javascript复习(更新)
认识 JS
+ 什么是 JS?
=> 在页面内
-> html: 页面结构(表示了你的页面内有什么)
-> css: 页面样式(表示了你的页面中每一个内容是什么样子的, 在什么位置)
-> javascript: 页面行为(表示了你的页面中每一个内容如何发生变化, 有什么行为内容)
+ JS的三大核心
1. ECMAScript
=> JS 的语法规范, 你如何书写代码
2. BOM - Browser Object Model(浏览器对象模型)
=> 一套操作浏览器的属性和方法
3. DOM - Document Object Model(文档对象模型)
=> 一套操作文档流的属性和方法
+ 本质: 使用 JS 的语法, 去让浏览器和文档流发生变化
js 的注释
1. 单行注释
// 注释内容
+ 作用: 注释一行代码
对下面一行代码进行说明解释
+ 快捷键: ctrl + /
2. 多行注释
/*
注释内容
*/
+ 作用: 注释多行代码
书写解释代码块的内容
+ 快捷键:
=> vscode: alt + shift + a
JS 的变量
+ 什么是变量 ?
=> 在程序的运行过程中, 一个用来保存中间值的内容, 叫做变量
+ 如何定义变量
=> 语法: var 名字 = 值
-> var 定义变量的关键字, 告诉浏览器, 我下面的操作是在定义变量
一次性定义多个变量, 有的赋值有的不赋值
=> 语法: var x = 10, x2, x3 = 30
JS 的输出语法
+ 作用1: 验证一下我的运算是对的
+ 作用2: 修改页面的显示内容
=> 纯文本, 必须要包裹引号
=>纯数字, 无所谓
=> 没有包裹引号, 会当做变量来解析, 如果没有这个变量就会报错了
1. alert(内容) 弹出提示框
+ 作用:
=> 在浏览器弹出提示框, 提示框内显示 () 内书写的文本内容
2. console.log(内容) 控制台显示
+ 作用:
=> 在浏览器控制台显示输出的内容
3. document.write(内容) 页面内输出
+ 作用:
=> 在浏览器页面内输出内容
+ 特点:
=> 可以输出一个 html 格式的文本
=> 会被浏览器解析
4. 选择框: window.confirm()
=> 表现: 在 提示框 的基础上多了一个 取消 按钮
=> 语法: window.confirm('文本内容')
=> 返回值: 是一个布尔值
-> 当用户点击取消的时候, 就是 false
-> 当用户点击确定的时候, 就是 true
5. 输入框: window.prompt()
=> 表现: 在 选择框 的基础上多了一个 输入框
=> 语法: window.prompt('文本内容')
=> 返回值:
-> 如果用户点击的是取消, 那么就是 null
-> 如果用户点击的是确定, 那么就是文本框内的内容
=> 注意: 不管文本框内书写的是什么, 都是 字符串 类型
=> 都会阻断程序的继续执行 ,直到用户操作为止
=> 报错:
+ 当你使用了一个没有的变量的时候
+ 会直接报错
交换变量值
不使用临时变量的思路都是让其中一个变量变成一个a和b都有关系的值,这样可以先改变另一个变量值, 最后改变原修改的变量值
加减运算
1
2
3
a += b;
b = a - b;
a -= b;数组
1
2
3
a = [a,b];
b = a[0];
a = a[1];对象
把a先变成了一个对象,这个对象保存着应该交换后的键值对,最后赋值搞定
1
2
3
a = {a:b,b:a};
b = a.b;
a = a.a;
变量的命名规则和规范
+ 规则: 必须要遵守, 不遵守就报错
1. 一个变量名只能有 数字(0-9) 字母(a-z A-Z) 美元符($) 下划线(_) 组成
2. 一个变量不能由数字开头
3. 严格区分大小写
4. 不要使用关键字和保留字
=> 关键字: js 内正在使用的关键字
=> 保留字: js 现在没有使用, 但是将来有可能要使用的关键字
+ 规范: 建议你遵守
1. 建议变量语义化
=> 当你定义一个变量的时候, 尽量使用一个有意义的单词
=> username, password, email
=> yonghuming, mima, youxiang
2. 驼峰命名法
=> 当一个变量由多个单词组成的时候, 第二个单词开始首字母大写
=> useremail 推荐写成 userEmail
=> getuserinfo 推荐写成 getUserInfo
3. 不要用中文
=> H5 的标准下, 可以使用中文作为变量名
=> 不要这样使用
js 的基本数据类型 // 7种
=> Number 数值
=> String 字符串
=> Boolean 布尔
=> Undefined 空
=> Null 空
=> Symbol 表示独一无二的值 // ES6 新增
=> BigInt 表示任意大的整数 // ES11 新增
Number 数据类型
+ 整数
+ 浮点数(小数)
+ 科学记数法
=> 10e5
=> e5 表示 10 的 5 次方
+ 其他进制表示方式(了解)
=> 十六进制: 0x100, 表示我存储的是一个 十六进制的 100
=> 八进制: 0o100, 表示我存储的是一个 八进制的 100
=> 二进制: 0b100, 表示我存储的是一个 二进制的 100
String 数据类型
+ 一切被单引号或者双引号包裹的内容
+ 表示一段没有意义的文本
Boolean 数据类型
+ 只有两个值是布尔类型
+ true, 表示 真 的意思, 在计算机存储的时候就是 1
+ false, 表示 假 的意思, 在计算机存储的时候就是 0
Undefined 空
+ Undefined 类型只有一个值, 就叫做 undefined
=> 本该有一个值, 但是没有
=> 一个变量, 定义但是没有赋值, 就是 undefined
Null 空
+ null 类型只有一个值, 就叫做 null
=> 有值, 有一个空值
=> 一个变量, 需要赋值为 null 才会是 null
Symbol 表示独一无二的值 ES6 新增
BigInt 表示任意大的整数 ES11 新增
BigInt是一种特殊的数字类型,它提供了对任意长度整数的支持。Number可以准确表达的最大数字是2^53,也就是2的53次方减一
检测数据类型1: typeof
+ 语法:
=> typeof 要检测的变量
=> typeof(要检测的变量)
+ 结果:
=> 你检测的变量的数据类型
=> 以字符串的形式给你
+ 注意: typeof 的结果必然是一个字符串类型
=> 当多个 typeof 连写的时候, 结果必然是 string
+ 两个语法的区别
=> ()
=> 当你需要检测两个内容的运算结果的时候, 必须要使用 () 包裹
typeof 原理:
不同的对象在底层都表示为二进制,在Javascript中二进制前(低)三位存储其类型信息。
000: 对象
010: 浮点数
100:字符串
110: 布尔
1: 整数typeof null 为"object",
原因是因为 不同的对象在底层都表示为二进制,
在Javascript中 二进制前(低)三位 都为0 的话会被判断为 Object类型,
null的二进制表示 全为0 ,自然前三位也是0,所以执行typeof时会返回"object"
检测是否有效:***
除 Function 外的所有构造函数(new)的类型都是 'object'
typeof'';// string 有效
typeof 1;// number 有效
typeof Symbol();// symbol 有效
typeof true;//boolean 有效
typeof undefined;//undefined 有效
typeof new Function();// function 有效
typeof null;//object 无效
typeof [] ;//object 无效
typeof new Date();//object 无效
typeof new RegExp();//object 无效
区分数组和普通对象****!!!!
使用 Array.isArray 或者 Object.prototype.toString.call
检测数据类型2(最常用***): Object.prototype.toString.call()
toString() 是 Object 的原型方法,调用该方法,默认返回当前对象的内部属性,其格式为 [object Xxx] ,其中 Xxx 就是对象的类型。
Object.prototype.toString.call('') ; // [object String]
Object.prototype.toString.call(1) ; // [object Number]
Object.prototype.toString.call(true) ;// [object Boolean]
Object.prototype.toString.call(Symbol());//[object Symbol]
Object.prototype.toString.call(undefined) ;// [object Undefined]
Object.prototype.toString.call(null) ;// [object Null]
Object.prototype.toString.call(newFunction()) ;// [object Function]
Object.prototype.toString.call(newDate()) ;// [object Date]
Object.prototype.toString.call([]) ;// [object Array]
Object.prototype.toString.call(newRegExp()) ;// [object RegExp]
Object.prototype.toString.call(newError()) ;// [object Error]
Object.prototype.toString.call(document) ;// [object HTMLDocument]
Object.prototype.toString.call(window) ;//[object global] window 是全局对象 global 的引用
数据类型转换
转数值
+ '18' + 1 得到结果是 '181', 因为这个结果不是我想要的
+ 我们如果可以把 '18' 转换成数值类型, 那么在进行计算就对了
+ 把其他数据类型转换成数值类型
1. Number()
=> 语法: Number(你要转换的内容)
=> 返回值(结果): 转换后的数值类型
=> 转换规则:
-> 把你要转换的内容当做一个整体
-> 如果能转换成合法数字, 那么就是这个数字
-> 如果不能转换成合法数字, 那么结果就是 NaN(not a number)
2. parseInt()
=> 语法: parseInt(你要转换的内容)
=> 返回值(结果): 转换后的数值类型
=> 转换规则: 一定会一位一位的看待
-> 如果第一位就不能转换成合法数字, 那么直接给出 NaN 的结果, 停止转换
-> 如果第一位可以转换, 那么保留, 继续查看第二位
-> 以此类推, 直到某一位不能转换, 或者到达末尾
-> 把保留的内容当做返回值
=> 特点: 不认识小数点
3. parseFloat()
=> 语法: parseFloat(你要转换的内容)
=> 返回值(结果): 转换后的数值类型
=> 转换规则: 和 parseInt 一模一样
=> 区别: 认识小数点
4. 非加法的数学运算
=> 进行数值的转换
=> 转换规则和 Number 方法一模一样
转字符串
+ 把其他类型转换成字符串类型
1. String()
=> 语法: String(你要转换的数据)
=> 返回值: 转换好的字符串类型
=> 什么数据类型都可以转换
2. toString()
=> 语法: 你要转换的数据.toString()
=> 返回值: 转换好的字符串类型
=> 注意: 不能转换 null 和 undefined
3. 进行加法运算
=> 在 JS 内, 加(+) 符号有两个意义
=> 第一个: 当符号两边都是 数字或者布尔 的时候, 会进行数学运算
=> 第二个: 只要赋值任意一边是 字符串, 就会进行字符串拼接
转布尔
+ 把其他数据类型转换成布尔数据类型
1. Boolean()
=> 语法: Boolean(你要转换的内容)
=> 返回值: 转换好的布尔值内容
+ 在 JS 内, 只有 5 个内容转换成 false
=> 数值 0
=> 空字符串 ''
=> 数值 NaN
=> undefined
=> null
+ 其他所有内容都转换成 true
赋值运算符
a += 10 等价于 a = a + 10
2-1. && 与
=> 需要左右两边都是 true 才能返回 true
=> 短路表达式, 左边为 true 的时候, 右边的代码才会执行
&& 的短路表达式
// 因为左边的 10 > 20 是 false, 导致右边的代码不会执行
// 10 > 20 && console.log('hello world')
// 因为左边的 20 > 10 是 true, 导致右边的代码会执行
// 20 > 10 && console.log('你好 世界')
2-2. || 或
=> 需要任意一边是 true, 就能返回 true
=> 短路表达式, 左边为 false 的时候, 右边的代码才会执行
|| 的短路表达式
// 因为左边的 10 > 20 是 false, 导致右边的代码会执行
// 10 > 20 || console.log('hello world')
// 因为左边的 20 > 10 是 true, 导致右边的代码不会执行
// 20 > 10 || console.log('你好 世界')
2-3. ! 非(取反)
=> 本身是 true 结果就是 false
=> 本身是 false 结果就是 true
=> 双取反可以转布尔
取余: %
=> 被除数 / 除数 = 商 ··· 余数
=> 余数, 就是不能被整除的那一部分
+ 取余:
=> 取到不能被整除的那一部分数值
var res = 10 % 3 //1
比较运算符
1-1. > 大于
1-2. < 小于
1-3. >= 大于等于
1-4. <= 小于等于
1-5. == 等于, 只比较数据的值, 不比较数据类型
1-6. === 等等于, 比较数据类型和值
1-7. != 不等于, 比较的是值不等于
1-8. !== 不等等, 比较的是值和数据类型任意一个不等于就是不等
自增自减运算符
3-1. ++ 加加
+ 使用:
=> 前置 ++ : 符号在 数据的前面
=> 后置 ++ : 符号在 数据的后面
+ 共同点:
=> 都会让变量的值改变(+1)
+ 区别: 在参与运算的时候
=> 前置 ++ : 先把变量的值改变(+1), 用改变以后的值参与运算
=> 后置 ++ : 先把变量本身的值参与运算, 然后在改变变量的值(+1)
3-2. -- 减减
验证数字的方法 // isNaN()
+ 方法叫做 isNaN()
+ 只能检测是不是一个合法数字
+ 语法: isNaN(你要检测的数据)
+ 返回值: 一个布尔值
=> true: 说明是一个 非数字, 证明 不是一个数字
=> false: 说明不是一个 非数字, 证明 是一个数字
if 分支语句
4-1. if (条件) { 代码 }
=> 意义: 条件为 true 就执行 {} 内的代码
4-2. if (条件) { 代码 } else { 代码 }
=> 意义: 条件为 true 执行 if 后面的 {}, 条件为 false, 执行 else 后面的 {}
=> 两个大括号必然且只能执行一个
4-3. if (条件) { 代码 } else if (条件2) { 代码 } ...
=> 意义: 哪一个条件满足, 就执行哪一个 if 后面的 {} 内的代码
=> 注意: 前面的条件满足了, 后面的就不执行了
=> 多个大括号最多能执行一个
4-4. if (条件) { 代码 } else if (条件2) { 代码 } ... else { 代码 }
=> 意义: 哪一个条件满足, 就执行哪一个 if 后面的 {} 内的代码, 都不满足的时候, 执行 else 后面的 {}
=> 注意: 前面的条件满足了, 后面的就不执行了
=> 多个大括号必然且只能执行一个
分支语句 - switch
switch: 开关, 岔路
case: 方案, 情况
break: 打断, 断开
default: 默认
基础语法
switch (要判断的变量) {
case 情况1:
满足情况1 的时候执行的代码
break
case 情况2:
满足情况2 的时候执行的代码
gh
break
default:
所有情况都不满足的时候执行的代码
}
注意:
1. 要判断的变量, 必须和 case 后面的内容是 === 为 true 才叫做满足
=> 也就是 数据类型 和 值 必须一样才行
2. switch 的判断, 只能判断准确的等于哪一个值, 不能进行范围的判断
3. 也不能进行逻辑运算的判断
4. default 可以写, 可以不写
=> 不写的时候, 就是所有条件都不满足, 就没有代码执行
5. break 必须要书写, 如果不写 break, 那么就会进行穿透
=> 穿透, 下一个 case 不管是不是满足, 都会直接执行代码, 直到 switch 结束或者遇到 break 为止
6. 穿透的时候, 会从第一个满足条件的 case 开始向下穿透
var week = 2
// break 穿透
switch (week) {
case 1:
console.log('星期一')
case 2:
console.log('星期二')
case 3:
console.log('星期三')
break
}
// 表示把 week 这个变量进入 switch 进行判断
// switch (week) {
// case 1: // 表示当 week 和 1 相等的时候
// console.log('星期一')
// break
// case 2: // 表示当 week 和 2 相等的时候
// console.log('星期二')
// break
// default: // 表示以上的所有 case 都不满足 的时候执行
// console.log('既不是星期一, 也不是星期二')
// }三目 / 三目运算符 / 三元表达式 // 条件 ? 满足 : 不满足
=> 两个符号 和 三个数据 组成的运算符
=> 是一个 if else 语句的简写形式
-> 只能简写 if else 语句
=> 语法:
-> 条件 ? 满足 : 不满足
-> 如果条件满足, 执行满足位置的代码
-> 如果条件不满足, 就执行不满足位置的代码
=> 注意:
1. 每一个代码执行区间, 只能书写一句话
2. 只能简写 if else 语句
3. 可以用来执行代码, 也可以用来赋值
// 1. 基础使用
// 10 < 20 ? console.log('a') : console.log('b')
循环语句
+ 循环: 重复执行
+ 循环需要几个要素
1. 什么时候开始, 从什么情况下开始
2. 什么时候结束, 从什么情况下结束
3. 步长, 间隔是多少
=> 变成代码
1. 开始: 从数字几开始
2. 结束: 到数字几结束
3. 步长: 每次数字改变多少
while 语句 // while (条件) { 代码 }
+ 意义: 只要满足条件就执行代码
=> 执行完毕代码, 再次判断条件
=> 如果还满足, 继续执行代码
=> 执行完毕代码, 再次判断条件
=> 直到不满足了, 结束当前循环
+ 循环控制变量
=> 在循环中, 什么可以控制循环的次数
=> 开始 结束 和 步长, 都能控制循环的次数
// 1. 确定循环的开始
var n = 1
// 2. 确定循环的结束
while (n <= 3) {
console.log('我执行了')
console.log(n)
// 3. 确定循环的步长
// n = n + 1 是为了让 n 改变, 我的改变就是 +1
// 写成 n += 1
// 写成 n++
n += 2
}do ... while // do { 代码 } while (条件)
+ 先执行一遍代码, 再开条件判断
+ 和 while 循环的区别
=> 当你的初始变量在条件判断范围以内的时候, 和 while 循环一样
=> 当你的初始变量在条件范围外的时候
-> while 循环一次都不执行, 因为先判断, 不满足直接结束了
-> do while 会执行一次, 因为后判断, 所以先执行一次
var m = 10
do {
console.log('我执行了', m)
m++
} while (m <= 3)for // for (定义初始变量; 条件判断; 步长) { 代码 }
+ 语法:
=> for (定义初始变量; 条件判断; 步长) { 代码 }
+ while 循环
=> 定义初始变量
=> while (条件) {
步长
}
// for 循环语法
for (var n = 1; n <= 10; n++) {
// 步长已经写过了
// 指数写重复的代码即可
console.log('我执行了 ', n)
}循环控制语句
1. break 结束整个循环
+ 当循环内执行到这句代码的时候, 会直接结束整个循环
2. continue 跳过本次循环
+ 当循环内执行到这句代码的时候, 会跳过循环的本次, 继续循环的下一次
函数(function)
+ 是一个 js 内的数据类型, 并且是一个 复杂数据类型
+ 函数在 JS 内叫做 "一等公民"
+ 什么是函数 ? (私人)
=> 函数就是一个 "盒子", 能承载一段代码
=> 当你需要执行这一段代码的时候, 只要告诉 "盒子"
+ 函数分成两个阶段
=> 把代码放在 "盒子" 里面的过程, 叫做 函数定义阶段
=> 把 "盒子" 里面的代,码执行的过程, 叫做 函数调用阶段
函数定义阶段
+ 方式1: 声明式函数
=> 语法: function 名字() {}
=> function 定义函数的关键字
=> 名字 函数名(变量名), 遵循变量的命名规则和规范
=> () 必须写, 书写参数的位置(欠着)
=> {} 代码段, 你需要放在 "盒子" 里面的所有代码
=> 注意: 函数定义阶段, {} 内的代码不会执行
+ 方式2: 赋值式函数
=> 语法: var 名字 = function () {}
函数调用阶段
+ 语法: 函数名()
+ 意义: 找到函数名对应的那个函数盒子, 把里面的代码执行一遍
函数的参数
+ 第一种: 形参
=> 是书写在函数定义阶段的小括号内
=> 就是一个只能在函数内部使用的变量
=> 可以书写多个, 中间使用逗号(,) 分隔
=> 形参的值, 是由函数的 实参 决定的
+ 第二种: 实参
=> 是书写在函数调用阶段的小括号内
=> 按照从左到右的顺序依次给每一个形参进行赋值的
函数内的注意
1. 函数调用上的注意
+ 声明式函数可以先调用, 可以后调用
+ 赋值式函数只能后调用, 先调用会报错
2. 参数数量上的注意
+ 形参和实参一样多
=> 按照从左到右的顺序依次给每一个形参赋值
+ 形参多
=> 前面的按照从左到右的顺序依次赋值
=> 多出来的形参, 没有实参进行赋值
=> 在函数内使用的时候就是 undefined
+ 实参多
=> 前面的按照从左到右的顺序依次赋值
=> 多出来的实参, 在函数内没有形参接收
=> 在函数内不能直接使用(需要利用 arguments 来进行访问和使用)
arguments 实参的集合
+ 是一个函数内天生自带的变量
+ 是一个 "盒子", "盒子" 内部存放的不是代码, 是你所有的实参
=> 你调用函数的时候, 传递了多少个实参, 这个盒子里面就有多少个数据
=> 叫做实参的集合
+ arguments 内所有的数据都是按照 "序号" 排列的
=> 注意: "序号" 从 0 开始, 依次 +1
=> 我们管 "序号" 叫做 索引 或者 下标
=> arguments 内的数据是按照 索引 进行排列的
=> 索引: 从0 开始 依次 +1
+ 访问 arguments 内的每一个数据
=> 利用 索引(下标) 来进行访问
=> 语法: arguments[索引]
-> 表示你需要访问 arguments 这个 "盒子" 内部索引为 几 的数据
-> 如果 arguments 内有对应的索引, 那么就是对应索引位置的数据
-> 如果 arguments 内没有对应的索引, 那么就是 undefined
+ 知道 arguments 的长度
=> 指需要直到 arguments 内有多少个数据
=> 语法: arguments.length
=> 得到的就是一个数字, 表示 arguments 的长度, 也就是 arguments 内有多少个数据
-> 也就是你传递了多少个实参
=> 长度和索引的关系
-> 最后一个数据的索引一定是 长度 - 1
+ 遍历: 从头到尾访问到每一个数据
=> arguments 内每一个数据的索引放在一起, 是一组有规律的数字
=> 循环, 能给我们提供一组有规律的数字
=> 利用循环拿到一组有规律的数字, 把这个数字当做 arguments 的索引来访问每一个数据
打断函数 return
+ 使用 return 关键字
+ 作用2: 写在 return 后面行的代码不执行了
作用域
+ 作用: 生效, 可以使用, 可以产生用途
+ 域: 区域, 范围
+ 指 变量(变量名 和 函数名) 生效的范围
作用域分类
+ 全局作用域
=> 打开一个页面就是一个全局作用域
+ 私有作用域(函数作用域)
=> **只有函数生成私有作用域**
作用域上下级关系
+ 你在哪一个作用域下书写的函数, 就是哪一个作用域的子级作用域
作用域的机制 (***)
1. 变量定义机制
=> 你定义在哪一个作用域下的变量
=> 就是哪一个作用域的私有变量
=> 只能在该作用域及其后代作用域中使用
2. 变量赋值机制
=> 当你给一个变量赋值的时候
=> 如果自己作用域内有该变量, 那么给自己的赋值
=> 如果自己作用域内没有该变量, 那么给父级的变量赋值
=> 如果父级还没有, 那么就给再父级的变量赋值
=> 以此类推直到 window(全局作用域) 都没有这个变量
=> 那么把这个变量定义为全局变量, 再进行赋值
3. 变量访问机制
=> 当你需要获取一个变量的值的时候
=> 首先在自己作用域内查找, 如果有直接使用, 停止查找
=> 如果没有, 访问父级的该变量
=> 如果还没有, 就继续去父级访问
=> 直到全局作用域都没有, 那么直接报错
预解析
+ 预: 预先, 提前
+ 解析: 解释一些内容, 做出一个说明
+ 在所有代码执行之前, 对代码进行通读并解释
预解析的内容
1. 解析了 var 关键字
=> 规则: 会把 var 关键字声明的变量进行提前说明, 但是不进行赋值
2. 解析了 声明式 函数
=> 规则: 会把 函数名 进行提前声明, 并且赋值为一个函数
预解析的无节操
1. 在代码中, 不管 if 条件是否为 true, if 语句代码里面的内容依旧会进行预解析
2. 函数体内, return 后面的代码虽然不执行, 但是会进行预解析
预解析中的重名问题
+ 当你使用 var 定义变量 和 声明式函数 重名的时候, 以 函数为主
+ 只限于在预解析阶段, 以函数为准
递归函数(了解)
+ 一种函数的应用方式
=> 一个函数自己调用自己, 并且正确设置了结束条件, 可以逐步回归的时候
=> 我们管这种调用函数的方式叫做 递归调用
=> 非常消耗性能,不推荐使用
书写递归的原则
1. 先写折返点
2. 按照规则书写未到达折返点的情况
对象
+ 对象两个含义
=> 第一个: 一类事物的某一个个体
=> 第二个: 一种数据类型
对象数据类型 Object
+ 是 JS 中的一种数据类型, 是一个 复杂 数据类型
+ 什么是 对象 ? (私人)
=> 是一个 "盒子", 承载一些数据
+ 就是一个 键值对 的集合
如何创建一个对象 + 语法:
1. 字面量方式创建对象
=> 语法: var obj = { 键值对, ... }
2. 内置构造函数创建对象
=> 语法: var obj = new Object()
创建一个带有数据(键值对)的对象
+ 目前只能使用 字面量方式 创建
+ 语法:
=> var obj = { 键值对, ... }
+ 键值对:
=> 键: 值
=> 多个键值对之间, 使用 逗号(,) 分隔
对象的基本操作
+ 操作: 增删改查
=> 向对象内增加一条数据
=> 删除对象内的某一条数据
=> 修改对象内的某一条数据
=> 访问对象内某一条数据的值
+ 一共有两种语法
1. 点语法
=> 增: 对象名.键名 = 值
=> 删: delete 对象名.键名
=> 改: 对象名.键名 = 值
=> 查: 对象名.键名
2. 数组关联语法
=> 增: 对象名['键名'] = 值
=> 删: delete 对象名['键名']
=> 改: 对象名['键名'] = 值
=> 查: 对象名.键名
对象两种操作语法的区别
对象内的键名都可以如何书写
1. 符合变量命名规则和规范的可以书写
2. 可以是纯数字
3. 其他特殊字符也可以, 但是需要在 键名 的位置单独包裹一个引号
两种语法的区别
1. 对于名字的操作
=> 如果是符合变量命名规则和规范的 键名, 两种语法都可以
=> 纯数字只能使用数组关联语法, 不能使用点语法
=> 带有特殊符号的, 只能使用数组关联语法, 不能使用点语法
2. 和变量相关的时候
=> 点语法, 不管如何, 都不能和变量产生联系
-> 始终都是访问的对象内某一个准确的键名
=> 数组关联语法, 当你的 [] 内书写的是一个 变量 的时候
-> 会把变量解析出来填充在 [] 内
对象的遍历 // for in 循环
+ 对象没有办法使用 for 循环来进行遍历
=> 因为 for 循环能提供的是一组有规律的数字
=> 但是对象内的键名 没有规律
for in 循环
+ 主要作用, 就是用来遍历对象数据类型的
+ 语法:
for (var 变量名 in 对象名) {
// 重复执行的代码, 对象内有多少个成员, 就执行多少回
// 对象名[键名] 就是对象中的每一个成员的值
}
数据类型存储的区别
+ 栈内存和堆内存(存在内存空间--内存条)
+ 都是用来存储代码中的数据的位置
+ 基本数据类型 和 复杂数据类型 在存储上是有区别的
+ 了解栈内存: 按序排列, 先来的在栈底, 后来的在栈顶
+ 了解堆内存: 无序排列, 根据地址来查找(堆空间地址)
基本数据类型的存储
+ 直接存储在 栈 内存中
复杂数据类型的存储 (地址数据类型 / 引用数据类型)
+ 把数据存储在 堆内存 中
+ 把地址赋值给 栈内存 的变量里
数据类型赋值上的区别
基本数据类型
+ 赋值的时候, 就是直接值的复制
+ 赋值以后, 两个变量互相之间没有任何关系
+ 改变一个变量, 另一个不会发生变化
复杂数据类型
+ 赋值的时候, 是把变量内存储的地址进行赋值
+ 赋值以后, 两个变量操作的是一个存储空间
+ 任意一个变量去改变存储空间内的数据, 另一个变量看到的一样是改变以后的
数据类型比较上的区别
+ 基本数据类型, 就是 值 和 值 之间的比较
+ 复杂数据类型, 是 地址 和 地址 之间的比较
数组数据类型
+ 数组是 数据的组合
+ 是一个 JS 中的复杂数据类型, 叫做 Array
=> 也是一个 "盒子", 是一个承载数据的 "盒子"
=> 数组里面的数据排列是按照顺序的
=> 有序的数据集合
+ 数组里面所有数据的排列都是按照 "序号" 进行排列的
=> 我们管 "序号" 叫做 索引 或者 下标
=> 索引(下标): 从0开始, 依次+1
数组的创建
1. 字面量方式创建数组
=> 创建空数组: var arr = []
=> 创建带有数据的数组: var arr = [ 数据1, 数据2, 数据3, ... ]
2. 内置构造函数创建数组
=> 创建空数组: var arr = new Array()
-> 等价于 var arr = []
=> 创建指定长度的数组: var arr = new Array(数字)
-> 数字表示的是数组的长度
-> 因为没有数据填充, 就会用 empty 填充
=> 创建带有数据的数组: var arr = new Array(数据1, 数据2, 数据3, ...)
