【Linux 入门篇(三)】Vim、Gcc、Make、Makefile、Shell
目录
- 一、vim 编辑器
-
- 1. vim编辑器工作模式
-
- 1.1 一般模式
- 1.2 编辑模式
- 1.3 命令行模式
- 2. 保存退出
- 3. 其他操作方式
-
- 3.1 移动光标
- 3.2 屏幕翻滚指令
- 3.3 复制、删除和粘贴指令
- 4. 设置 TAB 键为 4 字节
- 5. VIM 编辑器显示行号
- 二、GCC
-
- 1. GCC编译器
- 2. GCC编译流程
- 三、Make、Makefile
-
- 1. Make、Makefile 介绍
- 2. Makefile 的使用
-
- 2.1 使用gcc编译
- 2.2 使用 Makefile 编译
- 3. Makefile 语法
-
- 3.1 Makefile 规则格式
- 4. Makefile 变量
-
- 4.1 赋值符 “=”
- 4.2 赋值符 “:=”
- 4.3 赋值符 “?=”
- 4.4 变量追加 “+=”
- 5. Makefile 模式规则
- 6. Makefile 自动化变量
- 7. Makefile 伪目标
- 8. Makefile 条件判断
- 9. Makefile 函数使用
一、vim 编辑器
Linux系统都会自带vi编辑器,vim编辑器需要另外安装。
安装命令:sudo apt-get install vim
使用vi命令打开文件:vim test.c
1. vim编辑器工作模式
1.1 一般模式
用vim打开一个软件以后自动进入到此模式。
1.2 编辑模式
一般模式中无法编辑文件,要编辑文件就要进入编辑模式,按下“i、I、a、A、o、O、s、r”等就会进入到编辑模式。一般按下“a”进入编辑模式。按下ESC键可退出编辑模式。
| 指令 | 描述 |
|---|---|
| i | 在当前光标所在字符的前面,转为输入模式。 |
| I | 在当前光标所在行的行首转换为输入模式。 |
| a | 在当前光标所在字符的后面,转为输入模式。 |
| A | 在光标所在行的行尾,转换为输入模式。 |
| o | 在当前光标所在行的下方,新建一行,并转为输入模式。 |
| O | 在当前光标所在行的上方,新建一行,并转为输入模式。 |
| s | 删除光标所在字符。 |
| r | 替换光标处字符。 |
1.3 命令行模式
先进入到一般模式,然后输入:、/、?这三个中的任意一个就可以进入到命令行模式。
2. 保存退出
当文件编辑好以后,输入
:wq来保存退出。:q退出,:q!不保存退出,:w保存。
3. 其他操作方式
3.1 移动光标
| 指令 | 描述 |
|---|---|
| h(或左方向键) | 光标左移一个字符。 |
| l(或右方向键) | 光标右移一个字符。 |
| j(或下方向键) | 光标下移一行。 |
| k(或上方向键) | 光标上移一行。 |
| nG | 光标移动到第 n 行首。 |
| n+ | 光标下移 n 行。 |
| n- | 光标上移 n 行。 |
3.2 屏幕翻滚指令
| 指令 | 描述 |
|---|---|
| Ctrl+f | 屏幕向下翻一页,相当于下一页。 |
| Ctrl+b | 屏幕向上翻一页,相当于上一页。 |
3.3 复制、删除和粘贴指令
| 指令 | 描述 |
|---|---|
| cc | 删除整行,并且修改整行内容。 |
| dd | 删除该行,不提供修改功能。 |
| ndd | 删除当前行向下 n 行。 |
| x | 删除光标所在的字符。 |
| X | 删除光标前面的一个字符。 |
| nyy | 复制当前行及其下面 n 行。 |
| p | 粘贴最近复制的内容。 |
4. 设置 TAB 键为 4 字节
VI 编辑器默认 TAB 键为 8 空格,我们改成 4 空格,用 vi 打开文件/etc/vim/vimrc,在此文
件最后面输入如下代码:set ts=4
修改完成以后保存并关闭文件。
5. VIM 编辑器显示行号
VIM 编辑器默认是不显示行号的,不显示行号不利于代码查看,我们设置 VIM 编辑器显
示行号,同样是通过在文件/etc/vim/vimrc 中添加代码来实现,在文件最后面加入下面一行代码即可:set nu
修改完成以后保存并关闭文件。
二、GCC
Ubuntu 下的 C 语言编译器是 GCC,GCC 编译器在我们 Ubuntu 的时候就已经默认安装好了,可以通过如下命令查看 GCC 编译器的版本号:
gcc -v
1. GCC编译器
gcc [选项] [文件名]
gcc test.c -o test
主要选项如下:
-c:只编译不链接为可执行文件,编译器将输入的.c 文件编译为.o 的目标文件。
-o:<输出文件名>用来指定编译结束以后的输出文件名,如果不使用这个选项的话 GCC 默认编译出来的可执行文件名字为 a.out。
