【CVPR轻量级网络】- 追求更高的FLOPS(FasterNet)
文章目录
-
-
- 题目:
- 摘要
-
- 1 介绍
- CNN中FLOPs的计算
- 2 相关工作
- 3 PConv和FasterNet的设计
-
- 3.1 偏卷积作为基本算子(PConv)
- 3.2 PConv后接PWConv
- 3.3 FasterNet作为通用骨干
- 4实验
-
题目:
Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks
摘要
提出了一种新的部分卷积(PConv),通过同时减少冗余计算和内存访问,可以更有效地提取空间特征。FLOPs 的减少并不一定会导致类似水平的延迟减少。在ImageNet1k上,小型FasterNet-T0在GPU、CPU和ARM处理器上分别比MobileViT XXS快3.1倍、3.1倍和2.5倍,同时准确率高2.9%。我们的大型FasterNet-L实现了令人印象深刻的83.5%的顶级精度,与新兴的Swin-B不相上下,同时在GPU上的推理吞吐量(吞吐量大,就是指单位时间内成功地传送数据的数量大。)提高了49%,并在CPU上节省了42%的计算时间。
1 介绍
导致低FLOPS问题的主要原因是频繁的内存访问。提出了一种新的部分卷积(PConv)作为一种竞争性的替代方案,它减少了计算冗余和内存访问次数。PConv比常规Conv具有更低的FLOPs,而比DWConv/GConv具有更高的FLOPs,但是PConv可以更好地利用设备上的计算能力。
MobileViT和MobileFormer通过将DWConv与改进的注意力机制相结合来降低计算复杂度。但是DWConv会受到内存访问增加的副作用。MicroNet 进一步分解和稀疏网络,将其 FLOPs 推到极低的水平。 尽管它在 FLOPs 上有所改进,但这种方法经历了低效的碎片计算。
- 1)指出了实现更高FLOPS的重要性,而不仅仅是为了更快的神经网络而简单地减少FLOPs。
- 2)引入了一种简单但快速有效的PConv,它很有可能取代现有的首选DWConv。
- 3)推出了FasterNet,它在GPU、CPU和ARM处理器等各种设备上运行良好且普遍快速。
CNN中FLOPs的计算
FLOPS: 注意全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。(越大越好)
FLOPs: 注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。(越小越好)

![]()

2 相关工作
CNN,群卷积和深度可分离卷积(由深度卷积和逐点卷积组成)可能是最流行的卷积。它们已被广泛用于面向移动/边缘的网络,如MobileNets、ShuffleNets、GhostNet、EfficientNets、TinyNet、Xception、CondenseNet、TVConv、MnasNet和FBNet。
3 PConv和FasterNet的设计
虽然DWConv在减少FLOPs方面是有效的,但它通常后面跟着逐点卷积(PWConv),不能简单地用来取代常规的Conv,因为它会导致严重的精度下降。因此,在实践中,DWConv的信道数c(或网络宽度)增加到c0(c0>c),以补偿精度下降,例如,对于反相残差块中的DWConv,宽度扩展了六倍。然而,这会导致更高的内存访问,这可能会导致不可忽略的延迟并降低整体计算速度,尤其是对于I/O绑定设备。
3.1 偏卷积作为基本算子(PConv)
它只需在输入通道的一部分上应用正则Conv进行空间特征提取,而不影响其余通道。对于连续或规则的内存访问,我们认为第一个或最后一个连续的cp通道是整个特征图的代表,我们认为输入和输出特征图具有相同数量的通道。PConv的FLOPs仅为常规Conv的1/16

PConv具有较小的存储器访问量:



3.2 PConv后接PWConv
为了充分有效地利用来自所有通道的信息,进一步将逐点卷积(PWConv)附加到PConv。在输入特征图上的有效感受野看起来像一个T形Conv,与均匀处理补丁的常规Conv相比,它更关注中心位置。


为了证明这个T形感受野的合理性,首先通过计算位置上的Frobenius范数来评估每个位置的重要性。我们假设,如果一个位置的Frobenius范数比其他位置大,那么它往往更重要。我们认为一个显著位置是具有最大Frobenius范数的位置。然后,我们在预先训练的ResNet18中共同检查每个滤波器,找出它们的显著位置,并绘制显著位置的直方图。在滤波器中,中心位置是最频繁的显著位置。换句话说,中心位置的重量更大。

T形Conv的FLOPs可以计算为

3.3 FasterNet作为通用骨干

它有四个层次级,每个层次级之前都有一个嵌入层(一个步长为4的正则Conv 4×4)或一个合并层(步长为2的正则Conv 2×2),用于空间下采样和信道数扩展。每个阶段都有一堆FasterNet块,最后两个阶段的块消耗更少的内存访问,并且往往具有更高的FLOPS,如表1中的经验验证。因此,我们放置了更多的FasterNet块,并相应地将更多的计算分配给最后两个阶段。每个FasterNet块都有一个PConv层,后面是两个PWConv(或Conv 1×1)层。它们一起显示为反向残差块,其中中间层具有扩展数量的通道,并放置快捷连接以重用输入特征。归一化层和激活层对于高性能神经网络也是必不可少的,只将它们放在每个中间PWConv之后,以保持特征多样性并实现更低的延迟。BN的好处是可以将其合并到相邻的Conv层中,以实现更快的推理。选择GELU用于较小的FasterNet变体,ReLU用于较大的FasterNet变体。最后三层,即全局平均池、Conv 1×1和全连接层,一起用于特征转换和分类。
为了在不同的计算预算下为广泛的应用提供服务,我们提供了FasterNet的小型、小型、中型和大型变体,分别称为FasterNetT0/1/2、FasterNet-S、FasterNet-M和FasterNet-L。它们共享相似的架构,但在深度和宽度上有所不同。
4实验
Latency on GPU:模型推理和后处理的时间,时间越小,执行速度越快

消融实验:

1、对于部分比率r,我们默认为所有fastnet变体将其设置为 1 /4实现了更高的准确性、更高的吞吐量和更低的延迟。
2、对于归一化,选择BN而不是LN。因为BN可以合并到其相邻的卷积层中,从而更快地进行推断。
3、对于激活函数,GELU比ReLU更适合fastnet - t0 /T1模型。然而,fastnet-t2 /S/M/L则相反。
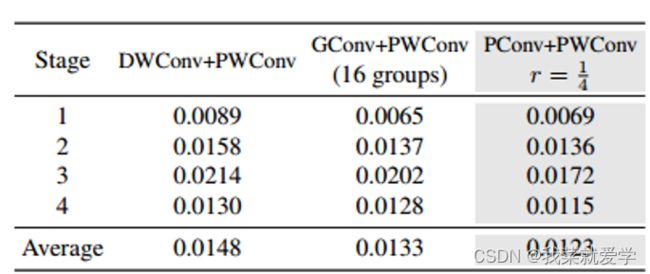
PConv + PWConv的测试损失最小,这意味着它们在特征变换中可以更好地逼近一个规则的Conv
为了进一步评估fastnet的泛化能力,在具有挑战性的COCO数据集上进行了对象检测和实例分割的实验。使用fastnet作为骨干,并配备流行的掩码R-CNN检测器
