Kubernetes中的Calico网络
文章目录
- 1 介绍
- 2 环境部署
-
- 3 IPIP模式
-
- 3.1 测试环境
- 3.2 ping包网络转发
- 4 BGP模式
-
- 4.1 测试环境
- 4.2 ping网络转发
- 5 两种模式对比
1 介绍
Calico网络的大概思路,即不走Overlay网络,不引入另外的网络性能损耗,而是将转发全部用三层网络的路由转发来实现。
下边实践一下Calico网络的两种模式:
- IPIP:就是对IP的封装,通过tunnel的方式,进行路由转发
- BGP:直接
2 环境部署
在Kuberntes环境里部署calico网络,下载calico.yaml
安装脚本如下:
#!/bin/bash
#
# wget https://projectcalico.docs.tigera.io/manifests/calico.yaml
# preload cni calico
docker pull calico/cni:v3.23.1
docker pull calico/node:v3.23.1
docker pull calico/kube-controllers:v3.23.1
kubectl apply -f calico.yaml

3 IPIP模式
3.1 测试环境
为了模拟两个POD跨node通信,我们创建两个pod,分别部署在master和node节点。下边以两个nginx的pod为例:
在master节点上部署:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-master-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
nodeSelector:
kubernetes.io/hostname: baihl-master
containers:
- name: nginx
image: nginx:alpine
ports:
- containerPort: 80
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
operator: Exists
Pod中增加容忍master节点的node-role.kubernetes.io/master:NoSchedule 污点,否则Pod无法在master节点上运行。
node节点上也部署一下nginx,记得把tolerations删掉。
查看两个pod的执行情况:

两个pod分别运行在mster和node节点上,ip地址分别为10.10.40.129和10.10.194.134。
在master节点上的pod1中执行ping node节点的pod2:

网络互通性没有问题。
3.2 ping包网络转发
在master节点上的pod1怎么ping通的node节点上的pod2,分析整个网络转发过程,可以从头开始看,先看ping是怎么从pod1中出去的,在pod1中查看路由信息:

根据路由表信息,ping 10.10.194.134,应该匹配到第一条路由,去往任何网络都先到网关169.254.1.1,从eth0网卡出去。
然后我们看下master节点上的路由信息:

当数据包到达master节点时,会匹配到红色框住的路由,去往10.10.194.192/26网段的数据包,都走到tunl0上,并且网关是192.168.170.138(node节点IP)。所以数据包就通过tunl0到达了node节点。
数据包到达了node节点,看下node节点的路由信息:

数据包到达node节点后会匹配上上边红线框的路由,到达10.10.194.134的数据包都走calie1e27109044。
calie1e27109044是veth pair的一端,另一端就是10.10.194.134的pod2,可以验证下,在pod2中使用ethtool命令查看:
![]()
在pod2中执行ethtool命令报错,原因应该是pod中没有此命令,或者执行权限不够。下边使用nsenter命令实现在主机上调试容器。步骤如下:
- 首先获取pod所在容器的id

- 根据容器ID,查看容器进程

注意:因为容器是运行在node节点上的,要在node节点上执行以上命令,可以看到获取到的PID为535135。
- 使用nsenter命令进入进程的名字空间
root@baihl-node:/home/baihl# nsenter -t 535135 -n
root@baihl-node:/home/baihl# ethtool -S eth0
NIC statistics:
peer_ifindex: 71
可以看到,pod2中eth0网卡的另一端设备号是71,在node节点上查看编号为71的网卡就是calie1e27109044:

到此为止,在node上的路由表明,发送到calie1e27109044的数据其实就是发送到pod2网卡中,ping包就到达了目的地。
下边是整个网络的结构图:
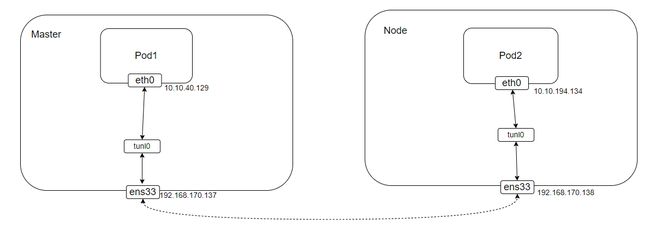
在master节点进行抓包分析,ping的数据包:

打开上边的一个ICMP包,可以看到数据包有5层,其中有两个IP层,分别是pod之间的网络和主机之间的网络封装。
4 BGP模式
4.1 测试环境
在安装calico网络时,默认安装是IPIP网络。calico.yaml文件中,将CALICO_IPV4POOL_IPIP的值修改成 “off”,就能够替换成BGP网络。
- name: CALICO_IPV4POOL_IPIP
value: "off"
修改完成后重新部署。
使用BGP模式后,首先变化是节点上不再有tunl0设备:

同样重新在master和node节点部署两个pod。如下:

两个pod的ip地址分别为10.10.40.129和10.10.194.128。
同样的操作在pod1 10.10.40.129中ping pod2的10.10.194.128:

4.2 ping网络转发
pod1中ping pod2首先pod1中的路由表:

根据pod1中的路由信息,ping包通过eth0网卡到master节点。master节点上根据路由信息,到10.10.194.128的数据包匹配到下边红框中的路由,直接发送到了192.168.170.138(node节点),从ens33网卡出去。

node节点上的路由信息如下:

ping包到达node节点,匹配上红框中的路由信息,直接发送到了pod2的veth pair的一端,数据就直接到了pod2的网卡。
如果ping包回应pod1的 10.10.40.129,则在node节点上匹配到:

直接到达了master节点192.168.170.137,后边的流程不再赘述。
同样下表在master上抓包看一下:

通过上边的流程发现,BGP的模式不再基于IPIP进行封装,也没有了tunl0设备做转发,而是通过路由表,直接转到了节点的网卡上转发出去。
BGP模式下的整个网络的结构图:

5 两种模式对比
IPIP网络:需要tunl0设备封装数据,形成隧道,承载流量,需要tunl0设备封装效率略低。
BGP模式:使用路由引导流量转发,比IPIP效率更高。
本文参考:https://www.cnblogs.com/goldsunshine/p/10701242.html