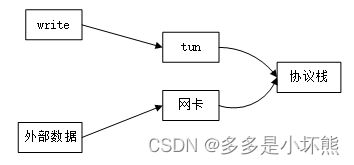
tun驱动之write
tun的write执行类型下面的代码
int fd = open("/dev/net/tun", O_RDWR)
write(fd, buf, len);
首先要明确一点,向tun驱动写的数据,最后会进入网络协议栈,相当于外部的数据通过网卡进入网络协议栈。所以写入tun驱动的数据,会放到cpu中的input_pkt_queue队列。
一 软中断启动
要想把数据发送将清除,软中断是绕不过去的。因为tun驱动,没有对应的硬件设备,所以不会产生硬中断。
软中断的初始化函数是spawn_ksoftirqd,在函数中注册了软中断处理线程softirq_threads。
static struct smp_hotplug_thread softirq_threads = {
.store = &ksoftirqd,
.thread_should_run = ksoftirqd_should_run,
.thread_fn = run_ksoftirqd,
.thread_comm = "ksoftirqd/%u",
};
static __init int spawn_ksoftirqd(void)
{
cpuhp_setup_state_nocalls(CPUHP_SOFTIRQ_DEAD, "softirq:dead", NULL,
takeover_tasklets);
BUG_ON(smpboot_register_percpu_thread(&softirq_threads));
return 0;
}
在smpboot_register_percpu_thread中调用了smpboot_register_percpu_thread_cpumask:
int smpboot_register_percpu_thread_cpumask(struct smp_hotplug_thread *plug_thread,
const struct cpumask *cpumask)
{
unsigned int cpu;
int ret = 0;
if (!alloc_cpumask_var(&plug_thread->cpumask, GFP_KERNEL))
return -ENOMEM;
cpumask_copy(plug_thread->cpumask, cpumask);
get_online_cpus();
mutex_lock(&smpboot_threads_lock);
for_each_online_cpu(cpu) {
ret = __smpboot_create_thread(plug_thread, cpu);
if (ret) {
smpboot_destroy_threads(plug_thread);
free_cpumask_var(plug_thread->cpumask);
goto out;
}
if (cpumask_test_cpu(cpu, cpumask))
smpboot_unpark_thread(plug_thread, cpu);
}
list_add(&plug_thread->list, &hotplug_threads);
out:
mutex_unlock(&smpboot_threads_lock);
put_online_cpus();
return ret;
}
遍历系统中的每个cpu,调用__smpboot_create_thread创建软中断处理线程:
static int
__smpboot_create_thread(struct smp_hotplug_thread *ht, unsigned int cpu)
{
struct task_struct *tsk = *per_cpu_ptr(ht->store, cpu);
struct smpboot_thread_data *td;
td = kzalloc_node(sizeof(*td), GFP_KERNEL, cpu_to_node(cpu));
if (!td)
return -ENOMEM;
td->cpu = cpu;
td->ht = ht;
tsk = kthread_create_on_cpu(smpboot_thread_fn, td, cpu,
ht->thread_comm);
return 0;
}
构造smpboot_thread_data对象,并作为线程处理函数smpboot_thread_fn的参数。
static int smpboot_thread_fn(void *data)
{
struct smpboot_thread_data *td = data;
struct smp_hotplug_thread *ht = td->ht;
while (1) {
set_current_state(TASK_INTERRUPTIBLE);
preempt_disable();
/* Check for state change setup */
switch (td->status) {
if (!ht->thread_should_run(td->cpu)) {
preempt_enable_no_resched();
schedule();
} else {
__set_current_state(TASK_RUNNING);
preempt_enable();
ht->thread_fn(td->cpu);
}
}
}
ht即softirq_threads,判断当前是否有软中断,如果有,则执行ht->thread_fn,即run_ksoftirqd。run_ksoftirqd中调用了__do_softirq。
asmlinkage __visible void __softirq_entry __do_softirq(void)
{
struct softirq_action *h;
__u32 pending;
int softirq_bit;
pending = local_softirq_pending(); // 保存软中断掩码
account_irq_enter_time(current);
__local_bh_disable_ip(_RET_IP_, SOFTIRQ_OFFSET);
restart:
/* Reset the pending bitmask before enabling irqs */
// 清除软中断标志,必须在local_irq_enable前清除
set_softirq_pending(0);
// 强开中断
local_irq_enable();
h = softirq_vec;
while ((softirq_bit = ffs(pending))) {
unsigned int vec_nr;
h += softirq_bit - 1;
vec_nr = h - softirq_vec;
trace_softirq_entry(vec_nr);
h->action(h);
h++;
pending >>= softirq_bit;
}
rcu_bh_qs();
local_irq_disable(); // 强关中断
}
softirq_vec是softirq_action类型的数组,保存了系统中注册的软中断的处理函数。pending是按位标识了softirq_vec哪个类型的软中断被触发。如果该类型的软中断被触发,调用其处理函数。软中断的处理函数是在哪注册的呢,继续往下看。
二 网络模块初始化
网络模块的初始化函数是net_dev_init。
static int __init net_dev_init(void)
{
int i, rc = -ENOMEM;
INIT_LIST_HEAD(&ptype_all);
for_each_possible_cpu(i) {
struct work_struct *flush = per_cpu_ptr(&flush_works, i);
struct softnet_data *sd = &per_cpu(softnet_data, i);
INIT_WORK(flush, flush_backlog);
skb_queue_head_init(&sd->input_pkt_queue);
skb_queue_head_init(&sd->process_queue);
INIT_LIST_HEAD(&sd->poll_list);
sd->output_queue_tailp = &sd->output_queue;
sd->backlog.poll = process_backlog;
sd->backlog.weight = weight_p;
}
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
return rc;
}
每cpu变量sd保存了发送和接收的网络数据包,其中从其他机器接收的包,放到了input_pkt_queue。
关注下process_backlog,如果驱动不支持napi,则会用到process_backlog。
调用open_softirq注册接收数据的软中段NET_RX_SOFTIRQ的处理函数net_rx_action。
void open_softirq(int nr, void (*action)(struct softirq_action *))
{
softirq_vec[nr].action = action;
}open_softirq的处理也相当简单,将该类型的软中断处理函数,放到softirq_vec数组的相应位置。
三 软中断处理函数net_rx_action
static __latent_entropy void net_rx_action(struct softirq_action *h)
{
struct softnet_data *sd = this_cpu_ptr(&softnet_data);
LIST_HEAD(list);
LIST_HEAD(repoll);
local_irq_disable();
// 将poll_list列表中的数据,移到到list列表
list_splice_init(&sd->poll_list, &list);
local_irq_enable();
for (;;) {
struct napi_struct *n;
// 获取到相应的napi_struct
n = list_first_entry(&list, struct napi_struct, poll_list);
budget -= napi_poll(n, &repoll);
}
local_irq_disable();
}poll_list的数据从哪来的呢, 后面会解答这个疑惑。此次讲解的tun驱动,不支持napi,for循环中获取到的struct napi_struct n为sd->backlog,又是为什么。也会在后面解答。
static int process_backlog(struct napi_struct *napi, int quota)
{
struct softnet_data *sd = container_of(napi, struct softnet_data, backlog);
bool again = true;
int work = 0;
napi->weight = dev_rx_weight;
while (again) {
struct sk_buff *skb;
while ((skb = __skb_dequeue(&sd->process_queue))) {
rcu_read_lock();
__netif_receive_skb(skb);
rcu_read_unlock();
input_queue_head_incr(sd);
if (++work >= quota)
return work;
}
local_irq_disable();
rps_lock(sd);
if (skb_queue_empty(&sd->input_pkt_queue)) {
napi->state = 0;
again = false;
} else {
skb_queue_splice_tail_init(&sd->input_pkt_queue,
&sd->process_queue);
}
rps_unlock(sd);
local_irq_enable();
}
return work;
}process_backlog首先处理 process_queue列表中的数据,如果process_queue列表为空,则将input_pkt_queue列表中的数据移到process_queue。调用__netif_receive_skb开始网络协议栈的处理。
四 tun驱动write逻辑
向tun驱动文件中写数据,会走到tun_chr_write_iter-->tun_get_user,在tun_get_user中,根据用户空间传入的数据,组装skb。
static ssize_t tun_get_user(struct tun_struct *tun, struct tun_file *tfile,
void *msg_control, struct iov_iter *from,
int noblock, bool more)
{
if (frags) {
} else if (tfile->napi_enabled) { // 如果tun支持napi
struct sk_buff_head *queue = &tfile->sk.sk_write_queue;
int queue_len;
spin_lock_bh(&queue->lock);
__skb_queue_tail(queue, skb);
queue_len = skb_queue_len(queue);
spin_unlock(&queue->lock);
if (!more || queue_len > NAPI_POLL_WEIGHT)
napi_schedule(&tfile->napi);
local_bh_enable();
} else if (!IS_ENABLED(CONFIG_4KSTACKS)) {
tun_rx_batched(tun, tfile, skb, more);
} else {
// 将数据传输到IP层
netif_rx_ni(skb);
}
}需要说明一点的是,如果tun支持napi,则走第二个分支。我们这次分析,tun不支持napi,所以走最后一个分支。
然道调用netif_rx_ni-->netif_rx_internal-->enqueue_to_backlog。
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi)
{
list_add_tail(&napi->poll_list, &sd->poll_list);
__raise_softirq_irqoff(NET_RX_SOFTIRQ); // 标记软件中断
}
static int enqueue_to_backlog(struct sk_buff *skb, int cpu,
unsigned int *qtail)
{
struct softnet_data *sd;
unsigned int qlen;
// 获取per cpu数据
sd = &per_cpu(softnet_data, cpu);
qlen = skb_queue_len(&sd->input_pkt_queue);
// 数量小于netdev_max_backlog
if (qlen <= netdev_max_backlog && !skb_flow_limit(skb, qlen)) { // 判断队列是否超过最大值
// 如果队列不空,说明当前已经标记过软件中断
if (qlen) {
enqueue:
// 把skb添加到input_pkt_queue队列
__skb_queue_tail(&sd->input_pkt_queue, skb);
input_queue_tail_incr_save(sd, qtail);
rps_unlock(sd);
return NET_RX_SUCCESS;
}
if (!__test_and_set_bit(NAPI_STATE_SCHED, &sd->backlog.state)) {
// 如果NAPI_STATE_SCHED标志没有设置,表示当前没有软中断在处理数据包
// 将backlog添加到poll_list中,backlog也就是初始化process_backlog
if (!rps_ipi_queued(sd))
____napi_schedule(sd, &sd->backlog);
}
goto enqueue;
}
}在 enqueue_to_backlog,如果qlen不为0,说明当前已经标记了软中断,将skb添加到input_pkt_queue列表中。如果qlen为0,将。backlog添加到poll_list上,然道标记软中断。
数据添加到input_pkt_queue列表后,就会在NET_RX_SOFTIRQ的中断处理函数net_rx_action中处理。
最后,有必要再回顾下net_rx_action。
static __latent_entropy void net_rx_action(struct softirq_action *h)
{
struct softnet_data *sd = this_cpu_ptr(&softnet_data);
LIST_HEAD(list);
LIST_HEAD(repoll);
local_irq_disable();
// sd->poll_list中连接的是sd->backlog->poll_list
list_splice_init(&sd->poll_list, &list);
local_irq_enable();
for (;;) {
struct napi_struct *n;
// 获取到相应的napi_struct,即sd->backlog
n = list_first_entry(&list, struct napi_struct, poll_list);
budget -= napi_poll(n, &repoll);
}
local_irq_disable();
}将sd->poll_list连接的内容,移到到list列表上,遍历list链表,调用napi_poll。
static int napi_poll(struct napi_struct *n, struct list_head *repoll)
{
if (test_bit(NAPI_STATE_SCHED, &n->state)) {
work = n->poll(n, weight);
}
}调用n->poll,即sd->backlog->poll,也就是process_backlog。 在process_backlog中开始进入协议栈的处理。