【C++项目】高并发内存池
前言:
本篇博客大致记录基于tcmalloc实现高并发内存池的思想与实现方案。
使用语言:C++,编译器:vs2022,开始时间:2023/4/3,结束时间:2023/4/12。
项目源码地址:C++project: 我的C++项目仓库 - Gitee.com
目录
总体思路:
三层模型设计
SizeClass-内存分配
1、申请流程
ThreadCache-申请流程
1.保证ThreadCache各线程的独立性
2.自由链表&具体的申请流程
3.思维导图表示ThreadCache申请流程
CentralCache-申请流程
1.CentralCache相关结构
Span内存跨度
2.从span获取内存和申请span进行切分内存
SizeClass-通过类型大小计算申请内存个数上限和申请span的页数
3.思维导图表示CentralCache申请流程
PageCache-申请流程
1.PageCache相关结构
2.申请span
3.思维导图表示PageCache申请流程
2、释放流程
ThreadCache释放流程
CentralCache释放流程
PageCache释放流程
3、性能优化
DefiniteLengthMemoryPool-定长内存池
32位下一层基数树的优化
总体思路:
背景:
首先需要了解池化技术。好比以前在农村家里的水缸:每次有水首先先把水缸给打满,提升用水的效率。提升用水的效率?1.每次用水不需要老远的去开启水管操作2.能够一次大批量的进行申请水......
池化技术正是这样,我们在计算机中提前向操作系统申请一批资源,然后我们自己管理并且分配资源,就能够提高资源的利用率以及效率。(一般频繁的向操作系统申请资源是很浪费效率的)
在C/C++中,malloc就是一个由语言管理的内存池。它先预先申请一批内存,然后按照用户的需求进行发放。对于内存池来说,除了解决效率之外,还需要解决的是内存的碎片问题。
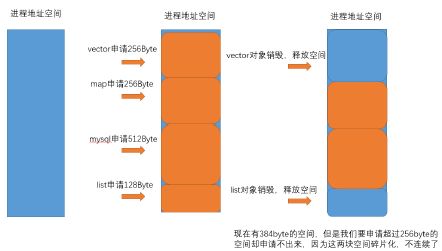
内存碎片问题。
比如如果同时向操作系统申请了4块大的内存,还回来的时候只是还回来了2块,那么此时连续的空间大小就被严重缩减了,也就是说如果我们再次申请大的空间的话,虽然剩余空间够,但是却不是连续的,导致空间利用率低,这就是外碎片问题。
除了外碎片问题,还存在内碎片问题。内碎片针对于申请小块内存由于对齐造成的小块内存的浪费。
内存池也需要对碎片问题进行处理。
但是,对于malloc来说,由于其的泛用场景,从而导致其在某些特定的场景下效率低下的问题,比如高并发场景下。所以正因为如此,我们才有此项目的诞生,优化在高并发的场景下内存池效率问题。
此高并发内存池项目基于GOOGLE开源项目tcmalloc实现,源码地址:tcmalloc。
因为需要完全摆脱malloc申请(C++的new底层也是调用的malloc),在后续实现高并发内存池的时候需要管理以及申请相关属性的空间,我们首先自己设计一个针对于单类型大小的内存池,也就是定长内存池,它的大致思路就是针对一种特定的类型,向系统申请大块内存,切成对齐大小(>=指针大小)的一块一块自由链表节点,然后将其挂起,申请的时候直接头删,回收的时候直接头插,由于是定长不需要考虑内存碎片问题。
三层模型设计
针对于当今的编程环境下,大多数都是高并发的场景(多线程)。正如我们上面所言,malloc是针对全部场景设计的,自然不会偏重于某一方面。但是现在高并发场景下我们又急需效率,此时针对于高并发场景下申请内存的tcmalloc就出来了。
基于tcmalloc的思想,我们设计的高并发内存池的话就必须考虑如下的三个问题:
1.性能问题。
2.多线程环境下的线程安全。
3.内存碎片的问题。
所以,既然是高并发环境下,那么我们如果能让每个线程都能有一个自己的内存池,然后汇总在后面的内存池中,从而大大减少锁竞争的出现,这样不就提高效率了嘛。
基于tcmalloc,于是我们有了下面的三层模型:
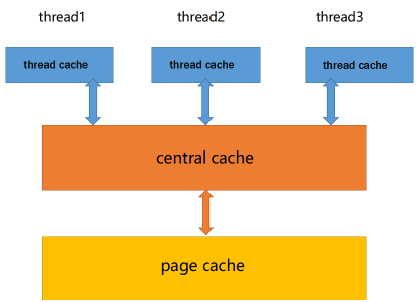
1.thread cache:
线程缓存是每个线程独有的,用于小于256KB的内存的分配,线程从这里申请内存不需要加锁,每个线程独享一个cache,这也就是这个并发线程池高效的地方。
