Flink处理大型离线任务稳定性与性能调优探索
Apache Flink作为分布式处理引擎,用于对无界和有界数据流进行状态计算。其中实时任务用于处理无界数据流,离线任务用于处理有界数据。
通过本文你将掌握让大型离线任务运行稳定的能力,同时能够通过分析离线任务运行特点,降低任务运行资源消耗,减少任务成本。
下面我们进入正题:
01
—
离线任务情况说明
对于平台处理的离线任务,任务大都是处理:从HDFS到HIVE的数据清洗任务。这类任务的特点是数据来一条处理一条,所以任务大都是没有状态的。
看一个任务
source: 301个文件,每个文件9.6G(压缩后的大小),总共大约240亿条数据
trans:对于每条数据通过正则去获取目标数据。
资源配置:301并发、tm:<10core、10slots、15G>、jm: 10core、8G内存。那将会产生32个container(运行在yarn中)。
任务运行的速度大概在1.2亿/min,运行2小时50多分钟。但是任务会偶发的报hadoop集群的问题,如下报错
connection reset by peer
EOFException: End of File Exception以至于后面这个任务少了几天数据,任务都跑不下去。但其他类似的任务运行的很稳定,“事出反常必有妖”:
本文尝试从内存、并发的角度分析任务的稳定性及任务运行速度等问题。
02
—
相关理论
1. Task Slots and Resources
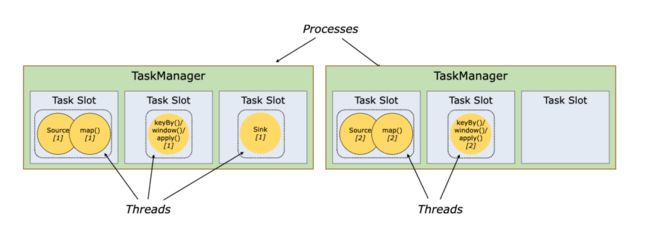
通过阅读官网,我们可以了解到:
1. taskmanager是一个jvm进程,一个taskmanager可能执行一个或多个subtask在各自的线程(slot)中。
2. taskmanager的(托管)内存资源会根据slot的数量而分开,但是tm中的 TCP(通过多路复用)连接、心跳消息、共享数据集、数据结构和cpu资源各slot会共享。
所以我们可以设置多个slot 在一个tm中,来实现资源共享,但是一个tm中设置几个slot合适呢?我们先带着疑问接着往下看。
2. 建议cpu和slot数关系
stack overflow 对于 Ideal Number of Task Slots,有一些建议:
As a rule-of-thumb, a good default number of task slots would be the number of CPU cores. With hyper-threading, each slot then takes 2 or more hardware thread contexts.
即:有超线程的机器可以建议设置:numOfslots = 2 * numOfcores ,没有超线程的机器建议设置:numOfslot = numOfcore。
3. tm的资源配置是否合适
目前配置的tm是:10core、10slot、15G,但是跑上述任务时,任务不稳定,这里在stack overflow 也找到了类似的问题:
![]()
We’ve frequently run into problems where, with multiple hosts running one large task manager a piece, all jobs get scheduled to one host, which can cause load problems.
![]()
当多个主机(tm)同时运行一个大型任务管理器时,所有作业都被调度到一个主机上,这可能会导致负载问题。
也给出了相应解答:
![]()
We ended up making multiple smaller task managers per host and jobs seem to be distributed better (although they still cluster on one node often).
