常见的卷积神经网络结构——分类、检测和分割
本文持续更新~~
本文整理了近些年来常见的卷积神经网络结构,涵盖了计算机视觉领域的几大基本任务:分类任务、检测任务和分割任务。对于较复杂的网络,本文只会记录其中的核心模块以及重要的网络设计思想,并不会记录完整的网络结构。
有一些网络结构是通用的,可以用于分类、检测和分割任务中的任意一个,本文就选取了其中一个有代表性的任务进行描述。
目录
- 分类任务
-
-
-
-
- 1.VGG
- 2. Inception v1
- 3. Inception V2
- 4. ResNet
- 5. DenseNet
-
-
-
- 检测任务
-
-
-
-
- 1. FPN
- 2. PAN
-
-
-
- 分割任务
-
-
-
-
- 1. FCN
- 2. U-Net
- 3. SegNet
- 4. PSPNet
-
-
-
- 参考文章
分类任务
1.VGG
论文地址:https://arxiv.org/abs/1409.1556
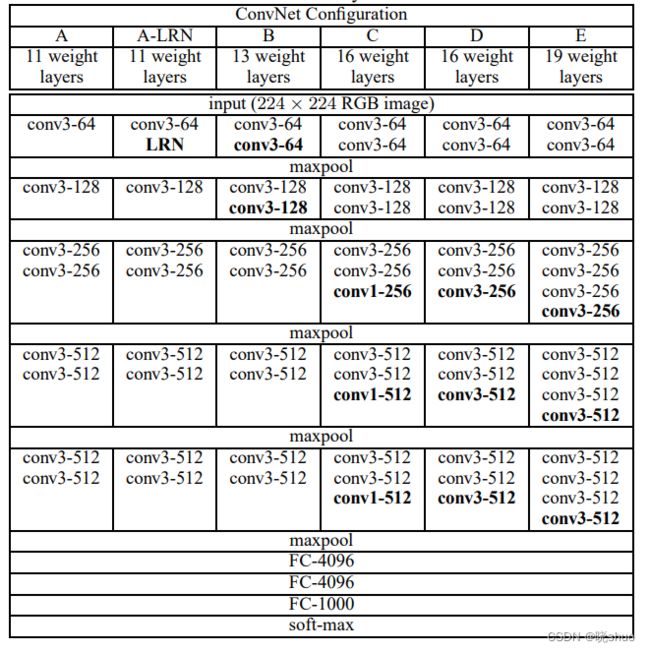
论文提出了6种不同的VGG网络,最常用的是VGG16。VGG16采用了5组13层卷积和5层最大池化,并且使用3层全连接和1层Softmax完成分类任务。
VGGNet使用的卷积核全部为 3 × 3 3×3 3×3,优点在于:两个 3 × 3 3×3 3×3的卷积核和一个 5 × 5 5×5 5×5的卷积核的感受野大小一致,但参数量更少;两个 3 × 3 3×3 3×3的卷积核比一个 5 × 5 5×5 5×5的卷积核的非线性表达能力更强,因为其拥有两个激活函数,可提高网络的学习能力。
2. Inception v1
论文地址:https://arxiv.org/pdf/1409.4842
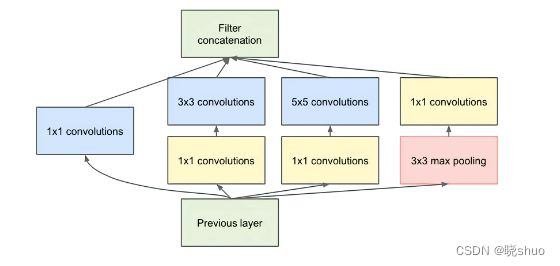
通过设计一个稀疏网络结构,但是能够产生稠密的数据,既能增加神经网络表现,又能保证计算资源的使用效率。 共4个通道,其中3个卷积通道分别使用 1 × 1 1×1 1×1、 3 × 3 3×3 3×3、 5 × 5 5×5 5×5的卷积核,保证了每个通道的感受野大小不同,从而获得不同尺度的特征;1个池化通道采用最大池化操作,以减少空间大小,降低过度拟合。使用 1 × 1 1×1 1×1的卷积核进行降维,减小了特征图的维度。
3. Inception V2
论文地址:https://arxiv.org/pdf/1502.03167
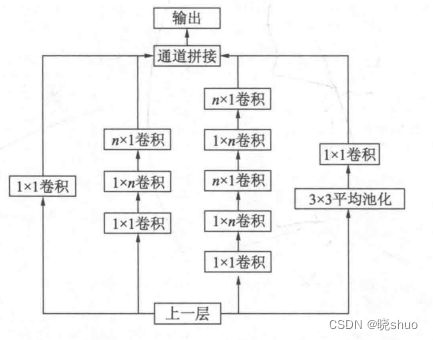
在不增加过多计算量的同时提高网络的表达能力,因而修改 Inception 的内部计算逻辑,提出了比较特殊的卷积计算结构。使用 3 × 3 3×3 3×3的卷积核代替 5 × 5 5×5 5×5的卷积核(用小卷积核代替大卷积核);分解卷积,将 n × n n×n n×n的卷积分解为 1 × n 1×n 1×n + + + n × 1 n×1 n×1,进一步降低了参数量;在保持相同感受野的同时减少参数量。