2.central cache:中心缓存是所有线程所共享,thread cache是按需从central cache中获取的对象。central cache合适的时机回收thread cache中的对象,避免一个线程占用了太多的内存,而其他线程的内存吃紧,达到内存分配在多个线程中更均衡的按需调度的目的。central cache是存在竞争的,所以从这里取内存对象是需要加锁,首先这里用的是桶锁,其次只有thread cache的没有内存对象时才会找central cache,所以这里竞争不会很激烈。
3. page cache:页缓存是在central cache缓存上面的一层缓存,存储的内存是以页为单位存储及分配的,central cache没有内存对象时,从page cache分配出一定数量的page,并切割成定长大小的小块内存,分配给central cache。当一个span的几个跨度页的对象都回收以后,page cache会回收central cache满足条件的span对象,并且合并相邻的页,组成更大的页,缓解内存碎片的问题。
根据上述的描述,需要注意如下的几点:
1.可以看到我们申请的内存如果是小于256kb走三层模型,而大于256kb的话是不会走三层模型的。
2.1page页的单位我们定义为8kb。当然可以随时自定义调整。
SizeClass-内存分配
当我们申请的内存小于256kb的时候,那么我们如何保存每个类型的内存块呢?因为类型大小不同的差别很多,比如int4byte、short2byte、double8byte。
首先,我们肯定得保证内存大小大于等于一个指针的大小。(这样才能链接自由链表,将内存块链接起来)这个时候自然需要内存向上对齐的要求。(如果没有内存对齐的需求的话,难不成保存256*1024种内存块?)
需要注意,我们首先是向ThreadCache申请内存的,释放的时候也是先经过这里。那么我们对应的缓存区内存池应给每个内存对齐的内存大小分配一定的内存,方便对应大小进行取走或者释放。那么如何分配内存对齐规则是个关键,还要兼顾内碎片的问题。假设每个都是8字节对齐的话,还是256/8=32*1024种,还是很多,所以我们需要一种合理的方案分配内存大小。
基于tcmalloc,可以设计出如下的映射规则:
| 申请字节范围 | 对齐字节数 | 哈希桶编号 |
|---|---|---|
| [1, 128] | 8 | [0, 15] |
| [129, 1024] | 16 | [16, 71] |
| [1025, 8*1024] | 128 | [72, 127] |
| [8*1024+1, 64*1024] | 1024 | [128, 183] |
| [64*1024+1, 256*1024] | 8*1024 | [184, 207] |
根据如上的内存控制,我们的内存种类实际一共就208种,并且上述控制可以有效的将内碎片控制在10%左右-也就是内存浪费。
比如我们申请129byte,那么此时浪费的内存为(下次对齐的是144byte):144-129=15。所以将浪费的内存比上申请的内存占比就为浪费的内存占比:15/144就约等于0.10417。就是10%左右了。如果继续往大了的去申请,分母变大,分子最多才15,自然浪费的更少了。
1、申请流程
如果申请内存小于256kb,首先走ThreadCache、CentralCache、PageCache三层模型进行申请。如果大于256kb(也就是256/8=32page)直接走PageCache模型,具体请看各个缓存进行介绍。
ThreadCache-申请流程
1.保证ThreadCache各线程的独立性
在高并发环境下,既然是每个执行流先找到的ThreadCache,那么我们就需要保证ThreadCache缓存在每个线程用来是独自的一份,而不是共享的。
实际上,我们描述ThreadCache后,它就是一个类型,类型向我们自定义的定长内存池申请后就是一个变量。TLS线程局部存储原理能够帮助我们解决这个问题。
它能够让我们的一个看似处于临界区的变量,但是每个执行流进行申请内存后都是独立的存在。
static __declspec(thread) ThreadCache* TLSThradObj = nullptr;
这样我们就能保证,每一个线程都是自己独立的一份ThreadCache缓存了。
2.自由链表&具体的申请流程
根据类型大小,我们需要一个哈希桶对之前SizeCalss分配的各个进行存储自由链表。自由链表可以写一个类,和SizeClass共同放在一个共享类中,给各个文件提供共享。