-> 每一个内容都是数组内部的真实数据, 没有表示长度的数据了
-> 等价于 var arr = [ 数据1, 数据2, 数据3, ... ]
数组的基本使用
1. 数组有一个 length 的属性
+ 是一个 读写 的书写
+ 读:
=> 语法: 数组名.length
=> 获取到的就是该数组的长度, 也就是数组内有多少个数据
+ 写:
=> 语法: 数组名.length = 数字
=> 设置该数组的长度
-> 设置的数字和原始长度一样, 相当于没有设置
-> 设置的数字比原始长度大, 多出来的位置, 用 empty 补齐
-> 设置的数字比原始长度小, 从后面开始删除
2. 数组的索引属性
+ 是一个 读写 的属性
+ 读:
=> 语法: 数组[索引]
=> 获取数组该索引位置的数据
-> 如果数组有该索引位置, 那么就是该索引位置的数据
-> 如果数组没有该索引位置, 那么就是 undefined
+ 写:
=> 语法: 数组[索引] = 值
=> 给数组的某一个索引位置进行赋值
-> 如果原先数组中就有该索引位置, 那么就是修改
-> 如果原先数组中没有该索引位置, 那么就是添加
+ 如果你设置的索引刚好和 length 一样, 那么就是在最后追加
+ 如果你设置的索引大于 length, 那么中间空出来的位置用 empty 补齐, 为了保证最后一位的索引一定是 length - 1
3. 遍历数组
+ 因为数组的索引是一组有规律的数字
+ for 循环也可以提供一组有规律的数字
+ 所以我们使用 for 循环遍历数组
4. 数组排序
4-1. 冒泡排序
for (var i = 0; i < arr.length - 1; i++) {
for (var j = 0; j < arr.length - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
var tmp = arr[j]
arr[j] = arr[j + 1]
arr[j + 1] = tmp
}
}
}4-2. 选择排序
for (var j = 0; j < arr.length - 1; j++) {
var minIndex = j
for (var i = j + 1; i < arr.length; i++) {
if (arr[i] < arr[minIndex]) {
minIndex = i
}
}
var tmp = arr[j]
arr[j] = arr[minIndex]
arr[minIndex] = tmp
}数组常用方法1----(会改变原始数组)
1. push()在最后追加
=> 语法: 数组.push(数据)
=> 作用: 向数组的末尾追加数据
=> 返回值: 添加数据以后, 数组最新的 **长度**
2. pop()在最后删除
=> 语法: 数组.pop()
=> 作用: 删除数组的最后一个数据
=> 返回值: 被删除的数据
3. unshift()在前面添加
=> 语法: 数组.unshift('数据')
=> 作用: 从数组的最前面插入一个数据
=> 返回值: 添加数据以后, 数组最新的 **长度**
4. shift()在前面删除
=> 语法: 数组.shift()
=> 作用: 删除数组最前面一个数据
=> 返回值: 被删除的数据
5. reverse()反转数组
=> 语法: 数组.reverse()
=> 作用: 反转数组
=> 返回值: 反转后的数组
6. sort()数组排序
=> 语法:
-> 数组.sort()
+ 把每一个数据一位一位的看待, 进行排序的
-> 数组.sort(function (a, b) { return a - b })
+ 把所有数据进行升序排列
-> 数组.sort(function (a, b) { return b - a })
+ 把所有数据进行降序排列
=> 作用: 对数组进行排序
=> 返回值: 排序后的数组
7. splice()截取数组
=> 语法:
-> 数组.splice(开始索引, 多少个)
-> 数组.splice(开始索引, 多少个, 要插入的数据)
+ 从安一个索引开始删除, 从哪一个索引开始插入
=> 作用: 截取数组并选择性是否插入内容
=> 返回值: 必然是一个新的数组
-> 你截取了多少内容, 新数组里面就有多少内容
-> 你如果没有截取内容, 那么就是一个空的新数组
数组常用方法2----(不会改变原数组, 以返回值形式给结果)
1. concat()数组拼接
+ 语法: 数组.concat(数据, 数组, ...)
+ 作用: 进行数组拼接
+ 返回值: 拼接好的数组
+ 注意: 不会改变原始数组
2. join()使用连接符把数组连接成字符串
+ 语法: 数组.join('连接符')
=> 连接符不写, 默认使用 逗号(,)
+ 作用: 使用连接符把数组内的每一项连接成为一个字符串
+ 返回值: 连接好的字符串
+ 注意: 不会改变原始数组, 返回值是一个字符串类型
3. slice()截取数组, 包前不包后
+ 语法: 数组.slice(开始索引, 结束索引)
=> 开始索引: 默认值是 0
=> 结束索引: 默认值是 length
+ 特点:
=> 包前不包后
=> 可以填写负整数, 当你填写负整数的时候, 等价于 负整数+length
+ 作用: 截取数组, 从数组内复制一些内容出来
+ 返回值: 一个新的数组
=> 如果你截取了数据, 那么截取多少, 新数组内就有多少数据
=> 如果你没有截取数据, 那么就是一个空的数组
+ 注意: 不会改变原始数组
4. indexOf()查询数据在数组中的索引位置
+ 语法: 数组.indexOf(数据, 开始索引)
=> 开始索引选填, 默认值是 0
+ 作用: 从开始索引向后检索该数组中是否有该数据
+ 返回值:
=> 如果检索到了改数据, 那么就是该数据第一次出现的索引位置
=> 如果没有检索到该数据, 那么就是 -1
+ 注意: 不会改变原始数组
5. lastIndexOf()从后向前查询数据在数组中的索引位置
+ 语法: 数组.lastIndexOf(数据, 开始索引)
=> 开始索引选填, 默认值是 length
+ 作用: 从开始索引向前检索该数组中是否有该数据
+ 返回值:
=> 如果检索到了改数据, 那么就是该数据第一次出现的索引位置
=> 如果没有检索到该数据, 那么就是 -1
+ 注意:
=> 不会改变原始数组
=> 不会改变索引位置
数组常用复杂方法----(不会改变原数组, 以返回值形式给结果)
1. forEach()遍历数组**
+ 语法: 数组.forEach(function (item, index, arr) {})
=> 函数可以接受三个参数
=> 第一个参数: 表示数组内的每一项
=> 第二个参数: 表示数组内每一项的索引
=> 第三个参数: 表示原始数组
+ 作用: 用来遍历数组
+ 返回值: 没有 undefined
2. map()映射数组***
+ 语法: 数组.map(function (item, index, arr) {})
+ 作用: 映射数组
+ 返回值:
=> 是一个新数组, 并且和原始数组长度一致
=> 新数组内每一个数据都是根据原始数组中每一个数据映射出来的
=> 映射条件以 return 的形式书写
// 2. map() var arr = [ 100, 200, 300, 400, 500 ] console.log('原始数组 : ', arr) // 开始映射 var res = arr.map(function a(item) { // 以 return 的形式书写映射条件 return item * 10 }) console.log('返回值 : ', res) /* map 的原理 1. 准备了一个新数组 => [1000, 2000, 3000, 4000, 5000] 2. 开始根据原始数据进行遍历 => 第一次调用 a(100, 0, 原始数组), 返回值是 1000, 把这个返回值放在新数组里面 => 第二次调用 a(200, 1, 原始数组), 返回值是 2000, 把这个返回值放在新数组里面 => 第三次调用 a(300, 2, 原始数组), 返回值是 3000, 把这个返回值放在新数组里面 => ... 3. 把 最终的这个数组当做 map 这个方法的返回值 */3. filter()过滤数组**
+ 语法: 数组.filter(function (item, index, arr) {})
+ 作用: 过滤数据
+ 返回值:
=> 是一个新数组
=> 数组内是原始数组中所有满足条件的项
=> 条件以 return 的形式书写
//3.filter() var arr = [ 111, 222, 333, 444, 555 ] console.log('原始数组 : ', arr) // 对 arr 进行过滤 var res = arr.filter(function a(item) { // 以 return 的形式书写过滤条件 return parseInt(item / 100) % 2 === 0 }) console.log('返回值 : ', res) /* filter 原理 1. 准备一个空数组 => [400, 500] 2. 开始根据数组内有多少成员调用多少次 a 函数 => 第一次调用 a(100, 0, 原始数组), 返回值 false, 那么 100 不加入新数组 => 第二次调用 a(200, 1, 原始数组), 返回值 false, 那么 200 不加入新数组 => 第三次调用 a(300, 2, 原始数组), 返回值 false, 那么 300 不加入新数组 => 第四次调用 a(400, 3, 原始数组), 返回值 true, 那么 400 加入新数组 => 第五次调用 a(500, 4, 原始数组), 返回值 true, 那么 500 加入新数组 3. 把数组最终结果当做 filter 的返回值 */4. every()判断数组是否全部满足条件
+ 语法: 数组.every(function (item, index, arr) {})
+ 作用: 判断数组中是不是每一个都满足条件
+ 返回值: 一个布尔值
=> 如果数组中每一个都满足条件, 那么返回值 true
=> 只要数组中任何一个不满足条件, 那么返回 false
+ 判断条件以 return 的形式书写
//4. every() var arr = [100, 200, 300, 400, 500] console.log('原始数组 : ', arr) var res = arr.every(function (item) { // 以 return 的形式书写 判断 条件 return item < 500 }) console.log('返回值 : ', res) //false5. some()判断数组是否有某一个满足条件
+ 语法: 数组.some(function (item, index, arr) {})
+ 作用: 判断数组中是不是有某一个满足条件
+ 返回值: 一个布尔值
=> 如果数组中有任何一个满足条件, 那么返回 true
=> 只有数组中所有的都不满足条件, 才会返回 false
//5. some() var arr = [100, 200, 300, 400, 500] console.log('原始数组 : ', arr) var res = arr.some(function (item) { // 以 return 的形式书写 判断 条件 return item < 50 }) console.log('返回值 : ', res)6. find()查找数组中满足条件的那一项**
+ 语法: 数组.find(function (item, index, arr) {})
+ 作用: 查找数组中某一个数据
+ 返回值:
=> 数组中你查找到的该数据
+ 查找条件以 return 的形式书写
+ 所用在复杂数据类型的查找
//6. find() var arr = [ 100, 200, 301, 400, 500 ] console.log('原始数组 : ', arr) // 我想找到原始数组中的哪一个 奇数 var res = arr.find(function (item) { // 以 return 的形式书写查找条件 return item % 2 === 1 }) console.log('返回值 : ', res) /*------------------------------------------------------------*/ // find 一般查找的都是复杂数据类型 var arr = [ { id: 1, name: 'Jack' }, { id: 2, name: 'Rose' }, { id: 3, name: 'Tom' } ] //prompt是输入弹窗 var id = prompt('请输入你要查询的学生 id') - 0 // 我已知的只有 id, 我想知道这个人叫什么 // 使用 find 方法直接找到这个人的完整信息 var student = arr.find(function (item) { // 条件: 找到 每一项中 id 和我准备的 id 一样的哪一个 return item.id === id }) console.log(student)7. reduce()进行叠加***
+ 语法: 数组.reduce(function (prev, item, index, arr) {}, 初始值)
=> 函数, 函数根据数组中的成员进行重复调用
-> 第一个参数: 初始值 或 每一次叠加后的结果
-> 第二个参数: 每一项
-> 第三个参数: 索引
-> 第四个参数: 原始数组
=> 初始值: 默认是 0, 表示从什么位置开始叠加
+ 作用: 进行叠加累计
// 7. reduce() var arr = [ 100, 200, 300, 400, 500 ] console.log('原始数组 : ', arr) var res = arr.reduce(function a(prev, item) { // 以 return 的形式书写每次的叠加条件 return prev + item }, 0) console.log('返回值 : ', res) /* reduce 原理 1. 准备了一个初始值, 按照你传递的第二个参数来定 var init = 1500 2. 根据原始数组来调用 a 函数 => 第一次调用 a(0, 100, 0, 原始数组), return 0 + 100, 把 返回值再次赋值给 init => 第二次调用 a(100, 200, 1, 原始数组), return 100 + 200, 把 返回值再次赋值给 init => 第三次调用 a(300, 300, 2, 原始数组), return 300 + 300, 把 返回值再次赋值给 init => 第四次调用 a(600, 400, 3, 原始数组), return 600 + 400, 把 返回值再次赋值给 init => 第五次调用 a(1000, 500, 4, 原始数组), return 1000 + 500, 把 返回值再次赋值给 init 3. 把最初始准备的变量 init 结果, 当做 reduce 的返回值 */
数组去重***!!!
/*
方案1:
1. 排序 // sort
=> 一样的挨着
2. 循环遍历数组
=> 如果当前这个和下一个一样, 删除一个 // splice
=> 为了解决数组塌陷 // i--
*/
arr.sort(function (a, b) { return a - b })
for (var i = 0; i < arr.length; i++) {
if (arr[i] === arr[i + 1]) {
arr.splice(i, 1)
i--
}
}
/*
方案2:
1. 准备一个新数组
2. 循环遍历原始数组, 一个一个把数据添加到新数组内
=> 在添加的时候
=> 判断新数组内是否有该数据
=> 如果有, 就什么都不做
=> 如果没有, 就添加进去 // push
问题: 如何判断数组中是否有某一个数据 ?
=> indexOf()
=> 如果返回值是 -1, 表示 没有
=> 只要不是 -1, 表示 有
*/
var newArr = []
for (var i = 0; i < arr.length; i++) {
if (newArr.indexOf(arr[i]) === -1) {
newArr.push(arr[i])
}
}
/*
方案3:
1. 循环遍历原始数组
2. 每一个数据判断后面是否还出现了这个内容 // indexOf
=> 如果没有出现了, 那么什么都不做, 继续下一次
=> 如果有出现, 那么把后面的干掉 // splice
=> 为了解决数组塌陷 // i--
*/
for (var i = 0; i < arr.length; i++) {
var index = arr.indexOf(arr[i], i + 1)
if (index !== -1) {
arr.splice(index, 1)
i--
}
}
// 或者
for (var i = 0; i < arr.length; i++) {
var index = arr.indexOf(arr[i], i + 1)
while (index !== -1) {
arr.splice(index, 1)
index = arr.indexOf(arr[i], i + 1)
}
}
/*
方案4:
+ 利用对象数据类型来进行数组去重
=> 因为对象内的 key 可以是纯数字
=> 又因为对象内的 key 不会重名
1. 准备一个空对象 // obj
2. 循环遍历数组
=> 把数组内每一个数据当做 键 来添加在对象内, 值是什么为所谓
// obj[arr[i]] = '无所谓'
3. 循环遍历对象 // for in 循环
=> 把对象内的每一个 key 添加到一个新的数组内 // push
*/
var obj = {}
for (var i = 0; i < arr.length; i++) {
var item = arr[i]
obj[item] = '随便'
}
var newArr = []
for (var k in obj) {
newArr.push(k - 0)
}
// 注意: 只对纯数字的数组去重比较友好
/*
方案5:
+ 借助有一个数据类型叫做 Set
=> 数据类型不接受重复数据
+ 语法: var s = new Set( [ 数据1, 数据2, 数据3, ... ] )
2. 把 set 数据类型还原成数组
=> 语法1: Array.from(set数据类型)
=> 语法2: [ ...set数据类型 ]
*/
// 1. 转换成 Set 数据结构, 自然去重
// 2. 再还原成数组
// 方式1:
var res = Array.from(new Set(arr))
// 方式2:
var res = [ ...new Set(arr) ]
字符串
+ 在 JS 内用 单引号 或者 双引号 包裹的内容就叫做 字符串
+ 字符串也是一个 包装数据类型
+ 存储的时候, 是以基本数据类型的形式进行存储
+ 当你使用它的时候, 会瞬间转换成 复杂数据类型 的样子让你使用
+ 等你使用完毕, 瞬间转换成 基本数据类型 的形式进行存储
创建字符串的方式
1. 字面量创建
=> var str = 'hello world'
=> var str = "hello world"
2. 内置构造函数创建
=> var str = new String('hello world')
字符串的基本操作
1. 字符串有一个 length 属性
+ 是一个 只读 的属性, 只能获取不能设置
=> 语法: 字符串.length
=> 获取到的就是该字符串的长度, 也就是字符串有多少个字符组成
=> 注意: 空格也是一个字符, 中文也是一个字符
2. 字符串有一个 索引 属性
+ 是一个 只读 的属性, 只能获取不能设置
=> 语法: 字符串[索引]
=> 获取到的就是该字符串指定索引位置的那一位字符
-> 如果没有该索引位置, 那么就是 undefined
+ 索引: 从0开始, 依次+1
3. 遍历字符串
+ 使用 for 循环进行遍历
字符串常用方法(结果是以返回值的形式出现)
+ 字符串常用方法为什么会出现 ?
