Python 数据文件与网络数据序列化存储详解
1、ETL简介
大部分可用数据都是存放于文本文件中的。这些数据可以是非结构化文本(如一篇推文或文学作品),也可以是比较结构化的数据,其每一行都是一条记录,多个字段之间由特殊字符分隔,如逗号、制表符或管道符号“|”。
文本文件有可能会很大,一个数据集可能会分布在几十甚至几百个文件中,其中的数据可能并不完整或充斥大量脏数据(dirty data)。虽然存在这么多变数,但还是会有读取和使用文本文件数据的需求,这几乎是难以避免的。
只要有数据文件存在,就需要从文件中获取、解析数据并转换为有用的格式,然后执行某些操作。实际上,该过程有一个标准术语,就是“抽取-转换-加载”(extract-transform-load,ETL)。
抽取是指按需读取数据源并解析数据源的处理过程。转换则是清洗和规格化(normalize)数据,还有组合、分解或重组其内部记录。加载是指将转换后的数据存入新位置,可以是另一个文件,也可以是数据库。
2、文本文件读取
ETL的第一部分是“抽取”,这涉及文件的打开和内容读取操作。这一过程看起来很简单,但即便是这么一个简单的过程也会碰到困难,如文件大小问题。如果文件太大而无法放入内存进行操作,那就需要精心构建代码,每次只处理一小段文件,有可能是每次操作一行数据。
1. 文本编码:ASCII、Unicode等
另一个可能的陷阱就是字符的编码,事实上现实世界中大部分交换的数据都在文本文件中。但是,不同的应用程序之间,不同人之间,当然还有不同国家之间,文本的准确含义都可能不一样。
有时候,文本表示ASCII编码的字符,ASCII码包含128个字符,其中只有95个是可打印的。关于ASCII编码的好消息是,它是大多数数据交换操作的最小公分母。坏消息是,世界上存在众多的字母表和书写系统,ASCII编码没有着手对其复杂性进行处理。如果用ASCII编码读取文件,几乎一定会惹出麻烦,碰到无法理解的字符值就会引发错误。可能是德语ü,也可能是葡萄牙语ç,或者除英语外的几乎其他所有语言。
出现错误的原因,就是因为ASCII是基于7位的。而典型文件中的字节都是8位,允许256种可能的数值,而不是7位的128种可能。通常这些多出来的值是用来存放额外的字符,包括额外的标点(如打印机上的短划线和长划线)、额外的符号(如商标、版权和角度符号)、带重音符号的字母等。
在读取文本文件时,如果遇到字符是属于ASCII范围外的128个值,那它的编码是无法确定的,这个问题会永远存在。例如,字符值是214,那它是除号、Ö还是别的什么字符呢?如果缺少创建该文件的代码,根本就无从知晓。
有一种方案可以减少上述混乱,那就是Unicode。名为UTF-8的Unicode编码,不但无须修改即可接受基础的ASCII字符,而且还允许接受近乎无限的其他字符和符号集,只要符合Unicode标准即可。正因为其灵活性,UTF-8已在超过85%的网页中使用。
这就意味着,读取文本文件时最好假设其采用的是UTF-8编码。如果文件仅包含ASCII字符,依旧可正确读取,如果还有其他字符是以UTF-8编码的,也能够正常读取。Python 3的字符串类型,默认就设计为可处理Unicode的,这真是个好消息。
即便是采用了Unicode编码,有时候文本中还是会包含无法成功编码的字符值。幸运的是,Python的open函数可以接受一个可选参数errors,该参数决定了函数在读写文件时该如何处理编码错误。默认选项是'strict',这样在遇到编码错误时将会引发错误。
还有其他几个比较有用的选项,例如,'ignore'会使得引发错误的字符被跳过,'replace'会使出错字符被替换为标记字符(通常是?),'backslashreplace'会用反斜杠转义序列替换字符,而'surrogateescape'在读取时会把异常字符转换为专用的Unicode码点(code point),并在写入时将其转换回原来的字节序列。到底需要采取多么严格的处理方式或编码方案,取决于特定的使用场景了。
以下是一个简短的文件示例,其中包含一个无效的UTF-8字符,不妨来看下不同的选项分别是如何对其进行处理的。
首先,用字节和二进制模式写入文件:
>>> open('test.txt', 'wb').write(bytes([65, 66, 67, 255, 192,193]))上述代码会生成一个文件,里面包含了“ABC”和3个非ASCII字符。根据所用的编码不同,这些非ASCII字符可能会表达成不同的字符。
如果用vim查看该文件,将会看到如下内容:
ABCÿÀÁ
~现在文本文件有了,不妨尝试用默认的错误处理选项'strict'来读一下文件:
>>> x = open('test.txt').read()
Traceback (most recent call last):
File "", line 1, in
File "/usr/local/lib/python3.6/codecs.py", line 321, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 3:
invalid start byte 第四个字节的值为255,它在这个位置不是合法的UTF-8字符,因此'strict'的错误处理参数将会引发异常。下面看看其他错误处理选项会如何处理这个文件,请记住最后3个字符将会引发错误:
>>> open('test.txt', errors='ignore').read()
'ABC'
>>> open('test.txt', errors='replace').read()
'ABC���'
>>> open('test.txt', errors='surrogateescape').read()
'ABC\udcff\udcc0\udcc1'
>>> open('test.txt', errors='backslashreplace').read()
'ABC\\xff\\xc0\\xc1'
>>>如果想让有问题的字符不要出现,可以使用'ignore'选项。'replace'选项只会把无效字符的位置标记出来,其他选项则会尝试以各种方式将无效字符不加解释地保留下来。
2. 非结构化文本
非结构化文本文件是最容易读取的数据类型,但从中抽取信息也是最难的。不同的非结构化文本处理方式,可能会存在很大差异,具体取决于文本的特性和要用到的内容。这里可以用一个简短的例子演示一些基础性的问题,并为结构化文本数据文件的讨论奠定基础。
最简单的一个问题,是要确定文件中基本逻辑单位的格式。如果面对的是一本新闻报道集,就需要能把它们分解成多个自成一体(cohesive)的单位。
许多时候,也许不会把每篇小说或新闻整体视为一个数据项。但如果确实需要如此,就得确定所需的数据单位,然后提出对应的文件拆分策略。或许需要按段落来处理文本,那么就得确定文件中段落的分隔方式,并相应地创建代码。如果段落与文本文件行相一致,那工作就简单了。不过一般文本文件中的行都要短于段落,因此就需要增加一些工作量。
下面来看看一些实例:
Call me Ishmael. Some years ago--never mind how long precisely--
having little or no money in my purse, and nothing particular
to interest me on shore, I thought I would sail about a little
and see the watery part of the world. It is a way I have
of driving off the spleen and regulating the circulation.
Whenever I find myself growing grim about the mouth;
whenever it is a damp, drizzly November in my soul; whenever I
find myself involuntarily pausing before coffin warehouses,
and bringing up the rear of every funeral I meet;
and especially whenever my hypos get such an upper hand of me,
that it requires a strong moral principle to prevent me from
deliberately stepping into the street, and methodically knocking
people's hats off--then, I account it high time to get to sea
as soon as I can. This is my substitute for pistol and ball.
With a philosophical flourish Cato throws himself upon his sword;
I quietly take to the ship. There is nothing surprising in this.
If they but knew it, almost all men in their degree, some time
or other, cherish very nearly the same feelings towards
the ocean with me.
There now is your insular city of the Manhattoes, belted round by wharves
as Indian isles by coral reefs--commerce surrounds it with her surf.
Right and left, the streets take you waterward. Its extreme downtown
is the battery, where that noble mole is washed by waves, and cooled
by breezes, which a few hours previous were out of sight of land.
Look at the crowds of water-gazers there.在版面上多多少少都会有文本行被断开,并且每个段落是用一个空行标识出来的。如果要把每个段落作为一个处理单位,则需要根据空行对文本进行拆分。
幸运的是,用字符串split()方法就能轻松完成任务了。字符串中的每个换行符都可以用“\n”表示。每个段落的最后一行都以一个换行符结束,如果下一行是空行,显然紧接着就是表示空行的第二个换行符:
>>> moby_text = open("moby_01.txt").read() ⇽--- 将全部文件内容读入一个字符串
>>> moby_paragraphs = moby_text.split("\n\n") ⇽--- 按照两个连续换行符进行拆分
>>> print(moby_paragraphs[1])
There now is your insular city of the Manhattoes, belted round by wharves
as Indian isles by coral reefs--commerce surrounds it with her surf.
Right and left, the streets take you waterward. Its extreme downtown
is the battery, where that noble mole is washed by waves, and cooled
by breezes, which a few hours previous were out of sight of land.
