【DevOps】GitOps之痛 -不完美的GitOps
前言
在前两篇文章中,我们对GitOps进行了大致的介绍:
【DevOps】GitOps初识(上) - 让DevOps变得更好
【DevOps】GitOps初识(下) - 让DevOps变得更好
GitOps 作为软件发布实践方式,有着许多的优点,然而,世上并没有完美无缺的事物, GitOps也是如此。当我们已经开始GipOps的探索,体验到它的美妙后,也必然体会到了使用它的痛苦。在这蜜月期已经结束的时候,我们需要开始审慎地探讨 GitOps 所存在的缺陷,才能更好地推进软件开发的进程。
GipOps只能覆盖软件开发的部分生命周期
当前的GitOps工具只关注应用程序的部署部分,而没有覆盖到其他的方面
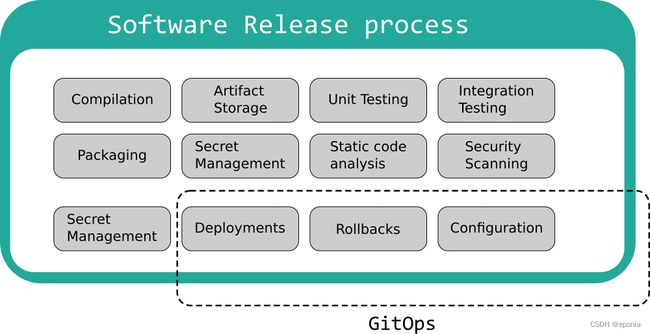
GitOps并非像许多人宣传的那样无所不能,它关注的部分非常有限,很多重要的步骤它都没有覆盖,比如:
- 代码编译/构建
- 单元测试/集成测试
- 代码安全扫描
- 静态分析
甚至,几个部署过程中应该关心的重要问题,GitOps也没有纳入它的关注范畴,如秘钥管理,跨环境版本发布,冒烟测试等。想要采用GitOps的技术团队,还需要自己妥善的设计一整套流程,与GitOps互相结合,才能形成最适合他们的最佳实践。
分离CI和CD并不如想象中简单
GitOps被誉为一种将CI与部署解耦的方法。在传统的CI/CD系统中,流程的最后一步通常是部署操作。采用GitOps的好处在于能够保持CI流程的独立性。Git提交将被监控Git仓库的GitOps组件捕捉,并通过在集群中拉取更改来进行实际部署。
在简单的场景下,这不失为一种行之有效的方案,但在大型组织采用的高级部署方案中,它可能会存在一些问题。举例来说,在进行Smoke Test之后,您可能需要根据测试结果来决定是否进行回滚操作。这种情况下,将CI和CD分离将变得非常困难,因为您需要在部署完成后立即运行Smoke Test,并快速准确地做出是否回滚的决策。
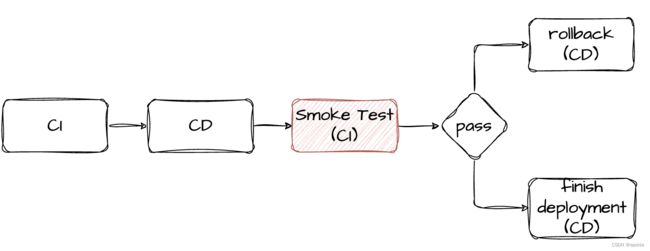
GitOps通常只处理CI过程产生的构件,如容器镜像,二进制包等,通常不能直接获取或调用源代码。但为了运行单元测试,通常我们是要获取并调用程序的源代码。目前我们采用的GitOps工具都没有能力获取到源代码,当然也不具备测试所需的框架和第三方库,因此不具备单元测试或集成测试的能力,它只负责将CI产物拉取并部署到环境中。 为了进行Smoke Test,我们将不得不再次使用CI流程中的方案来运行测试。
这样的结果就是CI-CD-CI-CD组件和过程产生了混合,这与我们使用GitOps的初衷背道而驰。在上图的方案中,还存在其他一些问题,例如,在Smoke Test开始前,如何准备的判断部署完成的时机,以触发测试。
在这样的场景下,如果放弃GitOps,采用传统的CICD方式,问题似乎就会迎刃而解。
难以自动推进跨环境的版本发布
一旦开始实践GitOps, 这几乎是每个人首先面临的诸多挑战之一。在大型的组织结构中,应用必然会部署到多个环境中。

正如上图所示,当代码提交后,会触发CI流程,得到一个可部署的产物,dev环境中的GitOps组件检测到了git仓库变化,于是触发了dev环境的部署。 那么怎么在dev环境完成部署后,进一步将新的版本发布部署到stage, 进而到production环境呢?
