基于pytorch训练的VGG16神经网络模型完成手写数字的分割与识别
一、输入图像的预处理相关操作
1.图像的黑白反相+二值化
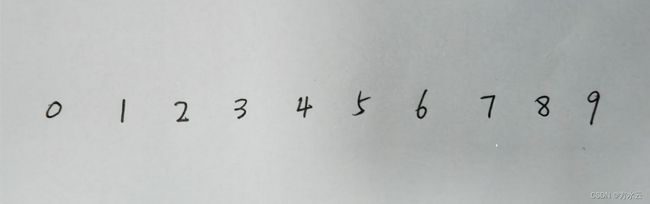 手写数字原图
手写数字原图
注:传入图片时需要对图片的分辨率进行修改,分辨率太大,显示的窗口会显示不全,如下图所示:
 分辨率太大导致的显示不全
分辨率太大导致的显示不全
我修改的图片分辨率为1700*616像素,自己观感合适即可。
如原图所示,我们手写的数字是黑色的,我们需要将黑色变成白色,再把每个数字分割裁剪成如mnist数据集一般(28*28),才能传入到神经网络中去进行字符识别。
具体请看如下代买及注释:
import cv2
import numpy as np
# 反相灰度图,将黑白灰度值颠倒
def accessPiexl(img):
height = img.shape[0] #图片像素点矩阵的行数
width = img.shape[1] #图片像素点矩阵的列数
for i in range(height):
for j in range(width): #灰度级0-255:255为白,0为黑
img[i][j] = 255 - img[i][j] #灰度值反转,黑变白,白变黑
return img
# 二值化反相图像
def accessBinary(img, threshold=128):
img = accessPiexl(img)
# 边缘膨胀,不加也可以
kernel = np.ones((3, 3), np.uint8) #3阶单位阵,数据类型是8位的
img = cv2.dilate(img, kernel, iterations=1) #将图片的高亮地区进行膨胀,也就是将我们手写的数字进行加粗
_, img = cv2.threshold(img, threshold, 0, cv2.THRESH_TOZERO)
#选取一个全局阈值,然后就把整幅图像分成了非黑即白的二值图像
# - 4. cv2.THRESH_TOZERO
# 大于阈值,保持原像素值; 小于等于,设定为0
return img测试函数效果的代码:
path = 'D:/beijing/writer_number.jpg' #图片路径
img = cv2.imread(path, 0) #图片按cv2打开,返回的就是像素点阵,是ndarray类型的矩阵
# cv2.IMREAD_COLOR:默认参数,读入一副彩色图片,忽略alpha通道,可用1作为实参替代
# cv2.IMREAD_GRAYSCALE:读入灰度图片,可用0作为实参替代
img = accessBinary(img)
cv2.imshow('test', img) #以窗口显示图片,'test'是窗口的名称
cv2.waitKey(0) #等待键盘响应,参数0代表,只有点击窗口的×,图片显示窗口才会关闭让我们具体看看各个函数的实现效果:
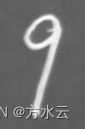 读入灰度图片
读入灰度图片 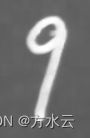 图片膨胀操作
图片膨胀操作  二值化操作
二值化操作
2.边框扫描+显示识别结果
接下来,我们将编写-在原图中显示边框-框出0-9十个数字,并在边框上显示神经网络的识别结果。
具体代码过程如下:
import cv2
import numpy as np
from change_img import accessBinary,accessPiexl
#这里的文件名记得改成自己命名的文件名
# 寻找边缘,返回边框的左上角和右下角(利用cv2.findContours)
def findBorderContours(path, maxArea=50):
img = cv2.imread(path, cv2.IMREAD_GRAYSCALE) #以灰度图片形式打开
img = accessBinary(img) #反相->加粗->二值化图片
contours, _ = cv2.findContours(img, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
#cv2.findContours:检测图像的轮廓
#cv2.findContours:接受的参数为二值图,即黑白的(不是灰度图)
#第二个参数表示轮廓的检索模式,有四种:
#cv2.RETR_EXTERNAL:表示只检测外轮廓
#第三个参数method为轮廓的近似办法
#CV_CHAIN_APPROX_NONE:保存物体边界上所有连续的轮廓点到contours向量内
#contours:list类型,list中每个元素都是图像中的一个轮廓-10个数字,10个轮廓
#cv2.findContours()函数返回两个值,一个是轮廓本身,还有一个是每条轮廓对应的属性
borders = [] #存储矩形框的左上角坐标和右下角坐标
for contour in contours:
# 将边缘轮廓拟合成一个边框
x, y, w, h = cv2.boundingRect(contour)
#得到轮廓的矩形边界,x,y是矩阵左上点的坐标,w,h是矩阵的宽和高
if w * h > maxArea: #maxArea=50
border = [(x, y), (x + w, y + h)]
#排除噪声等干扰,若边框内像素点(宽*高)<50,则认为是无用信息干扰
borders.append(border) #直接修改原始列表,从列表的末尾添加元素