Look at the crowds of water-gazers there.将文本拆分为段落,是处理非结构化文本时非常简单的第一步。在处理之前,可能还需要对文本进行其他的规格化(normalize)操作。
假设要统计文本文件中每个单词的出现次数。只要根据空格对文件进行拆分,就能得到文件中的单词列表。然而想要准确地统计单词的出现次数,就会比较困难,因为“This”“this”“this.”和“this,”被拆成了不同的单词。要让代码能够正常工作,解决办法就是对文本进行规格化,删除所有的标点符号,在进行处理之前让所有单词的状况都变得一致。
就以上示例文本而言,生成规格化单词列表的代码可能会如下所示:
>>> moby_text = open("moby_01.txt").read() ⇽--- 将全部文件内容读入一个字符串
>>> moby_paragraphs = moby_text.split("\n\n")
>>> moby = moby_paragraphs[1].lower() ⇽--- 全部变成小写
>>> moby = moby.replace(".", "") ⇽--- 删除句点
>>> moby = moby.replace(",", "") ⇽--- 删除逗号
>>> moby_words = moby.split()
>>> print(moby_words)
['there', 'now', 'is', 'your', 'insular', 'city', 'of', 'the', 'manhattoes,',
'belted', 'round', 'by', 'wharves', 'as', 'indian', 'isles', 'by',
'coral', 'reefs--commerce', 'surrounds', 'it', 'with', 'her', 'surf',
'right', 'and', 'left,', 'the', 'streets', 'take', 'you', 'waterward',
'its', 'extreme', 'downtown', 'is', 'the', 'battery,', 'where', 'that',
'noble', 'mole', 'is', 'washed', 'by', 'waves,', 'and', 'cooled', 'by',
'breezes,', 'which', 'a', 'few', 'hours', 'previous', 'were', 'out',
'of', 'sight', 'of', 'land', 'look', 'at', 'the', 'crowds', 'of',
'water-gazers', 'there']3. 带分隔符的普通文本文件
虽然非结构化文本文件很容易读取,但缺点是缺乏结构性。如果文件具有一定的组织结构,以便能提取出单个数据值,那往往就有用多了。最简单的方案是将文件拆分成多行,每行包含一条数据。可能是一个需要处理的文件名列表,可能是一个需要打印的人名列表(如用于打印在姓名标牌上),或者可能是远程监测设备生成的一系列温度读数。这些情况下的数据解析十分简单,仅需读取每行数据并在必要时转换为正确的类型。然后文件就可以备用了。
然而多数情况下,事情并没有这么简单。通常需要将关联的信息进行分组,然后要用代码将关联信息一起读取出来。常见做法是把关联的几条信息放在同一行,并由特殊字符分隔开。这样在逐行读取文件时,可以利用特殊字符将文件拆分为各个字段,并将字段值放入变量以供后续处理。
以下文件是带分隔符格式的简单示例,包含的是温度数据:
State|Month Day, Year Code|Avg Daily Max Air Temperature (F)|Record Count for
Daily Max Air Temp (F)
Illinois|1979/01/01|17.48|994
Illinois|1979/01/02|4.64|994
Illinois|1979/01/03|11.05|994
Illinois|1979/01/04|9.51|994
Illinois|1979/05/15|68.42|994
Illinois|1979/05/16|70.29|994
Illinois|1979/05/17|75.34|994
Illinois|1979/05/18|79.13|994
Illinois|1979/05/19|74.94|994这里的数据是以管道字符分隔的,也就是行内的每个字段都用管道字符“|”分隔。
这里给出了4个字段:观测状态、观测日期、平均最高温度、发送报告的观测站数量。其他常用的分隔符还有制表符和逗号。逗号可能是最常见的分隔符,但分隔符可以是任何不会出现在数据中的字符。逗号分隔符太常见了,以至于这种格式常被称为CSV(comma-separated values)格式。CSV类型的文件往往带有.csv扩展名,以标明其格式。
无论采用什么字符作为分隔符,只要事先知道,就可以编写Python代码,把每一行拆分为多个字段并返回为一个列表。
对于以上示例,可以用字符串split()方法将每行拆分为多个数据值组成的列表:
>>> line = "Illinois|1979/01/01|17.48|994"
>>> print(line.split("|"))
['Illinois', '1979/01/01', '17.48', '994']注意,上述技术非常简单,但所有数据值都会保存为字符串,这可能对后续的处理造成不便。
4. csv模块
如果需要对带分隔符的数据文件进行更多处理,就应该熟悉csv模块及其选项。
要问Python标准库中最喜欢什么模块,我不止一次提到了csv模块。并非因为csv模块很迷人(其实没有),而是因为它已为我节省了很多的精力,并且在职业生涯中,我依靠csv模块成功避免了很多自身的bug,这超过了其他任何模块。
csv模块是Python“功能齐备”理念的完美案例。要想读取带分隔符的文件,虽然完全有可能磕磕绊绊地自行写出代码,甚至很多情况下也不算特别困难,但采用Python模块会更加容易和可靠。csv模块已经过了测试和优化,而且已具备了很多特性。如果不得已需要自己编写,这些特性也许写起来也不太麻烦,但如果能拿来就用,就真的非常方便和省时了。
请先观察一下上述数据,再来决定如何用csv模块读取这些数据。解析数据的代码必须完成两件事:读取每一行并去除尾部的换行符;然后根据管道字符拆分每行并将数据列表添加到行列表中。解决方案可能会如下所示:
>>> results = []
>>> for line in open("temp_data_pipes_00a.txt"):
... fields = line.strip().split("|")
... results.append(fields)
...
>>> results
[['State', 'Month Day, Year Code', 'Avg Daily Max Air Temperature (F)',
'Record Count for Daily Max Air Temp (F)'], ['Illinois', '1979/01/01',
'17.48', '994'], ['Illinois', '1979/01/02', '4.64', '994'], ['Illinois',
'1979/01/03', '11.05', '994'], ['Illinois', '1979/01/04', '9.51',
'994'], ['Illinois', '1979/05/15', '68.42', '994'], ['Illinois', '1979/
05/16', '70.29', '994'], ['Illinois', '1979/05/17', '75.34', '994'],
['Illinois', '1979/05/18', '79.13', '994'], ['Illinois', '1979/05/19',
'74.94', '994']]如果用csv模块来完成同样的工作,代码可能会如下所示:
>>> import csv
>>> results = [fields for fields in
csv.reader(open("temp_data_pipes_00a.txt", newline=''), delimiter="|")]
>>> results
[['State', 'Month Day, Year Code', 'Avg Daily Max Air Temperature (F)',
'Record Count for Daily Max Air Temp (F)'], ['Illinois', '1979/01/01',
'17.48', '994'], ['Illinois', '1979/01/02', '4.64', '994'], ['Illinois',
'1979/01/03', '11.05', '994'], ['Illinois', '1979/01/04', '9.51',
'994'], ['Illinois', '1979/05/15', '68.42', '994'], ['Illinois', '1979/
05/16', '70.29', '994'], ['Illinois', '1979/05/17', '75.34', '994'],
['Illinois', '1979/05/18', '79.13', '994'], ['Illinois', '1979/05/19',
'74.94', '994']]就这个简单的例子而言,相比自己磕磕绊绊写出的代码,采用csv模块获得的收益看起来并不算多。尽管如此,代码还是缩短了两行,也更清晰了一些,而且再也无须费心剔除换行符了。当需要处理更具挑战性的案例时,真正的优势就会体现出来了。
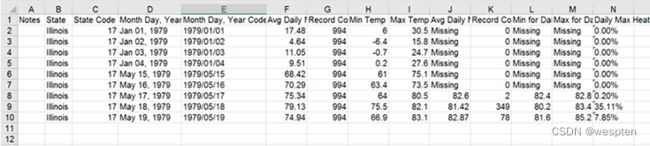
以上示例中的数据是真实的,但其实已经经过了简化和清洗。从数据源得到的真实数据会更加复杂,真实的数据中包含了更多的字段,某些字段被包在引号中而其他字段则没有,而且第一个字段为空。
原文件是以制表符分隔的,但为了便于说明,此处将以逗号分隔:
"Notes","State","State Code","Month Day, Year","Month Day, Year Code",Avg
Daily Max Air Temperature (F),Record Count for Daily Max Air Temp
(F),Min Temp for Daily Max Air Temp (F),Max Temp for Daily Max Air Temp
(F),Avg Daily Max Heat Index (F),Record Count for Daily Max Heat Index
(F),Min for Daily Max Heat Index (F),Max for Daily Max Heat Index
(F),Daily Max Heat Index (F) % Coverage
,"Illinois","17","Jan 01, 1979","1979/01/
01",17.48,994,6.00,30.50,Missing,0,Missing,Missing,0.00%
,"Illinois","17","Jan 02, 1979","1979/01/02",4.64,994,-
6.40,15.80,Missing,0,Missing,Missing,0.00%
,"Illinois","17","Jan 03, 1979","1979/01/03",11.05,994,-
0.70,24.70,Missing,0,Missing,Missing,0.00%