![]()
在每个主机上创建了多个较小的任务管理器,并且作业似乎可以更好地分布(尽管它们仍然经常聚集在一个节点上)。
简单地总结上面的经验就是:调小tm的资源(cpu和memory),作业可以更好地分布。
4. 阿里对于TaskManager资源配置建议
TaskManager资源设置不宜过小,也不宜过大:
1. 如果单个TaskManager资源过小,则可能影响其上作业的稳定性,并且由于其Slot数目不多,无法有效平摊TaskManager的开销,降低了资源的利用效率。
2. 如果单个TaskManager资源过大,则TaskManager上运行的作业数会很多,一旦TaskManager发生单点故障,影响面会很大。
从阿里给出的建议我们可以得出:
当tm设置的资源过大时,遇到单点问题影响面很大。目前看在部署taskmanager <10core,15G> 时,tm资源设置的大了,造成的单点故障的概率提高。
03
—
问题分析与解决
总体的调整思路
1. 目前<10core,15G> 的设置导致当任务规模到达一定水平时任务运行的将变得不稳定,所以这里调小Tm的
2. 因为任务是IO密集型,所以可以考虑1个cpu对应多个slot个数,这里Flink建议是2倍,但需要测试。
3. 当减小每个Tm的资源时,Tm的个数将会增加。在相同任务下,这时需要考虑Jobmanager的调度压力和管理压力,是否对任务运行的稳定性和效率有所影响。
测试结果对比
任务1
![]()
source: 301个文件,每个文件9.6G(压缩后的大小),总共大约240亿条数据
trans:对于每条数据通过正则去获取目标数据。
![]()

现在从3个方面讨论任务运行的情况:
速度:
从第2,3,5运行结果对比:可以看出yarn集群对于1core支持多并发的速度没有达到超线程效果、或对于hdfs到hive的io密集型任务没有收获很好的效果;
从第4运行结果看出:当1core 对应 4并发时,速度下降接近一半;
内存使用与资源共享:
从5、6运行结果对比看出:随着一个tm的slot数的增多,速度有所提升(提升不高),这里可以暂时认为是tm内的 TCP连接、心跳消息、共享数据集、数据结构和cpu资源等起到了共享的作用。
从7、8、9运行结果对比:可以看出运行速度基本都到了最高峰,此时tm的共享、内存的提高均没有提升Flink的运行速度。
稳定性:
从9运行结果:可以看出运行速度达到了最快,且多次运行后都能稳定运行完。
任务2
![]()
数据源: 有1000多个文件,每个文件1G(压缩后的大小)总共大约4.5亿条
数据处理:对于每条数据通过正则去获取目标数据。
![]()
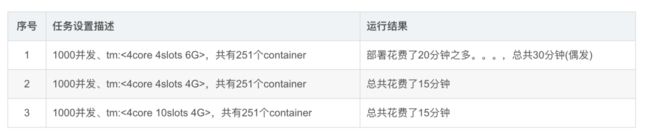
从1,2可以看出因为我们的任务是无状态的,内存的提升并没有提高运行效率,且增加了yarn部署container的负担。
1000并发下提高slots与core的比,速度也没有发生变化,可能是因为jm调度效率提升,资源共享状况提升,弥补了单线程cpu的运行效率。
任务3
![]()
数据源: 有1000多个文件,每个文件十几k,总共大约320万条数据
数据处理:对于每条数据通过正则去获取目标数据。
![]()

对于一个文件数特别多但文件都很小的情况下,我这里在相同cores下提高slot数(并发),那在相同任务并发的情况下,task的数量将减少:
![]()
这样设置会增加tm资源共享的能力,一批数据运行完之后调度的时间变短。假设每次仅通过一次拉取数据就能处理完一个文件,即在调高slot数量之后,处理速度还高于Flink“单次”处理数据速度峰值,这样总的处理时间将会和原来差不多或者更短。
![]()
04
—
离线任务性能调优小结
1. 任务稳定性
Tm任务的配置不能太大<10core 10slots 15G>,为了保证稳定调小到<4core …> ,之前启动大于100个tm时,任务就开始运行不稳定易导致HDFS集群问题,或flink内部通讯问题,现在运行250个后还可以稳定运行。
2.(IO型任务)运行效率取舍
a. 当单个文件很大时(9.6G/1G:43万条),需要处理速度峰值,此时需要numOfCores = numOfslots,速度将达到1.2亿/min
b. 当单个文件很小时十几kb(不到100条一个文件),这时更在意调度的效率以及Tm中资源共享的能力,即:单位时间内有更多slot去处理任务。此时可以设置numOfcores = n * numOfslots,随着n的提高,处理速度有所下降,但因为一个tm中slot的增多,jm的调度能力提高。
3. 内存瘦身
对于没有状态(来一条处理一条)的离线任务,内存的使用要求没有那么强,之前nCores=1.5nG 可以调整为 numOfcores=numOfMemory。
一方面节约资源,对于1000并发的任务,内存可节约0.5*1000=500G的内存;另一方面yarn在调度container时压力也会变小。