=> 因为字符串并不好操作
+ 字符串常用方法的统一语法
=> 字符串.xxx()
+ 注意: 所有字符串常用方法, 都不会改变原始字符串
1. charAt() // 根据索引找到对应的字符
=> 语法: 字符串.charAt(索引)
=> 返回值: 该索引位置的对应字符
-> 如果有该索引位置, 那么就是该索引位置的字符
-> 如果没有该索引位置, 那么就是 空字符串 ''
2. charCodeAt() // 根据索引找到对应字符的编码
=> 语法: 字符串.charCodeAt(索引)
=> 返回值: 该索引位置的对应字符的 编码(十进制)
3. toUpperCase() // 转大写
=> 语法: 字符串.toUpperCase()
=> 作用: 把所有字母转换成 大写
=> 返回值: 转换好的字符串
4. toLowerCase() // 转小写
=> 语法: 字符串.toLowerCase()
=> 作用: 把所有字母转换成 小写
=> 返回值: 转换好的字符串
5. substr() // 截取字符串
=> 语法: 字符串.substr(开始索引, 多少个)
=> 作用: 截取字符串
=> 返回值: 截取出来的字符串
6. substring() // 截取字符串
=> 语法: 字符串.substring(开始索引, 结束索引)
-> 包前不包后
=> 作用: 截取字符串
=> 返回值: 截取出来的字符串
7. slice() // 截取字符串**
=> 语法: 字符串.slice(开始索引, 结束索引)
-> 包前不包后
-> 可以填写负整数
=> 作用: 截取字符串
=> 返回值: 截取出来的字符串
8. replace() // 替换字符串*
=> 语法: 字符串.replace(换下字符, 换上字符)
=> 作用: 使用换上字符替换掉字符串内的换下字符
=> 注意: 只能替换出现的第一个, 只能替换一个
=> 返回值: 替换好的字符串
9. split() // 切割字符串***
=> 语法: 字符串.split('切割符号')
-> 可以不传递, 会把完整字符串当做一个整体
-> 传递一个空字符串(''), 会一位一位的切割
=> 作用: 按照切割符号, 把字符串切割开, 放在一个数组里面
=> 返回值: 是一个数组, 内容就是按照切割符号切割开的每一个部分
10. concat() // 字符串拼接*
=> 语法: 字符串.concat(字符串)
=> 作用: 字符串拼接
=> 返回值: 拼接好的字符串
11. indexOf() // 查找某一个字符在字符串中的索引位置
=> 语法: 字符串.indexOf(字符, 开始索引)
=> 作用: 检测该字符在字符串内的索引位置
=> 返回值:
-> 如果有该字符内容, 那么就是该字符的索引位置
-> 如果没有该字符内容, 就是 -1
12. lastIndexOf() // 从后向前查找某一个字符在字符串中的索引位置
=> 语法: 字符串.lastIndexOf(字符, 开始索引)
=> 作用: 从后向前检测该字符在字符串内的的索引位置
=> 返回值:
-> 如果有该字符内容, 那么就是该字符的索引位置
-> 如果没有该字符内容, 就是 -1
13. trim() // 去除首尾空白***
=> 语法: 字符串.trim()
=> 作用: 去除字符串首尾的空白内容
=> 返回值: 去除空白内容以后的字符串
14. trimStart() / trimLeft() // 去除开始位置空白
=> 语法:
-> 字符串.trimStart()
-> 字符串.trimLeft()
=> 作用: 去除前面的空白内容
=> 返回值: 去除前面空白内容以后的字符串
15. trimEnd() / trimRight() // 去除结束位置空白
=> 语法:
-> 字符串.trimEnd()
-> 字符串.trimRight()
=> 作用: 去除后面的空白内容
=> 返回值: 去除后面空白内容以后的字符串
查询字符串格式
-> key=value&key=value
-> 'name=zhangsan&password=123456&gender=男'
解析完毕的对象 { name: 'jack', age: 18, gender: '男', classRoom: 2109 }
封装--对象 与 字符串 转换_tby_pr的博客-CSDN博客
json 格式字符串(返回值)
str = '{"name":"Jack","age":18,"gender":"男"}'
-> key 和 value 必须使用 双引号 包裹, 纯数字和布尔值可以不用
把 js 的数据类型转换成 json 格式
+ 语法: JSON.stringify(要转换的 js 的数据类型)
+ 返回值: json 格式字符串
把 json 格式转换成 js 的数据类型
+ 语法: JSON.parse(json 格式字符串)
+ 返回值: js 的数据类型
+ 注意: 如果你的小括号内填写的不是一个 json 格式的字符串, 会报错
操作 数字 的常用方法
+ 专门提供给我们进行数字的操作
+ 统一语法: Math.xxx()
1. Math.random() // 随机小数**
=> 语法: Math.random()
=> 作用: 获取一个 0 ~ 1 之间的随机小数
=> 返回值: 一个 0 ~ 1 之间的随机小数
=> 注意: 有可能得到 0, 但是绝不可能得到 1
2. Math.round() // 四舍五入*
=> 语法: Math.round(数字)
=> 返回值: 四舍五入取整后的结果
3. Math.ceil() // 向上取整*
=> 语法: Math.ceil(数字)
=> 返回值: 向上取整以后的结果
4. Math.floor() // 向下取整*
=> 语法: Math.floor(数字)
=> 返回值: 向下取整以后的结果
5. Math.abs() // 绝对值
=> 语法: Math.abs(数字)
=> 返回值: 取绝对值以后的结果
6. Math.pow() // 取幂
=> 语法: Math.pow(底数, 指数)
=> 返回值: 取幂以后的结果
7. Math.sqrt() // 算术平方根
=> 语法: Math.sqrt(数字)
=> 返回值: 该数字的算术平方根
8. Math.max() // 最大值*
=> 语法: Math.max(数字1, 数字2, 数字3, ...)
=> 返回值: 若干个数字中的最大值
9. Math.min() // 最小值*
=> 语法: Math.min(数字1, 数字2, 数字3, ...)
=> 返回值: 若干个数字中的最小值
10. Math.PI // 近似 π
=> 语法: Math.PI
=> 得到的就是一个近似 π 的值
保留小数位 // 数字.toFixed(保留几位小数)
=> 返回值: 是一个字符串类型, 就是保留好的小数
=> 注意:
1. 返回值是一个 **字符串类型**
2. 当小数位不够的时候, 使用 0 补齐
范围内随机数 与 随机RGB颜色
封装--范围内随机数 与 随机RGB颜色_tby_pr的博客-CSDN博客
范围内的随机整数
let num = randomNum(数字1,数字2)
一个随机颜色 rgb 形式
let color = randomColor()
document.body.style.backgroundColor = color
时间对象
+ 时间是一个 js 内的复杂数据类型
+ 专门存储时间信息的
获取时间对象 + 语法: var time = new Date()
+ 得到: 当前终端的时间信息
=> 注意: 和你终端设置的时区有关系
格林威治时间: 1970 年 1 月 1 日 0 点 0 分 0 秒
创建一个指定时间的时间对象
+ 通过传递参数的方式来实现
1. 传递数字 // time = new Date(2003, 11, 31, 23, 59, 60)
+ 注意:
=> 至少传递两个数字, 一个不好使
=> 每一个数字都会自动进位
1-1. 表示年份的数字信息
1-2. 表示月份的数字信息
=> 注意: 0 表示 1 月, 11 表示 12 月
1-3. 表示日期的数字信息
1-4. 表示小时的数字信息
=> 注意: 24 小时制的数字
1-5. 表示分钟的数字信息
1-6. 表示秒钟的数字信息
2. 传递字符串 // time = new Date('2003/2/23 13:53:36')
+ 'yyyy-mm-dd hh:mm:ss'
+ 'yyyy/mm/dd hh:mm:ss'
+ 注意:
=> 当你传递字符串的时候, 1 表示 1 月, 12 表示 12 月
=> 年月日 和 时分秒 之间一定要有一个 空格
时间对象常用方法 - 获取get(返回值) - 设置set
1. getFullYear()年份
=> 语法: 时间对象.getFullYear()
=> 返回值: 该时间对象内的年份信息
2. getMonth()月份
=> 语法: 时间对象.getMonth()
=> 返回值: 该时间对象内的月份信息
=> 注意: 0 表示 1 月, 11 表示 12 月
3. getDate()日期
=> 语法: 时间对象.getDate()
=> 返回值: 该时间对象内的日期信息
4. getHours()24 小时制
=> 语法: 时间对象.getHours()
=> 返回值: 该时间对象内的小时信息
=> 注意: 获取到的是 24 小时制的小时时间
5. getMinutes()分钟
=> 语法: 时间对象.getMinutes()
=> 返回值: 该时间对象内的分钟信息
6. getSeconds()秒
=> 语法: 时间对象.getSeconds()
=> 返回值: 该时间对象内的秒钟信息
7. getMilliSeconds()毫秒
=> 语法: 时间对象.getMilliSeconds()
=> 返回值: 该时间对象内的毫秒信息
8. getDay()
=> 语法: 时间对象.getDay()
=> 返回值: 该时间对象是一周中的第几天, 周几
=> 注意: 0 表示周日, 1 ~ 6 表示周一到周六
9. getTime()时间戳**
=> 语法: 时间对象.getTime()
=> 返回值: 该时间对象的时间戳
=> 时间戳: 时间对象 ~ 格林威治时间 的 毫秒数
封装--格式化时间
Tue Oct 12 2021 19:51:48 GMT+0800 (中国标准时间)
2021 年 10 月 12 日 下午 7 点 51 分 48 秒 星期二
封装--格式化时间_tby_pr的博客-CSDN博客
封装--获取时间差(倒计时/秒杀)
+ 时间差: 两个时间节点之间相差的时间
+ 分析:
=> 拿到两个时间节点的时间戳相减, 得到两个时间节点之间相差的毫秒数
=> 最好在拿到的时候直接转换为秒
封装--获取时间差(倒计时/秒杀)_tby_pr的博客-CSDN博客
定时器
+ js 提供给我们的一个代码机制
+ 可以按照定时器规则去执行代码
+ 定时器分类:
1. 延时定时器(炸弹定时器)
=> 在一段固定时间后执行一段 js 代码
=> 只执行一次, 就没有了
2. 间隔定时器
=> 每间隔固定时间后执行一段 js 代码
=> 永不停止, 除非手动关闭
开启定时器
1. 延时定时器 => 语法: setTimeout(函数, 数字)
=> 函数: 在固定时间后执行的代码
=> 数字: 表示延后多少时间执行, 单位是 ms
2. 间隔定时器 => 语法: setInterval(函数, 数字)
=> 函数: 在间隔固定时间以后执行的代码
=> 数字: 表示每次间隔多少时间, 单位是 ms
定时器的返回值
+ 不分定时器种类, 都是一个数字
+ 表示的是你是页面上的第几个定时器
关闭定时器
1. clearTimeout()
=> 语法: clearTimeout(数字)
=> 数字: 你要关闭页面上的第几个定时器
2. clearInterval()
=> 语法: clearInterval(数字)
=> 数字: 你要关闭页面上的第几个定时器
+ 不分定时器种类
+ 只要给的数字是对的就可以了
开启定时器例子
let t1 = setTimeout(function () { console.log('timeout') }, 3000)
let t2 = setInterval(function () { console.log('interval') }, 1000)
关闭定时器例子
clearInterval(t1)
clearInterval(t2)
认识 BOM 浏览器对象模型
+ 全名: Browser Object Model,
=> 私人: 一整套操作浏览器的属性和方法
=> 注意: BOM 不是 js 给的, 是 浏览器 给的
-> BOM 的规则是浏览器制造厂商给的
=> 就是利用 js 的语法去操作浏览器的相关内容
-> 操作浏览器滚动条
-> 操作浏览器历史记录
-> 操作浏览器的窗口尺寸
-> 操作浏览器的地址栏(浏览器地址)
-> ...
+ BOM 的顶级对象是 window(窗口)
=> 所有和 BOM 相关的内容都是, window.xxx
=> 在书写的时候, 都可以省略 window. 不写
+ 一个小问题 :
=> DOM, 是操作页面
=> DOM 也是 BOM 下的一部分
浏览器的窗口尺寸 可视窗口宽度和高度(包含滚动条)
1. window.innerWidth宽度
2. window.innerHeight高度
+ 注意: 获取到的尺寸是包含滚动条在内的尺寸
浏览器的三种弹出层
1. 提示框: window.alert()
=> 表现: 有一段提示文本, 和一个确定按钮
=> 语法: window.alert('文本内容')
=> 返回值: 没有
2. 选择框: window.confirm()
=> 表现: 在 提示框 的基础上多了一个 取消 按钮
=> 语法: window.confirm('文本内容')
=> 返回值: 是一个布尔值
-> 当用户点击取消的时候, 就是 false
-> 当用户点击确定的时候, 就是 true
3. 输入框: window.prompt()
=> 表现: 在 选择框 的基础上多了一个 输入框
=> 语法: window.prompt('文本内容')
=> 返回值:
-> 如果用户点击的是取消, 那么就是 null
-> 如果用户点击的是确定, 那么就是文本框内的内容
=> 注意: 不管文本框内书写的是什么, 都是 字符串 类型
+ 共同点:
=> 都会阻断程序的继续执行
=> 直到用户操作为止
浏览器的地址栏***!!! // widnow.location
+ 在 widnow 下有一个成员叫做 location 里面存储的都是和地址栏相关的内容
1. href
+ 是一个 读写 的属性
+ 读:
=> 语法: window.location.href
=> 得到: 就是当前页面的地址栏完整信息
=> 注意: 拿到的是 url 编码格式的地址
+ 写:
=> 语法: window.location.href = '地址'
=> 作用: 把当前地址栏的地址修改
2. reload()
+ 是一个方法, 使用的时候需要加 ()
+ 语法: window.location.reload()
+ 作用: 把当前页面重新加载一遍, 刷新
+ 注意: 不要写在打开页面就能执行的地方
window.location.href(当前URL)
结果如下:
http://www.myurl.com:8866/test?id=123&username=xxxwindow.location.protocol(协议)
结果如下:
http:window.location.host(域名 + 端口)
结果如下:
www.baidu.com:8080window.location.hostname(域名)
结果如下:
www.baidu.com
window.location.port(端口):
结果如下:
8080window.location.pathname(路径部分)/
结果如下:
/testwindow.location.search(请求的参数)?
结果如下:
?id=123&username=xxxwindow.location.hash(路径部分)#
结果如下:
#home
浏览器的历史记录***!!! // window.history
+ window 下有一个成员叫做 history, 里面存储的都是和历史记录相关的信息
1. 历史回退 window.history.back()
=> 作用: 回到上一个历史页面
=> 前提: 你必须得有上一个页面, 当前页面是从某一个页面跳转过来的
=> 等价于浏览器左上角的 ← 按钮
2. 历史前进 widnow.history.forward()
=> 作用: 去到下一个页面
=> 前提: 你必须得有下一个页面, 当前也是是从某一个页面回退回来的
=> 等价于浏览器左上角的 → 按钮
3. 历史跳转 window.history.go(数字)
-> 正整数 历史前进
-> 0 从新打开当前页面
-> 负整数 历史回退
=> 作用: 进行历史跳转, 根据参数的不同进行不同的跳转
浏览器的标签页***!!!
+ 操作浏览器标签页的方法
1. open()
=> 语法: window.open('地址')
=> 作用: 开启一个新的标签页打开指定地址
2. close()
=> 语法: window.close()
=> 作用: 关闭当前标签页
浏览器的常见事件
+ 由浏览器行为触发的事件
1. onload(所有资源加载完毕后触发)
=> 语法: window.onload = function () {}
=> 时机: 页面所有资源(html 结构, 视音频, 图片 等)加载完毕后触发
=> 作用:
-> 当你把 js 代码书写在 head 内的时候, 并且还需要操作页面元素
-> 需要书写一个 window.onload 事件
=> 注意: 这种书写方式, 只能绑定一个函数
2. onresize(可视窗口尺寸改变触发)
=> 语法: window.onresize = function () {}
=> 时机: 页面可视窗口尺寸改变的时候触发
-> 不管横向还是纵向, 只要尺寸改变了, 就会触发
=> 作用:
-> 响应式布局
-> 在移动端判断横屏
3. onscroll(滚动条改变位置的触发)
=> 语法: window.onscroll = function () {}
=> 时机: 页面滚动条改变位置的时候偶触发
-> 不管横向还是纵向, 只要滚动条位置改变了, 就会触发
浏览器卷去的尺寸***!!!
+ 分成 卷去的 高度 和 宽度
卷去的高度
+ 语法:
=> document.documentElement.scrollTop
-> 当页面有 DOCTYPE 标签的时候使用
=> document.body.scrollTop
-> 当页面没有 DOCTYPE 标签的时候使用
+ 兼容:
=> 自己定义一个变量兼容
=> var scrollTop = document.documentElement.scrollTop || document.body.scrollTop
卷去的宽度
+ 语法:
=> document.documentElement.scrollLeft
-> 当页面有 DOCTYPE 标签的时候使用
=> document.body.scrollLeft
-> 当页面没有 DOCTYPE 标签的时候使用
+ 兼容:
=> 自己定义一个变量兼容
=> var scrollLeft = document.documentElement.scrollLeft || document.body.scrollLeft
浏览器滚动到
+ 对浏览器的滚动条进行定位
=> 其实就是设置浏览器卷去的高度和宽度
scrollTo()
+ 根据传递不同的参数决定不同的表现形式
+ 参数方案1:
=> 传递数字
=> 语法: window.scrollTo(x, y)
-> x: 表示设置卷去的宽度
-> y: 表示设置卷去的高度
=> 注意:
-> 如果你传递数字设置, 必须传递两个参数
-> 只能进行瞬间定位, 不能平滑滚动
+ 参数方案2:
=> 传递一个对象数据类型
=> 语法: window.scrollTo({
top: yyy,
left: xxx,
behavior: 'smooth'
})
=> 注意:
-> 如果你传递对象数据类型, 那么在对象内, 可以只写一个值
-> 默认是瞬间定位, 可以通过对象内的第三个成员来让他实现平滑滚动
认识 DOM
+ 全名: Document Object Model 文档对象模型
=> 私人: 一整套操作文档流的属性和方法
=> 其实就是在操作页面元素
-> 操作页面元素改变文本内容(增删改查)
-> 操作页面元素改变样式
-> 操作删除一个页面元素
-> 操作添加一个页面元素
-> ...
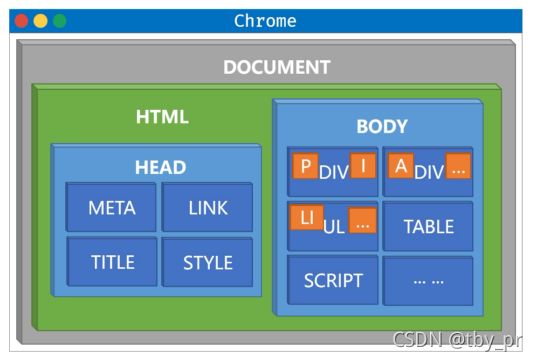
+ DOM 以树状结构出现的
=> 顶层是 document
=> 最大的标签是 html
=> 下面分成 head 和 body
=> body 下面就是一些元素标签
=> 操作 DOM 就是对这个 "树上" 的某个枝杈进行修剪或者修饰
+ 操作 DOM 的过程
1. 找到你要操作的 "树杈" : 获取元素
2. 对这个枝杈进行各种操作 : 操作 API
获取元素
+ 用一个变量来表示页面中的某一个标签
=> 当我用这个变量来操作的时候, 就是在操作这个标签
1. id 直接使用
=> 给一个元素标签设置一个 id 属性
=> id 名是一个天生的变量, 可以在 js 内直接使用
=> 表示的就是这个标签元素
=> 强烈不推荐使用
2. 有自己的获取元素的方式
=> 获取非常规标签(html, body, head)
=> 获取常规标签(所有标签)
获取非常规标签
1. html:
=> 语法: document.documentElement
=> 得到的就是该页面的 html 标签
2. head:
=> 语法: document.head
=> 得到的就是该页面的 head 标签
3. body:
=> 语法: document.body
=> 得到的就是该页面的 body 标签
获取常规标签
1. 根据 id 获取元素
=> 语法: document.getElementById('id名称')
=> 返回值:
-> 如果页面中有 id 对应的元素, 那么就是这个元素
-> 如果页面中没有 id 对应的元素, 那么就是 null
2. 根据 类名 获取元素(集合 [n] )
=> 语法: document.getElementsByClassName('类名')
=> 返回值: 必然是一个 **伪数组**
-> 如果页面上有 类名 对应的元素, 那么有多少获取多少, 放在伪数组内返回
-> 如果页面上没有 类名 对应的元素, 那么就是一个空的伪数组
=> 注意: 你拿到的不是这个元素, 而是一个集合, 集合内的 [n] 才是元素
3. 根据 标签名 获取元素(集合 [n] )
=> 语法: document.getElementsByTagName('标签名')
=> 返回值: 必然是一个 **伪数组**
-> 如果页面上有 标签名 对应的元素, 那么有多少获取多少, 放在伪数组内返回
-> 如果页面上没有 标签名 对应的元素, 那么就是一个空的伪数组
=> 注意: 你拿到的不是这个元素, 而是一个集合, 集合内的 [n] 才是元素
4. 根据 name 属性来获取元素(集合 [n] )
=> 语法: document.getElementsByName('name属性')
=> 返回值: 必然是一个 **伪数组**
-> 如果页面上有 name 属性对应的元素, 那么有多少获取多少, 放在伪数组内返回
-> 如果页面上没有 name 属性对应的元素, 那么就是一个空的伪数组
=> 注意: 你拿到的不是这个元素, 而是一个集合, 集合内的 [n] 才是元素
5. 根据 选择器 获取第一个元素***
=> 语法: document.querySelector('选择器')
-> 选择器: 就是 css 中捕获元素的内容
-> .box #box div li:nth-child(1) ...
=> 返回值:
-> 如果页面上有该 选择器 对应的元素, 那么就是满足条件的 **第一个**
-> 如果页面上没有该 选择器 对应的元素, 那么就是 null
6. 根据 选择器 获取一组元素(集合 [n] )**
=> 语法: document.querySelectorAll('选择器')
-> 选择器: 就是 css 中捕获元素的内容
-> .box #box div li:nth-child(1) ...
=> 返回值: 必然是一个 **伪数组**
-> 如果页面上有该 选择器 对应的元素, 那么有多少获取多少, 放在伪数组内返回
-> 如果页面上没有该 选择器 对应的元素, 那么就是空的伪数组
=> 注意: 你拿到的不是这个元素, 而是一个集合, 集合内的 [n] 才是元素
操作元素内容
1. innerText
+ 是一个 读写 的属性
+ 读:
=> 语法: 元素.innerText
=> 得到: 该元素内的所有文本内容
+ 写:
=> 语法: 元素.innerText = '值'
=> 作用: 完全覆盖式的书写该元素内的文本内容
=> 注意: 如果你设置一个 html 格式的字符串, 那么不会解析出来的
2. innerHTML
+ 是一个 读写 的属性
+ 读:
=> 语法: 元素.innerHTML
=> 得到: 该元素下的所有内容, 以字符串的形式给你
+ 写:
=> 语法: 元素.innerHTML = '值'
=> 作用: 完全覆盖式的书写该元素内的超文本内容
=> 注意: 如果你设置的是一个 html 格式的字符串, 那么会把标签内容解析出来
3. value
+ 是一个 读写 的属性
+ 读:
=> 语法: 表单元素.value
=> 得到: 该标签元素的 value 值
+ 写:
=> 语法: 表单元素.value = '值'
=> 作用: 完全覆盖式的书写该表单元素的 value 值
动态渲染页面--前端必备技能
动态渲染表格
+ 意义: 根据一个数据(数组 / 对象), 把页面的 html 结构完成
知识点: 模板字符串
=> JS 定义字符串的一种方式
=> 只不过是使用 反引号(``) 来定义
=> 区别:
1. 反引号 定义的字符串 可以换行书写
2. 可以直接在字符串内解析变量
+ 当你需要解析变量的时候, 直接书写 ${变量}
动态渲染表格_tby_pr的博客-CSDN博客
认识元素的属性
+ 一个元素的属性由 属性名="属性值" 组成的
认识属性的分类
+ 在 html 内, 元素的属性大致分成三类
1. 原生属性, 在 html 规范内有的属性
=> 比如 id, class, style, type, ...
=> 对于标签有特殊意义
2. 自定义属性, 在 html 规范内没有的属性
=> 我们自己随便书写的一个属性名, 对于标签没有特殊意义
=> 只是为了标注一些内容在标签身上
3. H5 自定义属性
=> H5 标准下提出的一个自定义属性的书写方式
=> 书写规则: data- 开头
=> 例子: data-a="100"
-> 属性名: a ,属性值: 100
操作元素属性
1. 操作原生属性
+ 直接使用 元素.属性名 的形式进行操作
+ 读:
=> 语法: 元素.属性名
=> 得到: 该元素, 该属性名对应的属性值
+ 写:
=> 语法: 元素.属性名 = 属性值
=> 作用: 修改该元素的该属性的值
2. 操作自定义属性
2-1. 获取自定义属性的值
=> 语法: 元素.getAttribute('属性名')
=> 返回值: 该元素内该属性名对应的属性值
2-2. 设置自定义属性的值
=> 语法: 元素.setAttribute('属性名', '属性值')
=> 作用: 给元素设置一个自定义属性
2-3. 删除自定义属性
=> 语法: 元素.removeAttribute('属性名')
=> 作用: 删除该元素的某一个属性
3. 操作 H5 自定义属性
+ 在元素身上有一个叫做 dataset 的成员
+ 是一个类似 对象 的数据类型
+ 里面存储着所有的元素身上以 data- 开头的 H5 自定义属性
+ 我们对于 H5 自定义属性的操作, 就是对这个 类似对象 数据的操作
+ 以上所有操作元素属性的方法
=> 注意 : 一般不操作元素的 类名 和 样式
H5 自定义属性的操作 // dataset
// 3-1. 获取某一个自定义属性的值
console.log(box.dataset.a)
// 3-2. 修改某一个自定义属性的值
box.dataset.a = 200
// 3-3. 增加某一个自定义属性
box.dataset.b = 300
// 3-4. 删除某一个自定义属性
delete box.dataset.a
案例--密码小眼睛(星号 和 显示的切换)
案例--密码小眼睛(星号 和 显示的切换)_tby_pr的博客-CSDN博客
案例--input全选 与 复选框
案例--input全选 与 复选框_tby_pr的博客-CSDN博客
操作元素样式
+ 在 JS 内操作元素样式分成三种
1. 设置元素的行内样式
2. 获取元素行内样式(只能获取到行内样式)
3. 获取元素非行内样式(可以获取行内样式也可以获取非行内样式)
1. 设置元素的行内样式
+ 语法: 元素.style.样式名 = 样式值
+ 给元素设置行内样式
+ 注意: 样式名带有中划线的名字, 需要写成驼峰或者数组关联语法
2. 获取元素的行内样式
+ 语法: 元素.style.样式名
+ 得到: 该元素指定样式对应的值
+ 注意: 只能拿到行内样式的值, 非行内样式是拿不到值的
+ 注意: 样式名带有中划线的名字, 需要写成驼峰或者数组关联语法
3. 获取元素非行内样式***!!!
