Spark环境搭建-Windows
Spark环境搭建-Windows
一、搭建环境简介。
1.1、相关材料的准备
• 以下是我们所要用到的环境,所有的安装包都可以到官网下载,也可以私信我的。
Python使用官方版的python- 3. 7. 2 版本
JDK使用 1. 8 版本
Scala使用 2. 12 版本
Hadoop使用 2. 7. 3 版本(Windows上搭建需要安装hadoop)
Spark使用 2. 3. 3 版本( 2. 4. 0 版本在Windows上有问题,不要用)

二、Python的安装与配置
2.1、安装Python
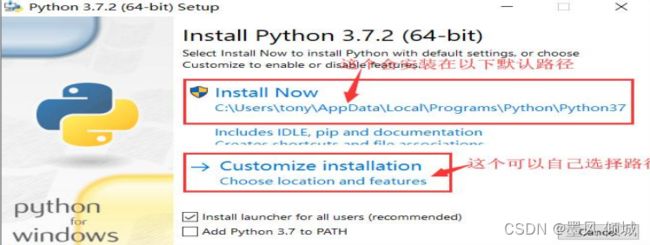
点击Python的安装包开始安装,又两种选择,一种是安装在默认路径下,一种可以自行选择安装路径,我们选第二种。也可以勾选底下的Add Python 3. 7 to Path,勾选后会帮你自动配置环境变量。
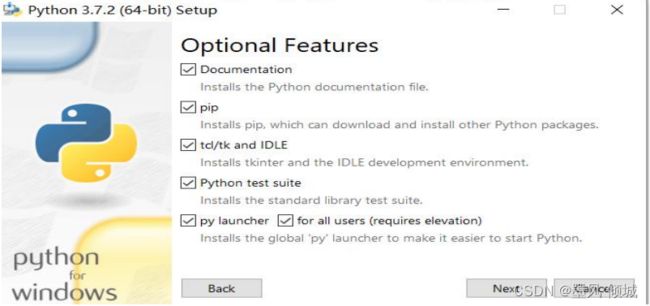
这里是询问你要安装那些功能,直接点击Next。
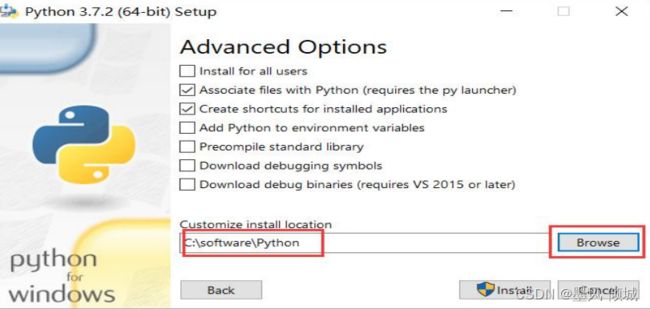
这里可以点击 Browser 选择安装的路径,自己新建一个Python目录来安装,选择完毕后点击 Install 按钮继续。尽量不要把软件安装在C盘,这里是因为虚拟机只有一个盘,所以才放C盘。
出现这个页面即为安装成功,直接关掉该窗口。
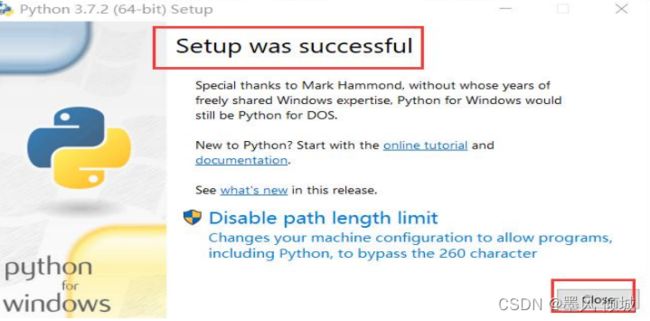
2.2、配置环境变量,将Python的目录添加到Path中。
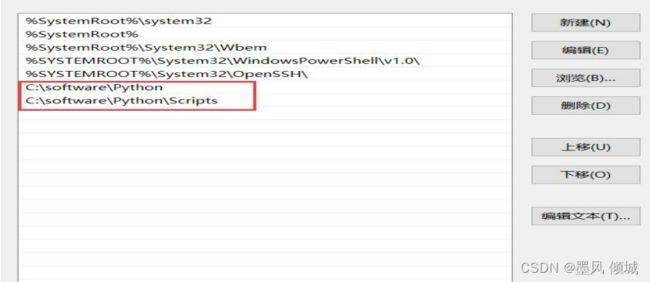
这里是环境变量配置,在计算机属性>高级系统设置>环境变量 当中设置添加。
2.3、验证Python是否安装成功
打开命令行,输入python,验证是否安装配置成功。

