Python的数据类型
文章目录
-
- 数据类型
- Python 数据类型
- Python 数据结构
- 举例
-
- 原子
- 结构
- Python 有趣特点
数据类型
数据类型 是一组性质相同的值的集合与定义在此集合上的一组操作的总称,相似的有概念还有 数据结构 是一个数据元素与数据元素间关系的集合,两者定义接近,通俗的说 数据类型 关心数据的种类而 数据结构 关心数据的构造,像是一对想法不同的亲兄弟
不严谨的定义
数据类型 = 同质数值 + 处理方式
有三类
原子类型 = 值不可分数据类型
结构类型 = 值可再分数据类型
抽象数据类型 = 数据对象 + 数据关系 + 基本操作
其中
结构类型 = 原子类型一 + 原子类型二 + … + 原子类型某某
不严谨的定义
数据结构 = 逻辑结构 + 存储结构 + 数据操作
值得注意,数据结构可以被抽象数据类型定义,兜底定义就是牛逼,抽象就完事了
不严谨的连结
结论
可以发现数据类型更加抽象以至于能够定义中顺带定义数据结构;但是也明显可以发现两者不等价,因为数据类型丝毫不关心物理世界的实现而数据结构需要描述清楚
Python 数据类型
-
Python 中有六个标准数据类型1. 数字 Number 2. 字符串 String 3. 列表 List 4. 元组 Tuple 5. 字典 Dict 6. 集合 Set
其中 数字 Number 和 字符串 String 是基本的数据类型
其中 数字 Number 和 字符串 String 与 元组 Tuple 是不可变数据类型
其中 列表 List 和 字典 Dictionary 与 集合 Set 是可变数据类型
# 不可变与可变数据类型,顾名思义内容能否改变,主要标志在于:
# 改变变量的内容后,是变量指向的内存地址改变还是变量指向的内存地址的内容改变
# 1,不可变数据类型,改变值时,开辟一个新的内存空间,变量指向新的内存空间的地址,变量表示新的数据
a = '123'
id(a)
2246064939504
a = a + '4'
id(a)
2246069673352
# 2,可变数据类型,改变值时,在原内存空间上修改数据,变量指向内存空间的地址不变,变量表示修改数据
a = [1,2,3]
id(a)
2246068878088
a.append(4)
id(a)
2246068878088
其中 字符串 String 和 列表 List 与 元组 Tuple 是可偏移量索引数据类型
其中 字典 Dictionary 是可键值索引数据类型
其中 集合 Set 是不可索引数据类型
Python 数据结构
-
Python 中有三类主要的数据结构1,序列 字符串 String 列表 List 元组 Tuple 2,散列 字典 Dict 3,集合 集合 Set
举例
原子
一,数字 Number
A,整型 int
# 定义整型变量
# 直接
var = 22
# 生成式
var = int(22)
# Out: 22
var = int('0b10110',2)
# Out: 22
var = int('0o26', 8)
# Out: 22
var = int('0x16', 16)
# Out: 22
# 相应的
# 二进制
var = bin(22)
# Out: '0b10110'
# 八进制
var = oct(22)
# Out: '0o26'
# 十六进制
var = hex(22)
# Out: '0x16'
B,浮点型 float
# 定义浮点型变量
# 直接
var = 3.1415926
# 生成式
var = float(3.1415926)
# Out: 3.1415926
C,布尔型 bool
# 定义布尔型变量
# 直接
var = False
# 生成式
var = bool(0)
var = bool('')
# Out: False
# 其它 var = bool(everything),Out: True
D,复数 complex
# 定义复数变量
# 直接
var = 2 + 2j
# 生成式
var = complex(2, 2)
# Out: 2 + 2j
二,字符串 String
当定义包含引号的字符串变量时,使用与包含引号相异的引号定义三引号与双三引号通常用于多行注释
# 定义字符串变量
# 单引号
var = '针不戳'
# 双引号
var = "针不戳"
# 三引号
var = '''针不戳'''
# 双三引号
var = """针不戳"""
# 生成式
var = str('argument')
# 最多输入一个参数
# 可以是任意六种标准数据类型
# 字符串变量是一个向量,可以通过序号索引,切片索引访问字符串变量中的元素
字符串变量中 \ 常常作为转义符(非字符串中充当续行符),与特定对象组合表达额外含义
'''
# 默认转义
\\ 反斜杠符号(\)
\' 单引号
\" 双引号
# ASCII码特殊字符
\a 响铃
\b 退格(backspace)
\n 换行
\v 纵向制表符
\t 横向制表符
\r 回车
\f 换页
'''
结构
三,列表 List
定义
# 直接定义列表
var = ['wh', 'zl', 'yzh', 'zhb', 666]