+ 标准浏览器
=> 语法: window.getComputedStyle(要获取样式的元素).样式名
window.getComputedStyle(box).width
=> 返回值: 该元素指定样式对应的值
=> 注意: 样式名带有中划线的名字, 需要写成驼峰或者数组关联语法
=> 注意: 行内和非行内都能拿到样式值, 但是只能在标准浏览器下使用
+ IE 低版本
=> 语法: 元素.currentStyle.样式名
=> 得到: 该元素指定样式对应的值
=> 注意: 样式名带有中划线的名字, 需要写成驼峰或者数组关联语法
=> 注意: 行内和非行内都能拿到样式值, 但是只能在 IE 低版本浏览器下使用
操作元素类名!!!***
1. className
+ 实际上就是操作元素的原生属性
+ 只不过在 JS 内 class 是一个关键字
+ 所以我们操作的原生属性改名叫做 className
+ 读:
=> 元素.className
=> 得到的就是元素的完整 类名
+ 写:
=> 元素.className = '值'
=> 作用: 设置元素类名, 完全覆盖式的设置
+ 追加:
=> 元素.className += ' 值'
=> 注意: 值的位置要书写一个空格
2. classList
+ 每一个元素有一个属性叫做 classList
+ 是一个类似数组的集合, 里面记录了元素所有的类名
+ 添加一个类名
=> 语法: 元素.classList.add('要添加的类名')
=> 作用: 给该元素添加一个类名, 但是重复的不会添加进去了
+ 删除一个类名
=> 语法: 元素.classList.remove('要删除的类名')
=> 作用: 该该元素删除一个类名
+ 切换一个类名
=> 语法: 元素.classList.toggle('要切换的类名')
=> 作用: 该元素切换一个类名
-> 切换: 有就删除, 没有就添加
案例--选项卡(简单版)
案例--选项卡(简单版)_tby_pr的博客-CSDN博客
案例--分页渲染
案例--分页渲染_tby_pr的博客-CSDN博客
获取元素尺寸/占地面积(display: none时拿不到尺寸)!!!***
+ 元素尺寸(私人): 占地面积
=> 一个元素在页面(文档流)内占多少位置
1. offsetWidth 和 offsetHeight(内容 + padding + border 区域)
=> 语法:
-> 元素.offsetWidth
-> 元素.offsetHeight
=> 得到:
-> 该元素的 内容 + padding + border 区域的尺寸
=> 注意:
-> 不管盒子模型是什么状态, 都是 内容 + padding + border 区域的尺寸
-> 当元素被 display: none; 的时候, 是拿不到尺寸的
2. clientWidth 和 clientHeight(内容 + padding 区域)
=> 语法:
-> 元素.clientWidth
-> 元素.clientHeight
=> 得到:
-> 该元素的 内容 + padding 区域的尺寸
=> 注意:
-> 不管盒子模型是什么状态, 都是 内容 + padding 区域的尺寸
-> 当元素被 display: none; 的时候, 是拿不到尺寸的
获取元素偏移量,从定位父级(元素.offsetTop/offsetLeft)!!**
+ 相对于参考元素的 左边 和 上边 的距离
一个元素结构有两个父级
+ 结构父级: 书写在这个标签外部的标签
+ 定位父级: 当你需要给 p 标签设置绝对定位的时候, 根据谁来定位, 谁就是他的定位父级
=> 如果到窗口以后, 那么定位父级就是 body
1. 元素的偏移量参考元素是谁 ?
=> 就是这个元素的 定位父级
=> 就是假设需要给这个元素设置绝对定位的时候, 根据谁定位
=> 你获取偏移量的时候, 就参考谁
2. offsetLeft 和 offsetTop
=> 语法:
-> 元素.offsetLeft
-> 元素.offsetTop
=> 得到:
-> 该元素相对于参考元素 左边 和 上边 的距离
获取窗口尺寸
+ BOM 级别的获取(包滚动条)
=> 语法:
-> window.innerWidth
-> window.innerHeight
=> 得到:
-> 窗口的宽度和高度
-> 是包含滚动条的尺寸
+ DOM 级别的获取(不包滚动条)
=> 语法:
-> document.documentElement.clientWidth
-> document.documentElement.clientHeight
=> 得到:
-> 可视窗口的宽度和高度
-> 不包含滚动条的尺寸
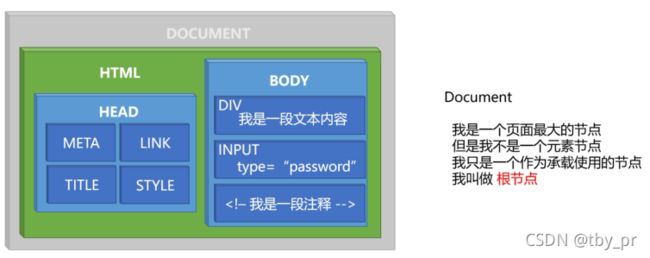
DOM 节点的操作
+ 什么是节点 ?
=> 页面的每一个组成部分
+ 注意 :
=> 标签是一个节点
=> 节点不都是标签
+ 在一个页面内
=> 所有内容都是一个一个的节点
=> document
=> 元素节点(标签)
=> 文本节点(文本内容)
=> 注释节点(注释内容)
=> 属性节点: 一个标签身上书写的属性(包含自定义属性和原生属性), 不作为独立节点出现
=> ...




+ 节点操作: 对节点的增删改查
获取节点
1. 获取元素节点
1-1. 非常规标签
=> html
=> body
=> head
1-2. 常规标签
=> getElementById()
=> getElementsByClassName()
=> getElementsByTagName()
=> getElementsByName()
=> querySelector()
=> querySelectorAll()
2. 获取节点(包含但不限于元素节点)!*
2-1. childNodes 所有子节点
=> 语法: 父节点.childNodes
=> 得到: 是一个伪数组, 内部包含该父节点下的所有子一级 节点
2-2. children 所有子元素
=> 语法: 父节点.children
=> 得到: 是一个伪数组, 内部包含该父节点下的所有子一级 元素节点
2-3. firstChild 第一个子节点
=> 语法: 父节点.firstChild
=> 得到: 该父节点下的第一个子 节点
2-4. firstElementChild 第一个子元素
=> 语法: 父节点.firstElementChild
=> 得到: 该父节点下的第一个子 元素节点
2-5. lastChild 最后一个子节点
=> 语法: 父节点.lastChild
=> 得到: 该父节点下的最后一个子 节点
2-6. lastElementChild 最后一个子元素
=> 语法: 父节点.lastElementChild
=> 得到: 该父节点下的最后一个子 元素节点
2-7. previousSibling 上一个兄弟节点
=> 语法: 节点.previousSibling
=> 得到: 该节点的上一个兄弟 节点
2-8. previousElementSibling 上一个兄弟元素
=> 语法: 节点.previousElementSibling
=> 得到: 该节点的上一个兄弟 元素节点
2-9. nextSibling 下一个兄弟节点
=> 语法: 节点.nextSibling
=> 得到: 该节点的下一个兄弟 节点
2-10. nextElementSibling 下一个兄弟元素
=> 语法: 节点.nextElementsSibling
=> 得到: 该节点的下一个兄弟 元素节点
2-11. parentNode 父节点
=> 语法: 节点.parentNode
=> 得到: 该节点的父 节点
2-12. parentElement 父元素
=> 语法: 节点.parentElement
=> 得到: 该节点的父 元素节点
2-13. attributes 所有属性节点
=> 语法: 节点.attributes
=> 得到: 是一个类似于数组的数据结构, 里面包含该元素的所有属性节点
创建一个节点!!!***
+ 无中生有, 凭空捏造
+ 利用 js 代码创建一个 节点 出来
1. 创建元素节点***
=> 语法: document.createElement('你要创建的标签名')
=> 可以创建 W3C 规范内的标签, 也可以创建自定义标签
=> 返回值: 一个元素节点
2. 创建文本节点
=> 语法: document.createTextNode('文本内容')
=> 返回值: 就是一个文本节点, 不是字符串
插入一个节点!!!***
+ 把一个节点插入到另一个节点内容
+ 不一定非得是插入到页面上
1. appendChild()
=> 语法: 父节点.appendChild(子节点) // 插入最后
=> 作用: 把该子节点插入到父节点内部, 并且排列在最后的位置
2. insertBefore()
=> 语法: 父节点.insertBeofre(子节点, 谁的前面)
=> 作用: 把该子节点插入到父节点内部, 并且排列在哪一个节点的前面
=> 删除一个节点
+ 把一个节点删除掉
+ 不一定非得删除页面上的, 只要是节点, 在某一个节点内, 就可以删除
1. removeChild()
=> 语法: 父节点.removeChild(子节点)
=> 作用: 把该子节点从父节点内移除
2. remove()
=> 语法: 节点.remove()
=> 作用: 自杀, 直接把自己移除
=> 替换一个节点
1. replaceChild()
=> 语法: 父节点.replaceChild(换上节点, 换下节点)
=> 作用: 在该父节点内, 使用换上节点替换掉换下节点
=> 克隆一个节点
+ 把某一个节点复制一份一模一样的出来
1. cloneNode()
=> 语法: 节点.cloneNode(参数)
-> 参数: 选填
-> 默认是 false, 表示不克隆后代节点
-> 选填是 true, 表示克隆后代节点
=> 返回值: 该节点复制了一份一模一样的
节点属性
+ 用来描述一类 节点 特点的一个属性
1. nodeType // 表示节点类名, 以一个数字的形式表示
+ 元素节点.nodeType : 1
+ 属性节点.nodeType : 2
+ 文本节点.nodeType : 3
+ 注释节点.nodeType : 8
2. nodeName // 表示节点名称
+ 元素节点.nodeName : 大写标签名***
+ 属性节点.nodeName : 属性名
+ 文本节点.nodeName : #text
+ 注释节点.nodeName : #comment
3. nodeValue // 表示该节点的内容部分
+ 元素节点.nodeValue : null
+ 属性节点.nodeValue : 属性值
+ 文本节点.nodeValue : 文本内容(包含换行和空格)
+ 注释节点.nodeValue : 注释内容(包含换行和空格)
案例--瀑布流渲染/无限下拉
案例--瀑布流渲染/无限下拉_tby_pr的博客-CSDN博客
了解事件
+ 我们使用代码的方式 和 一个内容 约定好一个行为
=> 当你打开浏览器, 触发了该行为的时候
=> 会有对应的代码执行
事件三要素:
1. 事件源: 和谁约定事件(和由谁触发不一样)
2. 事件类型: 约定了一个什么事件
3. 事件处理函数: 当行为发生的时候, 需要执行的函数
+ 这三个内容目的是为了绑定事件, 注册事件, 就是提前做好约定
事件绑定:
1. DOM 0级 事件
=> 语法: 事件源.on事件类型 = 事件处理函数
=> 注意: 给一个事件源的同一个事件类型, 只能绑定一个事件处理函数
2. DOM 2级 事件(事件侦听器 / 事件监听器)
2-1. 标准浏览器
=> 语法: 事件源.addEventListener('事件类型', 事件处理函数)
=> 特点:
-> 可以给同一个事件源的同一个事件类型绑定多个事件处理函数
-> 多个事件处理函数, 顺序绑定, 顺序执行
2-2. IE 低版本
=> 语法: 事件源.attachEvent('on事件类型', 事件处理函数)
=> 特点:
-> 可以给同一个事件源的同一个事件类型绑定多个事件处理函数
-> 多个事件处理函数, 顺序绑定, 倒序执行
事件解绑
1. DOM 0级 事件解绑
=> 语法: 事件源.on事件类型 = null
=> 因为赋值符号, 当你给这个事件类型赋值为 null 的时候
-> 会把本身的事件处理函数覆盖
-> 当你再次出发行为的时候, 没有事件处理函数执行
-> 相当于解绑了事件
2. DOM 2级 事件解绑
2-1. 标准浏览器解绑
=> 语法: 事件源.removeEventListener('事件类型', 事件处理函数)
2-2. IE 低版本解绑
=> 语法: 事件源.detachEvent('on事件类型', 事件处理函数)
+ 注意:
=> 当你使用 DOM 2级 事件解绑的时候
=> 因为函数是一个复杂数据类型, 所以你在绑定的时候
=> 需要把函数单独书写出来, 以函数名的形式进行绑定和解绑
事件类型
+ JS 给我们提供了哪些事件可以直接使用
+ 注意: JS 的原生事件没有大写字母
+ 在 JS 内事件类型大致分为几类
1. 鼠标事件
2. 键盘事件
3. 浏览器事件
4. 表单事件
5. 触摸事件
6. 其他事件
鼠标事件 // 事件源.on事件=函数
+ 依赖鼠标行为触发的事件
1. click: 鼠标左键单击
2. dblclick: 鼠标左键双击
3. contextmenu: 鼠标右键单击
4. mousedown: 鼠标按下(任何一个按键按下)
5. mouseup: 鼠标抬起
6. mousemove: 鼠标移动(光标只要位置变换就会触发)
7. mouseover: 鼠标移入(光标从外面进入事件源范围内)
8. mouseout: 鼠标移出(光标从事件源内部离开)
9. mousenter: 鼠标移入
10. mouseleave: 鼠标移出
+ 移入移出事件的区别
=> over / out 一套, 不光移入事件源触发, 移入子元素也触发
键盘事件
+ 依赖键盘行为触发的事件
+ 注意:
1. 所有元素都可以绑定键盘事件, 但是不是谁都能触发
=> 一般可以有 window / document / 表单元素 触发
2. 触发键盘事件, 一般不去考虑中文输入法
1. keydown: 键盘按下事件
=> 键盘上任何一个按键按下都会触发
2. keyup: 键盘抬起事件
=> 键盘上任何一个按键抬起都会触发
3. keypress: 键盘键入事件
=> 必须要按下可以真实键入内容的按键或者回车键
=> 键入的内容必须和按下的内容一致
表单事件
+ 专门提供给表单元素的事件
1. focus: 聚焦事件
2. blur: 失焦事件
3. change: 改变事件
=> 要求 聚焦 和 失焦 的时候, 内容不一致, 才会触发
4. input: 输入事件
=> 只要表单元素输入内容或者删除内容, 就会实时触发
5. reset: 重置事件
=> 事件需要绑定给 form 标签
=> 由 form 标签内的 reset 按钮触发
6. submit: 提交事件
=> 事件需要绑定给 form 标签
=> 由 form 标签内的 submit 按钮触发
触摸事件
+ 移动端事件, 只能在移动端设备使用
1. touchstart
=> 触摸开始: 表示手接触到屏幕的瞬间
2. touchmove
=> 触摸移动: 表示手在屏幕上移动的时候
3. touchend
=> 触摸结束: 表示手离开屏幕的瞬间
其他事件
1. selectstart
=> 选择开始: 当你去框选页面文本内容的时候触发
2. transitionend
=> 过渡结束事件: 当你元素具有过渡属性的时候, 结束以后触发
=> 过渡多少个属性, 触发多少次
事件对象
+ 是一个对象数据类型, 记录了本次事件的所有信息
+ 是一个记录了本次事件触发的所有信息的对象数据类型
获取事件对象
+ 标准浏览器
=> 直接在事件处理函数位置书写一个形参, 会在事件触发的时候
=> 由浏览器自动传递实参
=> 传递的实参就是 事件对象
+ IE 低版本
=> 直接使用 window.event 来获取事件对象
+ 兼容:
=> 在事件处理函数的时候, 正常接受形参
=> 书写: e = e || window.event
事件对象信息 - 鼠标事件 + 坐标点
1. clientX 和 clientY // 可视窗口左上角
=> 光标相对于浏览器可视窗口左上角的坐标位置
2. pageX 和 pageY // 文档流左上角
=> 光标相对于文档流左上角的坐标位置
3. offsetX 和 offsetY // 元素左上角
=> 光标相对于触发事件的元素左上角的坐标点
案例--吸附拖拽
案例--吸附拖拽_tby_pr的博客-CSDN博客
事件对象信息 - 键盘事件
1. 按下的是哪一个按键
2. 是否是组合按键
1. 按下的哪一个按键
=> 在事件对象内有一个信息叫做 keyCode
e.keyCode === 13
=> 注意:
-> 有一个兼容性问题
-> 在标准浏览器下使用 keyCode
-> 在 FireFox < 20 的浏览器下使用 which
2. 组合按键
=> 在事件对象内有四个信息
-> shiftKey
-> ctrlKey
-> altKey
-> metaKey
+ 在 win 系统里面表示 win 键
+ 在 OS 系统里面表示 command 键
=> 以上四个属性的值都是 布尔值
-> true 表示按下了
-> false 表示没有按下
=> 如果你想判断组合按键, 只要在判断键盘编码的时候
-> 额外判断一下以上的四个属性就可以了
事件的传播
+ 当一个事件在浏览器中触发的时候
+ 不光在自己元素身上触发, 是会传播出去的
+ 注意: 传播的是事件行为
+ 概念: 当你在一个元素身上触发行为的时候, 会按照结构父级的顺序, 向上直到 window 传递该行为
当你打开页面, 点击在 inner 身上的时候(我们看到的)
+ 首先行为发生在了 inner 身上
+ 因为事件传播, 点击行为被传播了, 点击行为也发生在了 center 身上
+ 因为事件传播, 点击行为被传播了, 点击行为也发生在了 outer 身上
+ 因为事件传播, 点击行为被传播了, 点击行为也发生在了 body 身上
+ 因为事件传播, 点击行为被传播了, 点击行为也发生在了 html 身上
+ 因为事件传播, 点击行为被传播了, 点击行为也发生在了 document 身上
+ 因为事件传播, 点击行为被传播了, 点击行为也发生在了 window 身上
真实的传播
+ 首先 window 接收到行为, 按照结构级别逐层向下传递到准确触发事件的元素
+ 在从准确触发事件的元素向上传递, 回到 window
+ 在这个过程中, 每一个内容都接受了两次行为, 但是为什么事件处理函数只被调用了一次
+ 因为浏览器的事件执行机制
浏览器的事件执行机制
+ 所有的浏览器默认在 向上传递的 过程中触发事件
事件的三个阶段:
1. 捕获阶段: 从 window 向 目标 传递的过程
2. 目标阶段: 事件发生在 目标 身上
3. 冒泡阶段: 从 目标 向 window 传递的过程
事件的目标冒泡和捕获
事件冒泡: 在事件传播的过程中, 从 目标 到 window 的过程
事件捕获: 在事件传播的过程中, 从 window 到 目标 的过程
=> 在 IE 低版本内只能按照冒泡的顺序来执行
=> 在标准浏览器下, 事件默认在冒泡阶段执行
=> 可以选择在捕获阶段执行
事件目标: 准确触发事件的那个元素
如何获取事件目标
+ 在事件对象内有一个固定的信息表示本次事件的事件目标
+ 标准浏览器: 事件对象.target
+ IE 低版本: 事件对象.srcElement
+ 兼容: 我们自己定义一个变量来兼容
=> var target = e.target || e.srcElement
如何在捕获阶段执行事件
+ DOM 0级 事件绑定没有办法修改
+ DOM 2级 事件绑定才可以修改事件的执行阶段
=> 通过 addEventListener() 的第三个参数来决定
=> 默认是 false, 表示冒泡阶段
=> 选填是 true, 表示捕获阶段
阻止事件传播
+ 只要你点击 p 的时候, 事件不再继续传播
+ 因为事件是默认在 冒泡阶段 触发的
+ 只要不继续向上传播, div 的事件就不会触发了
标准浏览器
+ 事件对象.stopPropagation()
IE 低版本
+ 事件对象.cancelBubble = true
兼容:
+ 不能用 或 运算符
+ 因为有一个会报错
+ try {} catch() {} 语法
=> 首先执行 try 后面的 {} 内部的代码
=> 如果代码没有报错, 那么 catch 就不执行了
=> 如果代码报错了, 那么执行 catch 内部的代码
// try ... catch 语法进行兼容
try {
e.stopPropagation()
} catch (err) {
e.cancelBubble = true
}默认行为
+ 不需要绑定事件, 当你触发行为的时候, 就会出现效果的事情 , 我们叫做默认行为
+ 例子:
=> a 标签的点击行为
=> form 表单的提交行为
=> ...
