Spring之循环依赖底层源码解析(一)
Spring之循环依赖底层源码解析
- 什么是循环依赖
- 回顾Bean的生命周期
- 分析循环依赖的生成
- 剖析解决循环依赖的演化
- 解决无AOP环境下的循环依赖
- 解决AOP环境下代理对象赋值的问题
- 为什么需要三级缓存
什么是循环依赖

// A依赖了B
class A{
public B b;
}
// B依赖了A
class B{
public A a;
}
循环依赖就是A对象依赖了B对象,B对象依赖了A对象
循环依赖在Spring中就是一个问题,为什么呢?
因为,在Spring中,一个对象并不是简单new就出来了,而是会经历一系列Bean的生命周期,就是因为Bean的生命周期所以才会出现循环依赖的问题.
当然,在Spring中,出现循环依赖的场景很多,有的场景Spring自动帮我们解决了,而有的场景需要我们自己去结局
回顾Bean的生命周期
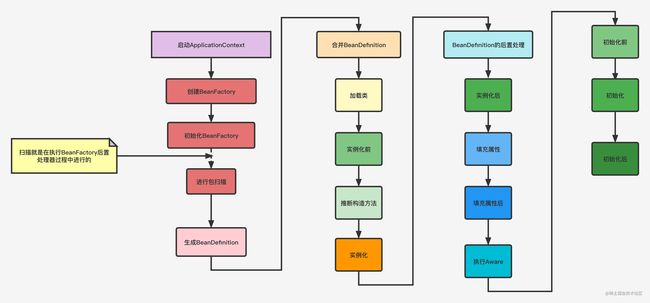
-
启动容器ApplicationContext
-
创建BeanFactory
-
初始化BeanFactory
-
BeanFactory后置处理
-
进行相关包扫描
-
首先通过ResourcePatternResolver获得指定路径下所有.class文件,并且封装成Resource对象
-
遍历每个Resource对象,利用MetadataReaderFactory解析Resource对象得到对应的MetadataReader,这样就可以从其中得到对应的类元数据信息,比如注解信息,接口信息等,底层采用的是ASM字节码技术
-
通过MetadataReader进行includeFilters和excludeFilters的处理,以及对应条件注解@Conditional的match条件匹配,对于加了@Component注解的类,默认属于includeFilter,如果@Conditional注解所指定类的match方法匹配成功,就属于includeFilter,否则就excludeFilte
-
在includeFilters中的,也就是匹配都成功的,就会生成ScannedGenericBeanDefinition
-
基于MetadataReader去判断对应的类是否是独立的类
- 如果不是独立的类比如说是一个普通的内部类,就不能成为Bean
- 如果是顶级类或者静态内部类,就是独立的
- 如果是接口或者抽象类,就不能成为Bean
- 如果是抽象类,但是有包含了@Lookup注解的方法,也就是说定义了FactoryBean,就是一个独立的类
-
如果筛选通过,那么就表示扫描到了一个Bean,将ScannedGenericBeanDefinition加入到Set集合中
-
-
-
生成BeanDefinition
- 在包扫描结束之后,就已经将生成的BeanDefinition放到了candidates的set集合中
-
合并BeanDefinition
- 通过扫描得到的所有BeanDefinition之后,就可以根据BeanDefinition创建Bean对象了,但是在Spring中支持父子BeanDefinition,所以如果继承了父BeanDefinition,子BeanDefinition就会把父中有的子中没有的一些属性给子并且重新生成一个BeanDefition,也就是RootBeanDefinition
-
加载类
- BeanDefinition合并之后,就可以去创建Bean对象了,而创建Bean对象就需要实例化对象,而实例化对象,就需要加载当前BeanDefinition对应的类,而加载类就需要对应的类加载器
- 这里如果beanClass类型是Class那么就直接返回,否则就会根据类名进行加载
-
实例化前
- InstantiationAwareBeanPostProcessor#postProcessorBeforeInstantation
- 需要注意的是如果实现了这个扩展点,就会返回一个对象,那么后续Spring的依赖注入也就不会进行了,会跳过一些步骤,直接进行初始化这一步
-
实例化
- 首先判断BeanDefinition是否设置了Supplier,如果设置了就会调用Supplier#get得到对象
- 对于创建对象有两种方式,第一种是通过factoryMethod,另外一种就是FactoryBean,其实@Bean就是一种factoryBean的创建方式,如果@Bean对应的方法是static那么对应的就是factoryMethod
-
推断构造方法
-
determineCandidateConstructors
-
Spring在基于某个类生成的Bean的过程中,需要利用这个类的构造方法进行实例化得到一个对象,但是如果一个类中存在多个构造方法,Spring就会按照以下逻辑进行判断
-
如果一个类只存在一个构造方法,不管这个构造方法是无参构造还是有参构造,Spring都会去使用这个构造方法
-
如果一个类中存在多个构造方法
- 这些构造方法中,存在一个无参构造方法,那么Spring就会使用这个无参构造方法
- 这些构造方法中,不存在无参构造方法,那么Spring就会报错
-
-
对于Spring的设计思想是这样的
-
如果一个类只有一个构造方法,那么就没有选择,只能使用这个构造方法
-
如果一个类中存在多个构造方法,Spring就不知道去选择哪一个,就会看是否有无参构造方法,因为无参构造方法本身就表示了一种默认的意义
-
如何某个构造方法上加了@Autowired注解,那就表示程序员告诉Spring我采用了这个构造方法来进行构造,如果Spring选择了一个有参构造方法,Spring在调用这个有参构造方法的时候,需要传入参数,那么Spring会根据入参的类型和入参的名字去Spring容器中找Bean对象,我们可以以单例为例子,Spring会从单例池singletonObjects中去找bean对象
- 先根据入参类型去找,如果找到了一个,那么就直接用来作为入参
- 如果根据入参类型找到了多个,那么就会再根据入参名字去确定唯一的一个
- 最终如果没有知道就会报错,无法创建Bean对象
-
-
对于推断构造方法中除了会去选择构造方法以及查找入参对象以外,还会去判断是否存在对应的类中存在使用@Lookup注解,如果存在就会把这个方法封装成LookupOverride对象并且添加到BeanDefinition当中
-
-
BeanDefinition的后置处理
- Bean对象实例化出来之后,接下来就会给对象进行赋值了,在真正给对象赋值之前,Spring提供了一个扩展点MergedBeanDefinitionPostProcessor#postProcessMergedBeanDefinition,可以在此时的BeanDefinition进行加工.
-
实例化后
- 在处理完BeanDefinition之后,Spring提供了一个扩展点InstantationAwareBeanPostProcessor#postProcessAfterInstantation
-
自动注入
- Spring的自动注入
-
填充属性
- 在这个步骤中,就会进行处理@Autowired、@Resource、@Value等注解
- 这里是通过InstantationAwareBeanPostProcessor#postProcessProperties实现的,在这里我们可以自定义实现注入逻辑
-
执行Aware回调接口
- 完成填充属性之后,Spring会执行一些回调接口,比如BeanNameAware、BeanClassLoaderAware、BeanFactoryAware等,这些会回传对应的信息给程序员
-
初始化前
- 初始化前也是Spring提供的一个扩展点BeanPostProcessor#postProcessBeforeInitialization
- 利用初始化之前,可以对进行了依赖注入的Bean进行处理
- 在Spring源码InitDestroyAnnotationBeanPostProcessor会在初始化前这个步骤执行@PostConstruct的方法
- ApplicationContextAwareProcessor会在初始化前执行其他Aware回调接口,比如EnvirnmentAware等
-
初始化
- 查看当前Bean对象是否实现了InitializationBean#afterPropertiesSet接口了,如果实现了就会调用afterPropertiesSet方法
- 执行BeanDefinition中指定的初始化方法
-
初始化后
- Spring扩展点BeanPostProcessor#postProcessAfterInitialization
- 可以在这个步骤中,对Bean最终进行处理,Spring中的AOP就是基于初始化后进行实现的,初始化后返回的对象才是最终的Bean对象
分析循环依赖的生成
可以看到,对于Spring中的Bean的生成过程,步骤还是很多的,在Spring中,构造一个Bean,包括new这个步骤,通过反射进行构造得到一个原始对象后,Spring需要给对象中的属性进行依赖注入,那么注入过程是怎样的?
