Linux: 性能分析之On-CPU和Off-CPU
文章目录
- 1. 前言
- 2. 概述
- 3. 分析方法概述
-
- 3.1 CPU 采样 方法
- 3.2 跟踪 方法
- 4. 使用火焰图分析
-
- 4.1 On-CPU 分析
- 4.2 Off-CPU 分析
-
- 4.2.1 Off-CPU 两种分析方法对比
- 4.2.2 生成 Off-CPU 火焰图
- 5. 参考资料
1. 前言
限于作者能力水平,本文可能存在谬误,因此而给读者带来的损失,作者不做任何承诺。
2. 概述
本文介绍用 火焰图(Flame Graph) 来分析 On-CPU 和 Off-CPU 线程状态的方法。火焰图 是分层数据的可视化,旨在可视化分析软件的堆栈跟踪记录,以便快速准确地识别最热的代码路径。
本文例子在 Ubuntu 16.04.4 LTS 下实施,如果你的系统下还没有安装 perf ,请查阅相关资料先安装 perf 。操作需要特权用户进行,操作前先切换到特权用户。
3. 分析方法概述
常见的分析方法有 CPU 采样 和 跟踪 两种。
3.1 CPU 采样 方法
许多传统的分析工具对系统中所有CPU进行定时采样,以特定的时间间隔或速率(如99Hz)收集当前指令地址(程序计数器)或整个堆栈回溯跟踪的快照。这将给出正在运行的函数或堆栈跟踪的计数,从而可以合理估计 CPU 的时间消耗在哪里。在 Linux 上,工作在采样模式下的 perf 工具(例如,-F 99)执行定时 CPU 采样。
假设应用程序函数 A() 调用函数 B(),而函数 B() 发起一个阻塞的系统调用:
CPU Sampling ----------------------------------------------->
| | | | | | | | | | | |
A A A A B B B B A A A A
A(---------. .----------)
| |
B(--------. .--)
| | user-land
- - - - - - - - - - syscall - - - - - - - - - - - - - - - - -
| | kernel
X Off-CPU |
block . . . . . interrupt
我们看这两行:
| | | | | | | | | | | |
A A A A B B B B A A A A
中间的空白表示程序处于 Off-CPU 状态,也即程序没有在 CPU 上运行,因此期间没有对程序的采样动作进行。
3.2 跟踪 方法
再来看 跟踪 方法:
App Tracing ------------------------------------------------>
| | | |
A( B( B) A)
A(---------. .----------)
| |
B(--------. .--)
| | user-land
- - - - - - - - - - syscall - - - - - - - - - - - - - - - - -
| | kernel
X Off-CPU |
block . . . . . interrupt
在 跟踪 方法中,记录函数 进入 和 结束 两点的时间戳,如此可以计算函数消耗的时间。如果记录的时间戳包括函数的起始时间,以及进入和退出 Off-CPU 状态的时间戳,那样我们可以计算出函数 消耗的总时间、On-CPU 时间、Off-CPU 时间,这是不同于 CPU 采样 方法的。另外,不同于 CPU 采样 方法的是,由于这些时间戳可以达到很高的精度(ns),而 CPU 采样 方法的采样频率不能太高,以免给系统带来额外的负载,这样就有可能漏采一些关键数据。
当然,跟踪 方法也是有它的缺点的,如果你跟踪程序中所有的函数,这可能会带来性能损失;但如果你选择性的跟踪部分函数,就有可能漏过真正需要关注的那些函数。
4. 使用火焰图分析
4.1 On-CPU 分析
On-CPU 是指在 CPU 上执行的状态。即下图中红色圈中的状态:
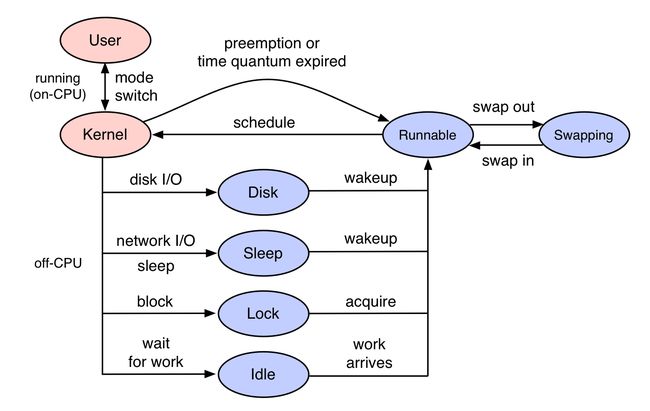
这里介绍使用 CPU 采样 方法来分析 On-CPU 线程状态。确定 CPU 繁忙的原因是一项性能分析的例行任务,这通常涉及分析堆栈跟踪。通过以固定速率采样进行分析是一种粗略但有效的方法,可以查看哪些代码路径很热(CPU 上繁忙)。它通常通过创建一个定时中断来工作,该中断收集当前程序计数器、函数地址或整个堆栈回溯,并在打印摘要报告时将它们转换为人类可读的内容。
采样数据可能长达数千行,并且难以理解。火焰图是采样堆栈跟踪的可视化,可以快速识别热代码路径。请参阅火焰图主页,了解除 CPU 分析之外此可视化的其它用途。
火焰图可以与任何操作系统上的任何 CPU 分析器一起使用。我在本文的例子使用 Linux perf (perf_events) 。
先来看一个 Linux perf 性能分析采样的例子:
# cat /proc/sys/kernel/kptr_restrict 确保次配置为 0 或 1,否则内核符号无法正确显示出来
1
# cat /proc/kallsyms
0000000000000000 A irq_stack_union
0000000000000000 A __per_cpu_start
0000000000004000 A cpu_debug_store
0000000000005000 A cpu_tss_rw
0000000000008000 A gdt_page
0000000000009000 A exception_stacks
000000000000e000 A entry_stack_storage
[...]