有人说可以通过CI的流程来实现,当然这就意味着放弃了GitOps。还有人说我们只有一个环境,不需要考虑这样的问题,当然,小企业中这是有可能的。 还有人说,我们用branch来区分不同的环境,每当要部署一个环境时,我们就在对应的branch新建一个Pull Request, 以触发CI/CD流程,那么流程就不再是上图那样了,而是像这样:
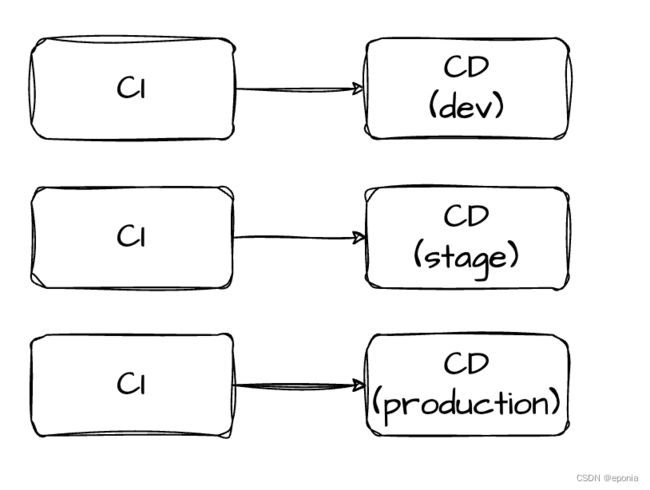
这种方案相信也是多数人第一时间能想到的最好方式,也是一种非常流行的做法,但是却经不起时间的考验,长久下来,我们就会发现其中存在很多的问题:
- 在环境对应的分支上提交业务代码,这意味着代码仓库需要包含特定环境的信息, 这就使得各个分支的代码与各自的环境相耦合,各分支的代码不一致;
- 各分支的代码需要花费大量精力进行同步,例如经常发生的
hostfix和配置变更,且有些配置还是与环境相关的,很容易出错; - CI系统会增加额外的压力,因为每个分支都会执行CI, 去运行其中的构件/测试等步骤。
这些缺点会随着环境数量变多,变得越来越明显,让人疲于应付。
没有规范的多环境配置管理方法
根据上节所述,如果你的应用有多个环境的话。 GitOps不仅不能帮助你,还会造成许多的困扰。假设你的应用有10个环境,每个环境对应一个需部署的地区。 你想在这些地区间逐个部署应用(比如先部署中国,再部署印度,再部署德国,再部署美国 …)。那你会有以下几种方案可以选择:
- 一个
git repo, 10个bracnh, 这意味着每次版本发布,都需要提交十次PR, 进行10次代码合并。 - 10个
git repo,那你需要对10个repo都提交commit, 或自己编写脚本来自动提交commit到不同的repo, 或者是在不同的repo间提交pull request - 1个单分支的
repo, 每个环境对应一个文件目录, 这样的话你需要额外的方案来保证这些目录间的更改可以同步。
上述的每个方案,其实都需要繁琐的额外工作,很难说哪一个方案更好。
GitOps会破坏一些特殊资源(如自动伸缩等动态资源)
GitOps会在部署时,完全按照Git仓库中的配置调整环境的实际配置,这本是它的一大卖点,但在一些复杂的场景中,这反而会成为一个令人头疼的大麻烦,特别是在那些可能拥有动态变化的值的资源中,尤其如此:
- 在配置了
autoscaler的资源中,replica会成为一个动态变化的配置; - 在配置了
optimizer的资源中,resource limit会成为一个动态变化的配置; - 其他一些由于第三方工具的作用,可能会出现的动态变化的配置(特别是有些跟日期和时间戳有关的配置);
试想这样一种情况, git仓库中某个deployment的replica字段配置为2, 由于autoscaler的作用, 目前环境中实际的replica字段的值为3, 此时, 如果git仓库有改动(假设改动的是某个ingress的配置,与这个deployment并无关系),此时会触发GitOps的部署,GitOps会尝试应用git仓库中的所有配置, 环境中该deployment的replica数量将被强制的设置为2。 这显然不是我们想要的效果。