,"Illinois","17","Jan 04, 1979","1979/01/
04",9.51,994,0.20,27.60,Missing,0,Missing,Missing,0.00%
,"Illinois","17","May 15, 1979","1979/05/
15",68.42,994,61.00,75.10,Missing,0,Missing,Missing,0.00%
,"Illinois","17","May 16, 1979","1979/05/
16",70.29,994,63.40,73.50,Missing,0,Missing,Missing,0.00%
,"Illinois","17","May 17, 1979","1979/05/
17",75.34,994,64.00,80.50,82.60,2,82.40,82.80,0.20%
,"Illinois","17","May 18, 1979","1979/05/
18",79.13,994,75.50,82.10,81.42,349,80.20,83.40,35.11%
,"Illinois","17","May 19, 1979","1979/05/
19",74.94,994,66.90,83.10,82.87,78,81.60,85.20,7.85%注意,某些字段里也含有逗号。这时的规则是给字段加上引号,表明其中的逗号不应被解析为分隔符。如上所示,比较常见的做法是只对某些字段加引号,特别针对那些可能会包含分隔符的字段。当然,这里也会碰到一些不太可能包含分隔符的字段,也被加上了引号。
在这种情况下,自己开发的代码可能会变得比较复杂臃肿。现在再也无法根据分隔符拆分每一行了,需要保证只识别不在引号字符串内的分隔符。此外,还得删除字符串外面的引号,引号可能随时出现或者根本就不出现。有了csv模块,就完全不需要修改代码了。实际上,因为逗号是默认的分隔符,所以甚至不需要指定它:
>>> results2 = [fields for fields in csv.reader(open("temp_data_01.csv",
newline=''))]
>>> results2
[['Notes', 'State', 'State Code', 'Month Day, Year', 'Month Day, Year Code',
'Avg Daily Max Air Temperature (F)', 'Record Count for Daily Max Air
Temp (F)', 'Min Temp for Daily Max Air Temp (F)', 'Max Temp for Daily
Max Air Temp (F)', 'Avg Daily Min Air Temperature (F)', 'Record Count
for Daily Min Air Temp (F)', 'Min Temp for Daily Min Air Temp (F)', 'Max
Temp for Daily Min Air Temp (F)', 'Avg Daily Max Heat Index (F)',
'Record Count for Daily Max Heat Index (F)', 'Min for Daily Max Heat
Index (F)', 'Max for Daily Max Heat Index (F)', 'Daily Max Heat Index
(F) % Coverage'], ['', 'Illinois', '17', 'Jan 01, 1979', '1979/01/01',
'17.48', '994', '6.00', '30.50', '2.89', '994', '-13.60', '15.80',
'Missing', '0', 'Missing', 'Missing', '0.00%'], ['', 'Illinois', '17',
'Jan 02, 1979', '1979/01/02', '4.64', '994', '-6.40', '15.80', '-9.03',
'994', '-23.60', '6.60', 'Missing', '0', 'Missing', 'Missing', '0.00%'],
['', 'Illinois', '17', 'Jan 03, 1979', '1979/01/03', '11.05', '994', '-
0.70', '24.70', '-2.17', '994', '-18.30', '12.90', 'Missing', '0',
'Missing', 'Missing', '0.00%'], ['', 'Illinois', '17', 'Jan 04, 1979',
'1979/01/04', '9.51', '994', '0.20', '27.60', '-0.43', '994', '-16.30',
'16.30', 'Missing', '0', 'Missing', 'Missing', '0.00%'], ['',
'Illinois', '17', 'May 15, 1979', '1979/05/15', '68.42', '994', '61.00',
'75.10', '51.30', '994', '43.30', '57.00', 'Missing', '0', 'Missing',
'Missing', '0.00%'], ['', 'Illinois', '17', 'May 16, 1979', '1979/05/
16', '70.29', '994', '63.40', '73.50', '48.09', '994', '41.10', '53.00',
'Missing', '0', 'Missing', 'Missing', '0.00%'], ['', 'Illinois', '17',
'May 17, 1979', '1979/05/17', '75.34', '994', '64.00', '80.50', '50.84',
'994', '44.30', '55.70', '82.60', '2', '82.40', '82.80', '0.20%'], ['',
'Illinois', '17', 'May 18, 1979', '1979/05/18', '79.13', '994', '75.50',
'82.10', '55.68', '994', '50.00', '61.10', '81.42', '349', '80.20',
'83.40', '35.11%'], ['', 'Illinois', '17', 'May 19, 1979', '1979/05/19',
'74.94', '994', '66.90', '83.10', '58.59', '994', '50.90', '63.20',
'82.87', '78', '81.60', '85.20', '7.85%']]注意,这里多余的引号都已删除,并且带逗号的字段值都予以完整保留,而且没有任何多余的字符。
5. 读取csv文件并存为字典的列表
在以上示例中,每行数据是作为字段的列表返回的。这种结果在很多情况下都能胜任,但有时候把每行作为字典返回会更方便,这里可用字段名称作为字典的键。
对于这种场景,csv库提供了DictReader对象,可以将字段列表作为参数,也可以从数据文件的第一行读取字段名称。如果要用DictReader打开数据文件,代码将如下所示:
>>> results = [fields for fields in csv.DictReader(open("temp_data_01.csv",
newline=''))]
>>> results[0]
OrderedDict([('Notes', ''), ('State', 'Illinois'), ('State Code', '17'),
('Month Day, Year', 'Jan 01, 1979'), ('Month Day, Year Code', '1979/01/
01'), ('Avg Daily Max Air Temperature (F)', '17.48'), ('Record Count for
Daily Max Air Temp (F)', '994'), ('Min Temp for Daily Max Air Temp (F)',
'6.00'), ('Max Temp for Daily Max Air Temp (F)', '30.50'), ('Avg Daily
Min Air Temperature (F)', '2.89'), ('Record Count for Daily Min Air Temp
(F)', '994'), ('Min Temp for Daily Min Air Temp (F)', '-13.60'), ('Max
Temp for Daily Min Air Temp (F)', '15.80'), ('Avg Daily Max Heat Index
(F)', 'Missing'), ('Record Count for Daily Max Heat Index (F)', '0'),
('Min for Daily Max Heat Index (F)', 'Missing'), ('Max for Daily Max Heat Index (F)',
'Missing'), ('Daily Max Heat Index (F) % Coverage', '0.00%')])注意,csv.DictReader返回的是OrderedDicts对象,因此各个字段仍然会保持原有的顺序。尽管各字段看起来稍有区别,但行为还是像字典一样。
>>> results[0]['State']
'Illinois'如果数据特别复杂,并且需要对指定字段进行操作,那么DictReader更易于确保读取正确的字段,某种程度上还能让代码更易于理解。相反,如果数据集非常大,那请务必牢记,同样数量的数据DictReader可能会花费两倍的读取时间。
3、Excel文件处理
由于Excel可以读写CSV文件,因此从Excel电子表格文件中提取数据的最快捷、最简单的方法,其实往往是在Excel中打开并另存为CSV文件。
但是,利用Excel提取并不总是有意义,特别是如果有大量文件需要处理的情况。即使理论上可以让CSV格式文件的打开和保存过程自动执行,但这种情况下直接处理Excel文件或许速度会更快些。
对电子表格文件的深入讨论,它带有很多特性,例如,同一文件包含多张表格(sheet)、宏、多种单元格式等。事实是,Python的标准库中没有包含读写Excel文件的模块,需要安装外部模块才能读取Excel格式。幸运的是,能够完成这项工作的模块有好几个。
本例用到了一个名为OpenPyXL的模块,该模块可从Python包仓库中获取。在命令行执行以下命令即可进行安装:
$pip install openpyxl下面展示电子表格中的数据:
读取文件相当简单,但还是比CSV文件要烦琐一些。首先要载入工作簿,然后要找到指定的表格,然后就可以遍历每一行,开始提取各个单元格中的数据。以下是读取电子表格的示例代码:
>>> from openpyxl import load_workbook
>>> wb = load_workbook('temp_data_01.xlsx')
>>> results = []
>>> ws = wb.worksheets[0]
>>> for row in ws.iter_rows():
... results.append([cell.value for cell in row])
...