-g:添加调试信息,如果要使用调试工具(如 GDB)的话就必须加入此选项,此选项指示编译的时候生成调试所需的符号信息。
-O:对程序进行优化编译,如果使用此选项的话整个源代码在编译、链接的的时候都会进行优化,这样产生的可执行文件执行效率就高。
-O2:比-O 更幅度更大的优化,生成的可执行效率更高,但是整个编译过程会很慢。
2. GCC编译流程
GCC 编译器的编译流程是:预处理、编译、汇编和链接。预处理就是展开所有的头文件、替换程序中的宏、解析条件编译并添加到文件中。编译是将经过预编译处理的代码编译成汇编代码,也就是我们常说的程序编译。汇编就是将汇编语言文件编译成二进制目标文件。链接就是将汇编出来的多个二进制目标文件链接在一起,形成最终的可执行文件,链接的时候还会涉及到静态库和动态库等问题。
三、Make、Makefile
1. Make、Makefile 介绍
GCC 编译器在 Linux 进行 C 语言编译,通过在终端执行 gcc 命令来完成 C 文件的编译,如果我们的工程只有一两个 C 文件还好,需要输入的命令不多,当文件有几十、上百甚至上万个的时候用终端输入 GCC 命令的方法显然是不现实的。如果我们能够编写一个文件,这个文件描述了编译哪些源码文件、如何编译那就好了,每次需要编译工程的时只需要使用这个文件就行了。这种问题怎么可能难倒聪明的程序员,为此提出了一个解决大工程编译的工具:make,描述哪些文件需要编译、哪些需要重新编译的文件就叫做 Makefile,Makefile 就跟脚本文件一样,Makefile 里面还可以执行系统命令。使用的时候只需要一个 make命令即可完成整个工程的自动编译,极大的提高了软件开发的效率。
如果大家以前一直使用 IDE来编写 C 语言的话肯定没有听说过 Makefile 这个东西,其实这些 IDE 是有的,只不过这些 IDE对其进行了封装,提供给大家的是已经经过封装后的图形界面了,我们在 IDE 中添加要编译的C 文件,然后点击按钮就完成了编译。在 Linux 下用的最多的是 GCC 编译器,这是个没有 UI的编译器,因此 Makefile 就需要我们自己来编写了。作为一个专业的程序员,是一定要懂得Makefile 的,一是因为在 Linux 下你不得不懂 Makefile,再就是通过 Makefile 你就能了解整个工程的处理过程。
2. Makefile 的使用
如有main.c、input.c 和 calcu.c 这三个 C 文件和 input.h、calcu.h 这两个头文件。其中 main.c 是主体,input.c 负责接收从键盘输入的数值,calcu.c 进行任意两个数相加
2.1 使用gcc编译
gcc 编译器对 main.c、calcu.c 和 input.c 这三个文件进行编译,编译生成的可执行文件叫做 main。
gcc main.c calcu.c input.c -o main
使用命令gcc main.c calcu.c input.c -o main看起来很简单是吧,只需要一行就可以完成编译,但是我们这个工程只有三个文件啊!如果几千个文件呢?再就是如果有一个文件被修改了以,使用上面的命令编译的时候所有的文件都会重新编译,如果工程有几万个文件(Linux 源码就有这么多文件!),想想这几万个文件编译一次所需要的时间就可怕。最好的办法肯定是哪个文件被修改了,只编译这个被修改的文件即可,其它没有修改的文件就不需要再次重新编译了,为此我们改变我们的编译方法,如果第一次编译工程,我们先将工程中的文件都编译一遍,然后后面修改了哪个文件就编译哪个文件,命令如下:
gcc -c main.c
gcc -c input.c
gcc -c calcu.c
gcc main.o input.o calcu.o -o main
上述命令前三行分别是将 main.c、input.c 和 calcu.c 编译成对应的.o 文件,所以使用了“- c”选项,“-c”选项我们上面说了,是只编译不链接。最后一行命令是将编译出来的所有.o 文件
链接成可执行文件 main。假如我们现在修改了 calcu.c 这个文件,只需要将 caclue.c 这一个文件
重新编译成.o 文件,然后在将所有的.o 文件链接成可执行文件即,只需要下面两条命令即可:
gcc -c calcu.c
gcc main.o input.o calcu.o -o main
但是这样就又有一个问题,如果修改的文件一多,我自己可能都不记得哪个文件修改过了,然后忘记编译,然后……,为此我们需要这样一个工具:
1、如果工程没有编译过,那么工程中的所有.c 文件都要被编译并且链接成可执行程序。
2、如果工程中只有个别 C 文件被修改了,那么只编译这些被修改的 C 文件即可。
3、如果工程的头文件被修改了,那么我们需要编译所有引用这个头文件的 C 文件,并且链接成可执行文件。
很明显,能够完成这个功能的就是 Makefile 了,在工程目录下创建名为“Makefile”的文件,文件名一定要叫做“Makefile”!!!区分大小写的哦!