标准浏览器
+ 事件对象.preventDefault()
IE 低版本
+ 事件对象.returnValue = false
兼容
+ try ... catch 兼容
try { e.preventDefault() } catch(err) { e.returnValue = false }
通用的阻止默认行为
+ 直接书写 return false
+ 会有问题:
=> 这个代码必须写在最后一行
=> 必须保证前面的代码百分之一百没有错误
总结
1. 事件是会传播的: 按照结构父级的顺序, 传递的 **事件行为**
2. 不管自己有没有事件, 行为一定会向上继续传播
3. 如何获取事件目标
=> 标准浏览器, 事件对象.target
=> IE 低版本, 事件对象.srcElement
4. 阻止事件传播
=> try { 事件对象.stopPropagation() } catch (err) { e.cancelBubble = true }
5. 阻止默认行为
=> try { 事件对象.preventDefault() } catch (err) { e.returnValue = false }
=> 通用的(慎用): return false
事件委托
把自己的事件委托给共同的结构父级
-> 在父级的事件内, 通过事件目标判断来决定执行什么内容
需求:
+ 页面上有 若干个 li, 点击每一个 li 在控制台输出该标签内的文本内容
+ 有一个 button 按钮, 点击的时候, 可以创建一个 li 插入到页面中
循环绑定事件 :
=> 一种给多个元素绑定事件的方式
=> 缺点:
-> 对于动态添加的元素(后期渲染的元素), 不够友好
-> 大量操作 DOM
事件委托来完成 :
=> 因为需求是点击 li 的时候, 做一些事情
=> 因为事件的传播, 如果我给 结构父级 身上绑定一个 点击事件
=> 也会因为点击 li 而触发
=> 例子: 给 ul 绑定一个点击事件
-> 点击 ul 会触发
-> 点击 li 会触发
=> 在事件对象中有一个信息叫做 事件目标
-> 准确触发事件的那个元素
-> 如果我是因为点击 ul 触发的事件, 事件目标 就是 ul
-> 如果我是因为点击 li 触发的事件, 事件目标 就是 li
=> 可以通过判断事件目标来确定我点击的是 li
=> 事件委托原则***:
-> 尽可能找到距离最近的公共的父级
-> 尽可能找到在页面上不动的元素来委托
事件总结
javascript事件总结_tby_pr的博客-CSDN博客
本地模拟购物车(简单版)
本地模拟购物车(简单版)_tby_pr的博客-CSDN博客
认识正则表达式 - RegExp
+ JS 中的数据类型, 是一个复杂数据类型
+ 作用: 专门用来验证字符串是否符合规则
如何创建一个正则表达式
1. 字面量方式创建
=> 语法: var reg = /abcd/
// 意思: 当你使用这个 reg 正则去验证字符串的时候, 要求字符串中必须包含 abcd 这个字符片段
2. 内置构造函数创建
=> 语法: var reg = new RegExp('abcd')
两种创建正则表达式的区别
1. 语法不一样
2. 书写标识符的时候
=> 字面量方式直接书写在正则的后面
=> 内置构造函数, 以第二个参数的方式传递
3. 拼接字符串
=> 字面量方式不接受拼接字符串
=> 内置构造函数方式, 可以拼接字符串
4. 基本元字符书写
=> 字面量方式的时候, 直接书写 \s\d\w
=> 内置构造函数书写的时候, 需要书写 \\s\\d\\w
为什么内置构造函数需要书写双斜线
+ 字符串
=> 被引号包裹的所有内容叫做字符串
=> 当你在字符串内书写 斜线(\) 的时候, 是表示转义符号
=> 会把紧挨着他的一个内容转换
-> 如果是有意义的内容转换成没有意义的内容
-> 如果是没有意义的内容转换成有意义的内容
-> 例子: n 是一个没有意义的字母
+ 当 n 和 转义符 在一起的时候, 就表示 换行
+ new RegExp()
=> 第一个参数需要一个字符串
=> 你写的字符串就是正则内部的内容
=> 如果你想得到 /\s\d\w/
=> 那么你要给他的字符串里面写上 \s\d\w
=> 但是, 因为在字符串中 \ 是转义符
=> 当你书写字符串 '\s' 的时候, \ 就会把 s 转换成有意义的特殊内容
-> 可以字符串中确实没有 \s 组成的特殊意义字符, 所以就变成了一个 单独的 字母 s
+ 解决问题:
=> 使用 \ 把有意义的特殊字符 \ 转换成没有意义的文本 \
=> 当你书写 '\\s\\d\\w' 的时候, 实际字符串就是 '\s\d\w'
正则表达式的常用方法
1. test() 匹配
=> 语法: 正则表达式.test('要检测的字符串')
=> 返回值: 一个布尔值
-> 如果该字符串符合正则的规则, 那么就是 true
-> 如果该字符串不符合正则的规则, 那么就是 false
2. exec() 捕获
=> 语法: 正则.exec(字符串)
=> 作用: 从 字符串中 把满足正则条件的部分获取出来
=> 返回值:
-> 原始字符串中没有符合正则要求的字符串片段
+ null
-> 原始字符串中有符合正则要求的片段
+ 正则没有 () 也没有 全局标识符g
+ 返回值是一个数组
+ 索引 0 是从字符串中捕获出来的满足正则条件的第一个内容
+ 注意: 不管捕获多少次, 每次都是从原始字符串的索引 0 开始检索
+ 正则有全局标识符 g
+ 返回值是一个数组
+ 索引 0 是从字符串中捕获出来的满足正则条件的第一个内容
+ 注意: 第二次捕获是从第一次的结束位置开始向后查询, 直到最后捕获不到为止, 再下一次的时候, 又从字符串的 索引0 开始检索
+ 有 ()
+ 返回的是一个数组
+ 索引 0 是从字符串中捕获出来的满足正则条件的第一个内容
+ 从索引 1 开始, 依次是每一个小括号的单独内容
+ 注意: 按照小括号的开始标志, 来数是第几个小括号
扩展:
+ () 有两个意义
=> 一个整体
=> 单独捕获
+ 如果你想只使用一个意义, 整体的所用, 不想在捕获的时候单独捕获出来
=> 你可以写成 (?:)
=> 匹配但不捕获
正则表达式的符号 - 基本元字符
正则表达式的组成部分
1. 元字符
=> 所有的文本内容
=> 特殊符号, 用符号表示一类内容
2. 标识符
=> 书写在正则的外面, 用来修饰正则表达式的
基本元字符
1. \d 表示 一位 数字
2. \D 表示 一位 非数字
3. \s 表示 一位 空白内容(空格/缩进/制表符/...)
4. \S 表示 一位 非空白内容
5. \w 表示 一位 数字(0-9)字母(a-zA-Z)下划线(_) 中的任意一个
6. \W 表示 一位 非数字字母下划线 中的任意一个
7. . 表示 一位 非换行以外的任意内容
8. \ 表示 转义符
-> 把有意义的符号转换成没有意义的普通文本
-> 把没有意义的文本转换成有意义的符号
元字符 - 边界符号
1. ^ 表示 字符串 开始
2. $ 表示 字符串 结尾
+ 注意: 当 ^ 和 $ 一起使用的时候, 表示的是从开头到结尾
元字符 - 限定符(修饰符号前内容出现次数)
+ 注意: 一个限定符只能修饰符号前面的一个内容的出现次数
1. * 表示出现 0 ~ 多次
2. + 表示出现 1 ~ 多次
3. ? 表示出现 0 ~ 1 次
4. {n} 表示出现 指定 多少次
5. {n,} 表示出现 至少 多少次
=> {0,} 等价于 *
=> {1,} 等价于 +
6. {n,m} 表示出现 n ~ m 次
=> {0,1} 等价于 ?
元字符 - 特殊符号
1. ()
=> 意义1: 一个整体
=> 意义2: 单独捕获(欠着)
2. |
=> 意义: 或者的意思
=> 注意: 或的边界, 要么是 (), 要么就到正则的边界
3. []包含
=> 意义: 包含
=> 注意: 一个 [] 内可以写多个内容, 但是一个 [] 只占一个字符位置, 表示 [] 内的任意一个都行
=> [0-9] 等价于 \d
=> [0-9a-zA-Z_] 等价于 \w
4. [^]非
=> 意义: 非
=> 注意: 一个 [^] 内可以写多个内容, 但是一个 [^] 只占一个字符位置, 表示 [^] 内的任意一个都不行
=> [^0-9] 等价于 \D
=> [^0-9a-zA-Z_] 等价于 \W
5. - 中划线(至)
=> 意义: 到 至
=> 注意: 需要和 [] 或者 [^] 连用
=> 注意: 需要 ASCII 编码连着的才可以使用
标识符
+ 书写在正则表达式的外面, 专门用来修饰整个正则表达式的符号
1. i (ignore) 表示忽略大小写不计
2. g (global) 全局: 欠着
案例1: 书写正则验证 身份证号码
// var reg = /^\d{17}(\d|x)$/
案例2: 书写正则验证 手机号码
// var reg = /^(\+86)?(133|135|138)\d{8}$/
案例3: 书写正则验证 邮箱
// var reg = /^\w{6,16}@(qq|163|sina)\.(com|cn)$/
正则的两个特性
1. 懒惰性
=> 每一次捕获都是从原始字符串的索引 0 位置开始检索
=> 解决: 使用全局标识符 g
2. 贪婪性
=> 贪婪匹配: 能拿 多少 拿多少 尽可能多的匹配内容
=> 非贪婪匹配: 能拿多 少 拿多少 尽可能少的匹配内容
-> 需要使用非贪婪限定符
-> 在原先的限定符后面再写一个 ?
-> *? 0 ~ 多次, 但是 0 次能解决问题, 就不在多
-> +? 1 ~ 多次, 但是 1 次能解决问题, 就不在多
-> ?? 0 ~ 1次, 0 次能解决问题, 就不去管 1 次
-> {n,}?
-> {n,m}?
正则字符串方法
+ 正则常用方法: 正则.xxx()
+ 字符串常用方法: 字符串.xxx()
1. replace()敏感词替换
=> 语法:
-> 字符串.replace('换下字符', '换上字符')
-> 字符串.replace(正则表达式, '换上字符')
=> 返回值: 替换好的字符串
-> 当你的第一个参数传递字符串的时候, 只能替换一个
-> 当你的第一个参数传递正则表达式的时候, 只能替换一个
-> 但是如果你的正则表达式有全局标识符 g, 那么有多少替换多少
案例--正则 + replace() // 替换敏感词_tby_pr的博客-CSDN博客
2. search()
=> 语法:
-> 字符串.search(字符串片段)
-> 字符串.search(正则表达式)
=> 作用: 在原始字符串内查找指定内容
=> 返回值:
-> 原始字符串内有指定内容, 那么就是这个内容的索引
-> 原始字符串内没有指定内容, 那么就是 -1
3. match()
=> 语法:
-> 字符串.match(字符串片段)
-> 字符串.match(正则表达式)
=> 返回值: 从原始字符串中捕获满足条件的片段
=> 注意: 如果你的参数传递的是字符串或者没有全局标识符g的正则, 那么和 exec 返回值一模一样
-> 当你的正则有全局标识符 g 的时候, 那么返回值是一个数组
-> 能从原始字符串内捕获多少, 数组里就有多少内容
案例--表单验证的逻辑
案例--表单验证的逻辑_tby_pr的博客-CSDN博客
自执行函数
+ 一个会自己调用自己的函数
+ 当这个函数定义好以后, 直接被调用
自执行函数的意义:
+ 利用函数的私有作用域, 保护变量私有化 + 不去污染全局
语法:
=> (function () { 代码 })()
=> ~function () { 代码 }()
=> !function () {}()
this 指向 !! 重要 !! 重要 !! 重要
+ this 是一个关键字 ,是一个使用在作用域内的关键字
=> 要么全局使用
-> this 就是 window
=> 要么使用在函数内
-> this 表示的是该函数的 context(执行上下文)
-> 私人: 熟读并背诵全文
函数内的 this (私人)
+ 概念: 函数内的 this, 和 函数如何定义没有关系, 和 函数在哪定义没有关系 => 只看函数是如何被调用的(箭头函数除外)
+ 几种调用方式, 决定不同的 this 指向
1. 普通调用
=> 函数名()
=> 该函数内的 this 指向 window
2. 对象调用
=> 对象名.函数名()
-> 对象名['函数名']()
-> 数组[索引]()
=> 该函数内的 this 指向 点 前面的内容
-> 也就是那个对象或者数组
3. 定时器处理函数
=> setTimeout(函数, 时间)
setInterval(函数, 时间)
=> 该函数内的 this 指向 window
4. 事件处理函数
=> 事件源.on事件类型 = 事件处理函数
事件源.addEventListener('事件类型', 事件处理函数)
=> 该函数内的 this 指向 事件源(谁身上的事件)
5. 自执行函数
=> (function () {})()
~function () {}()
!function () {}()
=> 该函数内的 this 指向 window
6. ...
强行改变 this 指向(跟随在函数名后面调用)
+ 不管你本身指向哪, 我让你指向哪, 你就得指向哪
1. call
+ 语法: 跟随在函数名后面调用
=> 函数名.call()
=> 对象名.函数名.call()
+ 意义: 修改 函数内 的 this 指向
+ 参数:
=> 第一个参数: 函数内的 this 指向
=> 第二个参数开始: 依次给函数传递实参
+ 特点: 立即调用函数
2. apply
+ 语法: 跟随在函数名后面调用
=> 函数名.apply()
=> 对象名.函数名.apply()
+ 意义: 修改 函数内 的 this 指向
+ 参数:
=> 第一个参数: 函数内的 this 指向
=> 第二个参数: 是一个数组或者伪数组都行, 里面的每一项依次给函数传递实参
+ 特点: 立即调用函数
+ 特殊作用: 改变给函数传递参数的方式
3. bind
+ 语法: 跟随在函数名后面调用
=> 函数名.bind()
=> 对象名.函数名.bind()
+ 意义: 修改 函数内 的 this 指向
+ 参数:
=> 第一个参数: 函数内的 this 指向
=> 第二个参数开始: 依次给函数传递实参
+ 特点:
=> 不会立即调用函数, 而是返回一个新的函数
=> 一个被改变了 this 指向的新函数
+ 特殊作用: 改变一些不会立即执行的函数内的 this 指向
ES6******
ES6 定义变量
+ 新增了两个定义变量的关键字
1. let 变量
2. const 常量
| var | let | const |
| 会预解析 | 不会预解析,会报错 | |
| 可重名 | 不允许重名,会报错 | |
| 无 块级作用域 | 块级作用域 会限制变量使用范围 | |
| 值 能修改 | 值 不能修改 | |
| 可不赋值 | 不能声明不赋值 | |
1. let/const 和 var 的区别***!!!
1-1. 预解析
=> var 会进行预解析, 可以先使用后定义
=> let/const 不会进行预解析, 必须先定义后使用
1-2. 变量重名
=> var 定义的变量可以重名, 只是第二个没有意义
=> let/const 不允许在同一个作用域下, 定义重名变量
1-3. 块级作用域
=> var 没有块级作用域
=> let/const 有块级作用域
=> 块级作用域: 任何一个可以书写代码段的 {} 都会限制变量的使用范围
2. let 和 const 的区别
2-1. 声明时赋值
=> let 可以在定义变量的时候, 不赋值
=> const 定义变量的时候, 必须赋值
2-2. 值的修改
=> let 定义的变量可以任意修改值内容
=> const 定义的常量, 一经赋值不允许修改
ES6 的模板字符串
+ ES6 提供的一种定义字符串的方式
+ 使用 反引号(``) 来进行字符串的定义
+ 和 单引号('') 或者 双引号("") 定义的字符串没有区别, 使用上是一样的
+ 只是当你使用 反引号(``) 定义的时候, 会有特殊的能力
1. 可以换行书写
2. 可以直接在字符串内解析变量
=> 当你需要解析变量的时候, 书写 ${ 变量 }
+ 注意:
=> ${} 外面的空格是真实在字符串内的空格
=> ${} 里面的空格是代码的空格, 和字符串没有关系
ES6 的箭头函数
+ ES6 语法中定义函数的一种方式
+ 只能用来定义函数表达式(匿名函数)
=> 当你把函数当做一个值赋值给另一个内容的时候, 叫做函数表达式
=> var xxx = function () {}
=> var obj = { xxx: function () {} }
=> xxx.onclick = function () {}
=> xxx.addEventListener('click', function () {})
=> xxx.forEach(function () {})
=> setTimeout(function () {}, 1000)
=> ...
+ 注意: 声明式函数不行
=> function fn() {}
+ 语法: () => {}
-> () 是写形参的位置
-> => 是箭头函数的标志
-> {} 是书写代码段的位置
箭头函数的特点:
1. 可以省略小括号不写
=> 当你的形参只有一个的时候, 可以不写小括号
=> 如果你的形参没有或者两个及以上, 必须写小括号
2. 可以省略大括号不写
=> 当你的代码只有一句话的时候, 可以省略大括号不写, 并且会自动返回这一句话的结果
=> 否则, 必须写大括号
3. 箭头函数内没有 arguments
=> 箭头函数内天生不带有 arguments
=> 没有所有实参的集合
4. 箭头函数内没有 this
=> 官方: 外部作用域的 this
=> 私人: 书写在箭头函数的外面那个函数 this 是谁, 箭头函数内的 this 就是谁
ES6 的函数参数默认值
+ 给函数的形参设置一个默认值, 当你没有传递实参的时候, 使用
+ 书写: 直接在书写形参的时候, 以 赋值符号(=) 给形参设置默认值就可以了
+ 任何函数都可以使用
+ 注意: 如果你给箭头函数设置参数默认值, 那么不管多少个形参, 都得写小括号
ES6 的解构赋值
+ 快速从对象或者数组中获取一些数据
+ 分成两类
1. 解构数组
2. 解构对象
1. 解构数组(快速从数组中获取数据)
=> 注意: 使用 [] 解构数组
=> 语法: var [ 变量1, 变量2, 变量3, ... ] = 数组
=> 按照索引, 依次从数组内给每一个变量赋值
=> 扩展: 解构多维数组
-> 数组怎么写, 解构怎么写
-> 把数据换成变量
2. 解构对象(快速从对象中获取数据)
=> 注意: 使用 {} 解构对象
=> 语法: var { 键名1, 键名2, 键名3, ... } = 对象
=> 按照键名, 依次定义变量从对象中获取指定成员
=> 解构的时候起一个别名(用:)
-> 语法: var { 键名: 别名, 键名2: 别名 } = 对象
-> 注意: 当你起了别名以后, 原先的键名不能在当做变量名使用了, 需要使用这个别名
ES6 的扩展运算符 ...
+ 展开合并运算符
+ 有两个意义
=> 展开
=> 合并
+ ...
=> 主要是操作 数组 和 对象 的运算符号
1. 展开
=> 可以 展开对象, 或者 展开数组
=> 如果是展开对象, 就是去掉对象的 {}
=> 如果是展开数组, 就是去掉数组的 []
2. 合并
=> 当这个符号书写在函数的形参位置的时候, 叫做合并运算符
=> 从当前形参位置开始获取实参, 直到末尾
=> 注意: 合并运算符一定要写在最后一位
模块化开发的规则ES6***
1. 如果你想使用 ES6 的模块化开发语法
=> 页面必须在服务器上打开
=> 本地打开不行
=> vscode 下载插件, live server
=> 打开页面的时候, 鼠标右键 open with live server
-> 快捷键, alt + l, 再按一次 alt + o
2. 当你使用了 模块化语法以后
=> 每一个 js 文件, 都是一个独立的 文件作用域
=> 该文件内的所有变量和方法, 都只能在这个文件内使用
=> 其他文件不能使用
=> 如果像使用, 需要导出
3. 每一个 js 文件, 也不能使用任何其他 js 文件内部的变量
=> 如果像使用
=> 那么你需要导入该文件
语法: 导出和导入***!!!
+ 导出语法:
export default { 你要导出的内容 }
+ 导入语法:
import 变量 from 'js 文件'
封装--运动函数
封装--运动函数_tby_pr的博客-CSDN博客
轮播图的逻辑代码
轮播图的逻辑代码_tby_pr的博客-CSDN博客
认识面向对象开发(使用构造函数批量创建对象)
+ 一种代码的开发方式, 是我们写代码的思想
词:
+ 面向过程: 在开发的过程中关注每一个 步骤 顺序 细节 ...
+ 面向对象: 在开发的过程中找到一个能帮我完成功能的对象
例子: 吃面条
+ 面向过程
=> 和面: 多少水, 多少面
=> 切面: 宽窄
=> 煮面: 时间长短
=> 拌面: 酱放多少
=> 吃: 用哪吃
+ 面向对象
=> 找一个面馆
=> 点一碗面
=> 吃
+ 面向对象 是对 面向过程 的高度封装
+ 核心思想: 高 内聚 低 耦合(重复)
=> 代码能以最少的方式完成最多的功能
开发: 完成一个轮播图
+ 面向过程
=> 获取元素
=> 准备变量
=> 书写过程(设置焦点, 复制元素, 自动轮播, ...)
+ 面向对象
=> 找到一个对象
o = {
banner:
,imgBox:
pointBox:
index: 1,
...,
setPoint: function () { 能把当前 pointBox 内的焦点设置好 }
...
}
o.setPoint()
=> 我需要实现第二个轮播图
o2 = {
banner:
,imgBox:
pointBox:
index: 1,
...,
setPoint: function () { 能把当前 pointBox 内的焦点设置好 }
...
}
o2.setPoint()
=> 找到的对象特点:
-> 多个对象之间, 属性名一致, 值不一样
-> 多个对象之间, 都有一样的方法, 方法中操作的都是自己对象内的内容
开发思想:
+ 当你需要完成一个 "功能" 的时候
+ 首先找到一个 对象, 这个对象内的成员能完成 "功能"
+ 如果没有这样的 对象, 想办法找到一个 "机器", 这个机器能创造 对象
+ 能创造一个完成 "功能" 的对象
+ 利用这个 "机器", 创建一个对象
+ 使用对象去完成 "功能"
开发思想: 我要完成 选项卡 功能
+ 首先找到一个 对象, 对象内包含的内容能完成选项卡
+ 发现没有, 我需要自己手写一个构造函数
+ 构造函数创建出来的对象要求能完成选项卡
+ 使用构造函数创建一个对象
+ 使用创建出来的对象完成选项卡
任务:
+ 找到一个 "机器"
+ 能批量创造对象
+ 批量创建出来的对象, 属性名一样, 值不一样
+ 创建有属性有方法合理的对象
创建对象的方式
1. 字面量方式
+ 语法: var o = {}
+ 不适合: 因为不能批量创建
2. 内置构造函数创建对象
+ 语法: var o = new Object()
+ 不合适: 因为不能批量创建
3. 工厂函数创建对象
3-1. 自己书写一个工厂函数
=> 就是一个函数, 只是因为这个函数可以创建对象
=> 我们起名叫做 工厂函数
3-2. 用工厂函数创建对象
+ 合适: 可以批量创建, 可以自由设置值
function createObj(name, age) {
// 1. 手动创建一个对象
const obj = {}
// 2. 手动添加成员
obj.name = name
obj.age = age
// 3. 手动返回这个对象
return obj
}
/**/
const o1 = createObj('Jack', 18)
const o2 = createObj('Rose', 20)4. 自定义构造函数创建对象****
4-1. 自己书写一个构造函数
=> 就是一个函数, 只不过在调用的时候需要和 new 关键字连用
=> 我们起名叫做 构造函数
4-2. 使用构造函数创建对象
+ 合适: 可以批量创建, 可以自由设置值
注意: 当一个函数和 new 关键字连用的时候, 函数内的 this 指向前面的变量
本质: this 指向那个自动创建出来的对象
// 自定义构造函数
// 0. 自己书写一个构造函数
function CreateObj(name, age) {
// 1. 自动创建一个对象, 叫做 xxx
// 2. 手动向这个对象内添加成员
this.name = name
this.age = age
// 3. 自动返回这个创建的对象
}
/**/
const o1 = new CreateObj('张三', 18)
const o2 = new CreateObj('李四', 20)构造函数的书写*(和 new 关键字连用)******
+ 构造函数也是一个函数
+ 只不过使用的时候需要和 new 关键字连用
1. 书写构造函数首字母大写(规范)
=> 为了和普通函数做一个区分
2. 构造函数的调用必须和 new 关键字连用(规范)
=> 因为只有 和 new 关键字连用的时候, 才有自动创建对象的能力
=> 我们书写构造函数的意义, 就是为了批量创建对象
=> 不和 new 关键字连用, 没有自动创建对象的能力了, 那么构造函数书写的意义就没了
3. 构造函数内不要写 return
=> 当你 return 一个基本数据类型的时候, 写了白写
=> 当你 return 一个复杂数据类型的时候, 构造函数白写
4. 构造函数内的 this
=> 因为你的函数调用和 new 关键字连用
=> this 会指向自动创建出来的那个对象
=> 又因为这个对象会被自动返回, 赋值给本次调用是前面的那个变量
=> this 指向 new 前面定义的变量
=> 构造函数自动创建对象的过程, 叫做 实例化的过程
=> 我们管构造函数创建出来的对象, 起名叫做 实例对象
=> 概念: 构造函数内的 this 指向当前实例
构造函数内的不合理
+ 当你把方法直接书写在构造函数体内的时候 , 会造成额外的资源浪费
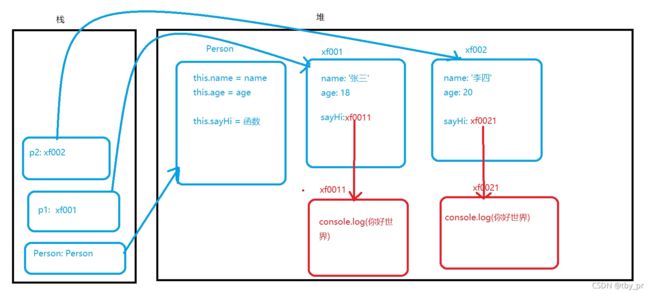
解决:
+ 把属性书写在构造函数体内
+ 把方法书写在构造函数的原型上(prototype)
原型
构造函数概念:
+ **每一个函数天生自带一个属性, 叫做 prototype, 是一个对象数据类型**
+ 构造函数也是一个函数, 所以构造函数也有 prototype
+ 这个天生自带的 prototype 内有一个叫做 constrictor 的属性
=> 表名我是谁自带的 prototype
=> 指向自己的构造函数
+ 是一个对象, 我就可以向里面添加一些成员
Person.prototype.a = 100
+ 一个函数伴生的存储空间
+ 专门由构造函数向内添加方法, 供构造函数的实例使用
构造函数this
=> this 指向 当前实例(new 前面定义的那个变量)
=> 本质: 构造函数内自动创建出来的那个对象
1. 构造函数体内的 this
=> 因为和 new 关键字连用
=> this 指向 当前实例
2. 原型上的方法体内的 this
=> 因为原型上的方法是被当前实例调用的
=> this 指向 当前实例
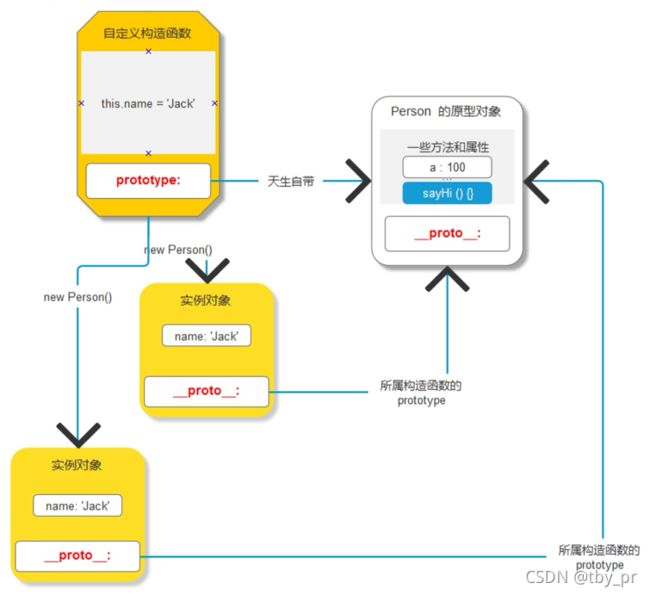
实例对象概念:
+ **每一个对象天生自带一个属性, 叫做 __proto__, 指向所属构造函数的 prototype**
+ 实例对象也是一个对象, 所以实例对象也有 __proto__
面向对象与构造函数总结***
1. 面向对象的开发思想
+ 核心: 高内聚低耦合
+ 意义:
=> 在开发一个功能的时候
=> 首先书写一个构造函数
=> 这个构造函数可以生成能完成功能的对象
=> 使用构造函数生成一个对象
=> 利用生成的对象完成功能
2. 构造函数的书写
1. 首字母建议大写
=> 为了和普通函数做一个区分, 使用的时候要和 new 关键字连用
2. 构造函数体内不要写 return
=> 如果你 return 了一个基本数据类型, 写了白写
=> 如果你 return 了一个复杂数据类型, 构造函数白写
3. 构造函数的使用必须和 new 关键字连用
=> 因为构造函数的目的就是为了自动创建对象
=> 当你不和 new 关键字连用的时候, 就没有自动创建对象的意义了
=> 构造函数就没有用了
4. 构造函数内的 this
=> 构造函数因为和 new 关键字连用, 所以内部的 this 指向那个被自动创建出来的对象
=> 又因为自动创建出来的对象, 被自动返回, 赋值给 new 前面的变量
=> this 就指向 new 前面的变量
=> 本质: this 指向当前实例对象
3. 构造函数内的不合理
+ 当你把方法书写在构造函数体内的时候
+ 会随着创建对象的增加, 导致额外的资源浪费
4. 解决构造函数内的不合理
4-1. prototype
=> 每一个函数天生自带一个属性, 叫做 prototype, 是一个对象数据类型
4-2. __proto__
=> 每一个对象天生自带一个属性, 叫做 __proto__, 指向所属构造函数的 prototype
4-3. 对象访问机制
=> 当你访问一个对象的成员的时候
=> 会首先在自己身上查找, 如果有直接使用, 停止查找
=> 如果没有, 会自动去 __proto__ 上查找
=> 未完待续 ...