针对这个问题,ArgoCD支持custom diff, 但只能做为一个workaround。 这种方案其实破坏了GitOps的设计初衷,并且会引入一些其他的问题。
GitOps没有标准的回滚流程
事实上,在GitOps中执行回滚操作是非常方便的,只需要在GitOps执行同步操作时指定想要回滚到的目标版本的commit即可,但是,在实践中,如何"使用之前的commit"是一个问题, 不同的人会有不同的理解:
- 直接在GitOps上执行回滚操作,指定
commit号。 但这样做的问题是,实际环境中的应用版本与Git仓库中的最新版本不一致,与GitOps的设计初衷不一致; - 在Git仓库中执行
revert操作,回滚到之前的代码版本,触发CI 和 GitOps部署,这样的话就遵循了GitOps的原则, 但是显然需要一些手动的操作; - 将上面两种方式结合起来,在GitOps执行回滚操作的同时,由GitOps向Git仓库提交一个回滚的
commit或revert操作, 使得环境和Git仓库的代码保持一致。 但显然会存在一些安全隐患,相信大多数人都不会允许GitOps这样的部署系统对Git仓库拥有修改的权限。
如上所述, 不同的人可能对于回滚有着不同的想法和实践。 目前为止, 现有的GitOps工具都没有提供一套标准的流程建议来执行回滚。
可观测性尚不完善
这一点主要是从业务角度出发来看的, 从运维和开发人员这些技术角色的角度出发, GitOps的可观测性已经非常棒了,可以看到Git的提交和哈希值,确保他们和代码仓库中的一致。然而,业务负责人的关注点却不在这些地方,从一个软件的功能角度来说,更重要的可能是下面这些问题:
production环境中是否包含某个特定的feature?- 某个
feature是否已经在staging环境中测试通过了? - 某些特定的
bug是否只出现在某几个特定的环境中?
这些问题通常是业务负责人或者项目经理非常关心的,他们会希望通过某种方式快速的得到这些信息。 目前GitOps的工具都关注在技术的最底层次,也就是Git Commit Hash, 并且没有提供任何与业务特征关联的方法。 想要找出代码与业务的关联, 还是需要开发或运维这些技术角色去人工判断。
审计仍是问题
尽管通过Git仓库我们可以获取到所有的提交历史记录和部署记录, 但是正如上面一点提到的,从这些信息上,并不能轻易的映射到应用功能的变更,如果想从业务和功能的角度进行审计,仍然是非常困难的。
在相对简单的环境中,也许可以通过commit的文字信息来映射到某个应用或功能的变更。但这只适用于简单的场景。在企业级的应用环境中, Git仓库和配置文件的数量都是非常多的。 再简单的通过结合commit的文字信息来判断功能变更是不太可能实现的。在复杂的环境下,某个代码变更可能对应到多个应用,也可能只对应到一个应用,有的设置只影响一些无关紧要的配置,谈不上版本变更。
类似于可观测性不足的问题,从审计角度看,下面这些问题可能也是GitOps无法轻易回答的:
- 某个特定
feature从预发布环境到生产环境用了多长时间; - 过去两个月中,各个
feature的最长,最短和平均开发周期是多少(从第一个commit提交到上线生产环境); - 某个特定环境的部署成功率是多少?导致回滚的原因是什么?
- 哪些各个环境中的应用
feature有哪些差别?