注意,此自由链表目前提供头插、头删、以及慢启动策略。
申请内存的时候,如果计算出对于大小指向的哈希桶的自由链表没有内存块,我们就向上一层进行申请。上一层根据我们想要的批量个数(如果申请内存的话肯定申请一批效率高)-根据慢启动策略(增加内存块的利用率),获取一个期望个数的自由链表(可能上层某些内存块没多少可以分配的了),将头返回,剩余的插入对应哈希桶的自由链表中去。
当然,如果存在就直接头删返回了。由于ThreadCache是每个线程独有的,所以在这个过程中不存在线程安全问题。
具体各个函数以及相关流程如下:
3.思维导图表示ThreadCache申请流程
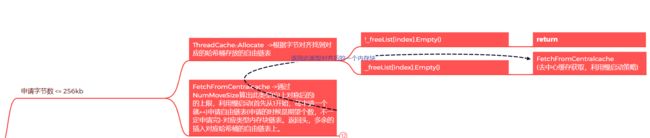
CentralCache-申请流程
1.CentralCache相关结构
因为每个执行流的ThreadCache的自由链表都由CentralCache进行分配,为了匹配,我们应该在结构上实现和ThreadCache同等的哈希桶关系(通过对方的类型大小,算出对齐大小和映射的桶号(当然也是小于256kb的))。
但是,为了更好的管理每个类型对应的自由链表以及配合上层的分配与合并,我们实现出一个结构span-跨度来存储每个类型对应的空间,以此分配自由链表以及管理回收(先描述在组织)。
Span内存跨度
span因为存在多个文件使用,所以也是统一定义在Common文件下。span的描述如下:
| 字段 | 名称 | 描述 |
|---|---|---|
| size_t _pageNum; | 页号 | 因为内存均是按页向系统申请,那么不用地址表示申请的一段空间,使用地址除以页的大小就可以表示一段空间的起始页号。 |
| size_t _n; | 页数 | 表示申请了多少页。此段内存最后的页号=_pageNum + _n - 1。 |
| size_t _objNum; | 类型大小 | 表示当前申请的span主要用于什么类型大小的使用中(被申请到CentralCache中后需要对特定的类型进行分配自由链表-如何分配根据SizeClss提供的算法) |
| Span* _pre; | 前指针 | 维护这些span使用双链表维护,前指针是不可或缺的元素。 |
| Span* _next; | 后指针 | 同上。 |
| size_t _useCount; | 当前类型内存块使用个数 | 当分配到centralCache之后,每分出去一段自由链表统计个数,回收一段也统计个数。当检测的时候=0表示全部还回来了可以进行回收。 |
| void* _freeList; | 此内存块存放可用自由链表处 | 根据起始地址根据对应类型大小切分为一块一块的自由链表以便提供给ThreadCache。 |
| bool _isUse; | 是否被用户使用中 | 用于合并的时候辨别缓存中的span是被PageCache分出去的还是没有被分出去的。(被分出去的就无法进行合并) |
使用此Span就可以管理自由链表并且方便上层解决外碎片问题。并且使用SpanList带头双向循环链表管理起来,放置在CentralCache中跟对应的各个对齐内存大小的哈希桶对应起来。
有了结构可以管理内存了,但是需要注意在高并发环境下,可能存在线程安全问题。这里线程安全就是指对同一块span的申请或者释放。注意是同一块,也就是同一映射的地方,所以我们可以使用桶锁解决(不必使用一整把大锁解决,效率低下)。可以在SpanList实现的结构中实现。
另外,在一个进程内,此CentralCache应该只能存在一个,所以使用设计模式中的单例模式-饿汉模式解决。
2.从span获取内存和申请span进行切分内存
当ThreadCache向CentralCache申请内存的时候,根据它慢启动的策略,申请类型大小,申请个数。CentralCache会根据SizeClass计算出的哈希桶桶号映射到相应位置,如果有span,根据其参数_freeList进行切分对应个数(如果没有对应那么多个就全部分出去,有多少分多少个)(这也是期望个数的由来)。
但是,当span没有,我们就需要向上一层获取span。那么如何根据该申请类型大小申请多少页的span呢?我们需要SizeClass增加通过类型获取大小的算法。
SizeClass-通过类型大小计算申请内存个数上限和申请span的页数