4. ResNet
论文地址:https://arxiv.org/abs/1512.03385
ResNet可以说是卷积神经网络的一个里程碑式的结构,自从ResNet被提出后,此后的分类、检测和分割等任务大都使用ResNet作为骨干网络进行特征提取。
ResNet的思想比较简单,引入了一个残差结构来解决梯度消失的问题。普通网络需要直接拟合输出 H ( x ) H(x) H(x),而ResNet通过引入一个shortcut连接,将需要拟合的映射变为 F ( x ) = H ( x ) − x F(x)=H(x)-x F(x)=H(x)−x。即相对于直接优化潜在映射 H ( x ) H(x) H(x),优化残差映射 F ( x ) F(x) F(x)更容易。

5. DenseNet
论文地址:https://arxiv.org/abs/1608.06993
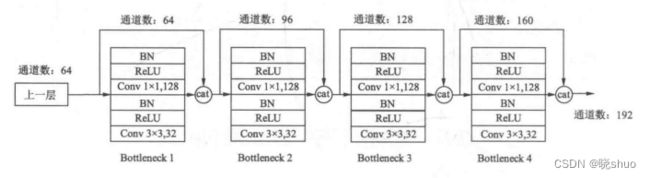
DenseNet通过建立前面所有层与后面层的密集连接,即直接将前面所有层的特征Concat后传到下一层,实现了特征在通道维度上的复用。
DenseNet采用了激活函数在前,卷积层在后的顺序,与一般的卷积网络不同;每个BottleNeck中, 1 × 1 1×1 1×1大小的卷积的作用是固定输出通道数,达到降维的作用。
检测任务
1. FPN
论文地址:https://arxiv.org/abs/1612.03144
FPN(Feature Pyramid Network,特征图金字塔网络),主要解决的是物体检测中的多尺度问题,通过简单的网络连接改变,在基本不增加原有模型计算量的情况下,大幅度提升了小物体检测的性能。FPN通过高层特征进行上采样(对高层特征进行放大,即卷积后的特征数最少的那一层)和低层特征进行自顶向下的连接(反向卷积),而且每一层都会进行预测。
算法大致结构如下:一个自底向上的线路,一个自顶向下的线路,横向连接(lateral connection)。
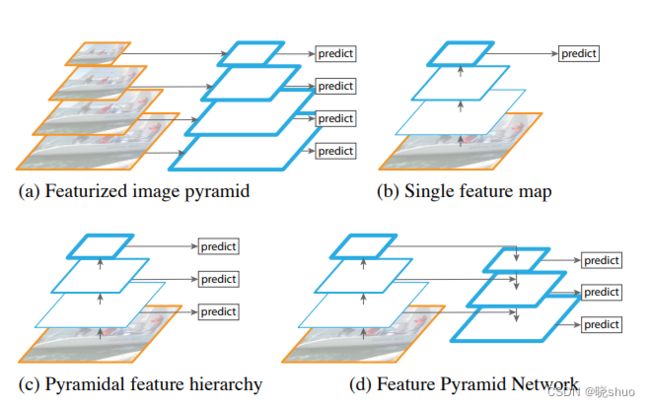
2. PAN
论文地址:https://arxiv.org/abs/1803.01534
PAN(Path Aggregation Network,路径聚合网络)采用自底向上路径增强的方法,在较低的层次上使用精确的定位信号来增强整个特征层次结构,缩短了较低层次与最上层特征之间的信息路径。提出了自适应特征池,它将特征网格和所有特征层连接起来,使每个特征层中的有用信息直接传播到下面的建议子网络。
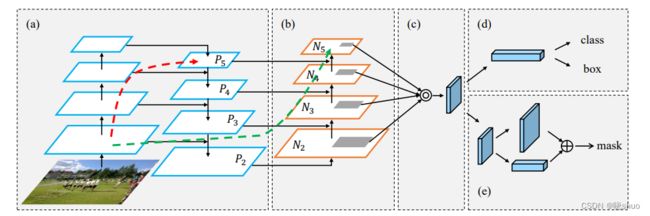
分割任务
1. FCN
论文地址:https://arxiv.org/abs/1411.4038