2.2 使用 Makefile 编译
Makefile 和 C 文件是处于同一个目录的

在 Makefile 文件中输入如下代码:
main: main.o input.o calcu.o
gcc -o main main.o input.o calcu.o
main.o: main.c
gcc -c main.c
input.o: input.c
gcc -c input.c
calcu.o: calcu.c
gcc -c calcu.c
clean:
rm *.o
rm main
上述代码中所有行首需要空出来的地方一定要使用“TAB”键!不要使用空格键!这是Makefile 的语法要求
Makefile 编写好以后我们就可以使用 make 命令来编译我们的工程了,直接在命令行中输入“make”即可,make 命令会在当前目录下查找是否存在“Makefile”这个文件,如果存在的话就会按照 Makefile 里面定义的编译方式进行编译
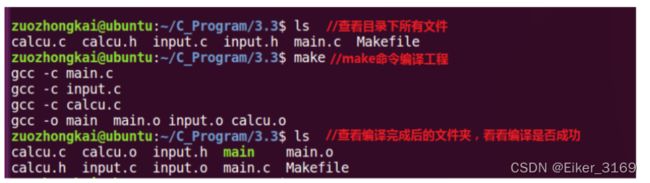
使用命令“make”编译完成以后就会在当前工程目录下生成各种.o 和可执行文件,说明我们编译成功了。
需要用到 Makefile 中的 clear 命令,清除 .o 文件和 main 文件,格式如下
make clear
3. Makefile 语法
3.1 Makefile 规则格式
Makefile 里面是由一系列的规则组成的,这些规则格式如下:
目标… : 依赖文件集合…
命令 1
命令 2
……
比如:
main : main.o input.o calcu.o
gcc -o main main.o input.o calcu.o
这条规则的目标是 main,main.o、input.o 和 calcu.o 是生成 main 的依赖文件,如果要更新目标 main,就必须先更新它的所有依赖文件,如果依赖文件中的任何一个有更新,那么目标也必须更新,“更新”就是执行一遍规则中的命令列表。
命令列表中的每条命令必须以 TAB 键开始,不能使用空格!