比如上面说的A类,A类中存在一个B类的b属性,所以在A类生成了一个原始对象之后,就会去给b属性进行赋值,此时就会根据b属性的类型和属性名去BeanFactory中去获取B类所对应的单例Bean.
如果此时BeanFactory中存在B对应的Bean,那么就直接拿来赋值给b属性
如果此时BeanFactory中不存在B对应的Bean,就需要生成一个B对应的Bean,然后赋值给b属性
问题出现在在BeanFactory中找不到B对应的Bean,如果此时B类在BeanFactory中还没有生成对应的Bean,那么就需要去生成,就会经历B的Bean生命周期
那么在创建B类的Bean的过程中,如果B类中存在一个A类的a属性,那么在创建B的Bean的过程中就需要A类对应的Bean,但是,触发B类Bean的创建条件是A类Bean在创建过程中的依赖注入,所以这里就出现了循环依赖
我们可以看下图
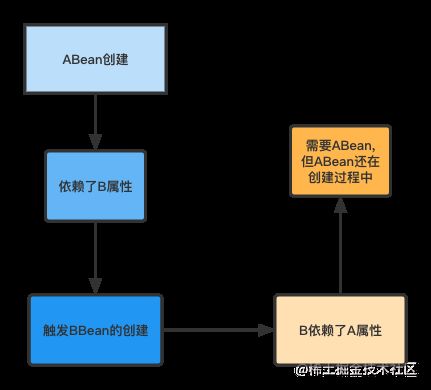
ABean创建->依赖了B属性->触发BBean的创建->B依赖了A属性->需要ABean但ABean还在创建过程中
从而导致ABean创建不出来,BBean也创建不出来
这是循环依赖的场景,但是前面说了,通过某些机制帮助开发者解决了部分循环依赖的问题,这个机制就是三级缓存
剖析解决循环依赖的演化
@Component
class AService{
@Autowired
public BService bService;
}
@Component
class BService{
@Autowired
public AService aService;
}
解决无AOP环境下的循环依赖
详细链接: https://www.processon.com/view/link/626115f1e0b34d072168e7b8

对于在没有AOP环境下的循环依赖我们可以怎么去解决呢
很简单,可以通过一个Map去缓存,正在创建的Bean对象可以从这个Map中找到对应的依赖项,当两个都创建好了,自然而然依赖的Bean也随着有值了
我们可以看下面的流程
- 先创建AService
- 实例化AService
- 得到AService对象
- 将对象放入Map中缓存,Map
- 填充属性
- 填充BService属性,发现单例池中没有找到BService的属性,就开始走BService的生命周期
- 创建BService
- 实例化BService
- 得到BService对象
- 将对象放入Map中缓存Map
- 填充属性
- 填充AService属性,发现单例池中没有找到BService的属性,去Map缓存中找到AService的原始对象,将它赋值到AService属性
- 初始化前
- 初始化
- 初始化后
- 将ASevice放入单例池
- 填充BService属性,发现单例池中没有找到BService的属性,就开始走BService的生命周期
- AService中创建好的BService赋值给BService属性
- 初始化前
- 初始化
- 初始化后
- 将BSevice放入单例池
解决AOP环境下代理对象赋值的问题
在没有AOP的场景下我们赋值给BService的属性是AService的原始对象,但是在这里依旧是赋值AService的原始对象而不是代理对象,该如何去解决呢?