# 生成式,最多输入一个参数,可以是任意六种标准数据类型
var = list('argument')
# 推导式,可从左往右嵌套使用 for 与 if,使用 () 包裹返回列表生成器,而使用 [] 包裹将得到列表
var = [i for i in range(10) if i % 2 == 0]
var = [i2 for i1 in [[1, 2], [3, 4]] for i2 in i1 if i2 % 2 == 0]
访问
# 直接访问列表中元素,通过序号索引 var[index] 不得超出元素数范围;通过切片索引 var[start:end:gap] 其中 end 值越界则视为 len(var);间接访问列表中元素,可通过 in 判断是否存在
var = ['wh', 'zl', 'yzh', 'zhb', 666]
var[2]
# Out: 'yzh'
var[0:4:2]
# Out: ['wh', 'yzh']
"wh" in var
# Out: True
增删改查
# 列表取反
var.reverse()
# 列表组合
var1 + var2
# 重复列表 n 次
var1 * n
# 列表末尾添加元素
var.append('真不戳')
# 列表末尾添加可迭代对象,将其中的元素逐个加入列表中
var.extend([5, 2, 0])
# 列表插入元素
var.insert('真不戳')
# 删除列表中第一个匹配元素
var.remove()
# 移除列表指定下标处的元素(默认移除最后一个元素)
var.pop()
# 清除列表
var.clear()
# 列表元素索引查找,返回第一个匹配元素
var.index("wh")
# 列表元素频数统计
var.count("wh")
# 列表长度
len(var)
# 列表最大值,子对象数据类型数字或字符串(字符串则是比较 ASCII 值)
max(var)
# 列表最小值,子对象数据类型数字或字符串(字符串则是比较 ASCII 值)
min(var)
# 列表求和,子对象数据类型数字
sum(var)
# 列表顺序排列,子对象数据类型数字或字符串(字符串则是比较 ASCII 值)
var.sort()
# 列表倒序排列,子对象数据类型数字或字符串(字符串则是比较 ASCII 值)
var.sort(reverse=True)
四,元组 Tuple
定义
# 直接定义元组,必须包含一个逗号,若元组是更大表达式中的一部分则必须包含圆括号,元组是一个「不变」的列表,一旦创建其中各个元素的地址便不能改变
var = ('wh', 'zl', 'yzh', 'zhb', 666)
var = 'wh', 'zl', 'yzh', 'zhb', 666
var = (666,)
# 生成式,最多输入一个参数,可以是任意六种标准数据类型
var = tuple('argument')
访问
# 访问元组中元素,与访问列表变量类似可以索引、切片与判存
增删改查
# 元组没有增、删、改的方法但是可以查询;可以改变元组中的可变对象的元素从而实现间接改变元祖元素
var.index("wh")
var.count("wh")
# 可以组合元组
var1 + var2
# 重复元组 n 次
var1 * n
五,字典 Dict
# 直接定义字典
var = {'wh':22, 'zl':22, 'yzh':22, 'zhb':22, 211:666, ('针不戳','又拉了'):'那可不'}
# 生成式, 键与值可以是字符串,数字,元组,其中建必须唯一且可哈希的对象
var = dict('key' = 'value')
# 推导式,使用 {} 包裹 for 与 if 得到字典,可便捷反换 value 与 key 间位置
var = {key: value for key, value in zip(list1, list2) if value > number}
var = {value: key for key, value in dict.items()}
var = {diction[key]: key for key in diction}
访问
# 访问字典中元素,通过键索引返回值,不存在将报错
var['wh']
# Out: 22
# 访问字典键是否存在,存在返回 True 不存在返回 False
'wh' in var
# Out: True
# 访问字典中元素,通过键索引返回值,不存则返回 None
var.get('hm')
# Out: None
# 访问字典中元素,通过键索引返回值,不存则返回 None,并把当前键值写入字典
var.setdefault('hm')
# Out: None
Python3 中加入了 OrderedDict,一种有序字典,可以记住元素插入顺序并按顺序输出。但若有序字典中的元素一开始就定义好了,没有插入元素这一动作,那么遍历有序字典,其输出结果仍然是无序的,所以有序字典一般用于动态添加并需要按添加顺序输出的时候。Python3.6 字典已经默认有序了
增删改查
# 增加字典元素,可通过不存在的键索引添加或者已存在的键索引修改或使用字典方法
var['wyq'] = 22