make 命令会为 Makefile 中的每个以 TAB 开始的命令创建一个 Shell 进程去执行。
分析如下代码:
main: main.o input.o calcu.o
gcc -o main main.o input.o calcu.o
main.o: main.c
gcc -c main.c
input.o: input.c
gcc -c input.c
calcu.o: calcu.c
gcc -c calcu.c
clean:
rm *.o
rm main
上述代码中一共有 5 条规则,1~2 行为第一条规则,3~4 行为第二条规则,5~6 行为第三条规则,7~8 行为第四条规则,10~12 为第五条规则,make 命令在执行这个 Makefile 的时候其执行步骤如下:
首先更新第一条规则中的 main,第一条规则的目标成为默认目标,只要默认目标更新了那么就认为 Makefile 的工作。在第一次编译的时候由于 main 还不存在,因此第一条规则会执行,第一条规则依赖于文件 main.o、input.o 和 calcu.o 这个三个.o 文件,这三个.o 文件目前还都没有,因此必须先更新这三个文件。make 会查找以这三个.o 文件为目标的规则并执行。以 main.o为例,发现更新 main.o 的是第二条规则,因此会执行第二条规则,第二条规则里面的命令为“gcc–c main.c”,这行命令很熟悉了吧,就是不链接编译 main.c,生成 main.o,其它两个.o 文件同理。最后一个规则目标是 clean,它没有依赖文件,因此会默认为依赖文件都是最新的,所以其对应的命令不会执行,当我们想要执行 clean 的话可以直接使用命令“make clean”,执行以后就会删除当前目录下所有的.o 文件以及 main,因此 clean 的功能就是完成工程的清理,“make clean”的执行过程如图 所示:
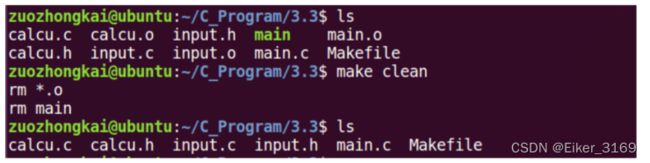
总结 Make 的执行过程:
- make 命令会在当前目录下查找以 Makefile(makefile 其实也可以)命名的文件。
- 当找到 Makefile 文件以后就会按照 Makefile 中定义的规则去编译生成最终的目标文件。
- 当发现目标文件不存在,或者目标所依赖的文件比目标文件新(也就是最后修改时间比目标文件晚)的话就会执行后面的命令来更新目标。
make 工具就是在 Makefile 中一层一层的查找依赖关系,并执行相应的命令。编译出最终的可执行文件。Makefile 的好处就是“自动化编译”,一旦写好了 Makefile文件,以后只需要一个 make 命令即可完成整个工程的编译,极大的提高了开发效率。
Makefile 中规则用来描述在什么情况下使用什么命令来构建一个特定的文件,这个文件就是规则的“目标”,为了生成这个“目标”而作为材料的其它文件称为“目标”的依赖,规则的命令是用来创建或者更新目标的。
除了 Makefile 的“终极目标”所在的规则以外,其它规则的顺序在 Makefile 中是没有意义的,“终极目标”就是指在使用 make 命令的时候没有指定具体的目标时,make 默认的那个目标,它是 Makefile 文件中第一个规则的目标,如果 Makefile 中的第一个规则有多个目标,那么这些目标中的第一个目标就是 make 的“终极目标”。
4. Makefile 变量
main: main.o input.o calcu.o
gcc -o main main.o input.o calcu.o
上述 Makefile 语句中,main.o input.o 和 calcue.o 这三个依赖文件,我们输入了两遍,我们这个 Makefile 比较小,如果 Makefile 复杂的时候这种重复输入的工作就会非常费时间,而且非常容易输错,为了解决这个问题,Makefile 加入了变量支持。不像 C 语言中的变量有 int、char等各种类型,Makefile 中的变量都是字符串!类似 C 语言中的宏。使用变量将上面的代码修改,修改以后如下所示:
1 #Makefile 变量的使用
2 objects = main.o input.o calcu.o
3 main: $(objects)
4 gcc -o main $(objects)
分析:
第 1 行是注释,Makefile 中可以写注释,注释开头要用符号“#”,不能用 C 语言中的“//”或者“/**/”!
