技术复盘(3)--ElasticSearch
技术复盘--ElasticSearch
- 技术复盘(3)--ElasticSearch
- 资料地址
- 概述
- 对比solr
- windows下使用es
- IK分词器介绍
- es基本命令
- 集成springboot以及调用api
技术复盘(3)–ElasticSearch
ElasticSearch7.x
资料地址
ElasticSearch官网:https://www.elastic.co/
ElasticSearch-head地址:https://github.com/zt1115798334/elasticsearch-head-master
ElasticSearch-kibana官网:https://www.elastic.co/cn/kibana/
ElasticSearch-ik分词器:https://github.com/medcl/elasticsearch-analysis-ik
学习地址-B站狂神:https://www.bilibili.com/video/BV17a4y1x7zq
概述
Elaticsearch,简称为es,es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、可以扩展到上百台服务器,处理PB级别的数据。es也使用lava开发并使用lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTfulAPI来隐藏Lucene的复杂性,从而让全文搜索变得简单。
对比solr
- es基本是开箱即用(解压就可以用!),非常简单。Solr安装略微复杂一丢丢!
- Solr利用Zookeeper进行分布式管理,而Elasticsearch自身带有分布式协调管理功能。
- Solr支持更多格式的数据,比如JSON、XML、CSV,而Elasticsearch仅支持json文件格式。
- Solr 查询快,但更新索引时慢(即插入删除慢),用于电商等查询多的应用;·ES建立索引快(即查询慢),即实时性查询快,用于facebook新浪等搜索。
windows下使用es
一共安装3个软件,elasticsearch,elasticsearch-head-master和kibana,以及为elasticsearch配置ik分词器,软件下载地址在最上方,都是开箱即用,简单修改下配置文件即可。
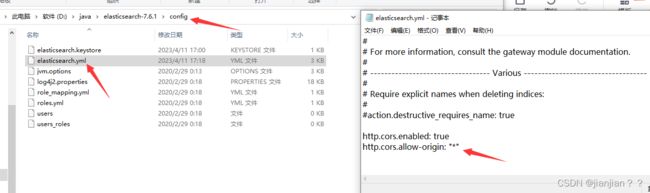
1.解压elasticsearch后,先解决跨域问题,因为es端口为9200,head端口为9100,两者之间通讯会发生跨域。【不懂跨域是什么的也跟着做,不会错】,修改es安装目录下的config目录中的elasticsearch.yml配置文件,把下面两行加在最后面,保存退出即可。
http.cors.enabled: true
http.cors.allow-origin: "*"
2.配置ik分词器,将ik分词器解压到es的pulgins目录下即可

3.启动:双击bin目录下elasticsearch.bat,es7.6最低要求jdk1.8,默认内存最低1G。

4.在浏览器输入http://localhost:9200/ 可查看es信息。

5.安装可视化界面:下载head插件,要求有vue环境,如nodejs。操作流程:在head目录下启动cmd,输入npm install安装head依赖。

6.启动head可视化插件,npm run start,启动成功后在浏览器地址栏输入http://localhost:9100/ 可查看到head可视化界面。

7.安装kibana,安装后修改下kibana的配置文件即可完成汉化,如下图,启动的话找到bin目录中的kibana.bat双击即可,启动成功后地址栏输入http://localhost:5601/ 即可访问。
Kibana是一款开源的数据可视化工具,主要用于展示和分析 Elasticsearch 中的数据。它提供了强大的图表、地图和可视化工具,使用户更容易理解大量数据的含义和趋势,帮助用户快速地发现数据中的问题和机会。Kibana 还允许用户创建自定义仪表盘,以适应不同的业务需求。它是 ELK(Elasticsearch、Logstash 和 Kibana)技术栈中的一部分,常用于日志管理、安全监控、业务分析等领域。

至此安装完成!恭喜!
IK分词器介绍
ik分词器中提供了两种分词方式:ik_smart和ik_max_word
ik_smart:适当拆分,粗粒度
ik_max_word:极限拆分,细粒度
es中有关于分词的数据有两种类型:text和keyword
text:可以被分词器分词,默认数据类型都为text
keyword:不能分词
用kibana举个例子:图一是ik_smart,图二是ik_max_word