return borders
# 在原图--彩色上显示结果及边框
def showResults(path, borders, results=None): #网络识别结果默认为results=None,因为现在还没进行识别,后续需要自己传入
img = cv2.imread(path) #若无设置,默认以彩色图像打开
# 绘制
for i, border in enumerate(borders):
cv2.rectangle(img, border[0], border[1], (0, 0, 255)) #绘制矩形框,颜色顺序BGR,(0,0,255)--代表全红
#参数表示依次为:(图片,长方形框左上角坐标, 长方形框右下角坐标,字体颜色,字体粗细)
if results: #传入的识别结果不为空,那么就在矩形框上显示数字字符
cv2.putText(img, str(results[i]), border[0], cv2.FONT_HERSHEY_COMPLEX, 0.8, (0, 255, 0), 1)
# 位置参数说明:(图片,要添加的文字,文字添加到图片上的位置,字体的类型,字体大小,字体颜色,字体粗细)
cv2.imshow('test', img)
cv2.waitKey(0) #不写这条代码,图片瞬间显示,瞬间关闭测试函数效果的代码:
path = 'D:/beijing/writer_number.jpg'
borders = findBorderContours(path) #找到所有的边框后,存储在列表中返回--borders[i]=[(x, y), (x + w, y + h)]
showResults(path, borders) #还有一个默认参数results=None,就是卷积网络识别后的结果,构成列表传入函数显示,这里暂时没传入,后续有识别完后在传入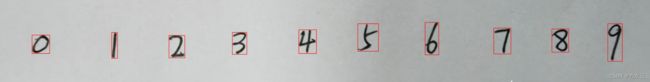 用边框框出手写数字
用边框框出手写数字
3.将边框框中的图像裁剪出+调整成mnist数据集的格式(28*28)
因为识别0-9的数字字符,一般都是采用mnist数据集进行训练的,所以需要把边框选中的图像调整成28*28的形式。
具体代码如下所示:
import cv2
import numpy as np
from scan_border import findBorderContours
from change_img import accessBinary,accessPiexl
#记得更换命名
# 根据边框转换为MNIST格式
def transMNIST(path, borders, size=(28, 28)): #ndarry的格式:H*W*C-高度(行)*宽度(列)*频道
imgData = np.zeros((len(borders), size[0], size[0], 1), dtype='uint8') #大小为四维全0矩阵(10,28,28,1),10是10个矩形框--裁剪出的10个图片,待会将调整好的图片存入此矩阵
img = cv2.imread(path, cv2.IMREAD_GRAYSCALE) #灰度
img = accessBinary(img) #二值化
for i, border in enumerate(borders): #enumerate--返回索引和列表内容
borderImg = img[border[0][1]:border[1][1], border[0][0]:border[1][0]] #border = [(x, y), (x + w, y + h)],裁剪出矩形框框中的图像,img[数字顶行:数字末行,**首列:**尾列],相当于两横两竖四条线选中某个矩形图像
# 根据最大边缘拓展像素
extendPiexl = (max(borderImg.shape) - min(borderImg.shape)) // 2
targetImg = cv2.copyMakeBorder(borderImg, 7, 7, extendPiexl + 7, extendPiexl + 7, cv2.BORDER_CONSTANT)
#拓展图像,不让手写数字贴着矩形框边沿,使图像更美观,识别更精准
#cv2.BORDER_CONSTANT=0,向外拓展黑色像素
#参数说明:
# src:要处理的原图
# top, bottom, left, right:向上、下、左、右要扩展的像素数
# borderType:边框类型
# BORDER_CONSTANT:常量法,常数值填充
targetImg = cv2.resize(targetImg, size) #拓展完之后,将图像统一缩放至28*28
targetImg = np.expand_dims(targetImg, axis=-1) #扩展维度,-1代表在末尾维度增加一个1--变成(28,28,1)
imgData[i] = targetImg #imgData-(10,28,28,1),imgData[0]-相当于在第一个位置放入第一张图片(28,28,1),即(1,28,28,1)不再是0,是截取的第一张图像数据
return imgData #返回10张图片的四维矩阵数据--(10,28,28,1)测试函数效果的代码:
path = 'D:/beijing/writer_number.jpg'
borders = findBorderContours(path)
imgData = transMNIST(path, borders)
