Linux之进程知识点
一、什么是进程
进程是一个运行起来的程序。
问题思考:
❓ 思考:程序是文件吗?
是!都读到这一章了,这种问题都无需思考!文件在磁盘哈。
本章一开始讲的冯诺依曼,磁盘就是外设,和内存与 CPU 打交道,它们之间有数据交互。
你的程序最后要被 CPU 运行,所以要运行起来必须先从磁盘外设加载到内存中。因此,当可执行文件被加载到内存中时,该程序就成为了一个进程。
操作系统里面可能同时存在大量的进程!
既然如此,那操作系统要不要将所以后的进程管理起来呢?
当然要,不要不就乱套了?当前想调用哪个进程,想让哪个进程占用 CPU 资源,
想执行哪个资源,数据一大你不管怎么行?所以我们刚才再次讲解了操作系统管理的概念:
被管理对象的管理本质上是对数据的管理。那么对进程的管理,本质上就是对进程数据的管理。
二、进程控制块(PCB)
/* Process Ctrl Block */
struct task_struct {
进程的所有属性数据
};
在操作系统中,我们把描述进程的结构体称为 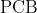 (Process Ctrl Block) 。
(Process Ctrl Block) 。
在很多教材中,会把 称为 进程控制块。
❓ 为什么每个进程都要有呢 (task_struct)?
因为操作系统要管理我们的进程,想要管理就必须要 "先描述再组织" 。
❓ 为什么我们的 task_struct 每个进程都要有呢?
因为这是为了管理进程而描述进程所设计的结构体类型,将来当有一个进程加载到内存时, 操作系统在内核中一定要为该进程创建 task_struct 结构体变量, 并且要将该变量链入到全局的链表当中。要删掉一个进程,实际上就是遍历所有的链表结点, 把对应进程的和代码都释放掉,这就叫对链表做管理。 最终你会发现,操作系统对进程的管理,最终变成了对链表的增删查改。什么是进程?目前为止我们可以总结成:进程 = 可执行程序 + 该进程对应的内核数据结构 task_struct 是一个非常大的结构体:
struct task_struct {
volatile long state;
void *stack;
atomic_t usage;
unsigned int flags;
unsigned int ptrace;
unsigned long ptrace_message;
siginfo_t *last_siginfo;
int lock_depth;
#ifdef CONFIG_SMP
#ifdef __ARCH_WANT_UNLOCKED_CTXSW
int oncpu;
#endif
#endif
...
}
三、进程查看
我们先创建一个 mytest.c 文件,然后写上一个死循环,每隔1秒就打印一句话:

通过指令查看进程
任何一个进程都有自己的代码和数据,比如我们常见的 C语言 源文件,经过编译后生成的可执行程序中,就包含着二进制代码和其创建修改的时间、所处位置信息

当可执行程序 myprogress 运行时,各种数据就会被描述,生成相应的进程控制块。
可以用ps ajx指令来查看进程块包含的信息
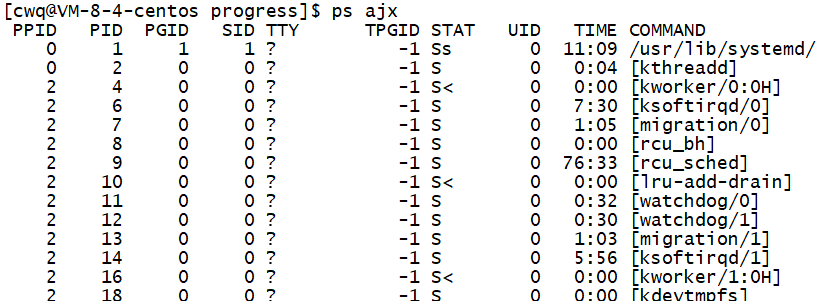
Linux中的PCB是task_struct,程序会被描述生成相应的 task_struct装载至内存中。
用命令ps ajx | head-1可以查看第一行的信息。
![]()
用管道组合一下就可以通过指令来查看正在运行的进程信息:
$ ps ajx | head -1 && ps ajx | grep 进程名 | grep -v grep

grep -v grep命令的意思是过滤掉自身的这一条命令。
我们可以通过函数来主动查看进程的PID。
获取pid的函数——getpid()
#include#include //Linux中睡眠函数的头文件 #include int main() { int sec = 0; while(1) { printf("这是一个进程,已经运行了%d秒 当前进程的PID为:%zu\n", sec, getpid()); sleep(1); //单位是秒,睡眠一秒 sec++; } return 0; }


可以看出他们的PID是一样的。
注: 当程序重新运行后,会生成新的 PID
因为查看进程的指令太长了,所以我们可以结合前面学的自动化构建工具 make ,编写一个 Makefile 文件,文件内容如下所示:

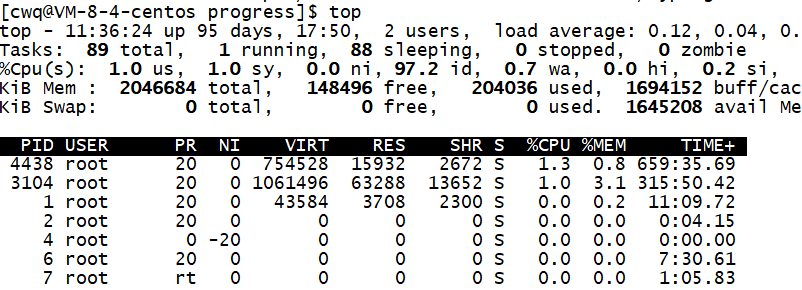
top指令
top
这个指令之前有介绍过,相当于Windows中的 ctrl+alt+del 调出任务管理器一样,top 指令能直接调起 Linux 中的任务管理器,显然,任务管理器中包含有进程相关信息
通过proc目录查看进程信息
$ /proc/

这些数字所代表的就是PID。
杀进程
我们再来回忆一下我们是如何杀掉一个进程的…… 
这是我们之前讲的,在 Linux 命令行中的热键,遇到问题解决不了可以用它来中止。
所谓的 就是用来杀进程的。除此之外,你也可以选择在另一个终端中使用 kill 命令:
$ kill -9 [pid] # 给这个进程发送9号信号
当前你只需要知道可以通过 kill -9 命令杀掉进程就行了,至于这个 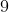 号信号,我们会放在后面的信号章节去讲!
号信号,我们会放在后面的信号章节去讲!
比如我们现在想杀掉刚才运行的, 打出进程  的 mytest 进程,其 为 22160:
的 mytest 进程,其 为 22160:
![]()
父进程
进程间存在 父子关系
比如在当前 bash 分支下运行程序,那么程序的 父进程 就是当前 bash 分支
其中,PID 是当前进程的ID,PPID 就是当前进程所属 父进程 的ID 我们一样可以通过函数来查看 父进程 的ID值
//函数:获取当前进程PPID值 #include#include pid_t getppid(void); //用法跟上面的函数完全一样

使用fork()创建子进程
写上如下代码:
#include#include #include int main(void) { pid_t id = fork(); printf("Hello, World!\n"); sleep(1); }
运行后发现

❓ 思考:
-
同一个 id 值,使用打印,没有修改,却打印出来了不同的值?为什么?这合理吗?
-
fork 如何做到会有不同的返回值?
再看看如下代码
#include#include #include int main(void) { pid_t id = fork(); /* id: 0 子进程, >0 父进程 */ if (id == 0) { // child while (1) { printf("我是子进程,我的pid: %d,我的父进程是 %d\n", getpid(), getppid()); sleep(1); } } else { // parent while (1) { printf("我是父进程,我的pid: %d,我的父进程是 %d\n", getpid(), getppid()); sleep(1); } } }
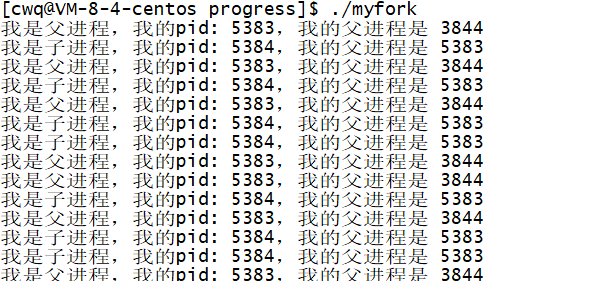
我们发现,这两块代码是可以同时执行的。
原因:fork 之后,父进程和子进程会共享代码,一般都会执行后续的代码。这也是为什么刚才的 printf 会打印两次的原因。fork 之后,父进程和子进程返回值不同,所以可以通过不同的返回值去判断,让父子执行不同的代码块。
fork函数工作原理:
fork 创建子进程时,会新建一个属于 子进程 的 PCB ,然后把 父进程 PCB 的大部分数据拷贝过来使用,两者共享一份代码和数据 各进程间是相互独立的,包括父子进程。 这句话的含义是当我们销毁父进程 后,它所创建的子进程并不会跟着被销毁,而是变成一个 孤儿进程。
最后,return 是代码吗?是的!所以当我们走到 return 时父进程有了,子进程也已经在运行队列了,fork 后代码共享,父子进程当然会执行后续被共享的 return 代码。因此,父进程执行一次 return,子进程执行一次 return,最后就是两个返回值了。