还需要介绍的一点就是扩展分词库,比如一些新兴的网络热词,ik分词器中是无法识别的,需要手动配置,手动配置流程如下图,图中的wode.dic是自己加的一个分词库。这种方法比较笨,可采取更智能的方法,比如对接一个热点接口,每隔一小时就拉取一下热点词存入分词器中。

es基本命令

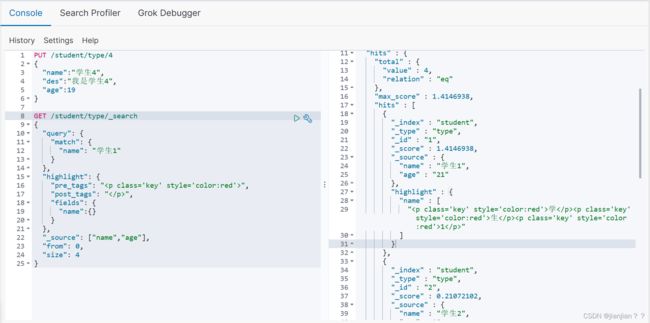
es练习语句,只包含常用的高亮、查询指定字段、分页查询,代码不难,结合图一起看很好理解,就没写注释:
PUT /student/type/4
{
"name":"学生4",
"des":"我是学生4",
"age":19
}
GET /student/type/_search
{
"query": {
"match": {
"name": "学生1"
}
},
"highlight": {
"pre_tags": ""
,
"post_tags": "",
"fields": {
"name":{}
}
},
"_source": ["name","age"],
"from": 0,
"size": 4
}
查询语句运行结果:
集成springboot以及调用api
springboot集成Java REST Client
1.创建项目,注意springboot的版本,默认为3.x,我们选择2.x的,以及在nosql中勾上es。

2.springboot默认的es版本可能和我们需要的不一致,那么就需要在pom文件中自定义es版本

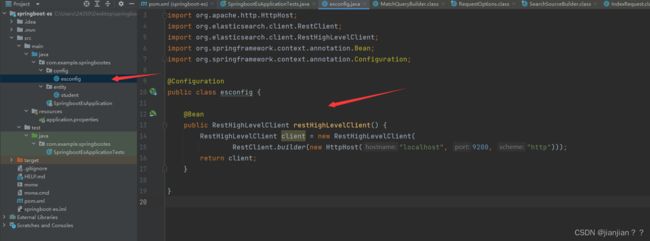
3.编写配置文件
@Bean
public RestHighLevelClient restHighLevelClient() {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
return client;
}
4.编写一个实体
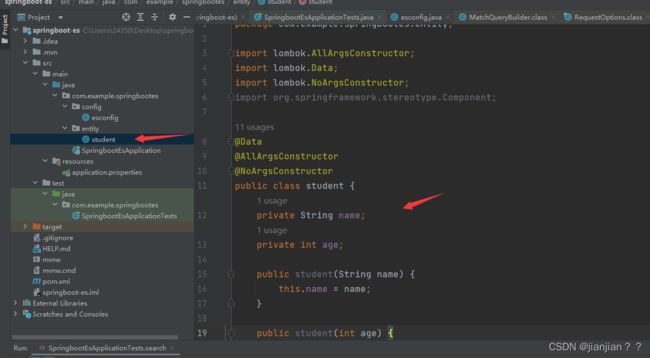
实体代码:
package com.example.springbootes.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.stereotype.Component;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class student {
private String name;
private int age;
public student(String name) {
this.name = name;
}
public student(int age) {
this.age = age;
}
}
5.开始测试

测试代码:
package com.example.springbootes;
import com.alibaba.fastjson.JSON;
import com.example.springbootes.entity.student;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.FetchSourceContext;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import java.util.ArrayList;
@SpringBootTest
class SpringbootEsApplicationTests {
// 自动注入es
@Autowired
private RestHighLevelClient restHighLevelClient;
//创建索引
@Test
void esTestAdd() throws IOException {
try {
// 创建请求
CreateIndexRequest student_index = new CreateIndexRequest("student_index");
// 提交创建请求
CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(student_index, RequestOptions.DEFAULT);
//打印返回结果 是否创建成功 只能是成功 不成功直接报异常
System.out.println("createIndexResponse:"+createIndexResponse.isAcknowledged());
}catch (Exception e){
System.out.println("请查看该索引是否已被创建");
}
}
//判断索引是否存在
@Test
void esTestGet() throws IOException {
GetIndexRequest student_index = new GetIndexRequest("student_index");
boolean exists = restHighLevelClient.indices().exists(student_index, RequestOptions.DEFAULT);
System.out.println("exists ==> "+exists);
}
//删除索引
@Test
void esTestDelete() {
try {
DeleteIndexRequest student_index = new DeleteIndexRequest("student_index");
AcknowledgedResponse delete = restHighLevelClient.indices().delete(student_index, RequestOptions.DEFAULT);
//是否删除成功 只能是成功 因为不成功会抛异常
System.out.println("delete ==> "+delete.isAcknowledged());
}catch (Exception e){
System.out.println("请查看该索引是否已被删除");
}
}
//插入文档 对标mysql为插入数据
@Test
void addData(){
try {
student student1 = new student("张三21", 17);
// 创建请求
IndexRequest student_index = new IndexRequest("student_index");
//不给id就会随便创建一个id 给了id可以如果es中无此id的数据 则创建 有则修改
student_index.id("1");
student_index.source(JSON.toJSONString(student1), XContentType.JSON);
// 提交创建请求
IndexResponse indexResponse = restHighLevelClient.index(student_index, RequestOptions.DEFAULT);
//打印返回结果 是否创建成功 只能是成功 不成功直接报异常
System.out.println("indexResponse:"+indexResponse.toString());
System.out.println("indexResponse:"+indexResponse.status());
}catch (Exception e){
System.out.println("请查看该索引是否已被创建");
}
}
//判断文档是否存在
@Test
void isExitDoc() throws IOException {
GetRequest student_index = new GetRequest("student_index", "1");
student_index.fetchSourceContext(new FetchSourceContext(false));
boolean exists = restHighLevelClient.exists(student_index, RequestOptions.DEFAULT);
//存在为true 不存在为false
System.out.println("exists:"+exists);
}
//获取文档内容
@Test
void getDoc() throws IOException {
GetRequest student_index = new GetRequest("student_index", "1");
GetResponse documentFields = restHighLevelClient.get(student_index, RequestOptions.DEFAULT);
// 获取的结果本质为一个json
System.out.println("documentFields:"+documentFields);
System.out.println("documentFields:"+documentFields.getSource());
}
//更新文档内容
@Test
void updateDoc() throws IOException {
UpdateRequest student_index = new UpdateRequest("student_index", "1");
student student = new student("法外狂徒张三",99);
student_index.doc(JSON.toJSONString(student),XContentType.JSON);
UpdateResponse update = restHighLevelClient.update(student_index, RequestOptions.DEFAULT);
// 获取的结果本质为一个json
System.out.println("update:"+update);
}
//删除文档记录
@Test
void deleteDoc() throws IOException {
DeleteRequest student_index = new DeleteRequest("student_index", "1");
DeleteResponse delete = restHighLevelClient.delete(student_index, RequestOptions.DEFAULT);
System.out.println("delete:"+delete);
System.out.println("delete:"+delete.status());
}
//批量插入
@Test
void bulkAddDoc() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
ArrayList<student> students = new ArrayList<>();
students.add(new student("zhang san",19));
students.add(new student("ls ii",25));
students.add(new student("wang wu",45));
students.add(new student("网五",33));
students.add(new student("法外狂徒",18));
for (int i = 0; i < students.size(); i++) {
bulkRequest.add(
new IndexRequest("student_index")
.id(""+i)
.source(JSON.toJSONString(students.get(i)),XContentType.JSON));
}
BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(bulkResponse.toString());
}
//查询
/***
*
*在java rest client中调用termQuery查不到数据,这个问题是java rest client客户端自带的bug,换用matchPhraseQuery直接替换即可。
* 如果存储数据是英文,则不会出现这个问题
*
*/
@Test
void search() throws IOException {
SearchRequest searchRequest = new SearchRequest("student_index");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
MatchQueryBuilder matchQuery = QueryBuilders.matchQuery("name", "三");
searchSourceBuilder.query(matchQuery);
searchSourceBuilder.from(0);
searchSourceBuilder.size(2);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(searchResponse);
}
}