详细链接: https://www.processon.com/view/link/62611c60e401fd32a56a8395

很简单,我们可以提前进行AOP,将AOP后得到的代理对象放到我们的Map缓存中
我们可以看下面的流程
- 先创建AService
- 实例化AService
- 得到AService对象
- 提前进行AOP
- 得到AService的代理对象
- 将AService的代理对象放入Map缓存中,Map
- 填充属性
- 填充BService属性,发现单例池中没有找到BService的属性,就开始走BService的生命周期
- 创建BService
- 实例化BService
- 得到BService对象
- 将对象放入Map中缓存,Map
- 填充属性
- 填充AService属性,发现单例池中没有找到AService属性,在Map缓存中找到AService的代理对象,将它赋值给AService属性
- 初始化前
- 初始化
- 初始化后
- 将BSevice放入单例池
- 填充BService属性,发现单例池中没有找到BService的属性,就开始走BService的生命周期
- AService中创建好的BService赋值给BService属性
- 初始化前
- 初始化
- 初始化后
- 将AService的代理对象放入单例池
为什么需要三级缓存
上面明明已经解决了循环依赖的问题了,为啥Spring需要三级缓存来解决呢
因为按照Bean的生命周期,AOP是在初始化后进行的,但是我们前面以前进行了AOP,不符合设计
但是如果要考虑到AOP,要解决循环依赖,我们就得提前进行AOP,如果不提前,赋值给BService的不会是AService的代理对象
那我们该如何判断AService出现了循环依赖呢
详细链接: https://www.processon.com/view/link/626122ace0b34d0721693e79

对于Spring的处理,就有点复杂了
我们可以看下面的大致流程
-
先创建AService
-
记录下AService正在创建中,也就是将AService放入singletonsCurrentlyInCreation中
-
实例化AService
-
得到AService对象
-
将AService的相关beanName,BeanDefinition,AService的原始对象生成一个ObjectFactory存入三级缓存sigletonFactories中,singletonFacories
Aservice:()->(beanName,mbd,AService) -
填充属性
-
填充BService属性,发现单例池singletonObjects中没有找到BService,就开始走BService的生命周期
- 创建BService
- 记录BService正在创建中,也就是将BService放入singletonsCurrentlyInCreation中
- 实例化BService
- 得到BService对象
- 将BService的相关beanName,BeanDefinition,BService的原始对象生成一个ObjectFactory存入三级缓存sigletonFactories中
Bservice:()->(beanName,mbd,BService)- 填充属性
- 填充AService属性,发现单例池singletonObjects中没有找到AService,判断singletonsCurrentlyInCreation中有没有AService,如果有就代表AService正在创建中,也就代表出现了循环依赖
- 对于出现了循环依赖的还会存放在earlyProxyReferences里,后续在AService初始化后会再次进行判断是否进行过AOP,没有就会去进行
- 从二级缓存earlySingletonObjects中找,如果没有找到就从三级缓存singletonFactories中找
- 判断是否需要进行AOP
- 如果需要进行AOP,就提前进行AOP
- 判断AService的代理对象在不在二级缓存earySingletonObjects中
- 不在二级缓存中
- ObjectFactory生成AService的代理对象
- 放入二级缓存earlySingletonObjects,假如后续出现了CService创建时,也跟AService出现了循环依赖,不应该再去创建一个代理对象,因为AService是单例的,所以这个缓存就有用了
- 将三级缓存中AService代理对象移除,这样是为了减少bug的出现: 比如出现再次执行ObjectFactory就不好了
- 在二级缓存中就直接拿出来
- 不在二级缓存中
- 将AService的代理对象赋值给属性AService
- 判断AService的代理对象在不在二级缓存earySingletonObjects中
- 如果不需要进行AOP
- 从三级缓存singletonFactories拿出ObjectFactory获取AService原始对象,将AService的原始对象放入二级缓存earlySingletonObjects中
- 从三级缓存singletonFactories缓存拿到AService的原始对象,赋值给属性AService
- 如果需要进行AOP,就提前进行AOP
- 判断是否需要进行AOP
- 初始化前
- 初始化
- 初始化后
- 将BService放入单例池
-
-
将BService对象的值赋值给属性BService
-
初始化前
-
初始化
-
初始化后
-
判断有没有进行过AOP,也就是earlyProxyReferences有没有这个bean
- 进行过,从二级缓存earlySingletonObjects拿出AService的代理对象,代理对象放入单例池
- 没有进行过AOP,进行AOP