C++-c语言词法分析器
一、运行截图
- 对于 Test.c 的词法分析结果
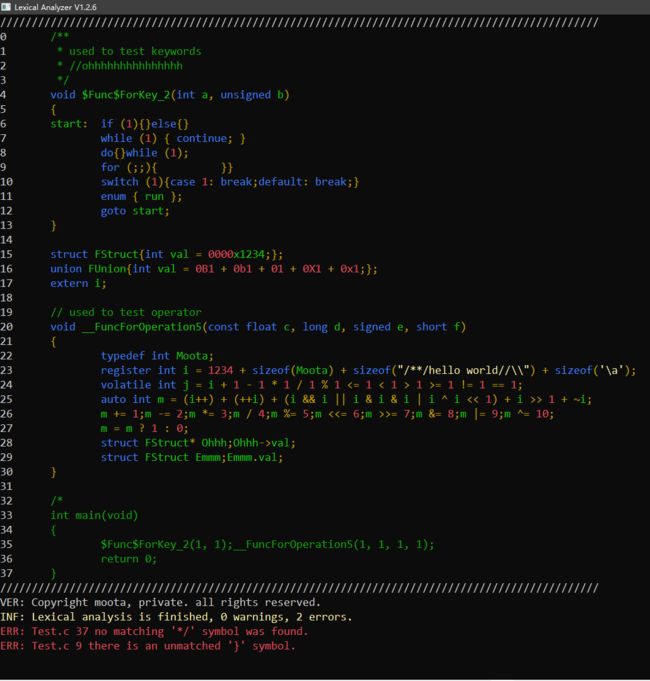
- 对于词法分析器本身的源代码的分析结果
二、主要功能
经过不断的修正和测试代码,分析测试结果,该词法分析器主要实现了以下功能:
1. 识别关键字
- 实验要求:if else while do for main return int float double char。以及:
- 数据类型关键字 void unsigned long enum static short signed struct union;
- 控制语句关键字 continue break switch case default goto;
- 存储类型关键字 auto static extern register;
- 其他关键字 const volatile sizeof typedef;
- 预编译指令 #xxx。
2. 识别运算符
- 实验要求:= + - * / % < <= > >= != ==
- 算术运算符 ++ –
- 逻辑运算符 && || !
- 位运算符 & | ^ ~ << >>
- 赋值运算符 += -= *= /= %= <<= >>= &= ^= |=
- 杂项运算符 , ? : -> .
3. 识别界限符
- 实验要求:; ( ) { }
- 其他:[ ]
4. 识别常量
- 实验要求:无符号十进制整型常量,正规式为:(1-9)(0-9)*
- 无符号二进制整型常量,正规式为: 0(B|b)(0-1)*
- 无符号八进制整型常量,正规式为: 0(0-7)*
- 无符号十六进制整型常量,正规式为: 0(X|x)(0-9|a-f|A-F)*
- 字符串常量,正规式为: “(all char)*”
- 字符常量,正规式为: ‘(all char)*’
5. 识别标识符
- 实验要求:以字母开头,正规式为:letter(letter|digit)*
- 以下划线开头,正规式为:_ (letter|digit|$ | _) *
- 以美元符号开头,正规式为:$ (letter|digit|$ | _ ) *
6. 识别其他符号
- 实验要求:空格符(’ ‘),制表符(’\t’),换行符(‘\n’)
- 单行注释(“//”)
- 多行注释(“/*”)
- 转义字符(‘\’)
特别的,在预处理阶段,识别单/多行注释时,遇到了一个小问题,由于要支持字符串常量和字符常量,而该常量中可能包含//,/*,导致将字符串内容识别为注释,另外,由于需要支持转义字符‘\’的存在,正确识别的字符串,也成为了一大问题,在多次修改匹配代码后,终于将问题解决。
7. 词法高亮
利用词法分析的token结果,按不同的类型码,对源代码文件进行着色输出。
运算符和界限符:黄色。
关键字:淡蓝色。
无符号二,八,十,十六进制整型常量:淡红色。
标识符:淡绿色。
字符串常量:淡黄色。
8. 词法错误处理
当朴素匹配或者正规匹配失败,或者匹配结束后,回退字符之前,出现非法字符时,对相应的错误进行记录并在分析完毕后进行输出。
目前已处理错误:未找到匹配的界限符()]}),多行注释未找到结束符(*/),出现未定义的字符(@¥`)。
值得注意的一点,当遇到未处理的词法错误时,程序存在可能的崩溃隐患。
三、项目内容
1. 测试代码 Test.c
/**
* used to test keywords
* //ohhhhhhhhhhhhhhh
*/
void $Func$ForKey_2(int a, unsigned b)
{
start: if (1){}else{}
while (1) { continue; }
do{}while (1);
for (;;){ }}
switch (1){case 1: break;default: break;}
enum { run };
goto start;
}
struct FStruct{int val = 0000x1234;};
union FUnion{int val = 0B1 + 0b1 + 01 + 0X1 + 0x1;};
extern i;
// used to test operator
void __FuncForOperation5(const float c, long d, signed e, short f)
{
typedef int Moota;
register int i = 1234 + sizeof(Moota) + sizeof("/**/hello world//\\") + sizeof('\a');
volatile int j = i + 1 - 1 * 1 / 1 % 1 <= 1 < 1 > 1 >= 1 != 1 == 1;
auto int m = (i++) + (++i) + (i && i || i & i & i | i ^ i << 1) + i >> 1 + ~i;
m += 1;m -= 2;m *= 3;m / 4;m %= 5;m <<= 6;m >>= 7;m &= 8;m |= 9;m ^= 10;
m = m ? 1 : 0;
struct FStruct* Ohhh;Ohhh->val;
struct FStruct Emmm;Emmm.val;
}
/*
int main(void)
{
$Func$ForKey_2(1, 1);__FuncForOperation5(1, 1, 1, 1);
return 0;
}
2. 项目代码 LexicalAnalyzer.cpp
/** Copyright Moota, Private. All Rights Reserved. */
#include