polygraphy深度学习模型调试器使用教程
深度学习系列文章目录
文章目录
- 深度学习系列文章目录
- Polygraphy介绍
- 一、安装
-
- 源码安装:
- 简单安装
- 安装依赖
- 二、简单使用
- 三、使用教程
-
- 2 、polygtaphy使用示例
Polygraphy介绍
Polygraphy在我进行模型精度检测和模型推理速度的过程中都有用到,因此在这做一个简单的介绍。polygraphy 是一个深度学习模型调试工具,包含 python API 和 命令行工具,它的功能如下:
使用多种后端运行推理计算,包括 TensorRT, onnxruntime, TensorFlow;
比较不同后端的逐层计算结果;
由模型生成 TensorRT 引擎并序列化为.plan;
查看模型网络的逐层信息;
修改 Onnx 模型,如提取子图,计算图化简;
分析 Onnx 转 TensorRT 失败原因,将原计算图中可以 / 不可以转 TensorRT 的子图分割保存;
隔离 TensorRT 终端 错误 tactic;
一、安装
源码安装:
Github地址:Polygraphy
根据自己的cuda以及cudnn版本选择对应的tensorrt版本,并将源码clone下来
使用anaconda创建虚拟环境(注:polygraphy不支持python2.x)
conda create -n polygraphy python=3.7
在polygraphy目录进入创建的虚拟环境 执行
python -m pip install colored polygraphy --extra-index-url pypi.ngc.nvidia.com
make install
完成polygraphy的安装。
简单安装
使用anaconda创建虚拟环境(注:polygraphy不支持python2.x)
conda create -n polygraphy python=3.7
进入创建的虚拟环境执行
pip install -i pypi.douban.com/simple nvidia-pyindex
python -m pip install colored polygraphy --extra-index-url pypi.ngc.nvidia.com
安装 colored 是为了让cli输出更加清晰明显
完成安装
安装依赖
Polygraphy 对其他 Python 包没有硬依赖。 但是,包含的大部分功能 确实需要其他 Python 包。 就比如对onnx和trt模型推理对比就需要安装onnxruntime和nvidia-tensorrt包。
自动安装依赖
当运行的程序需要哪些包时,程序会自动去安装对应的包要启用此功能可以在环境变量中做如下设置:
export POLYGRAPHY_AUTOINSTALL_DEPS=1
手动安装
如果你将tensorrt源码clone到了本地,那么可以在 tools/Polygraphy/polygraphy/backend 目录下的文件夹找到requirement.txt ,根据该文件你可以安装对应的包。
python -m pip install -r polygraphy/backend//requirements.txt
如果需要其他软件包,将记录警告或错误。 您可以使用以下方法手动安装其他软件包:
python -m pip install
二、简单使用
在 polygraphy\example 目录下存放有多个示例,包括Python API,CLI,现在来简单介绍一下Polygraphy/examples/cli/run/01_comparing_frameworks 这个示例:
首先准备一个onnx模型
input name : data
input shape : batchsize x 3 x 224 x 224
使用polygraphy 生成trt引擎,并将onnxruntime 和 trt的计算结果进行对比
polygraphy run yawn_224.onnx --onnxrt --trt --workspace 256M --save-engine yawn-test.plan --fp16 --verbose --trt-min-shapes 'data:[1,3,224,224]' --trt-opt-shapes 'data:[3,3,224,224]' --trt-max-shapes 'data:[8,3,224,224]' > test.txt
# 命令解析
polygraphy run yawn_224.onnx # 使用onnx模型
--onnxrt --trt # 使用 onnxruntime 和 trt 后端进行推理
--workspace 256M # 使用256M空间用于生成.plan 文件
--save-engine yawn-test.plan # 保存文件
--fp16 # 开启fp16模式
--verbose # 显示生成细节
--trt-min-shapes 'data:[1,3,224,224]' # 设定 最小输入形状
--trt-opt-shapes 'data:[3,3,224,224]' # 设定 最佳输入形状
--trt-max-shapes 'data:[8,3,224,224]' # 设定 最大输入形状
> test.txt # 将终端显示重定向test.txt 文件中
复制代码
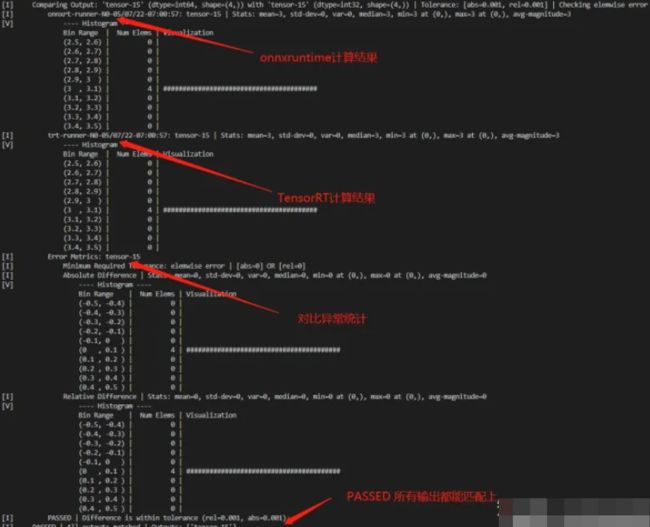
Result
其中 onnxrt_runner 表示的是onnxruntime的推理输出,trt-runner 为trt的输出,两者之间的输出误差对比由 Error Metrics 给出.