+ 结论:
=> 书写构造函数的时候
=> 属性直接书写在构造函数体内
=> 方法书写在构造函数的原型(prototype)上
5. 构造函数内相关的 this
=> 构造函数体内的 this
-> 因为和 new 关键字连用
-> this 指向 当前实例
=> 构造函数原型上方法内的 this
-> 因为原型上的方法就是被实例调用的
-> this 指向 当前实例
案例--封装--面向对象 选项卡
案例--封装--面向对象 选项卡_tby_pr的博客-CSDN博客
Swiper使用
JavaScript基础&高级&实战,JS从入门到精通全套完整版(耗时300小时的JS编程大作)_哔哩哔哩_bilibili
原型 和 原型链******
+ 原型: 每个函数天生自带的 prototype 对象数据类型
=> 作用: 由构造函数向 原型上 添加方法, 提供给该构造函数的所有实例使用
=> 为了解决构造函数将方法书写在构造函数体内时造成的资源浪费
+ 原型链: => 概念: 用 __proto__ 串联起来的对象链状结构
=> 作用: 为了对象访问机制服务(当你访问一个对象成员的时候, 为你提供一些服务)
=> 注意: 只是 __proto__ 串联起来的对象链状结构, 千万不要往 prototype 上靠
万物皆对象 + 在 JS 内, 任何一个数据类型其实都是对象
+ 函数也是一个对象, 数组也是一个对象, 正则也是一个对象, ...
=> 是对象, 就可以存储 键值对
+ 以函数为例
=> 当你书写完毕一个函数的时候
=> 此时 函数数据类型 出现了, 同时该函数名也是一个对象数据类型
概念:
1. 每一个函数天生自带一个属性叫做 prototype, 是一个对象数据类型
2. 每一个对象天生自带一个属性叫做 __proto__, 指向所属构造函数的 prototype
3. 任何一个对象, 如果没有准确的构造函数, 那么看做是 Object 的实例
=> 只要是一个单纯的对象数据类型, 都是内置构造函数 Object 的实例
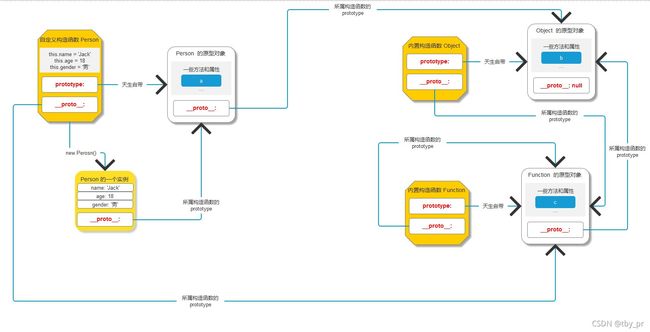
问题1: p1 身上的 __proto__ 是谁 ?
=> 因为 p1 是 Person 的时候
=> 根据 概念1 得到, p1.__proto__ 指向所属构造函数的 prototype
// 问题1证明
// console.log(p1.__proto__ === Person.prototype)
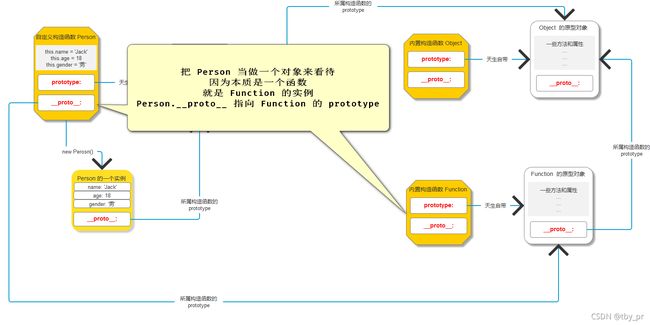
问题2: Person 的 __proto__ 是谁 ?
=> Person 是一个构造函数, 同时也是一个函数, 同时也是一个对象
=> 只要是对象就会有 __proto__ 属性
=> JS 内有一个内置构造函数叫做 Function, 只要是函数, 就看做 Function 的实例
=> 任何一个函数数据类型所属的构造函数都是 Function
=> Person 看做是 Function 的实例
=> Person 所属的构造函数就是 Function
=> Person.__proto__ 指向 Function.prototype
// 问题2证明
// console.log(Person.__proto__ === Function.prototype)
问题3: Person.prototype 的 __proto__ 是谁 ?
=> Person.prototype 是函数天生自带的一个对象数据类型
=> 只要是对象就会有 __proto__ 属性
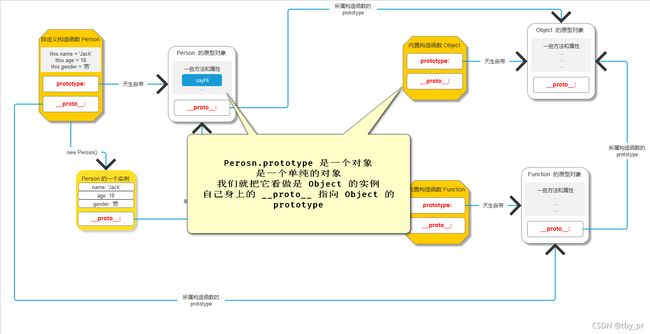
=> JS 内有一个内置构造函数叫做 Object, 只要是单纯的对象, 都是 Object 的实例
=> Person.prototype 是一个天生的对象数据类型, 并且是一个单纯的对象数据类型
=> 把 Person.prototype 看做是 Object 的实例
=> Person.prototype 的 __proto__ 就是 Object.prototype
// 问题3证明
// console.log(Person.prototype.__proto__ === Object.prototype)
问题4: Function 的 __proto__ 是谁 ?
=> Function 是一个构造函数, 同时也是一个函数, 同时也是一个对象
=> 只要是对象就会有 __proto__ 属性
=> JS 内有一个内置构造函数叫做 Function, 只要是函数就是 Function 的实例
=> Function 自己本身是一个内置构造函数, 本身也是一个函数
=> Function 自己是自己的实例, 自己是自己的构造函数
=> 在 JS 内管 Function 叫做顶级函数
=> Function.__proto__ 就是 Function.prototype
// 问题4证明
// console.log(Function.__proto__ === Function.prototype)
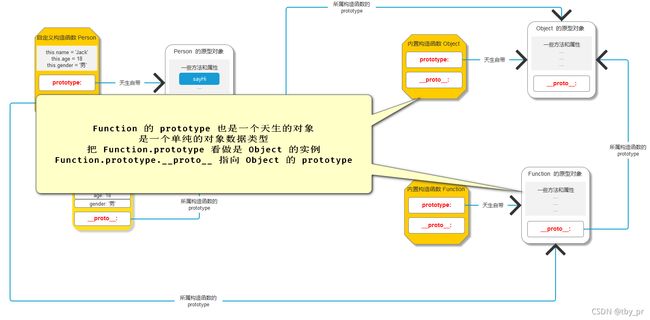
问题5: Function.prototype 的 __proto__ 是谁 ?
=> Function.prototype 是函数天生自带的一个对象数据类型
=> 只要是对象就会有 __proto__ 属性
=> Function.prototype 是一个天生的对象数据类型, 并且是一个单纯的对象数据类型
=> 把 Function.prototype 看做是 Object 的实例
=> Function.prototype 的 __proto__ 就是 Object.prototype
// 问题5证明
// console.log(Function.prototype.__proto__ === Object.prototype)
问题6: Object 的 __proto__ 是谁 ?
=> Object 是一个构造函数, 同时也是一个函数, 同时也是一个对象
=> 只要是对象就会有 __proto__ 属性
=> Object 也是一个函数, 只要是函数就是 Function 的实例
=> Object 这个内置函数所属的构造函数依旧是 Function
=> Object.__proto__ 就是 Function.prototype
// 问题6证明
console.log(Object.__proto__ === Function.prototype)
问题7: Object.prototype 的 __proto__ 是谁 ?
=> Object.prototype 势函数天生自带的一个对象数据类型
=> 只要是对象就会有 __proto__ 属性
=> 在 JS 内, Object 是顶级对象, Object.prototype 是顶级原型
=> Object.prototype 是唯一一个没有 __proto__ 的对象数据类型
=> Object.prototype 的 __proto__ 是 null
// 问题7证明
console.log(Object.prototype.__proto__)
对象访问机制:
对象访问机制
+ 当你需要访问一个对象的成员的时候
+ 首先在自己身上查找, 如果有直接使用, 停止查找
+ 如果没有, 会自动去 __proto__ 上查找
+ 如果还没有, 再去 __proto__ 上查找
+ 以此类推, 直到 顶级原型(Object.prototype) 上都没有, 返回 undefined
结论:
+ Object.prototype 中添加的内容, 所有的数据类型都可以使用
+ Function.prototype 中添加的内容, 所有的函数数据类型都可以使用(专门给函数使用的)
+ 自定义构造函数.prototype 中添加的内容, 给该构造函数的实例使用的
案例--放大镜
自己不作为事件目标 // pointer-events: none;
案例--放大镜_tby_pr的博客-CSDN博客
ES6 的类语法***
+ 解释: ES6 书写构造函数的方式
语法:
+ class 类名 {}
=> class: 定义类的关键字
=> 类名: 该类的名字
=> {}: 该类里面包含的所有内容
+ 在类里面写的内容
1. construcor () {}
=> 等价于 ES5 的构造函数体
2. 原型上的方法 => 方法名 () {}
=> 直接在 constructor 的后面书写
=> 方法名 () {}
=> 表示是添加在原型上的方法
3. 类 的 静态方法和属性
=> static 方法名 () {}
=> static 变量 = 值
如何区分静态方法和原型方法
+ 在书写上
=> 如果你想写一个方法将来给实例使用, 那么就写成原型方法
=> 如果你想写一个方法将来给类自己使用, 那么就写成静态方法
=> 如果你想写成原型方法, 那么就直接写 ( 方法名 () {} )
=> 如果你想写成静态方法, 那么就直接写 ( static 方法名 () {} )
+ 在使用上
=> 如果你写的就是 ( 方法名 () {} )
=> 那么将来你使用的时候, 要依赖这个类的 实例对象 去调用
-> const p1 = new Person()
-> p1.方法名()
=> 获取在方法内以 this 的形式来调用
-> 方法名 () { this.xxx }
=> 如果你写的是 ( static 方法名 () {} )
=> 那么将来使用的时候要依赖 类名 去调用
-> 类名.方法名()
ES6与ES5的变化
ES5
//构造函数体
function Person() {}
//原型方法
Person.prototype.a = function () {}
//静态方法
Person.c = function () {}
ES6
class Person {
//构造函数体
constructor () {}
//原型方法
a () {}
//静态方法
static c () {}
}
案例--ES6类 渐隐渐现 轮播图
案例--ES6类 渐隐渐现 轮播图_tby_pr的博客-CSDN博客
案例--ES6类 贪吃蛇 小游戏
JavaScript基础&高级&实战,JS从入门到精通全套完整版(耗时300小时的JS编程大作)_哔哩哔哩_bilibili
前后端交互
+ 前端想办法从服务器获取一些数据
+ 例子: 新闻网站
=> 前端:
-> 根据一个已知数据, 把数据渲染成页面
-> 已知数据不再是自己写好的
=> 后端(服务端):
-> 根据前端的需求, 准备好对应的数据
-> 给到前端
+ 例子: 登录
=> 前端:
-> 当用户点击登录按钮的时候
-> 拿到用户输入的用户名和密码
-> 想办法把用户名和密码发送给后端
-> 根据后端给出的结果, 给用户提示
=> 后端:
-> 接受前端传递来的用户名和密码
-> 进行正确性的验证
-> 把验证结果返回给前端
ajax(A债克丝 / 阿贾克斯)
+ 是一个前端和后端交互的手段(技术)
=> a: async 异步
=> j: javascript 脚本语言
=> a: and 和
=> x: xml 严格的 html 格式
如何发送一个 ajax 请求
1. 创建 ajax 对象
=> 语法: var xhr = new XMLHttpRequest()
=> xhr 就是我们需要的 ajax 对象, 能帮我们发送一个请求
2. 配置本次请求的信息
=> 语法: xhr.open('请求方式', '请求地址', 是否异步)
=> 请求方式: 接口文档内的内容
=> 请求地址: 接口文档内的内容(基准地址 + 接口地址)
=> 是否异步: 选填, 默认是异步的
3. 把配置好的请求发送出去
=> 语法: xhr.send()
4. 配置一个请求完成的事件
=> 语法: xhr.onload = function () { 代码 }
=> 时机: 会在当前请求完成以后被触发(后端给回对应的响应以后)
=> 如何拿到后端给我的信息(数据):
-> 在 ajax对象 内有一个成员叫做 responseText
console.log(xhr.responseText)
当后端返回的是 json 格式的数据的时候
// 我们最好把 json 格式转换成 js 的数据格式使用
// 语法: JSON.parse(json 格式数据)
const res = JSON.parse(xhr.responseText)
ajax 的异步问题
+ ajax 是一个默认异步的技术手段
+ ajax 墙裂 不推荐同步请求
=> 同步: 从上到下依次执行, 上一行代码没有完成, 后面的代码不会执行
-> 当你的网络环境不好的时候, 一旦请求发送出去, 当请求没有回来的时候
-> 此时你什么都干不了
=> 异步: 先放在队列池里面
-> 等到所有同步代码执行完毕, 在来执行异步的代码
ajax 的异步出现在什么时候
1. 创建 ajax 对象
=> 同步代码
2. 配置请求信息
=> 同步代码
3. 发送本次请求
=> 同步发送
=> 异步接受
4. 绑定事件
=> 同步绑定事件
=> 会根据 ajax 完成以后触发
ajax 的同步异步问题
=> open 第三个参数不写的时候, 默认是 true, 表示 异步
=> open 第三个参数选填是 false 表示 非 异步
总结:
=> ajax 解决异步拿不到响应的方式(掌握)
-> 把步骤三(发送) 和 步骤四(绑定事件) 交换位置
结论:
=> 如果你发送异步请求, 可以是 步骤 1 2 3 4 , 也可以是步骤 1 2 4 3
=> 如果你发送同步请求, 步骤必须是 1 2 4 3
=> 今后写 ajax 请求, 都写成 1 2 4 3
常见的请求方式
1. GET: 偏向获取的语义, 当你需要向服务器索要一些数据的时候使用
2. POST: 偏向提交的语义, 当你需要给服务器一些数据的时候使用
3. PUT: 偏向提交的语义, 偏向提交给服务器, 服务器进行添加操作
4. DELETE: 偏向删除的语义, 告诉服务器我需要删除一些信息
5. PATCH: 偏向提交的语义, 偏向提交给服务器, 服务器进行局部信息的修改
6. HEAD: 用于获取服务器响应头信息的一个请求
7. CONNECT: 保留请求方式
8. OPTIONS: 不需要任何响应的请求, 只是为了获取服务器信息, 需要服务器允许
GET 和 POST 的区别(掌握, 熟读并背诵全文)!!!***
1. 语义不一样
=> GET 偏向获取
=> POST 偏向提交
2. 携带信息的位置不一样
=> GET: 直接在请求地址后面以 查询字符串 的形式进行拼接
=> POST: 是在 请求体 内进行信息的携带
3. 携带信息的大小不一样
=> GET: 原则上可以携带任意大小的数据, 但是会被浏览器限制(IE: 2KB)
=> POST: 原则上可以携带任意大小的数据, 但是会被服务器限制
4. 携带信息的格式不一样
=> GET: 只能携带 查询字符串 格式
=> POST: 可以携带很多格式(查询字符串/json/二进制流/...), 但是需要在发送请求的时候特殊说明一下
5. 安全问题
=> GET: 明文发送, 相对post不安全
=> POST: 暗文发送, 相对get安全
发送一个带有参数的 GET 请求(掌握)
+ 当你需要携带参数给后端的时候
+ 因为 GET 是直接在地址后面拼接 查询字符串
=> 查询字符串: 'key=value&key2=value2'
-> 一条数据: 'key=value'
-> 多条数据之间: '&'
+ 注意: 地址 和 查询字符串 之间 使用 问号(?) 分隔
const xhr = new XMLHttpRequest()
xhr.open('GET', 'http://localhost:8888/test/third?name=Jack&age=18')
xhr.onload = function () {
const res = JSON.parse(xhr.responseText)
console.log(res)
}
xhr.send()发送一个带有参数的 POST 请求
+ 因为 POST 请求是在请求体内携带信息
+ xhr.send() 的小括号内, 就是书写请求体的位置
+ 我们直接把 查询字符串 放在小括号内就可以了
+ 注意: 如果你发送 POST 请求, 并且需要携带信息, 那么一定要在发送之前特殊说明
=> 如果你发送的是 查询字符串: applicetion/x-www-form-urlencoded
=> 如果你发送的是 json格式: application/json
=> 如果你发送的是 二进制流: mutilpart/data
+ 设置特殊说明的语法:
=> xhr.setRequestHeader('content-type', 对应的类型)
const xhr = new XMLHttpRequest()
xhr.open('POST', 'http://localhost:8888/test/fourth')
xhr.onload = function () {
const res = JSON.parse(xhr.responseText)
console.log(res)
}
// 请求之前, 做出特殊说明
xhr.setRequestHeader('content-type', 'application/x-www-form-urlencoded')
xhr.send('name=前端小灰狼&age=18')案例--登录(简易版)
案例--登录(简易版)_tby_pr的博客-CSDN博客
案例--电商(简易版)逻辑分析
案例--电商(简易版)逻辑分析_tby_pr的博客-CSDN博客
1.查看是否登录 : localStorage 内的 标识 ,只要不对,说明没登录
2.查看登录是否过期 : 发送请求,根据文档请求一个需要登录的接口
按照根据接口文档,在请求头携带字段 把token携带过去验证
能请求数据,说明状态没过期,
根据后端返回的内容中的 code 判断 token 是否在有效期内
不能请求回数据,代表状态过期了

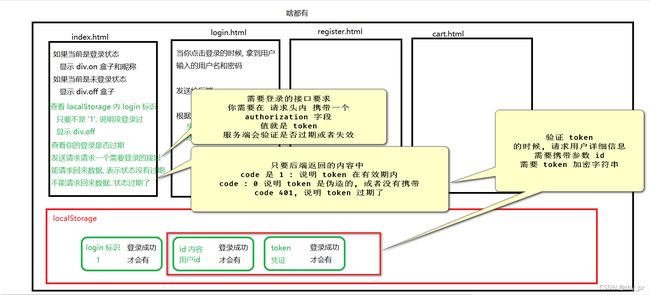
浏览器本地存储webStorage
+ 在 JS 内有, 有两个浏览器的本地存储
+ localStorage 永久存储
+ sessionStorage 会话存储(关闭浏览器就消失了)
+ 所有页面都可以访问, 因为是属于浏览器的一部分内容
localStorage // 永久存储
+ 设置:
=> 语法: window.locaStorage.setItem(key, value)
+ 修改:
=> 第二次设置同一个 名字 就是修改
+ 获取:
=> 语法: window.locaStorage.getItem(key)
=> 返回值:
-> 如果 lcoalStorage 内有这个数据, 那么就是这个数据对应的值
-> 如果 localStorage 内没有这个数据, 那么就是 null
+ 删除:
=> 语法: window.lcoalStroage.removeItem(key)
=> 作用: 删除 lcoalStroage 内对应的该数据
sessionStorage // 会话存储
+ 设置:
=> 语法: window.sessionStorage.setItem(key, value)
+ 修改:
=> 第二次设置同一个 名字 就是修改
+ 获取:
=> 语法: window.sessionStorage.getItem(key)
=> 返回值:
-> 如果 SessionStorage 内有这个数据, 那么就是这个数据对应的值
-> 如果 SessionStorage 内没有这个数据, 那么就是 null
+ 删除:
=> 语法: window.sessionStorage.removeItem(key)
ajax 状态码
+ 用一个数字来描述当前这个 ajax 处于什么步骤
如何拿到 ajax 状态码语法:
+ 语法: ajax对象.readyState
+ 得到: 就是当前 ajax 的状态码
意义: (记住, 熟读并背诵全文)
0: 表示创建 ajax 对象成功
1: 表示配置请求信息成功
2: 表示请求已经发送出去, 并且服务器给回的响应已经到了 浏览器
3: 表示浏览器正在解析响应报文, 并且把真实响应体内容逐步赋值给 xhr 的 responseText
4: 表示浏览器解析响应报文完成, xhr 对象内已经有完整的响应体内容了
事件: + 当 ajax 状态码改变的时候触发
+ xhr.onreadystatechange = function () {}
http 状态码
+ 是网络协议的一部分+ 用来描述本次请求的状态
+ 各种数字来描述各种情况
分类:
1. 100 ~ 199 => 表示 连接继续
2. 200 ~ 299 => 表示 各种意义的成功
=> 200 标准成功
=> 201 创建成功
=> 204 删除成功
=> ...