首先是在ThreadCache涉及的申请个数上限。我们利用三层结构最大byte:256 * 1024byte除以其对齐类型大小就可以算出大概有多个可以申请的了。但是,有些可能过于小(比如申请大内存的时候),有些可能过于大(申请小内存的时候),针对过小和过大做出规范:最多申请512个,最少申请2个。
申请对应类型的span的页数首先就需要计算上限,上限计算后就可以*其类型大小算出申请上限的总byte大小。总的byte大小除以page的大小就可以算出申请多少页了。当然,对于小的内存,最多申请512个,自然不足页的大小,所以最小页数就是1了。
我们就可以通过计算出的页的个数向PageCache层申请span。此时申请的span是一个全新的span,我们给其对于的分配_objNum,并且通过类型大小,将此段内存切分为自由链表,个数就是当前页全部分完,然后挂在_freeList上即可,分配给ThreadCache期望个数个完毕。
3.思维导图表示CentralCache申请流程
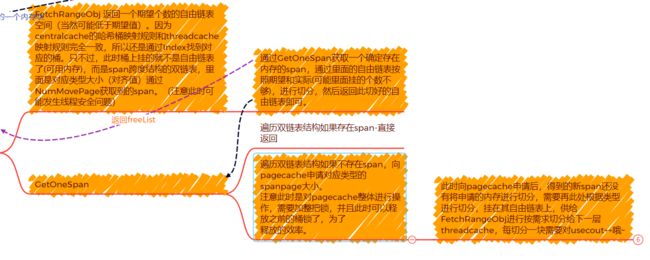
PageCache-申请流程
1.PageCache相关结构
PageCache是创造span的地方。首先自然不能和CentralCache和ThreadCache那样,以256kb一下的内存划分进行映射,而是通过页号进行映射。
方便管理,我们以1MB为界限。1MB=1024*1024byte=128 * 8 * 1024 = 128page
所以,PageCache管理的哈希表就是从1到128page的span,同样的也是用SpanList进行管理。
同样的,因为CentralCache向PageCache申请Span的时候,存在线程安全问题,所以需要一把大互斥锁进行线程安全的维护(此时就不能用桶锁了,因为回收的时候动一处可能全体都要动-合并,所以只能动一把锁)。
因为回收内存的时候,我们需要通过对应的地址找到我们的span。这个时候就需要构建一个key-value结构的数据结构。这里先使用map(或者哈希实现的map,后续会进行优化),那么当我们向外进行分配span的时候,需要将此span的每一个页号均进行映射到同一个span(因为来源都是一个span,分出去的时候由于是多页,我们需要计算的时候映射到同一个span上而不只是找到首个页号从而导致找不到span)。并且我们也需要对存放在此哈希桶的span也要进行映射(只需要首和尾即可,方便后续合并)。
2.申请span
由于PageCache设置的最大页号为128page,如果我们申请的内存超过1MB,那么就需要分为两种情况。
-直接向操作系统申请内存
如果大于128page,那么原本的page哈希桶就没有用了,并且此span也不会参与合并的过程中(释放也需要直接找操作系统释放)
我们直接向操作系统申请对应页大小的内存,将返回的起始地址号转化为页号,构成一个span进行返回即可。注意也需要映射(只需要映射头即可 - 还回来也是一整块,好通过地址找回此span)。
-哈希桶向下查询申请内存
如果小于等于128page,我们走正常的流程。
首先通过直接定址法找到对应的哈希桶,查看当前双链表是否存在span。存在返回,并且设为使用状态。
如果不存在,那么我们可以向下找(向下找可以找到页数更大的span,此时进行切分即可),如果找不到,那么我们在向操作系统申请128page的页,进行切分,将需要的span返回,剩余的span挂到对应哈希桶上即可。注意别忘了映射。
3.思维导图表示PageCache申请流程


2、释放流程
释放流程的时候,给的是一个地址,我们首先通过地址根据之前在PageCache映射的span找到其span,根据span中的objNum类型大小进行操作,如果小于256kb,我们走三层的释放流程,否则直接走PageCache的释放流程。
ThreadCache释放流程
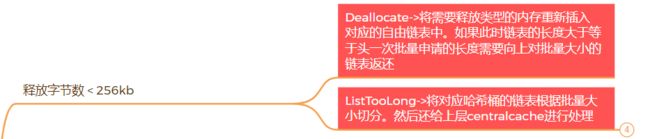
释放非常简单,所谓的释放不过就是将申请的内存还回来即可,将对应的地址根据内存大小找到映射的哈希桶,插入进自由链表即可。
当然,如果此时自由链表中结点的个数大于等于我们下一次此类型申请的期望大小的话,说明我们可以将此段自由链表进行回收了,将此段自由链表从对应的哈希桶上删除,返回给上一层CentralCache。(向上提供这段自由链表和类型大小,方便进行映射找到对应位置)
如下思维导图所示:
CentralCache释放流程
根据ThreadCache传回的类型大小和对应的自由链表,找到对应位置后,首先进行互斥锁加锁(此时对特定接口操作了,防止线程安全问题上桶锁)。
我们此时虽然找到了位置,但是很有可能此位置插入了很多同类型的span,所以,我们要通过遍历自由链表,通过PageCahe中的映射关系找到每一个span,然后对这写span维护的_freeList进行一个插入即可。
注意每插入一个,此span维护的_useCount就需要减少一个,当减少为0的时候,我们就需要将此span回收给上层的pageCache。(注意帮PageCache加锁,当加Page锁的时候我们可以先将桶锁释放,等回收完毕在申请回来)
思维导图如下:
PageCache释放流程
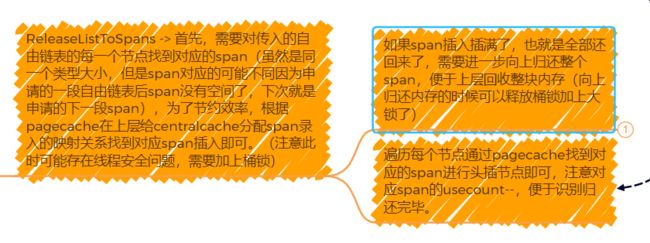
因为PageCache在之前的申请流程中分成了两类申请span,所以释放的时候也是需要两类。
如果此时返回的span的页数大于128page,我们直接交给操作系统释放即可,也不需要进行存储,和哈希桶没有任何的关系。
当小于等于128page的时候,我们是直接插入对应页号的哈希桶吗?不要忘记了,我们设计内存池的另一个目的就是为了解决内外碎片问题。内碎片我们通过SizeClass优化到了只浪费10%,外碎片我们通过内存合并就能解决。
所以基于当前的span,如果往页数低的去的话,每次-1即可,查看其映射的span是否存在,切和此span的页的个数相加不超过128page,并且不被使用中,不满足上述三种条件就进行合并,设置页号为当前找到的页号(跟新初始地址),否则break,循环到找不到即可。同理,向页数高的去的话,每次+当前span的页的个数即可,如果满足合并的条件就更新即可。注意合并后需要将合并找到的那个span先从对应的哈希桶SpanList删除掉。
合并成新的大块span后插入对应哈希桶中,并且添加映射(没有被用户使用直插入头和尾哦~方便下次合并)
思维导图如下:

3、性能优化
将我们的高并发内存池设计完后,可以通过下面的验证代码验证我们的内存池和malloc的效率:
#include "ConcurrentPool.hpp"
#include
using std::cout;
using std::endl;
using std::cin;
// ntimes 一轮申请和释放内存的次数
// rounds 轮次
// nworks 多少个线程进行并发执行
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)
{
std::vector vthread(nworks);
std::atomic malloc_costtime = 0;
std::atomic free_costtime = 0;
for (size_t k = 0; k < nworks; ++k)
{
vthread[k] = std::thread([&, k]() {
std::vector v;
v.reserve(ntimes);
for (size_t j = 0; j < rounds; ++j)
{
size_t begin1 = clock();
for (size_t i = 0; i < ntimes; i++)
{
//v.push_back(malloc(16));
v.push_back(malloc((16 + i) % 8192 + 1));
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < ntimes; i++)
{
free(v[i]);
}
size_t end2 = clock();
v.clear();
malloc_costtime += (end1 - begin1);
free_costtime += (end2 - begin2);
}
});
}
for (auto& t : vthread)
{
t.join();
}
printf("%zu个线程并发执行%zu轮次,每轮次malloc %zu次: 花费:%zu ms\n",
nworks, rounds, ntimes, malloc_costtime.load());
printf("%zu个线程并发执行%u轮次,每轮次free %zu次: 花费:%zu ms\n",