第 2 行我们定义了一个变量 objects,并且给这个变量进行了赋值,其值为字符串“main.o input.o calcu.o”。
第 3 和 4行使用到了变量 objects,Makefile 中变量的引用方法是“$(变量名)”,比如本例中的“$(objects)”就是使用变量 objects。
4.1 赋值符 “=”
使用 “=” 在给变量的赋值的时候,不一定要用已经定义好的值,也可以使用后面定义的值,比如如下代码:
1 name = zzk
2 curname = $(name)
3 name = zuozhongkai
4
5 print:
6 @echo curname: $(curname)
分析:
第 1 行定义了一个变量 name,变量值为“zzk”
第 2 行也定义了一个变量curname,curname的变量值引用了变量name,按照我们C写语言的经验此curname的值就是“zzk”
第 3 行将变量 name 的值改为了“zuozhongkai”
第 5、6 行是输出变量 curname的值。在 Makefile 要输出一串字符的话使用“echo”,就和 C 语言中的“printf”一样,
第 6 行中的“echo”前面加了个“@”符号,因为 Make 在执行的过程中会自动输出命令执行过程,在命令前面加上“@”的话就不会输出命令执行过程,大家可以测试一下不加“@”的效果。使用命令“make print”来执行上述代码,

可以看到curname的值不是“zzk”,竟然是“zuozhongkai”,也就是变量“name”最后一次赋值的结果,这就是赋值符“=”的神奇之处!借助另外一个变量,可以将变量的真实值推到后面去定义。也就是变量的真实值取决于它所引用的变量的最后一次有效值。
4.2 赋值符 “:=”
1 name = zzk
2 curname := $(name)
3 name = zuozhongkai
4
5 print:
6 @echo curname: $(curname)
修改完成以后执行 Makefile

此时的 curname 是 zzk,不是 zuozhongkai 了。这是因为赋值符 “:=” 不会使用后面定义的变量,只能使用前面已经定义好的,这就是 “=” 和 “:=” 两个的区别。
4.3 赋值符 “?=”
下述代码的意思就是,如果变量 curname 前面没有被赋值,那么此变量就是“zuozhongkai”,如果前面已经赋过值了,那么就使用前面赋的值。
curname ?= zuozhongkai
4.4 变量追加 “+=”
Makefile 中的变量是字符串,有时候我们需要给前面已经定义好的变量添加一些字符串进
去,此时就要使用到符号“+=”,比如如下所示代码:
objects = main.o inpiut.o
objects += calcu.o
一开始变量 objects 的值为“main.o input.o”,后面我们给他追加了一个“calcu.o”,因此变量 objects 变成了“main.o input.o calcu.o”,这个就是变量的追加。
5. Makefile 模式规则
1 main: main.o input.o calcu.o
2 gcc -o main main.o input.o calcu.o
3 main.o: main.c
4 gcc -c main.c
5 input.o: input.c
6 gcc -c input.c
7 calcu.o: calcu.c
8 gcc -c calcu.c
9
10 clean:
11 rm *.o
12 rm main
上述 Makefile 中第 3~8 行是将对应的.c 源文件编译为.o 文件,每一个 C 文件都要写一个对应的规则,如果工程中 C 文件很多的话显然不能这么做。为此,我们可以使用 Makefile 中的模式规则,通过模式规则我们就可以使用一条规则来将所有的.c 文件编译为对应的.o 文件。
模式规则中,至少在规则的目标定定义中要包涵“%”,否则就是一般规则,目标中的“%”表示对文件名的匹配,“%”表示长度任意的非空字符串,比如“%.c”就是所有的以.c 结尾的文件,类似与通配符,a.%.c 就表示以 a.开头,以.c 结束的所有文件。
当“%”出现在目标中的时候,目标中“%”所代表的值决定了依赖中的“%”值,使用方法如下:
%.o : %.c
命令
次因以上代码中的 Makefile 可以改为如下形式:
1 objects = main.o input.o calcu.o
2 main: $(objects)
3 gcc -o main $(objects)
4
5 %.o : %.c
6 #命令
7
8 clean:
9 rm *.o
10 rm main
第 5、6 这两行代码替代了“示例代码”中的 3~8 行代码,修改以后的 Makefile 还不能运行,因为第 6 行的命令我们还没写呢,第 6 行的命令我们需要借助另外一种强大的变量—自动化变量。
6. Makefile 自动化变量
上面讲的模式规则中,目标和依赖都是一系列的文件,每一次对模式规则进行解析的时候都会是不同的目标和依赖文件,而命令只有一行,如何通过一行命令来从不同的依赖文件中生成对应的目标?自动化变量就是完成这个功能的!所谓自动化变量就是这种变量会把模式中所定义的一系列的文件自动的挨个取出,直至所有的符合模式的文件都取完,自动化变量只应该出现在规则的命令中,常用的自动化变量如表