再输入命令pip list检查pip环境是否配置正确。

三、JDK安装与配置
3.1、JDK的安装
直接点击安装包开始安装,然后在弹出的窗口点击下一步。

这里可以选择安装路径,点击“更改”选择路径(一定要更改默认路径,默认路径带空格会出错的),自己新建一个java路径,我这里叫做“jdk 8 ”,选中然后点击“下一步”。
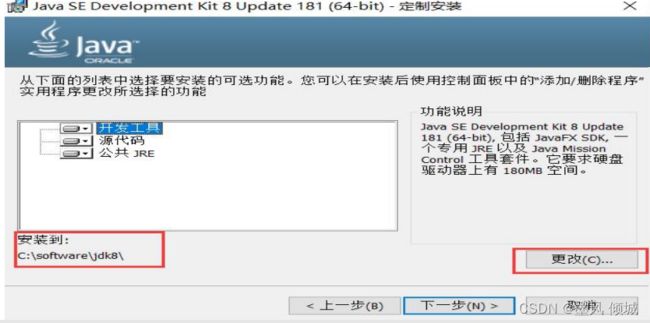
点击“确定”继续。

这里是要安装jre,点击“更改”选择路径,先在jdk 8 目录下新建一个文件夹叫“jre 8 ”,然后选中这个路径,点击“下一步”继续。
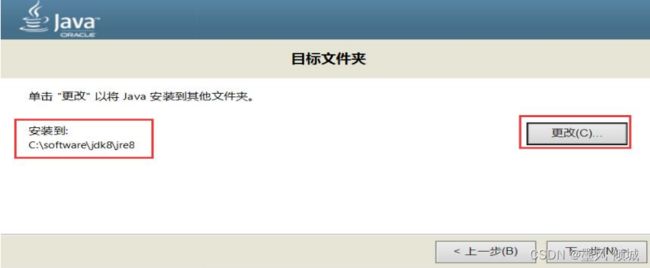
出现这个表明已经安装完成,点击“关闭”。
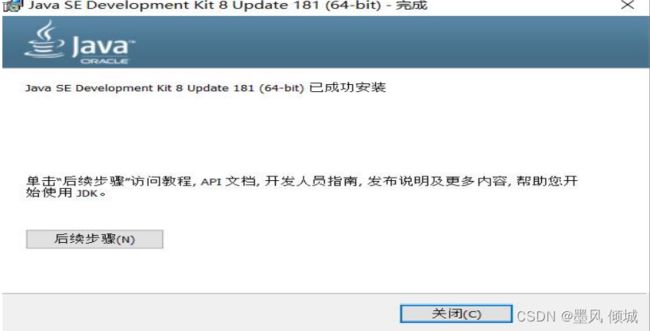
安装完成后,配置一下jdk的环境,新建一个变量,JAVA_HOME,值为你安装的的jdk/bin目录。

再新建一个变量,CLASSPATH,值为(注意前面有 .;):