FCN是对图像进行像素级的分类(也就是每个像素点都进行分类),从而解决了语义级别的图像分割问题。FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的特征图进行上采样,使它恢复到输入图像相同的尺寸,从而可以对每一个像素都产生一个预测,同时保留了原始输入图像中的空间信息,最后在上采样的特征图进行像素的分类。简单的说,FCN与CNN的区别在于FCN把CNN最后的全连接层换成卷积层,其输出的是一张已经标记好的图,而不是一个概率值。
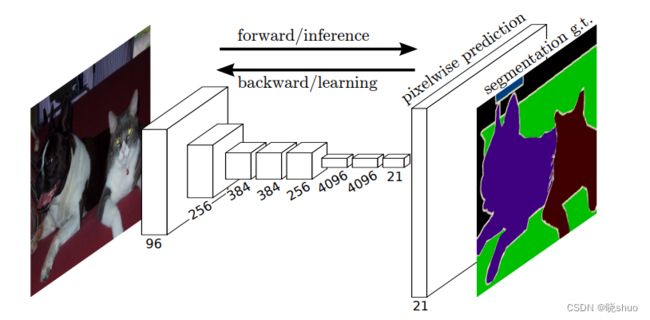
2. U-Net
论文地址:https://arxiv.org/abs/1505.04597
网络的左侧是由卷积和Max Pooling构成的一系列降采样操作,由4个block组成,每个block使用了3个有效卷积和1个Max Pooling降采样,每次降采样之后Feature Map的个数乘2,因此有了图中所示的Feature Map尺寸变化。最终得到了尺寸为 32 × 32 32 × 32 32×32的Feature Map。网络的右侧部分同样由4个block组成,每个block开始之前通过反卷积将Feature Map的尺寸乘2,同时将其个数减半(最后一层略有不同),然后和左侧对称的Feature Map合并,由于左侧和右侧的Feature Map的尺寸不一样,U-Net是通过将左侧的Feature Map裁剪到和扩展路径相同尺寸的Feature Map进行归一化的(即图1中左侧虚线部分)。右侧的卷积操作依旧使用的是有效卷积操作,最终得到的Feature Map的尺寸是 338 × 338 338 × 338 338×338。由于该任务是一个二分类任务,所以网络有两个输出Feature Map。
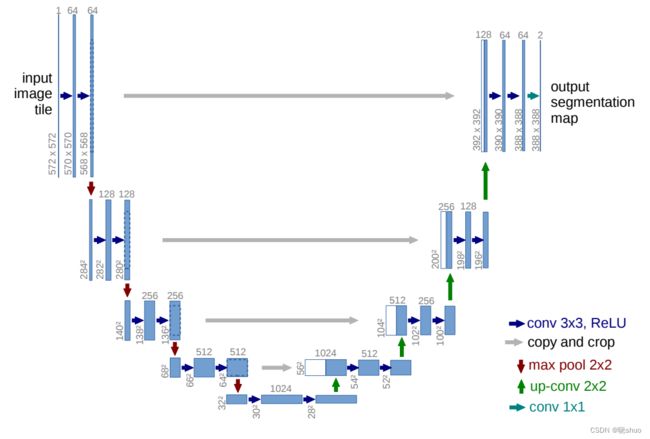
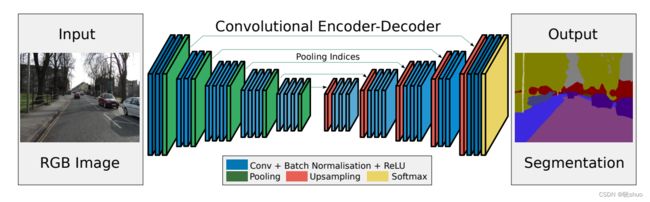
3. SegNet
论文地址:https://arxiv.org/abs/1511.00561
SegNet的核心由一个编码器网络和一个对应的解码器网络以及一个像素级分类层组成。
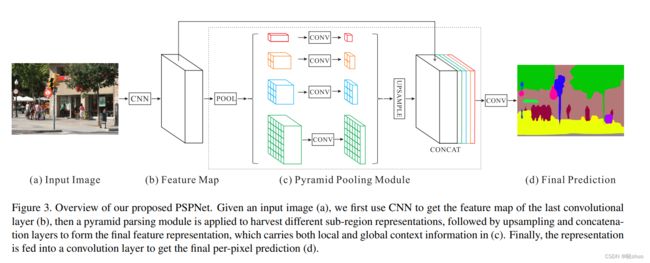
4. PSPNet
论文地址:https://arxiv.org/abs/1612.01105
PSPNet的核心模块是Pyramid Pooling Modules,融合了四种不同金字塔尺度下的特征。通过CNN得到的特征图经过四种尺度的池化操作得到四种尺寸的特征图,然后经过卷积操作改变特征图的通道,在通过上采样操作恢复特征图的尺寸大小,最后与输入特征图进行Concat,得到最终的金字塔池化全局特征。
参考文章
四、全卷积网络FCN详细讲解(超级详细哦)
快速理解Unet的网络结构
SegNet算法详解