ffffffffc0228080 r pacpi_pci_tbl [pata_acpi]
ffffffffc0229480 d __this_module [pata_acpi]
ffffffffc0227414 t cleanup_module [pata_acpi]
ffffffffc0228080 r __mod_pci__pacpi_pci_tbl_device_table [pata_acpi]
# echo -1 > /proc/sys/kernel/perf_event_paranoid
# perf record -F 99 -p 1085 -g -- sleep 30 对进程1085采样,持续 30 秒
# perf report -n --stdio
# To display the perf.data header info, please use --header/--header-only options.
#
#
# Total Lost Samples: 0
#
# Samples: 5 of event 'cpu-clock'
# Event count (approx.): 50505050
#
# Children Self Samples Command Shared Object Symbol
# ........ ........ ............ ........... ..................... ....................................................
#
60.00% 0.00% 0 Xorg [kernel.kallsyms] [k] entry_SYSCALL_64_after_hwframe
|
---entry_SYSCALL_64_after_hwframe
do_syscall_64
|
|--20.00%--sys_epoll_wait
| ep_poll
| schedule_hrtimeout_range
| schedule_hrtimeout_range_clock
| schedule
| __schedule
| finish_task_switch
|
|--20.00%--sys_writev
| do_writev
| vfs_writev
| do_iter_write
| do_iter_readv_writev
| sock_write_iter
| sock_sendmsg
| unix_stream_sendmsg
| sock_def_readable
[...]
如果采样时间长,或采样数据较多,perf report 报告的数据将多得没法看,这时候就需要对采样数据做一步处理,本篇讨论的火焰图就是一种将采样数据转换成容易查看的可视化方法。接下来看如何将采样数据转换成火焰图。在此之前,需要先到 此处 或 此处 下载 Brendan Gregg 编写的 FlameGraph 脚本工具,然后解压。
# perf script | ./FlameGraph-master/stackcollapse-perf.pl > out.perf-folded
# ./FlameGraph-master/flamegraph.pl out.perf-folded > perf.svg
通过上面的操作,最终生成了 SVG 格式的火焰图 perf.svg 。如下:

CSDN 博客不支持 SVG 格式,只能截图放在这里,想查看原图可去往 此处 。火焰图的内容很容易理解,显示是调用栈柱状图,最顶上函数是栈的顶部;函数名的宽度表示在采样数据中出现频次更高,也即代码热路径。
我们例子中使用了额外的辅助脚本 stackcollapse-perf.pl ,将采样数据中的函数名转换为基于行的输出。在更高版本的 perf 和 eBPF 中,已经集成了对火焰图的支持,不再需要辅助脚本 stackcollapse-perf.pl 。如可以通过 perf reprot 命令来生成 out.perf-folded :
# perf report --stdio --no-children -n -g folded,0,caller,count -s comm | awk '/^ / { comm = $3 } /^[0-9]/ { print comm ";" $2, $1 }' > out.perf-folded
此外,还可以通过 grep 之类的命令过滤我们感兴趣函数,然后生成火焰图:
