DevOps系列文章 - K8S知识体系
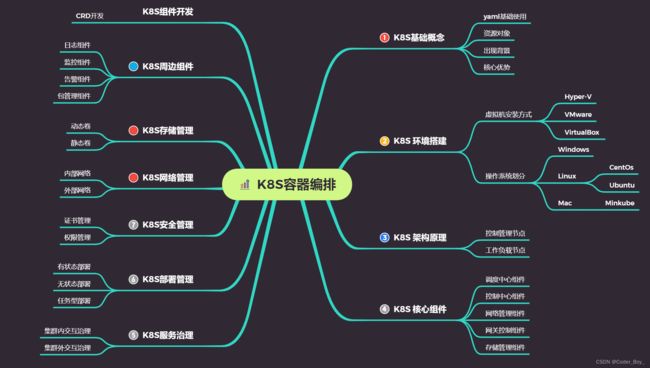
环境搭建部分:
1、安装前的准备工作
# 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
# 查看hostname并修改
hostname # 查看本机hostname
hostnamectl set-hostname k8s-master # 把本机名设置成k8s-master
hostnamectl status # 查看修改结果
echo "127.0.0.1 $(hostname)" >> /etc/hosts # 修改hosts文件
# 关闭selinux(linux的安全机制)
sed -i 's/enforcing/disabled/' /etc/selinux/config
setenforce 0
# 关闭swap(关闭内存交换)
swapoff -a
sed -ri 's/.*swap.*/#&/' '/etc/fstab'
free -m # 检查,确保swap里面没有东西
# 配置桥接流量
cat <2. docker安装
下载关于Docker的依赖环境
yum -y install yum-utils device-mapper-persistent-datalvm2
设置一下下载Docker镜像源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
安装Docker
下面这个命令是将软件包信息提前在本地缓存一份,用来提高搜索安装软件的速度
yum makecache fast
yum install docker-ce docker-ce-cli containerd.io
启动Docker服务
systemctl start docker
设置开机自动启动
systemctl enable docker
测试验证
docker run hello-world
3. 安装k8s
# 配置k8s的yum源
cat < /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpg_key=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
# 卸载旧版本
yum remove -y kubelet kubeadm kubectl
# 查看可以安装的版本
yum list kubelet --showduplicates | sort -r
# 安装kubernetes
yum install -y kubelet kubeadm kubectl
# 设置开机启动kubelet
systemctl enable kubelet
# 启动kubelet
systemctl start kubelet
# 查看kubelet状态
systemctl status kubelet # kubelet进入无限死循环状态 如果执行安装kubelet失败。可能是我阿里云的yum源配置有问题
4、配置master节点
# 查看kubeadm需要下载的镜像
kubeadm config images list
## 需要下载的镜像
k8s.gcr.io/kube-apiserver:v1.23.1
k8s.gcr.io/kube-controller-manager:v1.23.1
k8s.gcr.io/kube-scheduler:v1.23.1
k8s.gcr.io/kube-proxy:v1.23.1
k8s.gcr.io/pause:3.6
k8s.gcr.io/etcd:3.5.1-0
k8s.gcr.io/coredns/coredns:v1.8.6
# 挨个下载以上镜像,由于是国外镜像,使用阿里云镜像仓库下载
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.23.1
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.23.1
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.23.1
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.23.1
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.6
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.1-0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.8.6
# 因为coredns是带二级目录的,所以要多执行这一步
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.8.6 registry.cn-hangzhou.aliyuncs.com/google_containers/coredns/coredns:v1.8.6
# 创建k8s集群
# 查看eth0的inet私有网络地址,复制出来填入apiserver-advertise-address
ip a
# 初始化一个master节点
# image-respository 镜像仓库的地址
# service-cidr pod-network-cidr 设定两个子网范围,不能和apiserver冲突
kubeadm init \
--apiserver-advertise-address=172.31.43.126 \
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \
--kubernetes-version v1.23.1 \
--service-cidr=172.100.0.0/16 \
--pod-network-cidr=192.168.0.0/16 \
--ignore-preflight-errors=all- 如果:出现错误kubelet连接失败
- 解决方法:
-