print(imgData.shape) #打印截取出图像的形状
print(imgData[0].shape) #单张图像的形状结果如下:
(10, 28, 28, 1)
(28, 28, 1)在这里,我想强调以下10张图片imgData的格式--(10, 28, 28, 1),我在注释中已经说过opencv打开图像的像素矩阵是ndarray类型的-H*W*C-高度(行)*宽度(列)*频道-(28, 28, 1),10是图片张数,而在后续,将这些图像传入神经网络(基于Pytorch)进行识别需要将ndarray类型转换成tensor类型,而tensor类型是C*H*W的格式-(1, 28, 28)。
还有,这里我也曾想过直接将矩形框选中的数字图像截取下来,不进行上下左右拓展,先转换成tensor类型(transforms模块),再利用Resize缩放28*28后,传入神经网络进行识别,但效果没有拓展的好,因为有一个数字识别的结果发生了错误,因为图像扭曲的有些厉害,被神经网络识别成了其他数字,可看下图:
 没有拓展的矩形框图像
没有拓展的矩形框图像  进行拓展的图像
进行拓展的图像
 没有拓展的识别结果
没有拓展的识别结果  经过拓展后的识别结果
经过拓展后的识别结果
以上就是图像进行一系列预处理的过程,我也是参考了其他博客文章学来的,原文传送:
https://blog.csdn.net/qq8993174/article/details/89081859
二.VGG16神经网络识别过程
上文对图像的一系列预处理,可以看成调整成自己mnist数据集的过程,接下来就是对自己调整的数据集进行识别了。
在此说明一下,下文并没有利用VGG16进行训练数据集的过程,我直接拿我训练好的VGG16参数模型,传入神经网络中进行识别。
下面,让我们看看我稍微调整的VGG16网络模型:
import torch
from torch import nn
from torch.nn import ReLU, Conv2d, MaxPool2d, AdaptiveAvgPool2d, \
Flatten, Linear, Dropout
class Vgg16_Model(nn.Module):
"""
构建VGG16神经网络
"""
def __init__(self):
super(Vgg16_Model, self).__init__()
self.model = nn.Sequential(
Conv2d(1, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
ReLU(inplace=True),
Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),
Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
ReLU(inplace=True),
Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),
Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
ReLU(inplace=True),
Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
ReLU(inplace=True),
Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),
Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
ReLU(inplace=True),
Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
ReLU(inplace=True),
Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),
Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
ReLU(inplace=True),
# Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
# ReLU(inplace=True),
# Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
# ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),
Flatten(),
Linear(in_features=2048, out_features=512, bias=True),
ReLU(inplace=True),
Dropout(p=0.5, inplace=False),
Linear(in_features=512, out_features=256, bias=True),
ReLU(inplace=True),
Dropout(p=0.5, inplace=False),
Linear(in_features=256, out_features=10, bias=True),
)
def forward(self, x):
x = self.model(x)
return x
if __name__ == "__main__":
x = torch.rand(16, 1, 64, 64)
model = Vgg16_Model()
y = model(x)
