jacktablespace
temporary tablespaces
存储临时表的数据,包括用户创建的临时表,和磁盘的内部临时表。对应数据目录下的ibtmp1文件。当数据服务器正常关闭时,该表空间被删除,下次重新产生。
undo tablespaces
undo log的数据默认在系统表空间ibdata1文件中,因为共享表空间不会自动收缩,所以也可以单独创建一个undo表空间。
好了,通过一条查询SQL是如何执行的和一条更新SQL是如何执行的两篇文章,把MySQL的组件都介绍了一遍,相信大家也对MySQL的底层原理有了一定了解,感谢收看,欢迎点赞~