>>> print(results)
[['Notes', 'State', 'State Code', 'Month Day, Year', 'Month Day, Year Code',
'Avg Daily Max Air Temperature (F)', 'Record Count for Daily Max Air
Temp (F)', 'Min Temp for Daily Max Air Temp (F)', 'Max Temp for Daily
Max Air Temp (F)', 'Avg Daily Max Heat Index (F)', 'Record Count for
Daily Max Heat Index (F)', 'Min for Daily Max Heat Index (F)', 'Max for
Daily Max Heat Index (F)', 'Daily Max Heat Index (F) % Coverage'],
[None, 'Illinois', 17, 'Jan 01, 1979', '1979/01/01', 17.48, 994, 6,
30.5, 'Missing', 0, 'Missing', 'Missing', '0.00%'], [None, 'Illinois',
17, 'Jan 02, 1979', '1979/01/02', 4.64, 994, -6.4, 15.8, 'Missing', 0,
'Missing', 'Missing', '0.00%'], [None, 'Illinois', 17, 'Jan 03, 1979',
'1979/01/03', 11.05, 994, -0.7, 24.7, 'Missing', 0, 'Missing',
'Missing', '0.00%'], [None, 'Illinois', 17, 'Jan 04, 1979', '1979/01/
04', 9.51, 994, 0.2, 27.6, 'Missing', 0, 'Missing', 'Missing', '0.00%'],
[None, 'Illinois', 17, 'May 15, 1979', '1979/05/15', 68.42, 994, 61,
75.1, 'Missing', 0, 'Missing', 'Missing', '0.00%'], [None, 'Illinois',
17, 'May 16, 1979', '1979/05/16', 70.29, 994, 63.4, 73.5, 'Missing', 0,
'Missing', 'Missing', '0.00%'], [None, 'Illinois', 17, 'May 17, 1979',
'1979/05/17', 75.34, 994, 64, 80.5, 82.6, 2, 82.4, 82.8, '0.20%'],
[None, 'Illinois', 17, 'May 18, 1979', '1979/05/18', 79.13, 994, 75.5,
82.1, 81.42, 349, 80.2, 83.4, '35.11%'], [None, 'Illinois', 17, 'May 19,
1979', '1979/05/19', 74.94, 994, 66.9, 83.1, 82.87, 78, 81.6, 85.2,
'7.85%']]以上代码获得的结果,与简单得多的csv文件处理代码相同。电子表格本身就是复杂得多的对象,因此读取电子表格的代码就更加复杂,这并不奇怪。对于电子表格中的数据存储方式,也应该要了解清楚。如果电子表格包含的格式具有某种重要含义,如果标签(label)需要忽略或单独处理,如果需要处理公式和引用,那就得深入研究这些部分的处理方式,并且需要编写更加复杂的代码。
电子表格往往还会存在其他问题,电子表格通常被限制在约一百万行的规模。尽管上限听起来很大,但处理更大数据集的需求将会越来越频繁。此外,电子表格有时会自动进行一些烦人的格式处理。在我工作过的一家公司里,部件号包括一个数字和至少一个字母,后面跟着一些数字和字母的组合。很有可能看到1E20之类的部件编号。
大多数电子表格都会自动把1E20解释成科学记数法,并将其保存为1.00E+20(1×1020),而对1F20则会保留为字符串。由于各种原因,要防止这类情况的发生是相当困难的。尤其是面对大型数据集时,问题被发现时可能已经经过很多道处理工序了,甚至已全部完工了。
因此,建议尽量采用CSV或带分隔符的文件。通常用户可以把电子表格保存为CSV格式,因此通常没有必要容忍电子表格带来的额外复杂性和格式处理的麻烦。
4、数据清洗
在处理基于文本的数据文件时,有一个问题经常会碰到,那就是脏数据。“脏”的意思是,在数据中有各种各样的意外信息,例如,null值、对当前编码而言的非法值、额外的空白字符等。
数据还可能是无序的,或者顺序是难于处理的。处理这些情况的过程,就叫“数据清洗”。
1. 清洗
举个很简单的数据清洗例子,例如,要对从电子表格或其他财务程序导出的文件进行处理,而对应货币的数据列可能包含百分比和货币符号,如%、$、£和?之类,还用句点或逗号进行了额外的数据分组。从其他来源生成的数据,可能还会有其他的意外情况,如果没有提前发现,它们就会让处理过程变得十分棘手。让我们再来回顾一下之前的温度数据吧。
第一行数据如下所示:
[None, 'Illinois', 17, 'Jan 01, 1979', '1979/01/01', 17.48, 994, 6, 30.5,
2.89, 994, -13.6, 15.8, 'Missing', 0, 'Missing', 'Missing', '0.00%']某些数据列明显就是文本,如'State'(字段2)和'Notes'(字段1),对它们不会做太多的处理。还有两个不同格式的日期字段,大家很有可能想利用这两个日期进行计算,可能是按月或日对数据排序及分组,也可能是计算两行数据的时间差。
其余的字段貌似是各种类型的数字,温度是小数,记录数是整数。不过请注意,热指数温度(heat index temperature,即体感温度)有一点变化,当'Max Temp for Daily Max Air Temp (F)'字段的值低于80时,不会报告热指数字段的值,而是标为'Missing',记录数也为0。另请注意,'Daily Max Heat Index (F) % Coverage'字段表示有热指数的记录数占温度记录总数的百分比。如果要对这些字段中的值进行数学计算,这两点都会造成问题,因为'Missing'和以%结尾的数字都会被解析为字符串,而不是数字。
类似上述的数据清洗操作,可以在处理过程中分不同步骤完成。通常情况下,我倾向于在读取文件数据时进行数据清洗,因此很有可能是在处理每一行时将'Missing'替换为None值或空字符串。也可以保留'Missing'字符串不动,然后编写代码时不对'Missing'值执行数学运算。
2. 排序
如前所述,在进行处理前对文本文件的数据进行排序,往往是很有用处的。对数据进行排序后,能更容易发现和处理重复值,还有助于将相关行聚在一起,以便能更快更容易地进行处理。我曾经有一次收到了一个2000万行的文件,包含了很多属性和值,需要把数量未知的行与主SKU列表的数据项进行匹配。
只要按照数据项ID对行进行排序,就可以大大加快收集每个数据项属性的速度。排序方案取决于数据文件相对可用内存的大小,以及排序的复杂度。如果文件的全部行都能宽裕地放入可用内存中,那么最简单的方案就是将所有行读入列表并采用列表的排序方法:
>>> lines = open("datafile").readlines()
>>> lines.sort()还可采用sorted()函数,如sorted_lines = sorted(lines)。该函数会保留原列表中各行的顺序,通常这没有必要。采用sorted()函数的缺点是,它会新建一份列表的副本。这个过程会稍稍增加一点处理时间,而且会消耗两倍的内存,内存问题可能更让人担心一些。
如果数据集超过了内存大小并且排序条件非常简单,例如,只要按照一个易于抓取的字段进行排序,那么先用UNIX的sort命令这类外部实用程序对数据进行预处理,或许会更为简单一些:
$ sort data > data.srt不管采用哪种方案,排序都能够按逆序进行,并且可以由数据建立键,而不用从每行开头开始搜索。这时就得研究所用排序工具的文档了。举一个Python中的简单例子,不区分大小写对文本行进行排序。
为此要给sort方法提供一个键函数,该键函数将会在进行数据比较之前把数据项转为小写:
>>> lines.sort(key=str.lower)以下示例用到了lambda函数,以便忽略每个字符串的前5个字符:
>>> lines.sort(key=lambda x: x[5:])用键函数来决定Python中的排序行为,确实非常方便。但请务必小心,在排序过程中会大量调用键函数,因此,键函数太复杂就可能意味着实际性能的降低,特别是对大型数据集而言。
3. 数据清洗时的问题和陷阱
似乎数据源和使用场景有多少,脏数据的种类就有多少。数据总是会有很多古怪之处,一切结果皆有可能让数据处理无法准确完成,甚至可能让数据根本就无法载入。因此,这里不可能列出所有可能遇到的问题以及处理这些问题的方法,但可以给出一些通用的提示。