3. 300 ~ 399 => 表示 重定向
=> 重定向: 你请求的是 a 服务器地址, 但是 a 服务器把你的请求转嫁到了 b 服务器, 真实给你返回数据的是 b 服务器
=> 301: 永久重定向
=> 302: 临时重定向
=> 304: 缓存
=> ...
4. 400 ~ 499 => 表示各种客户端错误
=> 404: 地址不对
=> 403: 权限不够
=> ...
5. 500 ~ 599 => 表示各种服务端错误
=> 500: 表示标准服务器错误
=> 501: 服务器过载或维护
=> ...
语法: xhr.status 得到: 本次请求的 http 状态码
ajax 的兼容问题(了解, 不主动兼容)
1. 创建 ajax 对象的兼容问题
=> 标准浏览器: new XMLHttpRequest()
=> IE 低版本: new ActiveXObject('Microsoft.XMLHTTP')
=> 注意: 需要在真实的 IE 低版本内核中才能使用
2. 接受响应的事件
=> 标准浏览器: xhr.onload = function () {}
=> IE 低版本: xhr.onreadystatechange = function () {}
-> 在事件内进行一些条件判断来实现
封装 ajax
参数:
1. 请求地址(url)
2. 请求方式(method)
3. 是否异步(async)
4. 携带给后端的参数(data)
5. 是否存在 token(token)
6. 是否对响应体进行解析(dataType)
7. 请求成功后执行的函数(success)
参数是否有默认值:
1. url: 没有, 必填
2. method: 可以有, GET
3. async: 可以有, 默认 true, 选填是 false 表示非异步
4. data: 可以有, ''
5. token: 可以有, ''
6. dataType: 可以有, 'string' 表示不执行 JSON.parse(), 选填 'json' 表示执行 JSON.parse()
7. success: 可以有, 默认是一个空函数
封装--ajax_tby_pr的博客-CSDN博客
回调函数 callback
+ 一种封装代码的手段
+ 什么是 callback
=> 把 函数A 当实参传递到 函数B 内
=> 在 函数B 内使用形参调用 函数A
=> 我们管这个行为叫做 回调函数
=> 我们说 函数A 是 函数B 的回调函数
+ 为什么需要 callback
=> 当你在封装代码的时候
=> 并且代码内有异步的时候
=> 并且需要在 异步的 末尾 做一些事情的时候
=> 使用 callback
解释: 为什么异步的末尾封装要使用 callback
+ 因为 JS 的单线程
+ 同一个时间点只能做一个事情
+ 主要: 异步的结束时间不确定
+ 例子: 外卖
=> 一个外卖员同一个时间点只能做一件事情
=> 如果你希望多带一双筷子
=> 方案1: 等到外卖员刚好到达店里的时候, 给他打电话
=> 方案2: 在点餐的时候给一个备注
// 外卖公司做好的事情
function waimai(beizhu) {
var time = 1000 * Math.round(Math.random() * 5 + 1)
console.log('在路上')
setTimeout(() => {
console.log('到达店里了, 拿到外卖')
// 不管什么时候到了店里
// 拿到外卖以后, 把 备注 的内容执行一下
beizhu()
}, time)
}
// 用户的需求: 想多拿一双筷子
waimai(function () { console.log('多拿一双筷子') })回调地狱(套娃)
回调函数里 套 回调函数 再套 回调函数.
需求:
1. 发送请求到 /test/first
2. 发送请求到 /test/second
=> 前提: 必须要等到第一个请求结束以后再次发送
3. 发送请求到 /test/third
=> 前提: 必须要等到第二个请求结束以后再次发送
+ 一种使用回调函数封装的代码时候的情况
+ 回调函数的使用是有函数嵌套在里面的
+ 当你大量使用回调函数封装的代码的时候, 会出现结构紊乱
=> 不利于代码的阅读和维护
+ 为了解决回调地狱 => ES6 的语法内出现了一个新的语法, 叫做 Promise
=> 为了把 异步代码 封装变成 Promise 语法的封装
=> 不在使用 回调函数 来封装 异步代码了
=> 本质: 封装异步代码的
认识 Promise // ES6 语法
+ 是一个 ES6 出现的语法
+ Promise 也是一个 JS 内置的构造函数
承诺有多少个状态 ?
=> 继续(执行)
=> 成功
=> 失败
=> 承诺状态的转换只能有一次
-> 要么是 继续转换成 成功
-> 要么是 继续转换成 失败
Promise 也有三个状态
=> 继续: pending
=> 成功: fulfilled
=> 失败: rejected
Promise 的基础语法
=> const p = new Promise(function a(resolve, reject) {
// 你要封装的异步代码
})
=> promise 对象可以调用两个方法
1. p.then(function () {})
2. p.catch(function () {})
=> a 函数可以接受两个参数
1. 第一个参数: 可以将该 Promise 的状态转换为 成功
2. 第二个参数: 可以将该 Promsie 的状态转换为 失败

// 当你书写 resolve() 的时候, 就是在把 该 promsie 的状态转换为成功
// 执行 then 的时候书写的 b 函数
// 当你书写 reject() 的时候, 就是在把 该 promise 的状态转换为失败
// 执行 catch 的时候书写的 c 函数
Promise 进阶
+ 当一个 Promise 的 then 内的代码
+ 只要你在第一个 then 里面返回 return 一个新的 promise 对象
+ 新promise 对象的 then 可以在第一个 then 后面连续书写
const p = new Promise((resolve, reject) => {
// 做异步的事情
ajax({
url: 'http://localhost:8888/test/first',
success: function (res) {
resolve(res)
}
})
})
// 向拿到 p 的 resolve 的结果
// 就得写 p.then()
p
.then(function (res) {
console.log('第一次请求的结果')
console.log(res)
// 做第二个事情
const p2 = new Promise((resolve, reject) => {
ajax({
url: 'http://localhost:8888/test/second',
dataType: 'json',
success: function (res) {
resolve(res)
}
})
})
// 在第一个 then 内部 return 一个 新的 promise 对象 p2
return p2
})
.then(res => {
console.log('第二次的请求结果')
console.log(res)
})async 和 await 关键字 (ES7 以后的语法)
+ 为了解决 Promise 的问题
+ 核心作用: 把 异步代码 写的 看起来像 同步代码, 本质还是异步
async 关键字
+ 使用: 书写在函数的前面
=> async function () {}
=> async () => {}
+ 作用:
1. 该函数内可以使用 await 关键字了
2. 把该函数变成 异步函数, 只是叫做 异步函数
=> 影响的是函数内部的代码
await 关键字
+ 要求:
1. await 后面的内容必须是一个 promise 对象
2. await 必须写在一个有 async 关键字的函数内部
+ 作用:
=> 可以把 promise 中本该在 then 内的代码直接定义变量接受
=> 后续的代码需要等到 promise 执行完毕才会执行

改为:
// pAjax 返回出来的 promise 对象会执行
// 把 resolve() 的时候 括号里面的内容 赋值给 r1. 在继续向后执行代码
![]()
最后 :
console.log('start')
async function fn() {
// 此时 fn 函数内可以使用 await 关键字了
// pAjax 返回出来的 promise 对象会执行
// 把 resolve() 的时候 括号里面的内容 赋值给 r1. 在继续向后执行代码
const r1 = await pAjax({ url: 'http://localhost:8888/test/first' })
console.log(r1)
// 需求2:
const r2 = await pAjax({
url: 'http://localhost:8888/test/second',
dataType: 'json'
})
console.log(r2)
// 需求3:
const r3 = await pAjax({
url: 'http://localhost:8888/test/third',
data: 'name=Jack&age=20',
dataType: 'json'
})
console.log(r3)
}
fn()
console.log('end')认识服务器
php
MySQL数据库
php 操作 MySQL 数据库
sql 语句
服务器,php,MySQL_tby_pr的博客-CSDN博客
cookie
+ 客户端的一个存储空间
cookie 的特点
1. 按照域名存储的
+ 哪一个域名存储起来, 哪一个域名使用
2. 必须依赖服务器
+ 本地打开的页面是无法存取 cookie
3. cookie 的时效性
+ 默认是会话级别, 关闭浏览器就没有了
+ 可以手动设置时效
+ 手动设置的时候, 和你是否关闭电脑, 是否关闭浏览器没有关系
4. cookie 存储格式
+ 一条cookie 的存储格式是 key=value
+ 多条cookie 的存储格式是 key=value; key2=value2; key3=value
5. cookie 空间的存储大小
+ 4KB 左右
+ 50 条左右
6. 请求的自动携带
+ 当你的 cookie 空间中有数据的时候
+ 只要你在当前域名发起任何请求, 都会在请求头中自动把 cookie 空间内的所有数据带携带
7. 前后端操作
+ 前端可以通过 JS 操作 存取
+ 任何一个后端语言都可以操作 存取
本地存储之间的区别(重点)****
1. 出现时间
=> cookie 是一直有
=> localStorgae/sessionStorage 是 H5 标准下才有的
2. 存储大小
=> cookie 大概是 4KB 左右
=> localStorage/sessionStorage 大概是 20MB 左右
3. 时效性
=> cookie 默认是会话级别, 可以手动设置
=> localStorage/sessionStorage 有浏览器 API 固定好不能手动设置
-> lcoalStorage 就是永久存储
-> sessionStorage 就是会话存储
4. 请求携带
=> cookie 内存储的数据会自动携带在请求头
=> localStorage/sessionStorage 内存储的内容不会自动携带, 需要手动设置
5. 操作
=> cookie 是可以前后端操作的
=> localStorage/sessionStorage 只能前端操作, 后端语言不能操作
扩展: 在任何服务端语言内有一个 服务器存储空间, 叫做 session
前端操作 cookie
+ document.cookie
=> 读写都是用这一个语法
1. 前端设置 cookie
+ 语法: document.cookie = 'key=value'
+ 注意:
=> 一次只能设置一条 cookie
=> cookie 的key的value中不能出现分号
=> 一条 cookie 的 分号后面的内容, 是用来修饰这一个 cookie 的
=> 设置的 cookie 默认是会话级别的 cookie
2. 前端设置带有时效性的 cookie
+ 语法: document.cookie = 'key=value;expires=' + 时间对象
+ 注意: 不管你给他的时间对象是什么时间, 是哪一个时区的时间, cookie 都会当做世界标准时间来使用
=> 我们获取到的时间对象是 9:30
=> 因为我们前端 JS 获取的是当前终端的时间
=> 又因为我们处在 +0800 时区, 所以我们拿到的是 北京时间 9:30
=> 当你把 9:30 设置给 cookie 的时候, cookie 会把 9:30 当做世界标准时间来使用
=> 会决定本条 cookie 在世界标准时间 9:30 的时候过期
=> 世界标准时间的 9:30 其实使我们 北京时间 17:30
+ 问题: 我应该如何设置一条能在当前时间 30s 以后就过期的 cookie ?
=> 只要我拿到 当前时间对象
=> 把时间对象向前调整 8个小时
=> 再把时间对象向后调整 30s
=> 把这个时间点设置给 cookie , 就能在当前终端时间 30s 以后过期
=> 例子:
-> 拿到时间节点是 9:30(终端时间)
-> 向前调整8个小时 1:30(终端时间)
-> 向后调整30s 1:30:30
-> 把 1:30:30 设置给 cookie
-> cookie 会把他当做世界标准时间 1:30:30
-> 世界标准时间的 1:30:30, 就是终端时间的 9:30:30
3. 封装 设置 cookie 的操作
封装--cookie函数[设置 / 获取 / 删除]_tby_pr的博客-CSDN博客
3-1. 准备一个函数
=> 接受多少个参数
=> 第一个参数: key
=> 第二个参数: value
=> 第三个参数: 过期时间
=> 问题: 过期时间给一个什么数据 ?
-> 如果给一个时间对象
+ setcookie('a', 100, new Date())
+ 我们需要手动调整好时间对象
-> 如果给一个数字用来表示秒
+ setcookie('a', 100, 30)
3-2. 判断
=> 如果你没有传递 expires 这个参数, 表示你要设置会话级别的 cookie
=> 如果你传递了 expires 这个参数, 表示你要设置有时效性的 cookie, 设置一下时间对象
3-3. 根据传递进来的 expires 调整时间对象
4. 获取 cookie
+ 语法: document.cookie
+ 得到: cookie 空间中所有的 cookie 内容, 是一个字符串格式
5. 封装一个获取 cookie 的函数
5-1. 准备函数
=> 问题: 需要接受几个参数 ?
=> 第一个参数: key, 选填
=> 例子: c=300; a=100; b=200
-> 如果你用的时候, getcookie('a'), 你得到的返回值就是 100
-> 如果你用的时候, getcookie(), 你得到的返回值就是 { a: 100, b: 200, c: 300 }
5-2. 把 cookie 解析成对象数据类型
6. 删除 cookie
+ cookie 是不能手动删除的
+ 如果你想删除 cookie, 只能是把 cookie 的过期时间设置为当前时间以前
+ 有浏览器去删除
函数说明注释 /** */
JS从入门到精通全套完整版-298
36分钟
* 后面写函数说明
{} 里写数据类型
形参 后面写注释

封装--cookie函数[设置 / 获取 / 删除]
封装--cookie函数[设置 / 获取 / 删除]_tby_pr的博客-CSDN博客
同源策略
+ 注意: 同源策略是 浏览器 给出的一个关于网络安全的请求方案
什么是同源策略 ?
+ 当你在发送请求的时候
+ 如果 打开页面的 完整地址 和 接受服务器的 完整地址
=> 只要 域名 或者 传输协议 或者 端口号 有任意一个不一样
=> 就是触发了同源策略
=> 浏览器不允许你获取该服务器的数据
跨域请求
+ 我们需要请求非同源服务器的数据
+ 我们管这种请求叫做 跨域请求
+ 常见的跨域请求解决方案
1. jsonp
2. cors(跨域资源共享)
3. proxy(代理)
jsonp 跨域方式(绕开) // script 标签的 src 属性
+ 是一个 ajax 技术没有关系的 跨域方式
认识一下 script 标签 和 src 属性
=> 因为 src 属性只是标注引入一个外部资源的路径
=> script 标签默认会把你引入的所有内容当做 js 代码来执行
=> src 属性的特点
-> src 属性是 W3C 标准给出专门用来引入外部资源的属性
-> 浏览器不会去管 src 引入的内容是否是跨域的
-> 浏览器的同源策略不管 src 属性
jsonp 的实现方式
+ 利用 script 标签的 src 属性, 去请求一个 非同源的 服务器地址
+ 要求: 服务器给出的内容必须是一段合法的可以执行的 js 代码
+ 要求: 服务器给出的 js 代码需要是一个 '函数名(数据)' 的格式
前端准备一个函数名给到后端 callback=fn
案例--搜索引擎(百度 / jsonp)
案例--搜索引擎(百度 / jsonp)_tby_pr的博客-CSDN博客
cors(跨域资源共享)
+ 和前端没有任何关系的一种跨域请求方案
后端代码告诉浏览器, 你别管, 我愿意给他数据
+ 前端: 该如何发 ajax 请求, 就如何发
proxy(代理)
// 当你发送请求的时候, 请求地址 直接书写 代理标识符
// nginx 就会帮你把请求转发到 proxy_pass 配置的地址了
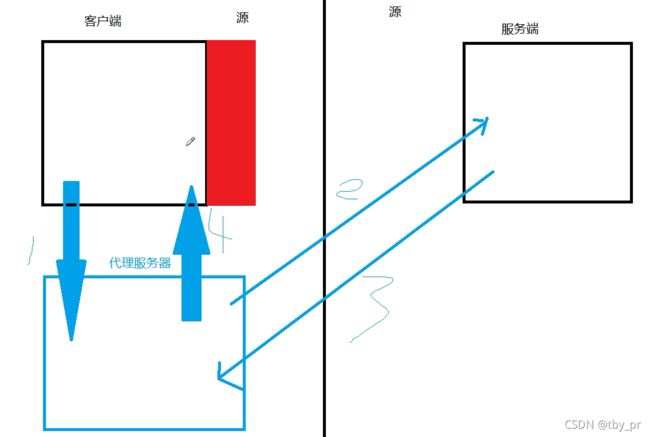
+ 任何服务器都可以实现代理请求转发的功能
+ apache 服务器
-> 代理 http 请求免费
-> 代理 https 请求要证书
+ nginx 服务器
-> 代理 http 和 https 都是免费的
+ 打开小皮面板
-> apahce 停止
-> nginx 开启
配置代理
+ 打开小皮面板
+ 点击左侧边栏 设置
+ 点击顶部选项 配置文件
+ 点击 vhosts.conf 文件
+ 选择下面的 0localhost_端口号.conf
+ 找到 server 的闭合括号的上一行, 书写代理配置
location /xx {
proxy_pass 你跨域的地址;
}
/xx: 代理标识符
+ 关键: 重启服务器
案例--不等高瀑布流
案例--不等高瀑布流_tby_pr的博客-CSDN博客
总结
cookie
=> 是一个客户端的存储空间
=> 可以存储一些简单的数据, 跨越页面进行传递数据
cookie 的特点
1. cookie 按照域名存储
=> 谁存储的谁使用
2. cookie 必须依赖服务器使用
=> 因为没有服务器没有域名
3. cookie 的时效性
=> 默认是会话级别的时效(关闭页面就没有了)
=> 可以手动设置时效
4. cookie 的存储格式
=> 一条 cookie, key=value 的格式
=> 多条 cookie, key=value; key2=value2
5. cookie 存储大小
=> 4KB 左右
=> 50 条左右
6. cookie 的自动携带
=> 只要 cookie 空间内有数据
=> 就会在该域名下发送任何请求的时候自动携带
7. cookie 的操作
=> 前后端都可以操作
=> 前端可以依赖 JS 操作
=> 后端任何语言可以操作
cookie 和 localStorage/sessionStorage 的区别
1. 出现时间
=> cookie 一直有
=> localStorage/sessionStorage H5 标准才有的
2. 存储大小
=> cookie 4KB 左右
=> localStorage/sessionStorage 20MB 左右
3. 时效性
=> cookie 默认是会话级别, 可以手动设置
=> localStorage/sessionStorage 一个是 永久, 一个会 会话, 不能设置
4. 请求自动携带
=> cookie 会自动携带
=> localStorage/sessionStorage 不会自动携带
5. 操作
=> cookie 前后端后可以操作
=> localStorage/sessionStorage 只能前端操作, 后端不行
同源策略
+ 浏览器给出的一个关于网络安全方面的协议(规则)
+ 约定了, 发送请求的时候
=> 如果 传输协议, 域名, 端口号, 三个有任意一个不一样
=> 就是触发了同源策略
=> 浏览器不让你使用该服务器的数据
+ 我们管触发了同源策略的请求叫做 跨域请求
跨域请求的解决方案
+ 跨域请求, 请求 "别人家" 的服务器的数据
1. jsonp
=> 利用了 script 标签会把请求回来的东西当做 js 代码执行
=> 利用了 src 不受同源策略的影响
=> 要求:
-> 后端需要返回一个合法的可以执行的 js 代码
-> 后端返回的数据格式是 '函数名(数据)' 这样的字符串
-> 前端提前准备好函数, 把函数名以参数的形式告诉后端
2. cors(跨域资源共享)
=> 一个和前端没有关系的跨域方式
=> 有后端开启
3. proxy(代理)
=> 利用代理服务器转发请求的方式
=> 绕开同源策略的影响
函数
+ 因为 闭包 是一种函数的高阶应用
1. 了解函数的特点
1-1. 保护私有变量
=> 因为每一个函数会生成一个独立的私有作用域
=> 在函数内定义的变量, 我们叫做 私有变量
=> 该变量只能在该函数作用域及下级作用域内使用, 外部不能使用
1-2. 函数定义时不解析变量
=> 函数定义的时候, 函数体内的代码完全不执行
=> 任何变量不做解析
=> 直到执行的时候才会解析变量
2. 函数的两个阶段分别作了什么事情(记住)
2-1. 函数定义阶段
2-1-1. 在 堆内存 中开辟一段存储空间
2-1-2. 把 函数体内的代码, 一模一样的复制一份, 以字符串的形式放在这个空间内, 此时不解析变量
2-1-3. 把 堆内存 中的空间地址赋值给变量
2-2. 函数调用阶段
2-2-1. 按照 变量名(函数名) 内存储的地址找到 堆内存 中对应的空间
2-2-2. 在 调用栈 内开辟一段新的函数执行空间
2-2-3. 在 新的 执行空间内 进行形参赋值
2-2-4. 在 新的 执行空间内 进行预解析
2-2-5. 在 新的 执行空间内 把函数体内的代码当做 js 代码执行一遍
2-2-6. 把 开辟在调用栈 内的 执行空间 销毁(等到所有代码执行完毕)

一个不会销毁的函数执行空间
+ 当这个函数返回一个 复杂数据类型, 并且在函数外部有变量接受的情况
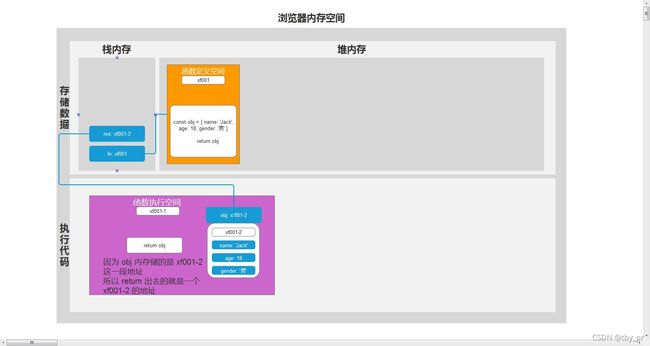
闭包:
+ 概念: 函数内的函数
+ 特点:
1. 延长变量的声明周期
=> 优点: 变量声明周期延长了
=> 缺点: 需要一个 闭包 结构
2. 可以在函数外部访问函数内的私有变量
=> 优点: 访问和使用变得更加灵活了
=> 缺点: 需要一个 闭包 结构
3. 保护变量私有化
=> 优点: 变量不会污染全局
=> 缺点: 外部没有办法使用, 如果需要使用, 得写一个 闭包 结构
+ 出现:
=> 需要一个不会销毁的函数执行空间
=> 函数内 直接 或者 间接 返回一个新的函数
=> 内部函数要使用着外部函数的私有变量
=> 我们管 内部函数(fnB) 叫做 外部函数(fnA) 的 闭包函数
+ 闭包直接返回一个函数
在函数外部拿到函数内部的私有变量:
function fnA() {
// 外部函数的 私有变量
var num = 100
var str = 'hello world'
function fnB() {
return num
}
return fnB
}
const res = fnA()