# grep -v cpu_idle out.perf-folded | ./FlameGraph-master/flamegraph.pl > nonidle.svg
生成的过滤掉 cpu_idle 的火焰图见 此处 。
4.2 Off-CPU 分析
Off-CPU 是指不在 CPU 上运行的状态,包括在运行队列、阻塞睡眠等状态,即下图中的蓝色圈中的状态:
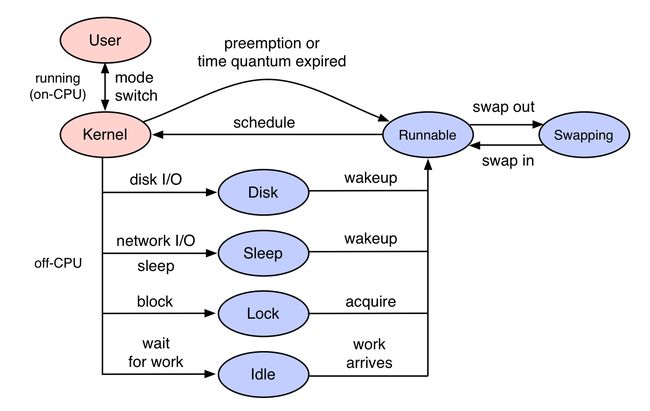
系统在 /proc 目录下导出了线程 Off-CPU 时间统计数据。Off-CPU 加上 On-CPU 时间,就是线程占用的所有 100% 的时间。线程可能出于多种原因离开 CPU,包括 I/O 和锁,但也有一些与当前线程的执行无关的原因,包括由于对 CPU 资源的高需求而导致的非自愿上下文切换和中断。无论出于何种原因,如果在工作负载请求期间发生这种情况,则会引入延迟。
Off-CPU 分析需要堆栈追踪记录,很多应用程序使用 GCC 的编译选项 -fomit-frame-pointer 进行编译,这样会导致基于栈帧指针的栈回溯的失败;而想 Java VM 等在运行时进行编译,在没有额外辅助的情形下,追踪工具无法程序的符号信息,栈记录将显示为符号地址。这些情形可参考 Stack Traces 和 JIT Symbols 进行处理。
为了说明 Off-CPU 的作用,先来对比下 Off-CPU 的 CPU 采样 和 跟踪 两种方法。
4.2.1 Off-CPU 两种分析方法对比
我们将对 Off-CPU 分析方法再细分为 Off-CPU 跟踪 和 Off-CPU 采样 两小类方法。我们先看 Off-CPU 跟踪 方法:
Off-CPU Tracing -------------------------------------------->
| |
B B
A A
A(---------. .----------)
| |
B(--------. .--)
| | user-land
- - - - - - - - - - syscall - - - - - - - - - - - - - - - - -
| | kernel
X Off-CPU |
block . . . . . interrupt
使用此方法,仅跟踪将线程切换为 Off-CPU 状态 的内核函数,以及时间戳和用户空间堆栈跟踪。这侧重于 Off-CPU 事件,无需跟踪所有应用程序功能,也不需要知道应用程序是什么。这种方法适用于任何阻塞事件,任何应用程序:MySQL,Apache,Java 等。即:
【Off-CPU 跟踪方法】跟踪捕获所有应用程序的所有等待事件。
我们应该注意的是,Off-CPU 跟踪方法 可能引入可观的开销,因为调度事件是非常频繁的,极端情况下,每秒可能有数百万次的调度事件发生。
再来看 Off-CPU 采样 方法:
Off-CPU Sampling ------------------------------------------->
| | | | | | |
O O O O O O O
A(---------. .----------)
| |
B(--------. .--)
| | user-land
- - - - - - - - - - syscall - - - - - - - - - - - - - - - - -
| | kernel
X Off-CPU |
block . . . . . interrupt
此方法使用定时采样当前没在 CPU 上运行的线程的调用栈。Off-CPU 采样 方法极少被系统采用工具使用。
Off-CPU 采样 方法同样也会存在开销问题,因为系统可能有数百万个线程需要不断采样。
要使用 Off-CPU 方法(不管是跟踪还是采样),都要注意开销,将每分钟数以GB的采样数据转储到用户空间后再处理(如 perf),已经足以让人望而生畏。这就是那些为减少 Off-CPU 实践开销,而生成内核摘要的追踪工具(如 eBPF),为什么如此重要了的原因了。还要注意到,追踪工具自身引发的 Off-CPU 事件反馈循环。来看一个 Brendan Gregg 提供的实际例子来直观感受下,数据转储 和 内核摘要 两种处理形式带来的差异:
为了让您了解开销,我测试了一个运行 Linux 4.15 的 8 CPU 系统,MySQL 负载很重,每秒导致 102k 上下文切换。刻意让
服务器在 CPU 饱和状态下运行(0% 空闲),因此任何跟踪器开销都会导致应用程序性能明显下降。然后,我将通过调度程序
跟踪进行的 CPU 外分析与 Linux perf 和 eBPF 进行了比较,它们演示了不同的方法:使用事件数据转储的 perf 和 使用
内核摘要汇总的 eBPF:
. 使用 perf 跟踪每个调度器事件,会导致跟踪时的吞吐量下降 9%,在将 perf.data 捕获文件刷到磁盘时,偶尔会下降 12%。
该文件在 10 秒的跟踪中最终达到 224 MB。然后通过运行 perf 脚本对文件进行后处理以执行符号转换,这会导致 13% 的性
能下降,持续 35 秒。你可以将这些总结为:10 秒的性能跟踪在 45 秒内花费了 9-13% 的开销。
. 相反,使用 eBPF 对内核上下文中的堆栈进行计数,会导致 10 秒跟踪期间吞吐量下降 6%,从初始化 eBPF 时 1 秒下降 13%
开始,然后是 6 秒的后处理(已汇总堆栈的符号解析),成本下降 13%。因此,10 秒的跟踪会在 17 秒内花费 6-13% 的开销。
这比 perf 要好多了。
如果在上述基础上,再加长跟踪时间,会发生什么?对于 eBPF,它只是捕获和解析堆栈,所以开销不会随跟踪持续时间变长而线性增长。 Brendan Gregg 通过将跟踪时间从 10 秒增加到 60 秒来测试这一点,这只会将 eBPF 后处理从 6 秒增加到 7 秒。而如果同样的,perf 的追踪时间也从 10 秒增加到 60 秒,其后处理时间将从 35 秒增加到 212 秒,因为它需要处理 6 倍的数据量。
4.2.2 生成 Off-CPU 火焰图
我们以 Linux 系统为例,来说明怎么进行 Off-CPU 分析。Linux 上有许多跟踪器可用于 Off-CPU 分析。在这里首先使用 perf 来说明。
# perf record -e sched:sched_stat_sleep -e sched:sched_switch \
-e sched:sched_process_exit -a -g sleep 1
# perf script -F comm,pid,tid,cpu,time,period,event,ip,sym,dso | \
awk 'NF > 4 { exec = $1; period_ms = int($5 / 1) }
NF > 1 && NF <= 4 && period_ms > 0 { print $2 }
NF < 2 && period_ms > 0 { printf "%s\n%d\n\n", exec, period_ms }' | \
./FlameGraph-master/stackcollapse.pl | \
./FlameGraph-master/flamegraph.pl --countname=ms --title="Off-CPU Time Flame Graph" --colors=io > offcpu.svg
生成冰焰图效果如下:
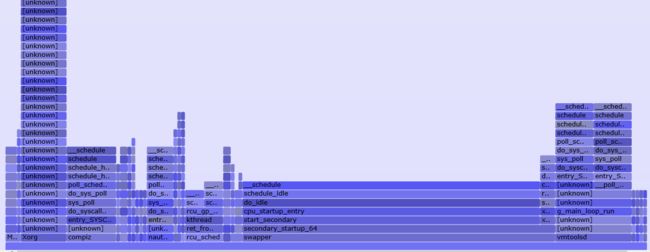
原图见 此处 。
另外,我么也给出一个 eBPF 示例,eBPF 可以轻松地对堆栈跟踪和时间进行内核内摘要。eBPF 是Linux内核的一部分,我将通过 bcc 前端工具使用它。这些至少需要 Linux 4.8 才能支持堆栈跟踪。
我们在 Ubuntu 16.04.4 LTS 下运行 bcc ,系统下默认没有 bcc ,需要先安装:
# offcputime-bpfcc -f -p 1809 30 > out.stacks
# ./FlameGraph/flamegraph.pl --color=io --title="Off-CPU Time Flame Graph" --countname=us < out.stacks > out.svg
Off-CPU 分析是查找线程阻塞和等待事件这些类型的原因而造成延迟的有效方法。通过从上下文切换线程的内核调度程序函数中跟踪这一点,可以以相同的方式分析所有 Off-CPU 类型延迟,而无需跟踪多个源。要查看 Off-CPU 事件的上下文以了解其发生原因,可以检查用户和内核堆栈回溯跟踪。
通过 CPU 采样分析(On-CPU 分析) 和 Off-CPU 分析,你可以全面了解线程花费时间的位置。On-CPU 分析 和 Off-CPU 分析 是互补的。
5. 参考资料
https://brendangregg.com/flamegraphs.html
https://brendangregg.com/FlameGraphs/cpuflamegraphs.html
https://brendangregg.com/offcpuanalysis.html
https://www.brendangregg.com/blog/2015-02-26/linux-perf-off-cpu-flame-graph.html