- 小心空白(whitespace)字符和空(null)字符。空白字符的问题在于人眼无法看到,却不意味着不会引起麻烦。数据行开头和结尾的多余空白字符,每个字段前后的多余空白符,是制表符而不是空格(反之亦然),这些问题都会让数据载入和处理过程变得更加麻烦,而且并不总是那么明显。类似地,包含空字符(ASCII 0)的文本文件在检查时看起来可能没问题,但在进行载入和处理时就会发生中断。
- 小心标点符号。标点符号也可能是个问题。多余的逗号或句点可能会破坏CSV文件的格式,也可能搅乱数值字段的处理过程。未经转义或未配对的引号,也可能会把事情搞乱。
- 分解步骤并分步调试。如果每一步都是独立的,那么调试起来就会更加容易,这意味着每步操作都要独占一行,会比较烦琐,也会用到更多的变量。但这么做是值得的。这可以让已引发的异常更容易理解。并且无论是用print语句、日志记录,还是用Python调试器,都能让调试变得更加容易。在每步执行完后都把数据保存下来,并将文件大小减小到只包含引发错误的数据行,也可能会有所帮助。
5、数据文件写入
ETL过程的最后一部分,有可能会涉及将转换后的数据保存到数据库中,但通常会牵涉到将数据写入文件。这些文件可能会被其他应用程序用作输入,并进行分析。通常该有某个文件说明,里面列出了应该包含哪些数据字段、字段名称、字段格式、字段约束条件等。
1. CSV和其他带分隔符的文件
最简单的做法,或许就是将数据写入CSV文件。因为已经完成了数据的载入、解析、清洗和转换过程,所以数据本身不太可能会碰到什么未解决问题。利用Python标准库中的csv模块,同样可以让工作更加轻松。
用csv模块写入分隔符文件的过程,几乎就是读取过程的逆操作。同样需要指定要用到的分隔符,csv模块也同样会处理分隔符位于字段内的所有情况:
>>> temperature_data = [['State', 'Month Day, Year Code', 'Avg Daily Max Air
Temperature (F)', 'Record Count for Daily Max Air Temp (F)'],
['Illinois', '1979/01/01', '17.48', '994'], ['Illinois', '1979/01/02',
'4.64', '994'], ['Illinois', '1979/01/03', '11.05', '994'], ['Illinois',
'1979/01/04', '9.51', '994'], ['Illinois', '1979/05/15', '68.42',
'994'], ['Illinois', '1979/05/16', '70.29', '994'], ['Illinois', '1979/
05/17', '75.34', '994'], ['Illinois', '1979/05/18', '79.13', '994'],
['Illinois', '1979/05/19', '74.94', '994']]
>>> csv.writer(open("temp_data_03.csv", "w",
newline='')).writerows(temperature_data)以上代码将会生成如下文件:
State,"Month Day, Year Code",Avg Daily Max Air Temperature (F),Record Count
for Daily Max Air Temp (F)
Illinois,1979/01/01,17.48,994
Illinois,1979/01/02,4.64,994
Illinois,1979/01/03,11.05,994
Illinois,1979/01/04,9.51,994
Illinois,1979/05/15,68.42,994
Illinois,1979/05/16,70.29,994
Illinois,1979/05/17,75.34,994
Illinois,1979/05/18,79.13,994
Illinois,1979/05/19,74.94,994正如读取CSV文件一样,如果采用了DictWriter,就可以写入字典而不是列表了。如果确实用到了DictWriter,要注意以下几点:必须在创建DictWriter时以列表的形式指定各个字段的名称,还可以用DictWriter的writeheader方法在文件开头写入标题行。
因此,下面假定数据与上面的相同,不过是以字典格式存在的:
{'State': 'Illinois', 'Month Day, Year Code': '1979/01/01', 'Avg Daily Max
Air Temperature (F)': '17.48', 'Record Count for Daily Max Air Temp
(F)': '994'}这时利用csv模块的DictWriter对象,就可以把所有字典数据记录逐行写入CSV文件的对应字段中。
>>> fields = ['State', 'Month Day, Year Code', 'Avg Daily Max Air Temperature
(F)', 'Record Count for Daily Max Air Temp (F)']
>>> dict_writer = csv.DictWriter(open("temp_data_04.csv", "w"),
fieldnames=fields)
>>> dict_writer.writeheader()
>>> dict_writer.writerows(data)
>>> del dict_writer2. Excel文件的写入
电子表格文件的写入,与读取过程类似,这是意料之中的事。首先需要创建工作簿(workbook)或电子表格(spreadsheet)文件,然后要创建一张或多张表(sheet),最后把数据写入合适的单元格中。
当然可以由CSV数据文件新建电子表格文件,如下所示:
>>> from openpyxl import Workbook
>>> data_rows = [fields for fields in csv.reader(open("temp_data_01.csv"))]
>>> wb = Workbook()
>>> ws = wb.active
>>> ws.title = "temperature data"
>>> for row in data_rows:
... ws.append(row)
...
>>> wb.save("temp_data_02.xlsx")在把单元格写入电子表格文件时,还能给单元格添加格式。
3. 数据文件打包
如果存在多个相互关联的数据文件,或者文件的尺寸很大,那么把它们打包到压缩过的归档文件中,可能就很有意义了。尽管目前在用的归档格式有很多,但zip文件仍为流行格式,并且几乎所有平台的用户都能用到。
6、获取网络数据
Python实现数据文件在网络上的传递,有些情况下可能是文本或电子表格文件。但其他情况下可能会是比较结构化的格式,由REST或SOAP应用程序编程接口(API)提供的。有时候,获取数据可能意味着从网站上抓取数据。
1. 获取文件
在对数据文件执行任何操作之前,首先得获取文件。有时获取过程非常简单,例如手动下载某个zip存档文件,或者文件已从其他地方推送到计算机中。但往往获取文件的过程会牵涉到更多的工作。可能需要从远程服务器检索大量文件,也可能需要定期检索文件。或者检索的过程非常复杂,足以让人工操作变得痛苦不堪。在这些情况下,都会愿意用Python来自动获取数据文件。
首先需要澄清的是,用Python脚本既不是检索文件的唯一途径,也不是最好的途径。下面给出了更多解释,这是我在决定是否采用Python脚本检索文件时考虑的因素。
虽然用Python检索文件完全能够正常工作,但并不总是最佳选择。在做出决定时,可能需要考虑两件事。
- 还有更加简单的选择吗?根据不同的操作系统和个人经验,大家可能会发现,简单的shell脚本和命令行工具配置起来会更简便易用。如果没有工具可用或者用不惯它们,或者维护它们的人用不惯,可能就会愿意考虑Python脚本。
- 检索文件的过程是否很复杂或与处理过程紧密相关?虽然这种情况从来不是我们希望的,但确实可能发生。我现在的规则就是,如果需要编写多行shell脚本,或者用shell脚本执行某些操作时必须苦思冥想该如何完成,那么可能就该是换用Python的时候了。
2. 用Python从FTP服务器获取文件
文件传输协议(FTP)已经存在很长时间了,如果不需要考虑太多的安全性,那么FTP仍然是共享文件的一种简便方案。如果要用Python访问FTP服务器,可以采用标准库中的ftplib模块。
需要遵循的步骤非常简单,先创建FTP对象,连接到服务器,然后使用用户名和密码登录,或者用“anonymous”用户名和空密码登录也是相当常见的做法。
如果要对天气数据继续操作,可以连到海洋和大气管理局(National Oceanic and Atmospheric Administration,NOAA)的FTP服务器,如下所示:
>>> import ftplib
>>> ftp = ftplib.FTP('tgftp.nws.noaa.gov')
>>> ftp.login()
'230 Login successful.'连上之后,就可以用ftp对象列出并更改目录了:
>>> ftp.cwd('data')
'250 Directory successfully changed.'
>>> ftp.nlst()
['climate', 'fnmoc', 'forecasts', 'hurricane_products', 'ls_SS_services',
'marine', 'nsd_bbsss.txt', 'nsd_cccc.txt', 'observations', 'products',
'public_statement', 'raw', 'records', 'summaries', 'tampa',
'watches_warnings', 'zonecatalog.curr', 'zonecatalog.curr.tar']然后就可以获取文件了,例如,天气报告(METAR)文件:
>>> x = ftp.retrbinary('RETR observations/metar/decoded/KORD.TXT',
open('KORD.TXT', 'wb').write)
'226 Transfer complete.'这里将远程服务器文件路径和本地数据处理方法传给了ftp.retrbinary方法,这里文件对象的write方法是用二进制写入模式和同一个文件名打开的。
如果打开KORD.TXT查看,就会看到其中的下载数据了:
CHICAGO O'HARE INTERNATIONAL, IL, United States (KORD) 41-59N 087-55W 200M
Jan 01, 2021 - 09:51 PM EST / 2021.01.02 0251 UTC
Wind: from the E (090 degrees) at 6 MPH (5 KT):0
Visibility: 10 mile(s):0
Sky conditions: mostly cloudy
Temperature: 33.1 F (0.6 C)
Windchill: 28 F (-2 C):1
Dew Point: 21.9 F (-5.6 C)
Relative Humidity: 63%
Pressure (altimeter): 30.14 in. Hg (1020 hPa)
Pressure tendency: 0.01 inches (0.2 hPa) lower than three hours ago
ob: KORD 020251Z 09005KT 10SM SCT150 BKN250 01/M06 A3014 RMK AO2 SLP214
T00061056 58002
cycle: 3用ftplib还可以通过FTP_TLS而不是FTP协议,以TLS加密方式连入服务器:
ftp = ftplib.FTPTLS('tgftp.nws.noaa.gov')3. 通过SFTP协议获取文件
如果数据要求更高的安全性,例如,在公司环境下通过网络传输业务数据,那么比较常见的做法是采用SFTP协议。SFTP是一种全功能的协议,允许通过安全shell(Secure Shell,SSH)连接进行文件访问、传输和管理。尽管SFTP的意思是“SSH文件传输协议”(SSH File Transfer Protocol),FTP的意思是文件传输协议(File Transfer Protocol),但两者其实毫无关系。SFTP并不是在SSH上重新实现了FTP,而是专用于SSH的全新设计。
因为SSH已经成为访问远程服务器的事实标准,并且服务器端很容易就能启用对SFTP的支持(往往默认是开启的),所以采用基于SSH的传输颇具吸引力,
Python没有在标准库中包含SFTP/SCP客户端模块,不过社区开发的库paramiko就可实现SFTP操作和SSH连接的管理。如果要使用paramiko,最简单的方式就是通过pip安装。假如NOAA站点使用了SFTP(其实并未使用SFTP,因此以下代码无法运行!),上述代码的SFTP等效实现将如下所示:
>>> import paramiko
>>> t = paramiko.Transport((hostname, port))
>>> t.connect(username, password)
>>> sftp = paramiko.SFTPClient.from_transport(t)值得注意的是,尽管paramiko支持在远程服务器上运行命令并接收其输出,但就像直接ssh会话一样,它不包含scp功能。scp是个不容错过的好功能,如果只想通过ssh连接转移一两个文件,用命令行工具scp完成往往会更加轻松简单。
4. 通过HTTP/HTTPS协议获取文件
最后一种检索数据文件的方式,就是通过HTTP或HTTPS连接获取文件。这可能是一种最简单的获取方式了,实际上就是从Web服务器检索数据,并且对访问Web服务器的支持是非常普遍的。这时同样可能不必用到Python。通过HTTP/HTTPS连接检索文件的命令行工具有很多,并且可能需要的大多数功能也都具备。其中最常用的两个工具就是wget和curl。不过,如果有理由要在Python代码中检索数据,那过程其实没那么困难。
到目前为止,要在Python代码中访问HTTP/HTTPS服务器,最简单可靠的方法就是requests库。通过pip install requests仍然是安装requests最容易的方式。
requests安装完成后,文件的获取就很简单了,先导入requests,再用正确的HTTP操作(通常是GET)连接到服务器并返回数据。
以下例程将会获取1948年以来希思罗机场的每月温度数据,也就是一个通过Web服务器提供的文本文件。大家完全可以将URL放入浏览器,加载页面,然后把文件保存下来。
如果页面很大,或者有很多页面需要获取,那么用以下代码将会容易一些:
>>> import requests
>>> response = requests.get("http://www.epubit.com:8083/quickpythonbook?heathrowdata.txt")页面响应对象response将带有相当多的信息,包括Web服务器返回的报头信息(Header),如果文件获取过程不正常,这些信息可以帮助调试。不过response对象中最让人感兴趣的部分,往往是返回的数据。
为了检索这些数据,需要访问response对象的text属性,其中存放了字符串形式的响应主体部分。或者还可以访问其content属性,其中存放了字节形式的响应主体部分:
>>> print(response.text)
Heathrow (London Airport)
Location 507800E 176700N, Lat 51.479 Lon -0.449, 25m amsl
Estimated data is marked with a * after the value.
Missing data (more than 2 days missing in month) is marked by ---.
Sunshine data taken from an automatic Kipp & Zonen sensor marked with a #,
otherwise sunshine data taken from a Campbell Stokes recorder.
yyyy mm tmax tmin af rain sun
degC degC days mm hours
1948 1 8.9 3.3 --- 85.0 ---
1948 2 7.9 2.2 --- 26.0 ---
1948 3 14.2 3.8 --- 14.0 ---
1948 4 15.4 5.1 --- 35.0 ---
1948 5 18.1 6.9 --- 57.0 ---通常应该把响应文本写入文件,以供后续处理。但根据需要,可以先做一些清洗操作,甚至直接进行数据处理。
5. 通过API获取数据
通过API提供数据已经相当地普遍了,这也顺应了将应用程序与服务进行解耦的趋势,而服务就是通过网络API进行通信的。API的工作方式可以有多种,但通常会在常规HTTP/HTTPS协议上采用标准的HTTP操作,如GET、POST、PUT和DELETE。
以这种方式获取数据与文件检索过程非常类似,但是数据不在静态文件中。应用程序不直接提供包含数据的静态文件,而是根据请求动态地从某些其他数据源查询、组装并提供数据。
虽然API的各种建立方式有很大差别,但最常见的一种就是REST风格的(REpresentational State Transfer)接口,运行在与Web相同的HTTP/HTTPS协议之上。API的工作方式千变万化,但常用的是通过GET请求来获取数据,这也正是Web浏览器用来请求网页的方式。当通过GET请求获取数据时,用于选取数据的参数通常会附到查询字符串的URL之后。
如果要从好奇号火星车上获取火星当前的天气,请用http://marsweather.ingenology.com/v1/ latest/?format=json作URL。?format=json是查询字符串参数,指定数据要以JSON格式返回。如果需要获取指定火星日的火星天气,或者指定自任务开始的火星日数,如第155火星日,URL请用http://marsweather.ingenology.com/v1/archive/?sol= 155&format=json。
如果想获取某地球日期区间的火星天气,如整个2021年10月,请使用http://marsweather.ingenology.com/v1/archive/?terrestrial_date_start=2021-10-01&terrestrial_date_end= 2021- 10-31。
注意,查询字符串中的各数据项应由“&”符号分隔。如果要用到的URL已知,就可以用requests库通过API获取数据,然后既可以实时进行处理,也可以保存到文件中供后续处理。
最简单的做法就是检索文件:
>>> import requests
>>> response = requests.get("http://marsweather.ingenology.com/v1/latest/?format=json")
>>> response.text
'{"report": {"terrestrial_date": "2021-01-08", "sol": 1573, "ls": 295.0,
"min_temp": -74.0, "min_temp_fahrenheit": -101.2, "max_temp": -2.0,
"max_temp_fahrenheit": 28.4, "pressure": 872.0, "pressure_string":
"Higher", "abs_humidity": null, "wind_speed": null, "wind_direction": "-
-", "atmo_opacity": "Sunny", "season": "Month 10", "sunrise": "2021-01-
08T12:29:00Z", "sunset": "2021-01-09T00:45:00Z"}}'
>>> response = requests.get("http://marsweather.ingenology.com/v1/archive/?sol=155&format=json")
>>> response.text
'{"count": 1, "next": null, "previous": null, "results":
[{"terrestrial_date": "2021-01-18", "sol": 155, "ls": 243.7, "min_temp":
-64.45, "min_temp_fahrenheit": -84.01, "max_temp": 2.15,
"max_temp_fahrenheit": 35.87, "pressure": 9.175, "pressure_string":
"Higher", "abs_humidity": null, "wind_speed": 2.0, "wind_direction":
null, "atmo_opacity": null, "season": "Month 9", "sunrise": null,
"sunset": null}]}'记住,在查询参数中应该对空格和大多数标点符号进行转义,因为URL中不允许存在这些符号。许多浏览器都会自动对URL进行转义。
最后再举一个例子,假定需要抓取2021年1月10日12点和下午1点之间的数据。采用API的方式,指定日期范围的查询字符串参数为“$where=date between < start datetime>”和“
由此,获取1小时的数据的URL将会是https://data.cityofchicago.org/resource/6zsd86xi.json?$where=date between '2021-01-10T12:00:00' and '2021-01-10T13:00:00'。