在稍成规模的软件团队中,这些问题实际上是普遍需要关注的。 而GitOps还没有能力去统计这些信息。
难以大规模的应用GitOps
随着公司规模的增大以及应用程序和环境数量的增加,采用GitOps会导致Git存储库数量急剧增加,给管理带来困难。
例如,如果有20个存储库(假设对应20个环境)包含kubernetes配置,现在,需要对一些公共的配置进行修改(例如在每个部署中添加新的公司级标签),就需要手动进行20次Git提交。前文已经提到, 如果将所有环境和集群都放在单个Git存储库中,可能会出现Git冲突的问题,且单一的巨大Git存储库也会成为GitOps过程中的性能瓶颈,因为GitOps会扫描Git仓库,仓库中的内容过多会导致扫描的性能消耗过大。
因此,在采用GitOps的过程中,需要在方便管理和避免冲突之间进行权衡。一种方式是将相似的环境和应用程序放在同一个存储库中,但是不要将所有东西都放在一个存储库中。总之,我们需要通过权衡,才可以更好地实现GitOps的效益。
与Helm的结合不顺利
众所周知,helm被称为kubernetes的包管理器, 可以方便的在集群中部署各种的第三方应用,当然,也可以用于部署我们自己的业务系统和应用。 helm的工作原理是用一组value去渲染一组kubernetes manifests模版, 用其得到的结果作为kubernetes配置清单,将其中声明的应用和配置部署到环境中去。
在运行helm命令进行部署时,会提供一个values.yml文件作为输入,最佳实践是把这个文件也提交到git仓库中去。 对于不同的环境(dev/staging/production),其对应的values.yml的内容应有所不同。
helm部署有三个关键部分,分别是:
- 源代码: 用于构建镜像
- 配置清单模版(
chart) - 用于渲染模版的输入值(
values.yml)
helm本身并没有规定这三部分需要存放的具体位置。我们可以把它们全都存到同一个git仓库中,也可以分别存到3个不同的git仓库中。由于不同的环境应有不同的value.yml, 而模版文件是各个环境共享的,因此推荐的做法是不要把values.yml和模版文件放在同一个仓库中。推荐将模版文件存到一个仓库中,将不同环境的values.yml存到另一个仓库中。
那么,我们可以想象,用GitOps进行helm部署的大致流程应该如下:
- 从模版仓库中下载模版文件;
- 从value仓库中下载对应环境的
values.yml; - 用
values.yml渲染模版文件,得到kubernetes manifests(资源清单); - 将生成的
kubernetes manifests应用到环境中去。
上面的步骤应该是应用首次部署时的步骤。 依照GitOps的范例,两个仓库都应该被监测,而且监测的应该是用values.yml渲染模版后得到的manifests是否有变化。目前为止,各种GitOps工具都还不支持这样的功能,尽管如ArgoCD和Flux这样的工具提供了一些workaround, 但同样也有很多的限制,如果你希望在GitOps流程中应用helm,可能会使得整个流程变得更加的复杂。
GitOps并不等于CD(持续发布)
GitOps是一种优秀的持续交付方案,每次源代码仓库的提交,只会触发CI流程,生成一个可发布的版本包,但不会直接部署到生产环境。而持续发布意味着,每次对源代码仓库的提交,都会直接推送到生产环境。
根据GitOps的定义和标准流程, 只有在配置仓库的PR才会触发GitOps的部署,而源代码仓库的提交并不会触发。在大多数情况下,配置仓库的PR还是会被人为的审批的。这意味着在GitOps部署的流程中还是多多少少会存在人工操作的步骤来处理这些PR。理论上说,如果能把对配置仓库的PR的审批流程自动化,那么GitOps也可以变成完全自动化的持续发布。但是GitOps工具本身并没有提供这方面的自动化能力,想要达到这样的效果,还是需要我们自己进行额外的设计。
当然,并不是全自动,无人干预的持续发布就一定是更好的选择。由于政策以及合规的要求,有很多组织就要求在部署前必须要有人工的审查步骤,从而禁止完全的自动部署流程出现。但如果你的目的是尽量快速的使代码上线,那GitOps就不是你的最佳选择了。
秘钥管理
在GitOps的世界中,秘钥管理本身就是一个悖论, 然而秘钥管理在任何的软件部署系统中都是一个必须解决的问题,可GitOps却没办法处理。众所周知,处于安全性的考虑,秘钥是不能直接存放在Git中的。但如果不存放在Git中,又违背了GitOps的初衷 – 集群状态与Git中声明的状态保持一致(当然也包括秘钥)。
总结
虽然GitOps有这么多令人头疼的问题,但是仍然不失为一种优秀的持续交付方案,并且越来越收到欢迎,上面说到的这些问题,相信在将来也会被不断地完善。