print(y)
print(y.shape)
print(model.model)需要说明的是,我将VGG16最后的卷积层去掉了两层,并修改了全连接层的神经元参数,因为mnist数据集是28*28的,那怕在下文我将处理好的矩形框数字图像从28*28扩大成64*64,对于网络层数很深的VGG16来说,所输入的图像特征太少了,这样的话,对于神经网络来说容易产生过拟合(就是这个网络想分的很细很细,但是输入的图像特征太少,根本分不了那么细),所以需要减少神经网络的层数--相当于减少神经网络的训练参数,加大数据集样本的数量,以期获得精度不错的识别成功率。
进行识别的代码:
import torch
import cv2
import numpy as np
from net import Vgg16_Model
from torchvision import datasets, transforms
from torch.utils.tensorboard import SummaryWriter
from change_img import accessBinary,accessPiexl
from scan_border import findBorderContours,showResults
from padding_piexl import transMNIST
#记得重命名
transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Resize([64,64]), #将28*28扩大成64*64,因为28太小了
])
# 将网络模型传入到GPU中
model = Vgg16_Model()
model = model.cuda() #将模型传入GPU执行,没有GPU直接删掉此行,默认CPU执行
#将最好的模型载入
model.load_state_dict(torch.load("D:/learn_pytorch/learning/save_model/best_model.pth")) #将训练好的参数传入
classes=["0","1","2","3","4","5","6","7","8","9"] #结果或者说是标签,根据神经网络输出的最大值的索引来找到所识别的数字
path = 'D:/beijing/writer_number.jpg'
borders = findBorderContours(path) #找到所有数字的边框
imgs = transMNIST(path, borders) #ndarry,输出--(10,28,28,1)
results = [] #存储最后得到的结果,或者说是要显示在原图上的数字
writer = SummaryWriter("logs") #根据tensorboard模块功能,显示tensor类型的图片,可视化,也可将tensor类型转换成PIL或ndarry类型调用相应函数显示
for i, img in enumerate(imgs):
img = transforms(img) #将ndarray转化成tensor类型并放大成64*64,(28,28,1)-->(1,28,28)-->(1,64,64)
writer.add_image("test", img, i+1) #tensorboard模块功能可视化
img = torch.reshape(img, (1, 1, 64, 64)) #model传入的必须是4维的,因为训练的时候是传入(512,1,28,28),所以一张图片必须重塑成四维(1,64,64)->(1, 1, 64, 64)
img = img.cuda() #传入GPU执行,没有GPU这行直接删掉,默认用CPU执行
#这是一张图片,标签是一个整型,无法传入GPU,但是这是已经验证好的模型,不用反向传播
#不用反向传播,自然不用传入label
model.eval()
with torch.no_grad():
output = model(img)
predict = classes[output.argmax(1)] #按行,提取出这行最大值的索引值,根据索引值找到相应的标签
print("predict -> "+predict)
results.append(predict)
writer.close() #tensorboard模块功能可视化,必须要进行结束
print(results)
showResults(path, borders, results=results) #在原图上显示矩形框,并显示神经网络预测的结果输出的结果如下所示:
predict -> 2
predict -> 0
predict -> 3
predict -> 1
predict -> 4
predict -> 8
predict -> 7
predict -> 9
predict -> 5
predict -> 6
['2', '0', '3', '1', '4', '8', '7', '9', '5', '6'] 最后的显示图像
最后的显示图像
tensorboard可视化模块--需要利用cmd等命令行进行打开,这里就不一一细说了,看图:





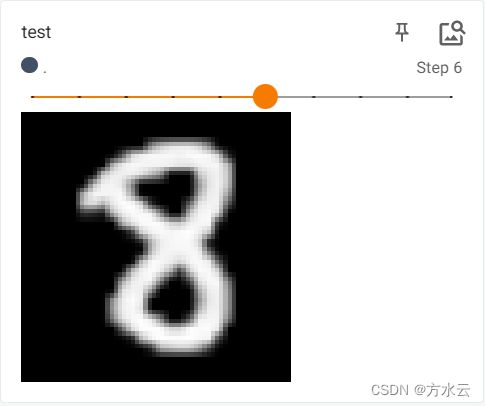





最后的最后,没了,终于结束了,好长啊!如果看文章过程有什么疑问以及需要我训练好的网络参数模型的话,可以评论区留言哟!如果像VGG16具体的训练过程和tensorboard模块功能使用等疑问,很多人有不懂的话,我会在下期或下下期出文进行具体的讲解!好啦,bye~~!