// 你在函数 fnA 的外面是没有办法拿到 num 这个私有变量的
// n 接受的就是 fnA 函数内定义的 私有变量 num 的值
var n = res()
console.log(n)闭包的间接返回一个函数
+ 在闭包内, 返回的其实是一个 对象数据类型 + 对象内有若干个函数
function outer() {
// 准备私有变量
var n = 100
var s = 'hello world'
// 准备一个对象数据结构
const obj = {
getN: function () { return n },
getS: function () { return s },
setN: function (val) { n = val }
}
// 返回这个对象数据结构
return obj
}
const res = outer()
// 我需要用到 outer 内的 n 变量的时候
console.log(res.getN())
// 我需要用到 outer 内的 s 变量的时候
console.log(res.getS())
// 我调用 res 内的 setN 函数的时候
res.setN(200)
// 再次访问 outer 内的 n 变量的时候
console.log(res.getN())
// ==========================================
// 新的函数执行空间
const res2 = outer()
console.log(res2.getN()) // 100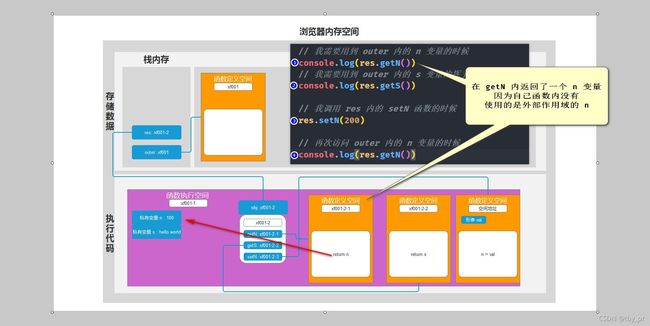
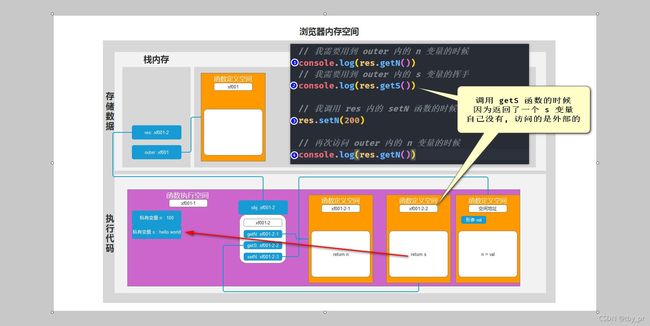
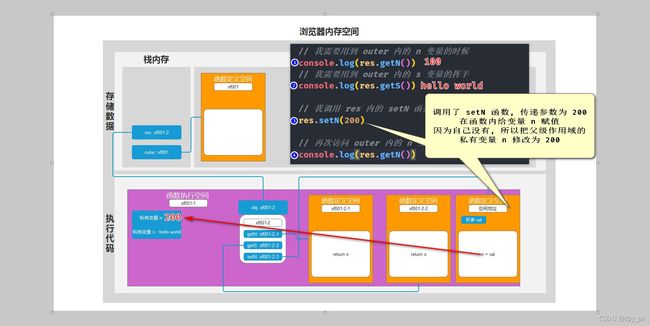
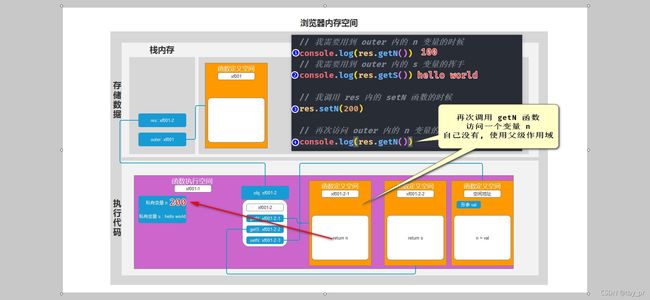
继承 extend
JavaScript从零基础入门到精通_315
+ 关于 构造函数 的高阶应用
+ 当多个构造函数需要使用一些共同的方法或属性时
=> 我们需要把这些共同的东西拿出来,单独书写一个构造函数
=> 让其他的构造函数去继承自这个公共的构造函数
+ 概念
=> 让 构造函数B 的实例能够使用 构造函数A 的属性和方法
=> 我们管构造函数B 是 构造函数A 的子类
=>我们管构造函数A 是 构造函数B 的父类
+ 构造函数
=> 原型: 每一个构造函数天生自带的一个属性, 是一个对象数据类型
=> 为什么要要原型
-> 为了解决构造函数的不合理
-> 书写构造函数的时候
-> 属性直接书写在构造函数体内
-> 方法书写在构造函数的原型上
=> 目的: 为了书写一些方法, 给到该构造函数的实例使用
-> 把每一个实例都会用到的方法, 提取出来放在了构造函数的原型上
+ 伪代码:
构造函数体 A
构造函数原型 -> 方法a
构造函数原型 -> 方法b 构造函数C
构造函数A 的实例 { 方法a, 方法b, 方法c } 构造函数C原型 -> 方法c
构造函数体 B
构造函数原型 -> 方法d
构造函数原型 -> 方法e
构造函数B 的实例 { 方法c, 方法d, 方法e }
+ 常见的继承方案
1. 原型继承
2. call继承(借用继承 / 借用构造函数继承)
3. 组合继承
4. ES6 的继承语法
5. 拷贝继承
6.寄生继承
7.寄生组合继承
// 父类
function Person(name, age) {
this.name = name
this.age = age
}
Person.prototype.sayHi = function () { console.log('hello world') }
/*
父类:
const p = new Person('Jack', 18)
p === {
name: 'Jack',
age: 18,
__proto__: Person.prototype {
sayHi: fn,
constructor: Person,
__proto__: Object.prototpye
}
}
*/原型继承
/*
原型继承(原型链继承)
+ 核心: 子类的 原型 指向 父类的 实例
+ 子类.prototype = new 父类
优点:
+ 父类的 构造函数体内 和 原型 上的内容都能继承下来
缺点:
+ 继承下来的属性不在自己身上, 子类的实例的所有属性分开了两部分书写
+ 同样都是给 子类实例 使用的属性, 在两个位置传递参数
*/
// 子类
function Student(gender) {
this.gender = gender
}
// 本身你的 Student.prototype 保存的是一个 对象数据类型 的地址
// Student.prototype 既然可以被赋值
// 那么我的 Person 的实例 p 也是一个 对象数据类型
// 我就可以直接把 p 赋值给 Student.prototype
// 因为这句代码的执行
// Student 的实例可以使用 Person 书写的属性和方法了
// 我们就说 Student 继承自 Person
// Student 是 Person 的 子类
// Person 是 Student 的 父类
Student.prototype = new Person('Jack', 18)
const s = new Student('男')
console.log(s)
console.log(s.gender) // 自己的, 男
console.log(s.name)
s.sayHi()call 继承(借用继承 / 借用构造函数继承)
/*
call 继承(借用继承 / 借用构造函数继承)
+ 核心: 利用 call 方法调用父类构造函数
优点:
+ 可以把继承来的属性直接出现在 子类的实例 身上
+ 一个实例使用的属性可以再一个位置传递参数了
缺点:
+ 只能继承 构造函数体内 书写的内容, 构造函数的 原型上 不能继承
*/
// 子类
function Student(gender, name, age) {
this.gender = gender
// 这里是 Student 的构造函数体内
// 这里的 this 是 Student 的每个实例对象
// 利用 call 调用 Person 构造函数, 把 Person 内的 this 修改为 Student 内的 this
// 把 Person 内的 this 修改为 Student 的每一个实例对象
// Person 构造函数体内书写成员就都添加到了 Student 的实例身上
Person.call(this, name, age)
}
Student.prototype.play = function () { console.log('你好 世界') }
const s = new Student('男', '张三', 20)
const s2 = new Student('女', '李四', 22)
console.log(s)
console.log(s2)
// 因为 call 方法调用 Person 的时候, 把 Person 内的 this 修改为 s 了
// 所以 name 和 age 成员添加到了 s 身上组合继承
/*
组合继承
+ 核心: 把 原型继承 和 call继承 合并在一起就做组合继承
*/
// 子类
function Student(gender, name, age) {
this.gender = gender
// 实现 call 继承
// 目的: 为了把父类构造函数体内的内容放在子类实例自己身上
Person.call(this, name, age)
}
// 实现原型继承
// 目的: 为了把 Person 的 prototype 内的内容继承下来
Student.prototype = new Person()
Student.prototype.play = function () { console.log('你好 世界') }
// 创建子类的实例
const s = new Student('男', '张三', 20)
console.log(s)ES6 的继承方案
/*
ES6 的继承方案
+ ES6 官方提出了关键字来实现继承
语法:
1. 使用 extends 关键字
=> class 子类 extends 父类 { ... }
2. 在子类的 constructor 内书写
=> super()
+ 注意:
=> 必须要两个条件同时书写
=> super 必须写在所有 this 的最前面
=> 父类如果是一个 ES5 的构造函数, 那么可以正常继承
*/
// ES6 的类的继承
// 创建一个 继承自 Person 的 Student 类
// extends 关键字相当于原型继承
class Student extends Person {
constructor (gender, name, age) {
// 相当于在调用父类构造函数体, 把 name 和 age 传递过去
// 相当于 call 继承
super(name, age)
this.gender = gender
}
play () { console.log('你好 世界') }
}
const s = new Student('男', 'Jack', 20)
console.log(s)拷贝继承(for in 继承)
+ 利用 for in 循环的特点,来继承所有的内容
+ 先实例化一个父类的实例
+ 使用 for in 循环来遍历这个实例对象
=> 因为 for in 循环不光遍历对象自己,还会遍历 __proto__
+ 直接把父类实例身上的所有内容直接复制到子类的 prototype
+ 核心代码
const p = new Person('Jack',18)
for (let key in p) {
console.log('key')
}
拷贝继承的优缺点
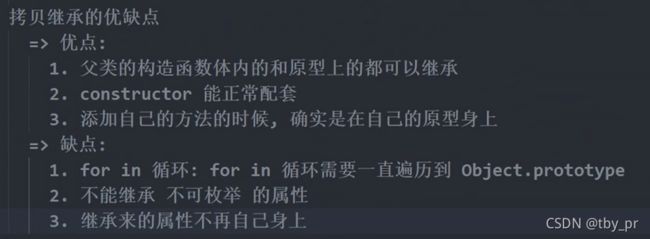
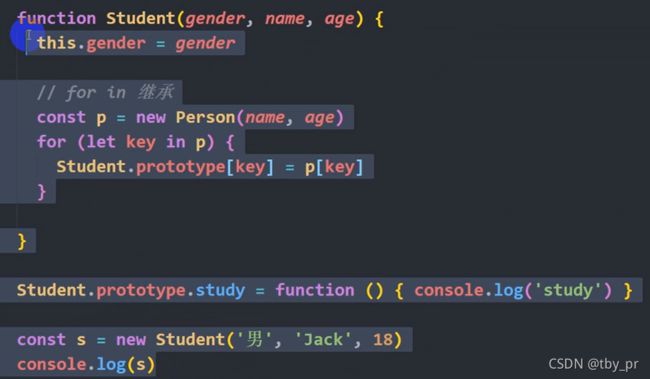
寄生继承
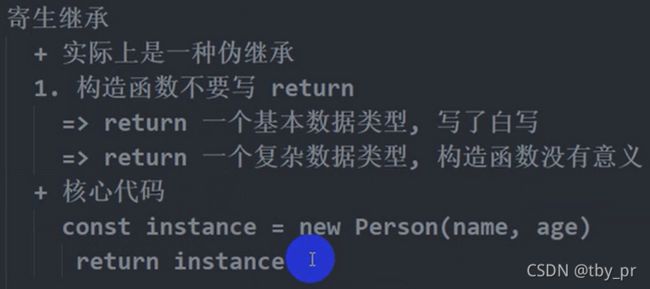
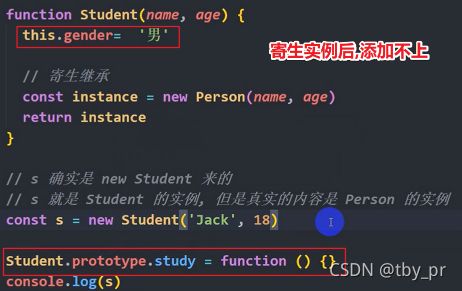

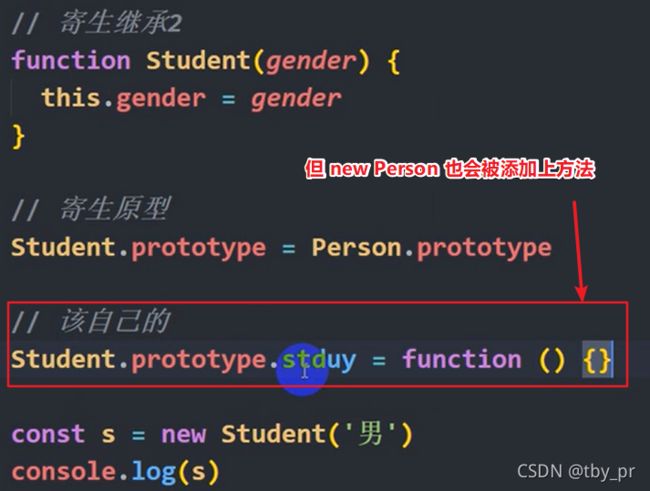
寄生继承的优缺点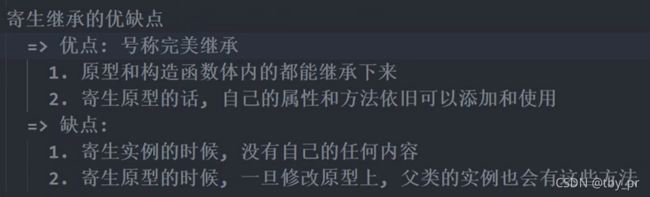
寄生式组合继承(完美继承)
JavaScript从零基础入门到精通_321寄生组合继承
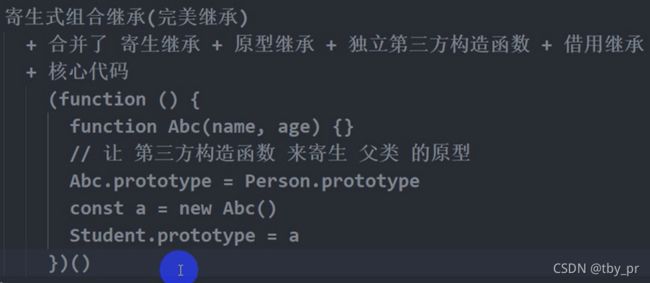

设计模式(非官方)
+ 为了解决某一类问题给出的简洁而优化的解决方案
1. 单例模式
+ 一个构造函数一生只有一个 实例对象
+ 例子: 弹出层
=> 一个网站的某一个页面, 连续弹出多次弹出层
=> 最好: 每次弹出的都是这一个 div, 只是文字和显示的效果更换了
+ 核心代码:
let instance = null
function singleton() {
if (!instance) instance = new 类
return instance
}class Dialog {
constructor (name) {
this.name = name
}
}
// 单例模式核心代码
let instance = null
function singleton() {
if (!instance) instance = new Dialog('提示')
return instance
}
// 将来使用 Dialog 的时候
// 全局定义一个变量叫做 instance 值是 null
// 因为 singleton 函数的第一次执行, instance 被修改为 Dialog 的实例
// 第一次调用 singleton 函数
// 条件判断 !instance 为 true
// 执行代码 instance = new Dialog('提示')
// 执行代码 return instance
// d1 得到的就是 Dialog 的实例
const d1 = singleton()
// 第二次调用 singleton 函数
// 条件判断 !instance 为 false
// 执行代码 return instance
// 因为 此时 instance 是第一次 new 出来的实例
// 这里返回的依旧是第一次的实例
// d2 得到的还是第一次的实例
const d2 = singleton()
console.log(d1)
console.log(d2)
console.log(d2 === d1) //true单例模式 - 修饰
const Person = (function outer() {
// 类 的本身
class Person {
constructor () {
// 属于 构造函数 体内容
// 问题: 什么时候会执行 ?
// 只有 new Person 的时候会执行
// 只要这里的内容执行了, 必然会出现一个新的实例
// 因为单例模式只能有一个实例, 所以这里的代码只能执行一次
this.name = 'Jack'
}
// 准备一个方法去修改 name 成员的值
// setName 方法的调用不会创建新的实例出现
// 把已经出现的实例的 name 属性修改掉
setName (val) {
this.name = val
}
}
// 单例模式核心代码
let instance = null
return function inner(name) {
if (!instance) instance = new Person()
// 我想设置到 实例的 name 属性上
// 每一次不管是真的 new 还是 假的 new , 这里的代码都会执行
instance.setName(name)
return instance
}
})()
const p1 = new Person('张三')
console.log(p1)
const p2 = new Person('李四')
console.log(p2)
console.log(p2 === p1)案例--自定义弹出层
案例--自定义弹出层_tby_pr的博客-CSDN博客
设计模式 - 观察者模式(发布订阅模式)
+ 逻辑
=> 有两个对象的出现
-> 一个是 观察者, 负责观察别人的动向, 一旦动向改变, 触发技能
-> 一个是 被观察者, 负责被别人观察, 一旦我的动向改变了, 通知观察者
观察者
+ 属性:
=> name: 名字
+ 方法:
=> 技能
被观察者
+ 属性:
=> 自己的状态
=> 观察者列表
+ 方法:
=> 添加观察者至列表
=> 删除观察者至列表
=> 状态改变
=> 通知观察者列表内的所有观察者
// 观察者类
class Observer {
constructor (name, fn) {
this.name = name
this.init = () => fn(this.name)
}
}
// 被观察者类
class Subject {
constructor (name, state) {
this.name = name
this.state = state
// 观察者列表
this.observers = []
}
addObserver (observer) {
// 向观察者列表内添加观察者
this.observers.push(observer)
}
removeObserver (observer) {
// 从观察者列表内删除观察者
this.observers = this.observers.filter(item => item.name !== observer.name)
}
setState (state) {
// 修改状态
this.state = state
// 通知观察者
this.emit()
}
emit () {
// 通知观察者, 触发技能
this.observers.forEach(item => item.init())
}
}
// 创建观察者人员
const o1 = new Observer('玲', (name) => { console.log(`我是 ${ name }, 我要骂你了 ^_^`) })
const o2 = new Observer('狼', (name) => { console.log(`我是 ${ name }, 我要夸一夸你 (#^.^#)`) })
// 创建被观察者
const tangboyu = new Subject('宇', '学习')
// 添加观察者
tangboyu.addObserver(o1)
// tangboyu.addObserver(o2)深浅拷贝***
+ 在 JS 内, 对于 "复制" 有三个级别
1. 赋值
2. 浅拷贝
3. 深拷贝
1. 赋值:
+ 使用 赋值符号(=) 进行的操作
+ 对于基本数据类型, 赋值之后两个变量没有任何关系了
+ 对于复杂数据类型, 赋值之后两个变量操作一个数据存储空间
// 1. 赋值
let n1 = 5
// // 把 n1 的值赋值给了 n2
let n2 = n1
console.log(n1, n2)
n2 = 10
console.log(n1, n2)
let o1 = { name: 'Jack' }
// 把 o1 的值赋值给了 o2
// 因为 o1 内存储的是一个 对象数据类型 的地址
// 所以给到 o2 的依旧是一个 地址
let o2 = o1
console.log(o1, o2)
o2.name = 'Rose'
console.log(o1, o2)2. 浅拷贝 - for in 循环遍历
+ 自己使用 for in 循环去遍历数据结构
+ 复制出一份一模一样的数据结构
+ 对于一维数据结构有效
+ 如果是多维数据结构, 那么第二维度开始, 依旧是操作同一个存储空间
// 2. 浅拷贝
let o1 = { name: 'Jack', age: 18, info: { height: 180 } }
let o2 = {}
for (let k in o1) {
// 在进行 for in 遍历的时候
// o2.info = o1.info
// 因为 info 内存储的是一个 地址
// 赋值以后, o2.info 和 o1.info 存储的是同一个地址
o2[k] = o1[k]
}
console.log(o1, o2)
// 修改
o2.name = 'Rose'
o2.age = 20
console.log(o1, o2)
// 修改第二维度
o2.info.height = 2003. 深拷贝 - 方案1 - 递归
+ 自己使用 递归 的方式进行逐层数据结构的 遍历赋值
+ 复制出一份完全一模一样的数据结构
+ 不管多少维度, 都变成独立的两个内容
//3. 深拷贝
let o1 = {
name: 'Jack',
age: 18,
info: {
weight: 180,
height: 180,
desc: {
msg: '这个人很懒, 什么都没有留下!',
title: '你好 世界'
}
},
hobby: [ '吃饭', '睡觉', [ '篮球', '羽毛球', '足球' ] ]
}
let o2 = {}
//3-1. 书写函数来完成(递归函数)
function deepCopy(o2, o1) {
// 把 o1 的内容全部复制一份到 o2 内
//3-2. 遍历 o1
for (let k in o1) {
// 判断, 如果是 对象数据类型 或者 数组数据类型, 不进行复制
// 否则, 才进行复制
if (Object.prototype.toString.call(o1[k]) === '[object Object]') {
// 是对象
o2[k] = {}
// 在这个位置, o1[k] 是一个对象数据类型
// o2[k] 也是一个数据类型
// o1[k] 里面的每一个数据复制一份到 o2[k]
deepCopy(o2[k], o1[k])
} else if (Object.prototype.toString.call(o1[k]) === '[object Array]') {
// 是数组
o2[k] = []
deepCopy(o2[k], o1[k])
} else {
// 直接复制
o2[k] = o1[k]
}
}
}
deepCopy(o2, o1)
console.log(o1, o2)
//修改
o2.info.desc.title = 'hello world'4. 深拷贝 - 方案2 - json转换
+ 只能是在 对象 和 数组 数据结构中使用
+ 不能有函数
+ 利用 json 格式字符串
4-1. 把源数据转换成json 格式字符串
4-2. 把 json 格式字符串转换回 js 数据类型
// 4. 深拷贝 - 方案2
let o1 = {
name: 'Jack',
age: 18,
info: {
weight: 180,
height: 180,
desc: {
msg: '这个人很懒, 什么都没有留下!',
title: '你好 世界'
}
},
hobby: [ '吃饭', '睡觉', [ '篮球', '羽毛球', '足球' ] ]
}
// 4-1.
let jsonStr = JSON.stringify(o1)
// 4-2.
let o2 = JSON.parse(jsonStr)
console.log(o1, o2)
// 修改
o2.info.desc.msg = '这个人更懒!'案例--图片懒加载!!!***
案例--图片懒加载_tby_pr的博客-CSDN博客
+ 只有进入(即将进入)可是区域的图片才进行加载
+ 如果没有进入可视区域的图片不进行加载
问题1: 如果你希望实现图片懒加载, 那么渲染页面的时候, img 的 src 还能写吗 ?
+ 不能
+ 但是有需要直到该 img 标签应该引入的是哪一张图片
+ 所以我们以一个自定义属性的形式, 来把该 img 需要的图片地址记录在标签身上
问题2: 获取元素
+ 不能在全局获取
// 1. 渲染页面
const ul = document.querySelector('ul')
bindHtml()
function bindHtml() {
let str = ''
list.forEach(item => {
str += `
案例--函数节流和防抖***!!!
案例--函数节流和防抖_tby_pr的博客-CSDN博客
+ 两种处理重复高频触发事件的方式
节流
+ 在单位时间内只能触发一次
const inp = document.querySelector('input')
// 1. 函数节流
// 准备节流开关
// 开关为 true 的时候, 表示可以执行
// 开关为 false 的时候, 表示不可以执行
let flag = true
inp.oninput = function () {
// 这个事件内的代码是否执行, 取决于 节流开关
if (!flag) return
// 代码能执行到这里, 说明开关是开着的
flag = false
console.log(`我要搜索的内容是: ${ this.value }`)
// 设置单位时间以后, 讲开关打开
setTimeout(() => flag = true, 300)
}防抖
+ 在单位时间内, 如果重复出现同样的事件, 那么把前一次干掉
const inp = document.querySelector('input')
// 2. 函数防抖
// 准备一个变量接收定时器返回值
let timer = null
inp.oninput = function () {
// 每一次执行这个事件的时候, 都关闭一次定时器
clearInterval(timer)
// 把本来应该立即执行的事情, 延后执行
timer = setTimeout(() => {
console.log(`我要搜索的内容是: ${ this.value }`)
}, 300)
}