附代码 MLP-Mixer: An all-MLP Architecture for Vision论文解读
MLP-Mixer: An all-MLP Architecture for Vision论文解读
参考连接:https://blog.csdn.net/weixin_44855366/article/details/120796804
摘要:
在不使用卷积或自我注意情况下,我们提出了MLP-Mixer,一个专门基于多层感知器(MLPs)的架构。MLP-Mixer包含两种类型的层:一种是将MLPs独立应用于image patch(即“混合”位置特征),另一种是跨patch应用的MLPs(即“混合”空间信息)。Mixer的架构完全基于多层感知器(MLPs),它们在空间位置或特征通道上重复应用。
网络结构:
对输入图像首先对其进行patch化,然后将每个patch输入全连接层中,生成一系列一维数据后输入Mixer layers,最后经过一个平均池化层,最后使用全连接层进行输出,在这个过程中,不使用卷积和子注意力层。网络模型如下:
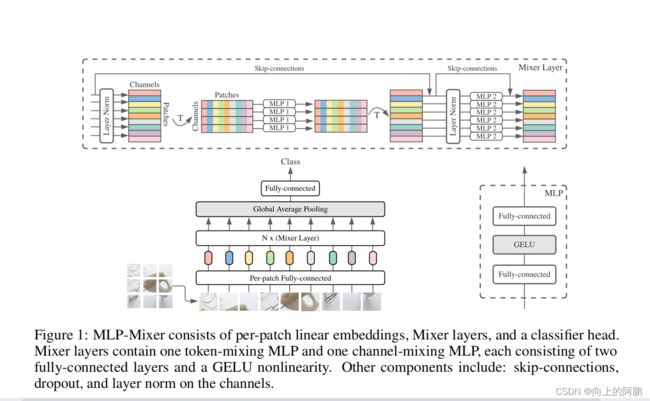
对图像进行patch化
Mixer以S个不重叠的image patch序列作为输入,每个patch投影到一个期望的隐藏维度 C. 会构建一个(C,S)的二维数据表,如果原始输入图像具有分辨率(H,W),并且每个补丁具有分辨率(P,P),则补丁数为S=HW/P/P。所有补丁都使用相同的投影矩阵进行线性投影。

假设输入图像大小为2402403,模型选取的Patch为1616,那么一张图片可以划分为(240240)/(1616)= 225个Patch。结合图片的通道数,每个Patch包含了16163 = 768个值,把这768个值做Flatten(拉平)作为MLP的输入,假设其中MLP的输出层神经元个数为128。这样,每个Patch就可以得到长度的128的特征向量,组合得到128225的Table。MLP-Mixer中Patch大小和MLP输出单元个数为超参数。在这个过程中使用Conv2d(inchannels,dim,kernel_size = patch_size,stride = patch_size)可以直接达到patch并投影的目的。这个时候的输入表尺寸为(1,255,128),其中128为通道数,225为patch数量。
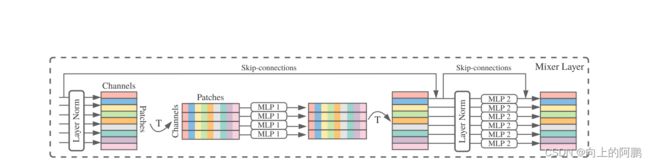
Mix-layer:
输入表(1,255,128)中,128代表了同一空间位置在不同通道上的信息,255代表了不同空间位置在同一通道上的信息。换句话说,对Table的每一列(128)进行操作可以实现通道域的信息融合,对Table的每一行(255)进行操作可以实现空间域的信息融合
Mixer由多个相同大小的层组成,每一层由两个MLP块组成。第一个MLP块为token-mix MLP(即空间信息融合,允许不同空间位置(token)之间的通信;它们在每个通道上独立操作,并将表中的patch数作为输入),第二个mlp为channels-mix MLP(通道信息融合,允许不同通道之间的通信,将表的通道数进行输入)。‘
过程:将表输入Layer Norm层中进行归一化(1,128,255),进行转置(转置目的是为了将列作为输入)(1,255,128),输入token-mix MLP中,输出(1,255,128)后,转置回(1,128,255),并进行skip connection,再输入进channels-mix MLP,输出再进行skip connection,再输出结构如下图:
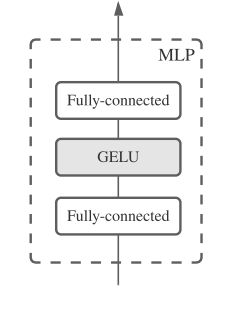
附代码:
import torch
import torch.nn as nn
class MIX_BLOCK(nn.Module):
def __init__(self, d, res):
super().__init__()
self.lm = nn.LayerNorm(res)
self.mlp1 = nn.Sequential(
nn.Linear(d,256),
nn.GELU(),
nn.Dropout(0.1),
nn.Linear(256,d),
nn.Dropout(0.1)
)
self.mlp2 = nn.Sequential(
nn.Linear(res,2048),
nn.GELU(),
nn.Dropout(0.1),
nn.Linear(2048,res),
nn.Dropout(0.1)
)
def forward(self,x):
x = self.lm(x)
out = torch.transpose(x,1,2)
out = torch.transpose(self.mlp1(out),1,2)
x = x + out
x = self.lm(x)
x = x + self.mlp2(x)
return x
class MLP_MIXER(nn.Module):
def __init__(self, inchannels, patch_size, dim, mix_num, image_size, num_classes):
super().__init__()
assert image_size % patch_size == 0, 'Image dimensions must be divisible by the patch size.'
self.out_num = int(image_size // patch_size)**2
self.block = MIX_BLOCK
self.to_patch = nn.Conv2d(inchannels, dim, kernel_size = patch_size, stride = patch_size)
self.mix_blocks = nn.ModuleList([])
for i in range(mix_num):
self.mix_blocks.append(MIX_BLOCK(self.out_num,dim))
self.avgpool = nn.AvgPool1d(2)
self.head = nn.Linear(int(dim/2)*self.out_num, num_classes)
def forward(self,x):
x = self.to_patch(x)
x = x.view(x.shape[0],x.shape[1],-1)
x = torch.transpose(x,1,2)
for mix_block in self.mix_blocks:
x = mix_block(x)
x = self.avgpool(x)
x = x.view(x.shape[0],-1)
x = self.head(x)
return x
if __name__ == '__main__':
input = torch.ones([1,3,224,224])
model = MLP_MIXER(3, 16, 128, 12, 224, 2)
out = model(input)
print(out)