| 自动化变量 | 描述 |
|---|---|
| $@ | 规则中的目标集合,在模式规则中,如果有多个目标的话,“$@”表示匹配模式中定义的目标集合。 |
| $% | 当目标是函数库的时候表示规则中的目标成员名,如果目标不是函数库文件,那么其值为空。 |
| $< | 依赖文件集合中的第一个文件,如果依赖文件是以模式(即“%”)定义的,那么“$<”就是符合模式的一系列的文件集合。 |
| $? | 所有比目标新的依赖目标集合,以空格分开。 |
| $^ | 所有依赖文件的集合,使用空格分开,如果在依赖文件中有多个重复的文件,“$^”会去除重复的依赖文件,值保留一份。 |
| $+ | 和“$^”类似,但是当依赖文件存在重复的话不会去除重复的依赖文件。 |
| $* | 这个变量表示目标模式中"%"及其之前的部分,如果目标是 test/a.test.c,目标模式为 a.%.c,那么“$*”就是 test/a.test。 |
表中的 7 个自动化变量中,常用的三种:$@、$<和$^,我们使用自动化变量来完成“示例代码 ”中的 Makefile,最终的完整代码如下所示:
1 objects = main.o input.o calcu.o
2 main: $(objects)
3 gcc -o main $(objects)
4
5 %.o : %.c
6 gcc -c $<
7
8 clean:
9 rm *.o
10 rm main
第 5 行使用了模式规则,第 6 行使用了自动化变量。
7. Makefile 伪目标
Makefile 有一种特殊的目标——伪目标,一般的目标名都是要生成的文件,而伪目标不代表真正的目标名,在执行 make 命令的时候通过指定这个伪目标来执行其所在规则的定义的命令。
使用伪目标主要是为了避免 Makefile 中定义的执行命令的目标和工作目录下的实际文件出现名字冲突,有时候我们需要编写一个规则用来执行一些命令,但是这个规则不是用来创建文件的,比如在前面的“示例代码”中有如下代码用来完成清理工程的功能:
clean:
rm *.o
rm main
上述规则中并没有创建文件 clean 的命令,因此工作目录下永远都不会存在文件 clean,当我们输入“make clean”以后,后面的“rm *.o”和“rm main”总是会执行。可是如果我们“手贱”,在工作目录下创建一个名为“clean”的文件,那就不一样了,当执行“make clean”的时候,规则因为没有依赖文件,所以目标被认为是最新的,因此后面的 rm 命令也就不会执行,我们预先设想的清理工程的功能也就无法完成。为了避免这个问题,我们可以将 clean 声明为伪目标,声明方式如下:
.PHONY : clean
我们使用伪目标来更改“示例代码”,修改完成以后如下:
1 objects = main.o input.o calcu.o
2 main: $(objects)
3 gcc -o main $(objects)
4
5 .PHONY : clean
6
7 %.o : %.c
8 gcc -c $<
9
10 clean:
11 rm *.o
12 rm main
上述代码第 5 行声明 clean 为伪目标,声明 clean 为伪目标以后不管当前目录下是否存在名为“clean”的文件,输入“make clean”的话规则后面的 rm 命令都会执行
8. Makefile 条件判断
在 C 语言中我们通过条件判断语句来根据不同的情况来执行不同的分支,Makefile 也支持条件判断,语法有两种如下:
<条件关键字>
<条件为真时执行的语句>
endif
<条件关键字>
<条件为真时执行的语句>
else
<条件为假时执行的语句>
endif
其中条件关键字有 4 个:ifeq、ifneq、ifdef 和 ifndef,这四个关键字其实分为两对、ifeq 与ifneq、ifdef 与 ifndef,先来看一下 ifeq 和 ifneq,ifeq 用来判断是否相等,ifneq 就是判断是否不相等,ifeq 用法如下:
ifeq (<参数 1>, <参数 2>)
ifeq ‘<参数 1 >’,‘ <参数 2>’
ifeq “<参数 1>”, “<参数 2>”
ifeq “<参数 1>”, ‘<参数 2>’
ifeq ‘<参数 1>’, “<参数 2>”
上述用法中都是用来比较“参数 1”和“参数 2”是否相同,如果相同则为真,“参数 1”和“参数 2”可以为函数返回值。ifneq 的用法类似,只不过 ifneq 是用来了比较“参数 1”和“参数 2”是否不相等,如果不相等的话就为真。
ifdef 和 ifndef 的用法如下:
ifdef <变量名>
如果“变量名”的值非空,那么表示表达式为真,否则表达式为假。“变量名”同样可以是一个函数的返回值。ifndef 用法类似,但是含义用户 ifdef 相反。
9. Makefile 函数使用
Makefile 支持函数,类似 C 语言一样,Makefile 中的函数是已经定义好的,我们直接使用,不支持我们自定义函数。make 所支持的函数不多,但是绝对够我们使用了,函数的用法如下:
$(函数名 参数集合)
${函数名 参数集合}
可以看出,调用函数和调用普通变量一样,使用符号“$”来标识。参数集合是函数的多个参数,参数之间以逗号“,”隔开,函数名和参数之间以“空格”分隔开,函数的调用以“$”开头。具体函数详情可以参考《跟我一起写 Makefile》。