误差参数含义
三、使用教程
2 、polygtaphy使用示例
mmdeploy用法:
polygraphy surgeon sanitize end2end.onnx --fold-constants -o end2end_folded.onnx
示例代码:
这里介绍一个polygraphy使用示例,对onnxruntime和TensorRT进行精度对比,流程差不多是这样的:
首先生成一个.onnx文件
其次使用polygraphy生成一个FP16的TRT引擎,并对比使用onnxruntime和TensorRT的计算结果;
然后使用polygraphy生成一个FP32的TRT引擎,将网络中所有层都标记为输出,并对比使用onnxruntime和TensorRT的计算结果(逐层结果对比);
相关代码示意如下:
# 生成一个 .onnx 模型作为 polygraphy 的输入
# export model.onnx from pytorch
# or
# export model.onnx from tensorflow
# 使用上面生成的 model.onnx 构建 TensorRT 引擎,使用 FP16 精度同时在 TensorRT 和 onnxruntime 中运行
polygraphy run model.onnx \
--onnxrt --trt \
--workspace 100000000 \
--save-engine=model_FP16.plan \
--atol 1e-3 --rtol 1e-3 \
--fp16 \
--verbose \
--trt-min-shapes 'x:0:[1,1,28,28]' \
--trt-opt-shapes 'x:0:[4,1,28,28]' \
--trt-max-shapes 'x:0:[16,1,28,28]' \
--input-shapes 'x:0:[4,1,28,28]' \
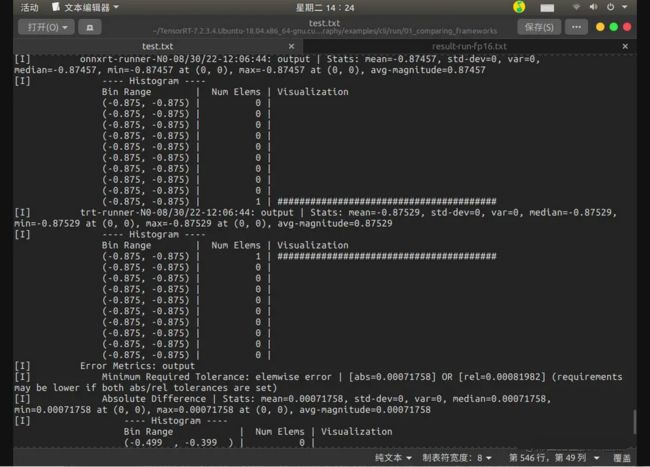
> result-run-FP16.txt
# 使用上面生成的 model.onnx 构建 TensorRT 引擎,使用 FP32 精度同时在 TensorRT 和 onnxruntime 中运行
# 输出所有层的计算结果作对比
polygraphy run model.onnx \
--onnxrt --trt \
--workspace 100000000 \
--save-engine=model_FP32_MarkAll.plan \
--atol 1e-3 --rtol 1e-3 \
--verbose \
--onnx-outputs mark all \
--trt-outputs mark all \
--trt-min-shapes 'x:0:[1,1,28,28]' \
--trt-opt-shapes 'x:0:[4,1,28,28]' \
--trt-max-shapes 'x:0:[16,1,28,28]' \
--input-shapes 'x:0:[4,1,28,28]' \
> result-run-FP32-MarkAll.txt
选取FP16推理对比结果进行展示,如下: