Sklearn——集成模型
sklearn——集成模型
- 1. bagging
- 2.决策树的bagging
-
- 2.1 随机森林
- 2.2 极端随机森林
- 2.3 参数
- 2.4 并行化
- 3.Adaboost
-
- 3.1 用法
- 4. Gradient Tree Boosting
-
- 4.1 分类
- 4.2 回归
- 5 Voting Classifier(投票分类器)
集成学习的目标是结合一组基学习器的预测构建学习算法来提高单个学习器的普遍性和健壮性。通常有两种方法:
averaging:构建一组相互独立的学习器求预测的均值。由于方差的减小,组合学习器的性能比任何单个学习器都好。(eg:bagging,随机森林)
boosting:基学习器串行组合,试图减小组合学习器的偏差,把几个弱学习器组合成一个强力的集成模型。(eg:adaboost,Gradient Tree Boosting)
1. bagging
import pandas as pd
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import GridSearchCV
import matplotlib.pyplot as plt
wine = load_wine()
print(f"所有特征:{wine.feature_names}")
X = pd.DataFrame(wine.data, columns=wine.feature_names)
y = pd.Series(wine.target)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=1)
#==================Bagging 元估计器=============#
from sklearn.ensemble import BaggingClassifier
from sklearn.neighbors import KNeighborsClassifier
bagging = BaggingClassifier(KNeighborsClassifier(),max_samples=0.5, max_features=0.5).fit(X_train, y_train)
y_pred = bagging.predict(X_test)
print(f"Bagging准确率:{accuracy_score(y_test,y_pred):.3f}")
Bagging准确率:0.944
max_samples 和 max_features 控制着子集的大小(对于样例和特征),
bootstrap 和 bootstrap_features 控制着样例和特征的抽取是有放回还是无放回的。
2.决策树的bagging
#=================决策树=============#
base_model = DecisionTreeClassifier(max_depth=1, criterion='gini', random_state=1).fit(X_train, y_train)
y_pred = base_model.predict(X_test)
print(f"决策树的准确率:{accuracy_score(y_test,y_pred):.3f}")
决策树的准确率:0.694
2.1 随机森林
#=================随机森林=============#
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=10,max_features=2).fit(X_train, y_train)
y_pred = bagging.predict(X_test)
print(f"随机森林准确率:{accuracy_score(y_test,y_pred):.3f}")
随机森林准确率:0.944
2.2 极端随机森林
#=================极限随机树=============#
from sklearn.ensemble import ExtraTreesClassifier
clf = ExtraTreesClassifier(n_estimators=10, max_depth=None,min_samples_split=2, random_state=0).fit(X_train, y_train)
y_pred = bagging.predict(X_test)
print(f"极限随机树准确率:{accuracy_score(y_test,y_pred):.3f}")
极限随机树准确率:0.944
2.3 参数
n_estimators:森林里树的数量,通常数量越大,效果越好,但是计算时间也会随之增加。 此外要注意,当树的数量超过一个临界值之后,算法的效果并不会很显著地变好。
max_features:分割节点时考虑的特征的随机子集的大小。 这个值越低,方差减小得越多,但是偏差的增大也越多。 根据经验,回归问题中使用 max_features = n_features , 分类问题使用 max_features = sqrt(n_features )其中 n_features 是特征的个数,是比较好的默认值。
max_depth = None 和 min_samples_split = 2 结合通常会有不错的效果(即生成完全的树)。 这些(默认)值通常不是最佳的,同时还可能消耗大量的内存,最佳参数值应由交叉验证获得。
另外,在随机森林中,默认使用自助采样法(bootstrap = True), 然而 极端随机森林的默认策略是使用整个数据集(bootstrap = False)。
当使用自助采样法方法抽样时,泛化精度是可以通过剩余的或者袋外的样本来估算的,设置 oob_score = True 即可实现。
2.4 并行化
模块还支持树的并行构建和预测结果的并行计算,这可以通过 n_jobs 参数实现。如果n_jobs=k,计算被划分为k个作业,在计算机的k个线程运行。如果n_jobs=1,可以使用所有线程
3.Adaboost
#=================AdaBoost=============#
model = AdaBoostClassifier(base_estimator= base_model,
n_estimators=50,
learning_rate=0.5,
algorithm='SAMME.R',
random_state=1)
model.fit(X_train,y_train)
y_pred = model.predict(X_test)
AdaBoost的准确率:0.972
3.1 用法
Parameter:
base_estimator :default=DecisionTreeClassifier,梯度集成的基学习器
n_estimators :default=50,学习器的最大数量,为了完美拟合,学习进程可能会早停
learning_rate :default=1. 学习率收缩每个学习器的贡献,learning_rate和n_estimators之间有一个平衡
algorithm :{‘SAMME’, ‘SAMME.R’}, optional (default=‘SAMME.R’) real boosting algorithm.SAMME,discrete boosting algorithm.SAMME.R具有更快的收敛速度,用更少的迭代实现更小的误差
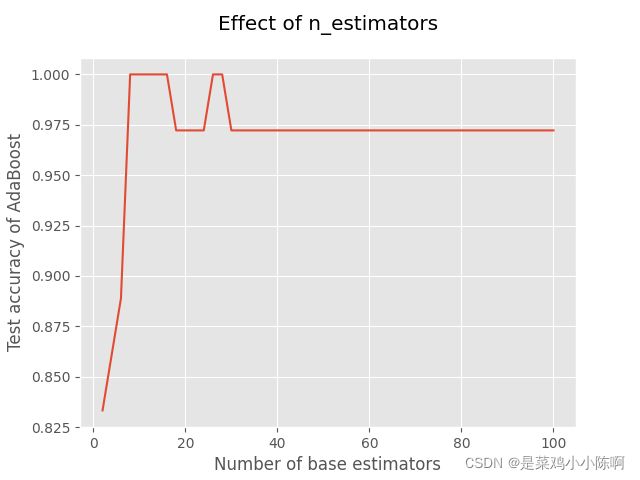
'''测试估计器个数的影响'''
x = list(range(2,102,2))
y = []
for i in x:
model = AdaBoostClassifier(base_estimator=base_model,
n_estimators=i,
learning_rate=0.5,
algorithm='SAMME.R',
random_state=1)
model.fit(X_train, y_train)
model_test_sc = accuracy_score(y_test, model.predict(X_test))
y.append(model_test_sc)
plt.style.use('ggplot')
plt.title("Effect of n_estimators", pad=20)
plt.xlabel("Number of base estimators")
plt.ylabel("Test accuracy of AdaBoost")
plt.plot(x, y)
plt.show()
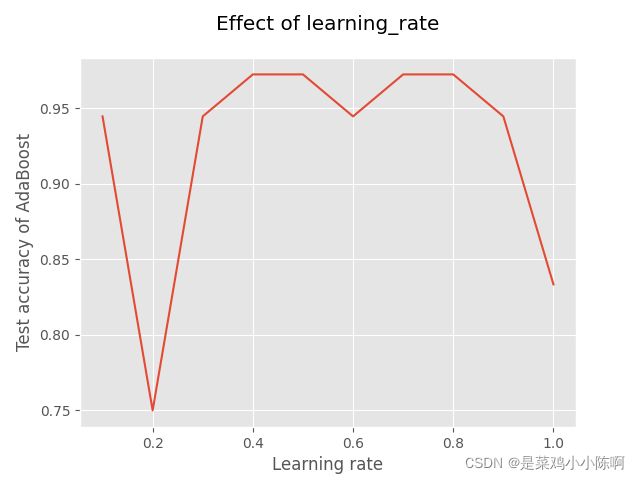
'''测试学习率的影响'''
x = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
y = []
for i in x:
model = AdaBoostClassifier(base_estimator=base_model,
n_estimators=50,
learning_rate=i,
algorithm='SAMME.R',
random_state=1)
model.fit(X_train, y_train)
model_test_sc = accuracy_score(y_test, model.predict(X_test))
y.append(model_test_sc)
plt.title("Effect of learning_rate", pad=20)
plt.xlabel("Learning rate")
plt.ylabel("Test accuracy of AdaBoost")
plt.plot(x, y)
plt.show()
'''使用GridSearchCV自动调参'''
hyperparameter_space = {'n_estimators':list(range(2, 102, 2)),
'learning_rate':[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]}
gs = GridSearchCV(AdaBoostClassifier(base_estimator=base_model,
algorithm='SAMME.R',
random_state=1,
param_gird = hyperparameter_space,
scoring = 'accuracy', n_jobs = 1, cv = 5))
gs.fit(X_train, y_train)
print("最优超参数:", gs.best_params_)
4. Gradient Tree Boosting
Gradient Tree Boosting或Gradient Boosted Regression Trees(GBRT)是任意可导损失函数提升模型的归纳。GBRT是一个准确有效的现成程序,可用于回归和分类问题。Gradient Tree Boosting模型可用于各种领域,包括web搜索排名和生态学。
GBRT的优点:
• 混合型数据的自然处理(异构特征)
• 预测强力
• 输出空间异常值的鲁棒性(强大的损失函数)
缺点:
• 由于boosting的本质而很难并行化
sklearn.ensemble模块提供了GBRT分类和回归的方法。
4.1 分类
from sklearn.datasets import make_hastie_10_2
from sklearn.ensemble import GradientBoostingClassifier
X, y = make_hastie_10_2(random_state=0)
X_train, X_test = X[:2000], X[2000:]
y_train, y_test = y[:2000], y[2000:]
clf = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0,
max_depth=1, random_state=0).fit(X_train, y_train)
clf.score(X_test, y_test)
4.2 回归
import numpy as np
from sklearn.metrics import mean_squared_error
from sklearn.datasets import make_friedman1
from sklearn.ensemble import GradientBoostingRegressor
X, y = make_friedman1(n_samples=1200, random_state=0, noise=1.0)
X_train, X_test = X[:200], X[200:]
y_train, y_test = y[:200], y[200:]
est = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1,
max_depth=1, random_state=0, loss='ls').fit(X_train, y_train)
mean_squared_error(y_test, est.predict(X_test))
5 Voting Classifier(投票分类器)
# 产生样本数据集
from sklearn.model_selection import cross_val_score
from sklearn import datasets
iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target
# ====================Voting Classifier(投票分类器)=========================
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
clf1 = LogisticRegression(random_state=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
eclf = VotingClassifier(estimators=[('lr', clf1), ('rf', clf2), ('gnb', clf3)], voting='hard') # 无权重投票
eclf = VotingClassifier(estimators=[('lr', clf1), ('rf', clf2), ('gnb', clf3)],voting='soft', weights=[2,1,2]) # 权重投票
for clf, label in zip([clf1, clf2, clf3, eclf], ['Logistic Regression', 'Random Forest', 'naive Bayes', 'Ensemble']):
scores = cross_val_score(clf,X,y,cv=5, scoring='accuracy')
print("准确率: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))
# 配合网格搜索
from sklearn.model_selection import GridSearchCV
params = {'lr__C': [1.0, 100.0], 'rf__n_estimators': [20, 200],} # 搜索寻找最优的lr模型中的C参数和rf模型中的n_estimators
grid = GridSearchCV(estimator=eclf, param_grid=params, cv=5)
grid = grid.fit(iris.data, iris.target)
print('最优参数:',grid.best_params_)
准确率: 0.95 (+/- 0.04) [Logistic Regression]
准确率: 0.94 (+/- 0.04) [Random Forest]
准确率: 0.91 (+/- 0.04) [naive Bayes]
准确率: 0.95 (+/- 0.03) [Ensemble]
最优参数: {'lr__C': 100.0, 'rf__n_estimators': 20}
http://www.uml.org.cn/ai/201907311.asp
https://www.jianshu.com/p/5d7ebe35f50f
https://github.com/datawhalechina/machine-learning-toy-code/blob/main/ml-with-sklearn/EnsembleLearning