上述例子中有很多字符是URL不可接受的,如引号和空格符。在发送之前,requests库会对URL进行正确的转义处理(quote)。因此这也充分体现了requests库的目标,能够为用户简化操作。request对象实际发送出去的URL将会是https://data.cityofchicago.org/resource/6zsd-86xi.json?$where=date%20between%20%222021-01-10T12:00:00%22%20and%20%222021-01-10T14:00:00%22。
注意,甚至都无须过多操心,所有的单引号都转义成了“%22”,所有的空格都成了“%20”。
7、网络数据序列化处理
虽然有时能够提供普通的文本格式,但API提供的数据更常见的还是结构化文件格式。
最常见的两种文件格式就是JSON和XML。这两种格式都基于普通文本,但内容做了结构化处理,因此灵活性更高,能够存放更加复杂的信息。
1. JSON数据
JSON代表JavaScript Object Notation的意思,历史可以追溯到1999年。JSON只包含两种结构:一种是称为结构(structure)的键/值对,与Python的字典很类似;另一种是数值的有序列表,名为数组(array),非常类似于Python的列表。
键只能是双引号包裹的字符串,值可以是双引号包裹的字符串、数字、true、false、null、数组或对象。这些元素促使JSON成了一种轻量级的解决方案,采用便于网络传递的方式表示大多数数据,同时人类也相当容易读懂。
JSON已得到普遍应用,以至于大多数编程语言都具备了将JSON转换为原生数据类型的功能。而Python提供的功能就是json模块,已成为2.6版标准库的一部分。该模块最初的外部维护版本,目前仍可作为simplejson使用。但在Python 3中,标准库的版本会常用得多。
由火星车API检索到的数据,采用的就是JSON格式。如果要通过网络发送JSON,需要将JSON对象序列化,也就是转换为字节序列。
因此,虽然由火星车API检索到的批量数据看起来像是JSON,但实际上只是JSON对象的字节字符串表示。要将该字节字符串转换为真正的JSON对象,并将其转换为Python字典,需要用到JSON对象的loads()函数。
例如,要获取火星天气报告,就可像之前一样操作,但这次会将数据转换为Python字典:
>>> import json
>>> import requests
>>> response = requests.get("http://marsweather.ingenology.com/v1/latest/
?format=json")
>>> weather = json.loads(response.text)
>>> weather
{'report': {'terrestrial_date': '2021-01-10', 'sol': 1575, 'ls': 296.0,
'min_temp': -58.0, 'min_temp_fahrenheit': -72.4, 'max_temp': 0.0,
'max_temp_fahrenheit': None, 'pressure': 860.0, 'pressure_string':
'Higher', 'abs_humidity': None, 'wind_speed': None, 'wind_direction': '-
-', 'atmo_opacity': 'Sunny', 'season': 'Month 10', 'sunrise': '2021-01-
10T12:30:00Z', 'sunset': '2021-01-11T00:46:00Z'}}
>>> weather['report']['sol']
1575注意,调用json.loads(),是为了得到JSON对象的字符串表示形式,并将其转换或加载到Python字典中。同样,json.load()函数也能从任何类似文件的对象中读取数据,只要支持read方法即可。
去看看之前字典的显示形式,内容是难以理解的。经过改善的格式化过程也叫美观输出(pretty printing),可让数据结构理解起来容易许多。下面用Python的prettyprint模块查看一下示例字典中的内容:
>>> from pprint import pprint as pp
>>> pp(weather)
{'report': {'abs_humidity': None,
'atmo_opacity': 'Sunny',
'ls': 296.0,
'max_temp': 0.0,
'max_temp_fahrenheit': None,
'min_temp': -58.0,
'min_temp_fahrenheit': -72.4,
'pressure': 860.0,
'pressure_string': 'Higher',
'season': 'Month 10',
'sol': 1575,
'sunrise': '2021-01-10T12:30:00Z',
'sunset': '2021-01-11T00:46:00Z',
'terrestrial_date': '2021-01-10',
'wind_direction': '--',
'wind_speed': None}}两种加载函数都可以加以配置,以便对原始JSON到Python对象的解析和解码过程进行控制,下表列出了默认的转换配置。
JSON转成Python对象的默认解码关系:
| JSON | Python |
| object | dict |
| array | list |
| string | str |
| number (int) | int |
| number (real) | float |
| true | True |
| false | False |
| null | None |
通过requests库来检索JSON格式的数据,然后用json.loads()方法将其解析为Python对象。这种技术完全没有问题,但是因为requests库经常是只派这种用场,所以就提供了一个快捷方式,response对象其实带有一个json()方法,可以直接完成转换。
因此在此例中,可以不用:
>>> weather = json.loads(response.text)而是采用:
>>> weather = response.json()结果是一样的,但是代码更简单易读,更具Python风格。
如果要将JSON写入文件,或者序列化为字符串,则load()和loads()的逆函数是dump()和dumps()。json.dump()带有一个参数,即拥有write()方法的文件对象,并返回一个字符串。在这两种情况下,JSON格式的字符串的编码都可以高度自定义。
因此,如果要将火星天气报告写入JSON文件,可以如下操作:
>>> outfile = open("mars_data_01.json", "w")
>>> json.dump(weather, outfile)
>>> outfile.close()
>>> json.dumps(weather)
'{"report": {"terrestrial_date": "2021-01-11", "sol": 1576, "ls": 296.0,
"min_temp": -72.0, "min_temp_fahrenheit": -97.6, "max_temp": -1.0,
"max_temp_fahrenheit": 30.2, "pressure": 869.0, "pressure_string":
"Higher", "abs_humidity": null, "wind_speed": null, "wind_direction": "-
-", "atmo_opacity": "Sunny", "season": "Month 10", "sunrise": "2021-01-
11T12:31:00Z", "sunset": "2021-01-12T00:46:00Z"}}'正如所见,整个对象已编码成了一个字符串。同样,就像采用pprint模块一样,这时如果要以可读性更好的方式对字符串进行格式化,可能就很方便了。
通过带有indent参数的dump或dumps函数,就很容易实现:
>>> print(json.dumps(weather, indent=2))
{
"report": {
"terrestrial_date": "2021-01-10",
"sol": 1575,
"ls": 296.0,
"min_temp": -58.0,
"min_temp_fahrenheit": -72.4,
"max_temp": 0.0,
"max_temp_fahrenheit": null,
"pressure": 860.0,
"pressure_string": "Higher",
"abs_humidity": null,
"wind_speed": null,
"wind_direction": "--",
"atmo_opacity": "Sunny",
"season": "Month 10",
"sunrise": "2021-01-10T12:30:00Z",
"sunset": "2021-01-11T00:46:00Z"
}
}不过有一点应该清楚,如果重复调用json.dump()将一系列对象写入文件,那么结果将是一系列合法的JSON格式对象,但整个文件的内容却不是合法的JSON格式对象。如果试图通过一次调用json.load()就想读取和解析整个文件,就会失败。要想把多个对象编码成一个JSON对象,需要将这些对象全部放入一个列表中,或者最好是一个对象中,然后将该对象编码成JSON文件。
如果需要把两天或以上的火星天气数据保存为JSON格式,则必须选择一种操作方案。可以对每个对象都调用一次json.dump(),这会生成包含多个JSON格式对象的文件。
假定weather_list是天气报告对象的列表,则代码可能如下所示:
>>> outfile = open("mars_data.json", "w")
>>> for report in weather_list:
... json.dump(weather, outfile)
>>> outfile.close()这样在读取时,就需要把每行都加载为单独的JSON格式对象:
>>> for line in open("mars_data.json"):
... weather_list.append(json.loads(line))或者也可以把列表放入一个JSON对象中。因为JSON的顶层数组可能存在漏洞,所以推荐方案是把数组放入一个字典中:
>>> outfile = open("mars_data.json", "w")
>>> weather_obj = {"reports": weather_list, "count": 2}
>>> json.dump(weather, outfile)
>>> outfile.close()通过这种方案,一步就可以从文件加载JSON格式的对象了:
>>> with open("mars_data.json") as infile:
>>> weather_obj = json.load(infile)如果JSON文件的大小可控,那么第二种方法会比较好。但对于非常大的文件来说,可能就不太理想了,因为错误处理可能会有点困难,还有可能将内存消耗殆尽。
2. XML数据
可扩展标记语言(eXtensible Markup Language,XML)是从20世纪末开始出现的。XML采用了类似HTML的尖括号标签(tag)写法,元素相互嵌套形成了树状结构。XML本来是打算供机器和人类阅读的,但往往太过冗长和复杂,以至于人类难以理解。
尽管如此,因为XML已是一种既定标准,所以查找XML格式的数据是相当常见的需求。尽管XML格式是机器可读(machine-readable)的,但大家很可能想转为更加便于处理的格式。
下面看一些XML数据的示例,这里是天气数据的XML版本:
NOAA's National Weather Service Forecast at a Glance
meteorological
forecast
2021-01-08T02:52:41Z
http://www.nws.noaa.gov/forecasts/xml/
Meteorological Development Laboratory
Product Generation Branch
http://www.nws.noaa.gov/disclaimer.html
http://www.weather.gov/
http://www.weather.gov/images/xml_logo.gif
http://www.weather.gov/feedback.php
point1
...