var = {'wh':22, 'zl':22, 'yzh':22, 'zhb':22, 211:666, ('针不戳','又拉了'):'那可不', 'wyq':22}
# 删除字典中元素
del var["wh"]
# 查找字典中元素
var["wh"]
# 修改字典中元素
var["wh"] = 66
# 返回键
var.keys()
# 返回值
var.values()
# 转换为可遍历的字典项目项目对象
var.items()
# 键值对个数
len(var)
六,集合 Set
# 直接定义集合
var = {'wh', 'zl', 'yzh', 'zhb', 666}
# 生成式,最多输入一个参数,可以是任意六种标准数据类型
var = set(argument)
# 推导式,使用 {} 包裹 for 与 if 生成,自动去除重复元素
var = {abs(x) for x in [1, -1, 0, 2, -2] if x != 0}
访问
集合的元素无序,通过序号索引访问不被允许,集合是可迭代的,for 可遍历访问,可以通过 in 判断元素是否存在,可转换为列表而间接访问
增删改查
# 添加元素
var.add(item)
# 必须添加可迭代对象,将其中的元素逐个加入集合中
var.updata(item)
# 删除元素
var.remove(item)
# 存在则删除元素
var.discard(item)
# 元素出栈
var.pop()
# 清空
var.claer()
# 浅拷贝
var.copy()
# 交集
var1 & var2
var1.intersection(var2)
# 并集
var1 | var2
var1.union(var2)
# 差集,找出前集合而后集合无的元素
var1 - var2
var1.difference(var2)
# 对称差分集,找出不同属于两个集合的元素
var1 ^ var2
var1.symmetric_difference(var2)
# 子集
var1 < var2
var1.issubset(var2)
# 超集
var1 >= var2
var1.issuperset(var2)
# 两个集合是否不包含相同元素
var1.isdisjoint(var2)
Python 有趣特点
1. Python 是解释性的语言,也可以事先预编译
- 一些重用的模块会被事先编译成 Pyc 文件储存机器可执行语言,其它部分在运行时逐行解释成机器可执行语言,整个过程是从上到下循序渐进的
2. Python 的数据很灵活,大多数时候不同数据类型之间可以直接进行的转换,但在进行与字典有关的数据转换时需要先使用 .items() 方法中继,否则只会保留 key 而失去 value
3. Python 文件命名可以使用数字,字母,下划线甚至是中文任意组合
- 但是当一个 Python 文件作为模块导入到另一个 Python 文件时,作为模块的 Python 文件不能用数字开头命名,能用下划线和字母开头
4. Python 变量名可以使用数字,字母,下划线任意组合,变量名一个下划线后缀通常用于避免关键字冲突
- 在 Python 中变量不能用数字开头,能用下划线和字母开头,变量名没有数据类型与结构,仅是一个对象的指针。在类中是通常 单下划线 开始的成员变量叫做保护变量,只有类对象和子类对象自己能访问到这些变量,而 双下划线 开始的是私有成员,只有类对象自己能访问,开头与后缀各 两下划线 是系统内建的一些变量或方法,不建议用户重载;对于包中的模块或函数,单下划线 开始表示私有避免 import * 导入,单下划线 结束的函数与方法通常是为了表明 in-place 属性即不新建对象直接在原对象上修改内容
5. Python 可以对数据进行赋值、浅拷贝与深拷贝
-
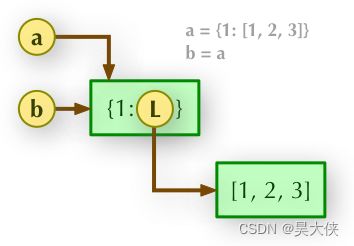
赋值 a={1:[1,2,3]} b=a 用变量 a 给变量 b 赋值就是给 a 指向的对象增加一个别名 b(a 与 b 的地址相同)
-
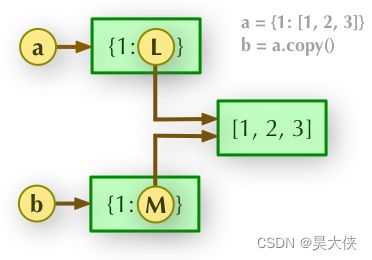
浅拷贝 a={1:[1,2,3]} b=a.copy() 表面上 a 与 b 都是指向独立的对象(a 与 b 的地址不同),但是内部的子对象中的可变元素仍指向同一地址
-
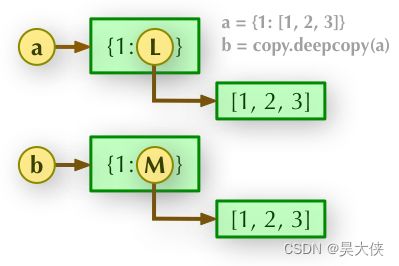
深拷贝 a={1:[1,2,3]} b=copy.deepcopy(a) 此时 a 与 b 是两个完全独立的对象
6. 创建 Python 文件会自动加载内建变量 name 用于标识
- 例如 Python 文件 a 直接运行时, Python 文件 a 的内建变量 _name_ = ‘_main_’ ,当 Python 文件 a 被另一个 Python 文件 b 调用运行时, 在两者组成的程序中 Python 文件 a 中内建变量 _name_ = ‘a’ ,Python 文件 b 的内建变量 _name_ = ‘_main_’ ,因此当我们写代码时通常用 if _name_ = ‘_main_’: 作为程序入口