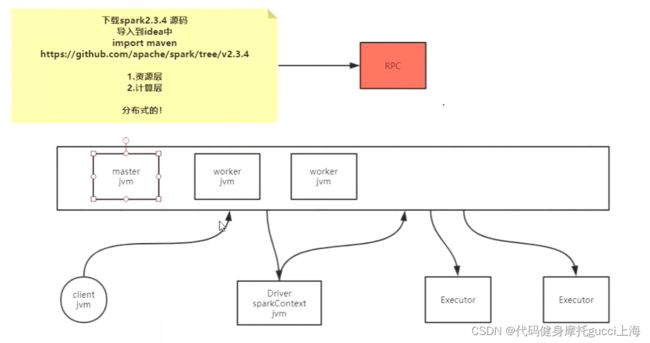
spark分布式计算框架
MapReduce是计算逻辑清晰的,只有两个步骤,任务是JVM进程级别,每执行到什么步骤 去申请具体的资源。
而spark根本不知道具体有几个stage,逻辑未知,每个人的job stage等根本不知道。它是默认倾向于抢占资源的,他会在sparkContext()这个函数执行的时候,直接根据下面textFile()代码逻辑抢占所有资源,任务以JVM线程的级别泡在Excutor里面
目前已知的: 每一个Excutor里面的就是一个job的stage,一个excutor跑在某一个节点,等需要shuffle的时候,另一个节点通过他的excutor把刚才的数据拿过来
Spark-Core源码解析:
首先 这些都是分布式计算框架,不同个体对象之间要使用RPC
!!!!!!!!!!!!!!!
Spark Master启动流程及源码详解_ustbxyls的博客-CSDN博客
1. RPC
下图为Master.scala里面 start-master.sh的具体流程
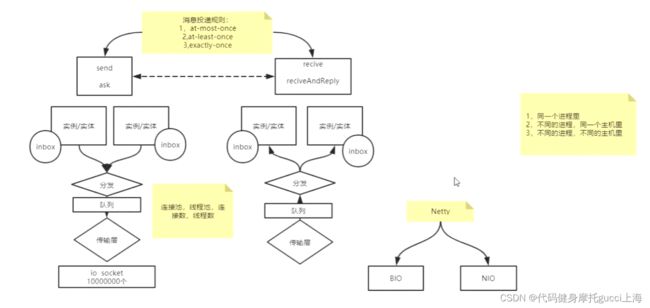
RPC也就是发送方与接收方通过传输层进行远程通信连接,来调用对方远程的服务。传输层里面最代表的就是Netty,他把各种IO进行了封装了只提供相应接口。
除此之外,不同主机可能会有多个进程进行传输,所以在通信时可以指定传输目标的IO,防止接收混乱。
分发 与 队列设置也是帮助多个实体进行传输。
内部的inbox是为了暂时存储,方便未来看给自己的哪个函数调用,他才是具体的处理东西的对象。
除此之外 ,还要设定消息投递规则,如接收不到就重发 或者 只发一次等
什么是 RPC 框架 - jiuchengi - 博客园
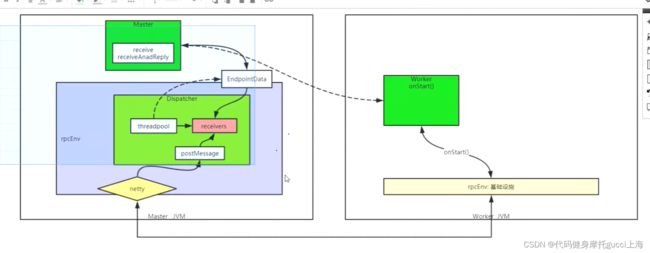
2. start-master首先要创建RpcEnv环境
一共分为两部分 Dispatcher(分发器)和传输服务(Netty)

Dispatcher 就是那个用来分发处理的 postMessage来生成data放入receive队列里面,threadpool线程池来使用死循环处理信息,根据信息具体内容实现不同 分发 操作
传输服务:
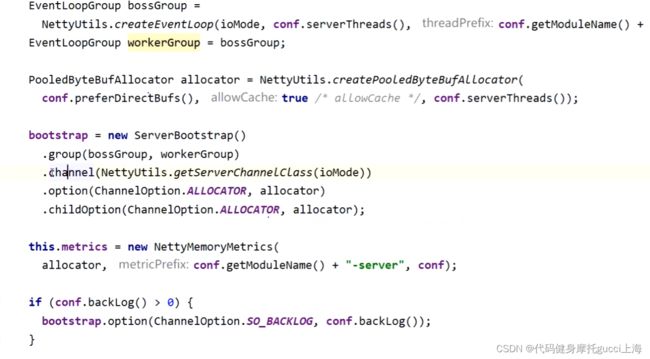
上图是spark-core Master.scala里 RpcEnv(就是包含了分发dispatcher 以及传输层Netty)里的源码 是传输服务这一部分(通过startServer开启),也就是具体的Netty实现
上面的Loop就是一个类似死循环,不能让线程频繁的创建消亡,只开通
下面bootstrap里面的channel可以直接实现接收读取数据或者发送数据,以往写java的时候必须要实现input类和output类,而这里一个channel就可以直接实现读写操作,具体实现在里面的Handler里面,Handler就是实现了区分读取和写数据,然后将数据使用RpcEnv里的postMessage保存起来(应该是对应于那个写进队列操作)。而这个postMessage就是DIspatcher里的方法
3.经过创建RpcEnv环境后(Dispatcher和传输层Netty等之后),开始注册Master信息。
在这个脚本里面,他只注册了Master这一个endpoint
最终结果就是利用rpcEnv创建EndPoint(Master)和 EndPointRef(Master的引用) 这个引用是Master的,但是如果对方主机获得了这个引用,就可以使用send方法给Master传信息(在未来的start-worker.sh脚本里面)
(在这个脚本里面 它的作用主要有两个:
(1)创建 Master对象, 该对象就是一个 RpcEndpoint, 在 RpcEnv 中注册这个 RpcEndpoint
(2)返回该 RpcEndpoint 的引用(master 的RpcEndpointRef))
首先Master就是继承于 EndPoint 里面重写了receive方法 这个是 大前提
方法中想创建的EndPoint(启动Master角色)返回的是一个引用EndPointRef,EndPoint有receive和receiveAndReplay方法用来接收引用传的数据(send方法和ask方法),根据引用传不同的数据 相应不同的方法(对应于不同的角色)