sudo docker info|grep Cgroup # 查看docker的 Cgroup Driver,显示为cgroupfs,而kubelet为systemd vim /etc/docker/daemon.json # 加入"exec-opts": ["native.cgroupdriver=systemd"] systemctl daemon-reload systemctl restart docker systemctl restart kubelet执行成功显示如下:
-
To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 172.31.43.126:6443 --token y5nwzd.kegm5jldmaep9i7z \ --discovery-token-ca-cert-hash sha256:f14ca1c0c3321d4c1ee7386eab8df759c34808ac0f902619fee4c506adcf6d9d根据提示执行
-
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config export KUBECONFIG=/etc/kubernetes/admin.conf # 并且安装插件,我这里安装Calico kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml # 命令检查,获取集群中所有部署好的应用,等待他们都是running状态 kubectl get pod -A # 查看集群里面所有的节点 kubectl get nodes5.其他节点加入集群
- 根据master节点的提示,可以在其他node节点使用命令加入集群
kubeadm join 172.31.43.126:6443 --token y5nwzd.kegm5jldmaep9i7z \
--discovery-token-ca-cert-hash sha256:f14ca1c0c3321d4c1ee7386eab8df759c34808ac0f902619fee4c506adcf6d9d 该token只有两个小时有效,如果两个小时内未使用,以后想加入集群,可以使用以下命令重新获取token
kubeadm token create --print-join-command
- 给集群加标签
kubectl label node k8s-node1 node.kubernetes.io/worker=''
# k8s-node1是节点的hostname
# node.kubernetes.io是固定写法不可变
# worker是给节点加的标签
# =''无所谓,''里面可以随便写
# 去除标签采用命令
kubectl label node k8s-node1 node.kubernetes.io/worker-- 设置ipvs模式
因为linux默认采用的是iptables模式,性能开销非常大,当你集群节点一多,每个节点的kube-proxy都要去同步iptables,可能一天都同步不完。
# 查看kube-proxy默认的模式
kubectl logs -n kube-system kube-proxy-28xv4
# 打开编辑kube-proxy的配置文件
kubectl edit cm kube-proxy -n kube-system
# 找到如下配置:
ipvs:
excludeCIDRs: null
minSyncPeriod: 0s
scheduler: ""
strictARP: false
syncPeriod: 0s
tcpFinTimeout: 0s
tcpTimeout: 0s
udpTimeout: 0s
kind: KubeProxyConfiguration
metricsBindAddress: ""
mode: ""mode中加入ipvs,保存后退出。
- 重启kube-proxy
kubectl get pod -A -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-system calico-kube-controllers-85b5b5888d-pg8bn 1/1 Running 692 (171m ago) 6d 192.168.235.195 k8s-master
kube-system calico-node-xdc6v 1/1 Running 318 (171m ago) 6d 172.31.43.126 k8s-master
kube-system coredns-65c54cc984-6mb7v 1/1 Running 104 (171m ago) 6d 192.168.235.196 k8s-master
kube-system coredns-65c54cc984-sfhnj 0/1 Pending 0 6d
kube-system etcd-k8s-master 1/1 Running 17 (171m ago) 6d 172.31.43.126 k8s-master
kube-system kube-apiserver-k8s-master 1/1 Running 270 (171m ago) 6d 172.31.43.126 k8s-master
kube-system kube-controller-manager-k8s-master 1/1 Running 872 (3m41s ago) 6d 172.31.43.126 k8s-master
kube-system kube-proxy-kbw49 1/1 Running 1 (171m ago) 6d 172.31.43.126 k8s-master
kube-system kube-scheduler-k8s-master 1/1 Running 845 (3m34s ago) 6d 172.31.43.126 k8s-master
# 找到kube-proxy-kbw49 ,删除他,不用担心他会自动重启,配置就生效了,-n后面跟的是他的命名空间。
kubectl delete pod kube-proxy-kbw49 -n kube-system
# 等待重启后重新查看状态
kubectl get pod -A|grep kube-proxy