nworks, rounds, ntimes, free_costtime.load());
printf("%zu个线程并发malloc&free %zu次,总计花费:%zu ms\n",
nworks, nworks * rounds * ntimes, malloc_costtime.load() + free_costtime.load());
}
// 单轮次申请释放次数 线程数 轮次
void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{
std::vector vthread(nworks);
std::atomic malloc_costtime = 0;
std::atomic free_costtime = 0;
for (size_t k = 0; k < nworks; ++k)
{
vthread[k] = std::thread([&]() {
std::vector v;
v.reserve(ntimes);
for (size_t j = 0; j < rounds; ++j)
{
size_t begin1 = clock();
for (size_t i = 0; i < ntimes; i++)
{
//v.push_back(QiHai::ConcurrentAlloc(16));
v.push_back(QiHai::ConcurrentAlloc((16 + i) % 8192 + 1));
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < ntimes; i++)
{
QiHai::ConcurrentFree(v[i]);
}
size_t end2 = clock();
v.clear();
malloc_costtime += (end1 - begin1);
free_costtime += (end2 - begin2);
}
});
}
for (auto& t : vthread)
{
t.join();
}
printf("%zu个线程并发执行%zu轮次,每轮次ConcurrentAlloc %zu次: 花费:%zu ms\n",
nworks, rounds, ntimes, malloc_costtime.load());
printf("%zu个线程并发执行%u轮次,每轮次ConcurrentFree %zu次: 花费:%zu ms\n",
nworks, rounds, ntimes, free_costtime.load());
printf("%zu个线程并发ConcurrentAlloc&ConcurrentFree %zu次,总计花费:%zu ms\n",
nworks, nworks * rounds * ntimes, malloc_costtime.load() + free_costtime.load());
}
int main()
{
size_t n = 10000, nworks = 1, rounds = 1;
cout << "测试高并发环境下malloc和简单模拟tcmalloc的效率问题" << endl;
cout << "输入一共需要几个线程:";
cin >> nworks;
cout << "执行几轮:";
cin >> rounds;
cout << "每轮申请释放次数:";
cin >> n;
// 4 10 1000
cout << "==========================================================" << endl;
BenchmarkConcurrentMalloc(n, nworks, rounds);
cout << endl << endl;
BenchmarkMalloc(n, nworks, rounds);
cout << "==========================================================" << endl;
return 0;
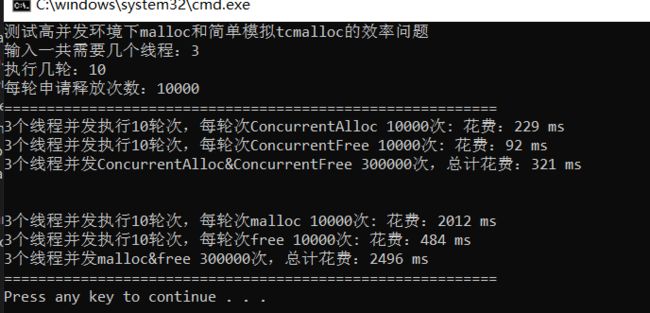
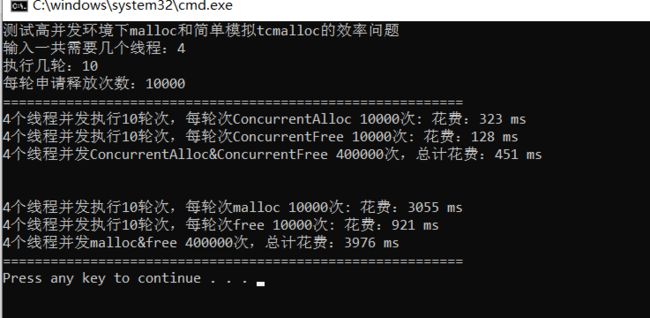
} 可以发现虽然可以运行,但是效率还是比malloc低下,这是为什么?