这里的EndPoint主要是针对不同角色和Master进行交涉的时候,比如Driver想申请资源,创建Master的引用传入message为Driver信息,一般来说一个EndPoint对应多个EndPointRef,

这种思想类似于接口 ref就是接口实现
在rpcenv里面注入master实体这个endpoint
并等待未来处理各类endpoint请求
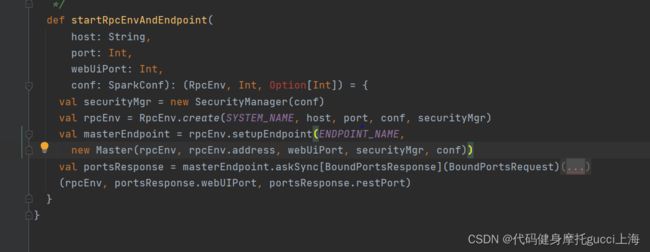
val masterEndpoint = rpcEnv.setupEndpoint(ENDPOINT_NAME, new Master(rpcEnv, rpcEnv.address, webUiPort, securityMgr, conf))
// name是endpoint的name endpoint这里是master
def registerRpcEndpoint(name: String, endpoint: RpcEndpoint): NettyRpcEndpointRef = {
val addr = RpcEndpointAddress(nettyEnv.address, name) //别台主机的名字但是放 master的地址
val endpointRef = new NettyRpcEndpointRef(nettyEnv.conf, addr, nettyEnv)
//endpointRef就存着另一台主机端点 他的端口号主机地址等
synchronized {
if (stopped) {
throw new IllegalStateException("RpcEnv has been stopped")
}
if (endpoints.putIfAbsent(name, new EndpointData(name, endpoint, endpointRef)) != null) {
throw new IllegalArgumentException(s"There is already an RpcEndpoint called $name")
}
val data = endpoints.get(name)
endpointRefs.put(data.endpoint, data.ref)
receivers.offer(data) // for the OnStart message
}
endpointRef
}里面会将各类主机信息注册到分发器Dispatcher,同时在填写分发器内部数据EndpointData时候,填的数据里面有个inbox来处理具体东西,他会先有个一个同步操作 即
inbox.synchronized {
messages.add(OnStart)
}
这个操作会将启动进程放入message未来的队列里面,未来多线程运行的时候,他就会先启动。标志着start-master的开始。(它是由初始化inbox的时候生成的,所以先于所有其他端点信息进入队列)
后续的队列处理才会处理那些天的endpoints
也就是
val masterEndpoint = rpcEnv.setupEndpoint(ENDPOINT_NAME, new Master(rpcEnv, rpcEnv.address, webUiPort, securityMgr, conf))
这一步 不仅注册了端点信息,还实现了startmaster,都是通过放入dispatcher处理队列里面实现的
start-worker.sh流程
同样的RPCEnv环境初始化,同样的注册自己这个worker信息,同样的inbox里面onStart()启动自己这个worker环境。
在启动之后 调用onStart()方法,里面会连接Master传递信息。首先是用Master的address和名字创建Master的引用(引用就是给别人调用的,别人用我的引用给我传消息)。然后发送自己要注册的信息
RegisterWorker( workerId, host, port, self, cores, memory, workerWebUiUrl, masterEndpoint.address))
Master的receive方法接收到之后,返回响应信息,Worker接收到之后,和Master不停的建立心跳连接。