以上示例只是XML文档的第一部分,这里省略了大部分数据。即便如此,它还是展示了一些在XML数据中经常会发现的问题。特别是XML协议冗长的特性,某些情况下标签占用的空间比内部包含的数据还要多。该示例还展示了XML中常见的嵌套或树状结构,以及在实际数据前面经常会用到的庞大的元数据首部。如果把数据文件格式从简单到复杂排列一下,CSV或分隔符文件可被视为最简单的一头,而XML算是最复杂的另一头。
该文件还演示了XML的另一个特性,也稍稍增加了数据提取的难度。XML支持用属性来存储数据和标签内的文本值。因此,查看一下例子末尾的point元素,会看到它没有包含文本值。
该元素在
以上代码当然是合法的XML,适用于存储数据,但也可以把相同数据存储为以下格式:
41.78
-88.65
如果没有仔细检查数据,也没有认真研究XML规范文档,那真的会不知道该用什么方案来处理给定的数据。
正是因为这种复杂性,要从XML中提取简单数据,将会面临很大难度。处理XML的方式有几种选择。Python标准库自带了解析和处理XML数据的模块,但用于简单数据提取都不是特别方便。
对于简单数据的提取,我能找到的使用最方便的实用程序,是一个名为xmltodict的库,它会解析XML数据并返回与树状结构对应的字典。
实际上,xmltodict背后用到了标准库中的XML解析器模块expat,将XML文档解析为对象树,并用对象树创建字典。因此,xmltodict可以处理XML解析器能够处理的任何内容,并且还能读取字典并在必要时将其“组装”(unparse)为XML,这使得xmltodict成为非常好用的工具。经过几年的使用,我发现这个解决方案可以满足所有的XML处理需求。如果要获取xmltodict,仍然可以用pip install xmltodict。
要将XML转换为字典,可以导入xmltodict并对XML格式的字符串使用parse方法:
>>> import xmltodict
>>> data = xmltodict.parse(open("observations_01.xml").read())为了紧凑,这里将文件内容直接传给parse方法。解析完成之后的数据对象,是一个有序字典,其中包含的数据就如同从JSON加载的一样:
{
"dwml": {
"@xmlns:xsd": "http://www.w3.org/2001/XMLSchema",
"@xmlns:xsi": "http://www.w3.org/2001/XMLSchema-instance",
"@version": "1.0",
"@xsi:noNamespaceSchemaLocation": "http://www.nws.noaa.gov/forecasts/ xml/DWMLgen/schema/DWML.xsd",
"head": {
"product": {
"@srsName": "WGS 1984",
"@concise-name": "glance",
"@operational-mode": "official",
"title": "NOAA's National Weather Service Forecast at a Glance",
"field": "meteorological",
"category": "forecast",
"creation-date": {
"@refresh-frequency": "PT1H",
"#text": "2021-01-08T02:52:41Z"
}
},
"source": {
"more-information": "http://www.nws.noaa.gov/forecasts/xml/",
"production-center": {
"sub-center": "Product Generation Branch",
"#text": "Meteorological Development Laboratory"
},
"disclaimer": "http://www.nws.noaa.gov/disclaimer.html",
"credit": "http://www.weather.gov/",
"credit-logo": "http://www.weather.gov/images/xml_logo.gif",
"feedback": "http://www.weather.gov/feedback.php"
}
},
"data": {
"location": {
"location-key": "point1",
"point": {
"@latitude": "41.78",
"@longitude": "-88.65"
}
}
}
}
}注意,所有属性已从标签中提取出来,带上了@前缀用以标明它们原来是父标签的属性。
如果XML节点同时包含文本值和嵌套元素,注意文本值的键是"#text",如"production-center"之下的"sub-center"元素。
之前提到过,解析的结果是一个有序字典,官方说法是OrderedDict。所以如果把它打印出来,代码应如下所示:
OrderedDict([('dwml', OrderedDict([('@xmlns:xsd', 'http://www.w3.org/2001/
XMLSchema'), ('@xmlns:xsi', 'http://www.w3.org/2001/XMLSchema-
instance'), ('@version', '1.0'), ('@xsi:noNamespaceSchemaLocation',
'http://www.nws.noaa.gov/forecasts/xml/DWMLgen/schema/DWML.xsd'),
('head', OrderedDict([('product', OrderedDict([('@srsName', 'WGS 1984'),
('@concise-name', 'glance'), ('@operational-mode', 'official'),
('title', "NOAA's National Weather Service Forecast at a Glance"),
('field', 'meteorological'), ('category', 'forecast'), ('creation-date',
OrderedDict([('@refresh-frequency', 'PT1H'), ('#text', '2021-01-
08T02:52:41Z')]))])), ('source', OrderedDict([('more-information',
'http://www.nws.noaa.gov/forecasts/xml/'), ('production-center',
OrderedDict([('sub-center', 'Product Generation Branch'), ('#text',
'Meteorological Development Laboratory')])), ('disclaimer', 'http://
www.nws.noaa.gov/disclaimer.html'), ('credit', 'http://www.weather.gov/
'), ('credit-logo', 'http://www.weather.gov/images/xml_logo.gif'),
('feedback', 'http://www.weather.gov/feedback.php')]))])), ('data',
OrderedDict([('location', OrderedDict([('location-key', 'point1'),
('point', OrderedDict([('@latitude', '41.78'), ('@longitude', '-
88.65')]))])), ('#text', '…')]))]))])虽然OrderedDict的显示形式着实有些古怪,即元组构成的多个列表,但它的行为与普通的字典完全相同,只不过能保证维持元素的顺序不变,当前情况下这是有用的。
如果元素有重复,那就会成为一个列表。在之前给出的完整文件中,还有一部分会出现以下元素(这里省略了一些元素):
2021-01-09T07:00:00-06:00
2021-01-09T19:00:00-06:00
2021-01-10T07:00:00-06:00
2021-01-10T19:00:00-06:00
2021-01-11T07:00:00-06:00
2021-01-11T19:00:00-06:00
注意两个元素"start-valid-time"和"end-valid-time",它们交替重复出现了,这两个出现重复的元素将会分别转换为字典中的列表,并保持每组元素的适当顺序不变:
"time-layout":
{
"start-valid-time": [
{
"@period-name": "Monday",
"#text": "2021-01-09T07:00:00-06:00"
},
{
"@period-name": "Tuesday",
"#text": "2021-01-10T07:00:00-06:00"
},
{
"@period-name": "Wednesday",
"#text": "2021-01-11T07:00:00-06:00"
}
],
"end-valid-time": [
"2021-01-09T19:00:00-06:00",
"2021-01-10T19:00:00-06:00",
"2021-01-11T19:00:00-06:00"
]
},字典和列表,乃至嵌套的字典和列表,在Python中处理起来都相当容易,因此采用xmltodict是处理大多数XML的有效途径。其实在过去的几年里,我已经在多种XML文档的生产环境中用过了,从来没有出现过问题。
8、网络数据爬取
有些情况下,数据位于某个网站中,由于某些原因在其他地方都得不到。这时通过爬取(crawling)或抓取(scraping)过程,从网页本身采集数据可能就很有意义了。
在详细介绍抓取操作之前,请允许做一个免责声明。抓取或爬取非自有或无控制权的网站,最好情况也不过是合法的灰色地带,需要考虑很多尚无定论和意见相互对立的难题,涉及网站使用条款、站点访问方式和被抓取数据的用途等方面。除非对要抓取的网站拥有控制权,否则对“抓取这个网站是否合法?”的答案往往是“看情况”。
如果决定要抓取生产环境下的网站,还需要时刻注意加到网站上的负载情况。虽然已建成的大流量站点或许能够处理抛过去的任何操作,但是小型的、不太活跃的站点可能会被一系列连续请求带入停顿状态。至少得多加小心,别让抓取操作变成无意间的拒绝服务攻击。
不过,我曾碰到过这种情况,某些数据通过我们自己的网站抓取确实比通过公司渠道要容易一些。
网站的抓取包括两部分操作:网页的获取和数据的提取。网页的获取可以通过requests模块来完成,而且相当简单。
下面考虑一个很简单的网页代码,只有几句正文,没有CSS或JavaScript,代码如下所示。
test.html文件:
Title
Heading 1
This is plan text, and is boring
this is special
Here is a link
Ann Address, Somewhere, AState 00000
假设只对上述页面中的几类数据感兴趣,即带有"special"类名的元素内容,以及网页链接。可以通过搜索字符串class="special"和"
Beautiful Soup安装完毕后,解析HTML页面就很简单了。对于上述示例页面,假设已经检索到了网页(可能是用了requests库),然后只需解析HTML即可。 第一步是加载文本并创建Beautiful Soup解析器: 以上就是把HTML解析为解析器对象bs的全部代码。Beautiful Soup解析器对象拥有很多很酷的技巧,如果确实要处理HTML,那么真的值得花点时间进行一些实验,感受一下它的能力。本例只需关心两件事:根据HTML标记提取内容,根据CSS类获取数据。 首先要找到网页链接。网页链接的HTML标记是,Beautiful Soup默认将所有标记转换为小写。因此要查找所有链接标记,可以用"a"作为参数调用bs对象本身: 现在得到了一个包含所有HTML链接标签的列表,本例只有一个网页链接。如果只是获得了这个列表,那还不算太糟。 但事实上,列表中返回的元素都还是解析器对象,可以用来完成剩下的获取链接和文本操作: 另一个要找的是带有CSS类"special"的部分,可以用解析器的select方法进行提取。如下所示: 因为由标签或select方法返回的数据项就是解析器对象本身,所以可以嵌套起来使用,这样就可以从HTML甚至XML中提取任何内容了。 总结:>>> import bs4
>>> html = open("test.html").read()
>>> bs = bs4.BeautifulSoup(html, "html.parser")>>> a_list = bs("a")
>>> print(a_list)
[link]>>> a_item = a_list[0]
>>> a_item.text
'link'
>>> a_item["href"]
'http://bitbucket.dev.null'>>> special_list = bs.select(".special")
>>> print(special_list)
[this is special]
>>> special_item = special_list[0]
>>> special_item.text
'this is special'
>>> special_item["class"]
['special']