首先,我们之前用的是STL库为我们提供的map进行key-value映射的。 并且,每次在进行释放内存的时候,或者获取一个映射的时候都要进行锁维护线程安全的(因为STL的map结构插入都结构发生变化),而效率的消耗大部分就是锁的功劳。
所以我们想要继续对我们的代码进行优化就要减少对锁的申请。减少锁的申请我们可以从key-value入手,我们不妨设计一个读和写都对此结构不影响的结构,这样不久减少了大量的锁申请的了嘛。
基数树就是应对方法。
基数树通过非类型参数指定需要存储的个数,开辟对应的空间(一层模型),这样每个key-value就不会收到其他的影响,并且在读取的时候不可能出现写入(读取了,别的执行流一定是申请的另外的)。这个时候我们查找地址映射span的时候就可以去掉锁的保护,效率提高。效率提高后,在多进程并发的条件下大概高出malloc五~十倍左右。
DefiniteLengthMemoryPool-定长内存池
首先确定windows下向系统申请的函数:VirtualAlloc_百度百科 (baidu.com)
根据接口,我们想设计成向系统申请大块内存的时候以1page(8kb)为单位的内存,根据API的介绍,函数应该写为:
VirtualAlloc(NULL, size << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);lpAddress:分配内存区域的地址。这里分配为空,让操作系统自己决定分配内存区域的位置,并且按64-KB向上取整(roundup)。
dwSize:申请空间的字节大小。由于单位是字节,size是页的个数,所以我们首先计算出其字节大小。
Type:分配的类型。MEM_COMMIT:为指定地址空间提交物理内存。MEM_RESERVE:
保留指定地址空间,不分配物理内存。这样可以阻止其他内存分配函数malloc和LocalAlloc等再使用已保留的内存范围,直到它被被释放。
flProtect:指定了被分配区域的访问保护方式。PAGE_READWRITE:区域不可执行代码,应用程序可以读写该区域。
首先自然是一个模板类。第一次或者管理的内存完的时候通过VirtualAlloc申请1page内存。
每次申请下内存的时候,就根据对应的类型(需要大于指针大小,小于的话就分配指针大小 - 用于存储地址从而管理自由链表)进行切分一块出去。
用一个指针,用于管理回收的内存,从而组成一个自由链表。每次回收的时候,强转类型存储当前指针指向的此链表头节点即可。那么在申请的内存的时候,只需要检查自由链表是否存在结点,存在直接头删即可,否则查看申请的内存块还有内存不,没有向系统申请,在一块一块的分出去。

32位下一层基数树的优化
由于32位的进程地址空间大小位2^32次方byte,除以页的大小就是2^32 / 2 ^ 13(8kb) = 2 ^ 19次方个,所以我们32位下可以一次性开2^19次方个存key-value的关系,由于是存span* ,32位下指针的大小位4byte,所以总大小位2^19 * 2 ^ 2 = 2 ^ 21byte = 2mb左右,是可以进行一层存储的。
操作的代码如下:
#include "Common.hpp"
// Single-level array
// BITS为非类型模板参数 表示需要存多少个的基数树 -以2为底,bits位数的个数
// 注意,一层模型只适用于32位
template
class TCMalloc_PageMap1 {
private:
static const int LENGTH = 1 << BITS; // 算出总长度,32位下为2^19个 (2^32byte / 2^13byte = 2^19个)
void** _array;
public:
typedef uintptr_t Number;
//explicit TCMalloc_PageMap1(void* (*allocator)(size_t)) {
explicit TCMalloc_PageMap1() {
//array_ = reinterpret_cast((*allocator)(sizeof(void*) << BITS));
size_t size = sizeof(void*) << BITS; // 算出存2^bites 个地址所需要的byte
size_t alignSize = QiHai::SizeClass::_RoundUp(size, 1 << QiHai::SHIFT_PAGE); // 算出对齐数进行申请
_array = (void**)QiHai::SystemAlloc(alignSize >> QiHai::SHIFT_PAGE); // 计算出大概申请多少页
memset(_array, 0, sizeof(void*) << BITS); // 初始化为0
}
// Return the current value for KEY. Returns NULL if not yet set,
// or if k is out of range.
void* get(Number k) const {
if ((k >> BITS) > 0) {
return nullptr;
}
return _array[k];
}
// REQUIRES "k" is in range "[0,2^BITS-1]".
// REQUIRES "k" has been ensured before.
//
// Sets the value 'v' for key 'k'.
void set(Number k, void* v) {
_array[k] = v;
}
};
// 基数树优化的作用:
// 由于使用STL的哈希的话,需要频繁的加锁(在实际调用中发现锁消耗的性能最大),这样在进行查找页号对应的span的时候,每一块是独立起来的。并且当一个线程申请到
// 一块内存,此页号就固定了,没还回去之前,都一直属于当前执行流,所以以此可以优化性能
// 上面只是一层基数树,对于32位可以使用2层基数树,但是如果是64位程序的话,就需要3层基数树了,扩展内容。