.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar
在Path变量中增加JDK的bin目录,值为:
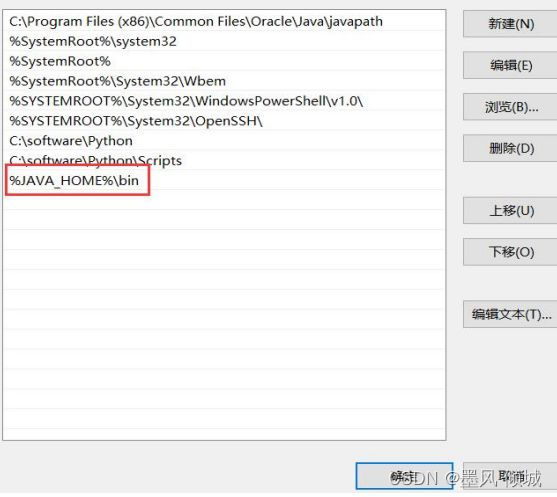
%JAVA_HOME%\bin
3.2、JDK的验证
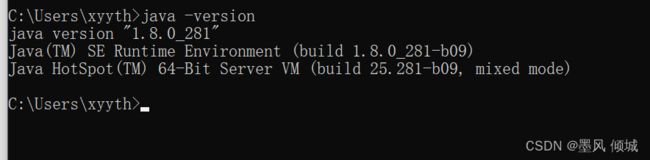
至此,jdk已经配置完毕,打开命令行,输入
java – version
命令检查是否安装成功。(java 命令,javac 命令也行)
四、Scala的安装与配置
4.1、Scala的安装
直接点击安装包开始安装,然后在弹出的窗口点击“Next”。先勾选“I accept…”再点击“Next”。
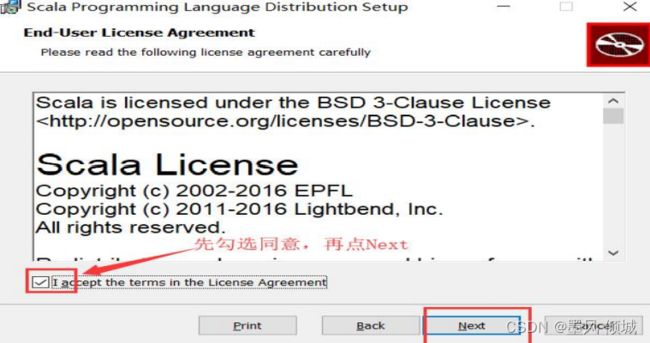
这里可以选择安装路径,点击“Browser”选择路径,自己新建一个scala路径,我这里叫做“scala”,选中然后点击“Next” 。
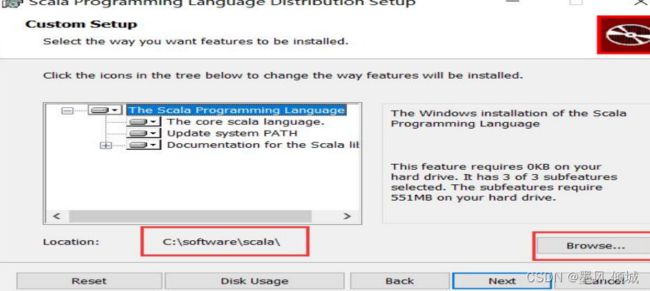
点击“Install”继续。出现这个即为安装成功,点击“Finish”关闭窗口。

4.2、Scala环境变量配置
安装完成后,在环境变量path中将scala下的bin目录添加进去。
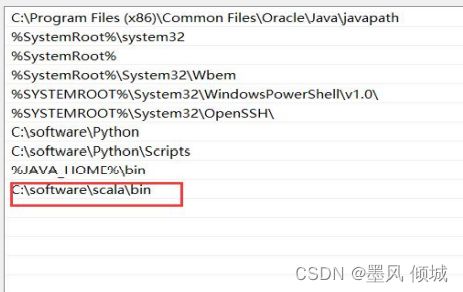
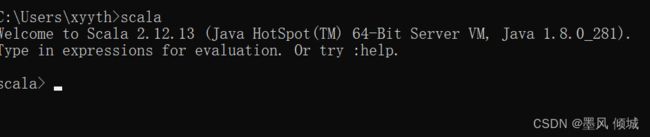
至此,scala已经安装配置完成,打开命令行窗口,输入命令
scala
如果能进入scala命令行,则说明安装成功。
五、Hadoop的安装与配置
将hadoop.rar和spark.rar文件解压并复制到一个你喜欢的位置。这里我是放在跟jdk和scala同级的文件夹下。
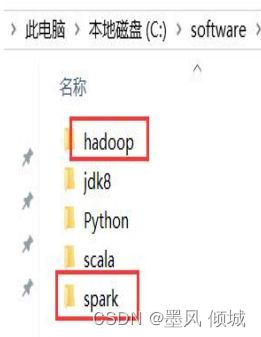
Hadoop的环境配置在系统变量中新增一个变量,叫HADOOP_HOME,值为hadoop文件夹的路径。

Hadoop的环境配置在系统变量Path中添加一个hadoop\bin路径,如果已经配置HADOOP_HOME,可以直接填:
%HADOOP_HOME %\bin

六、 Spark的安装与配置
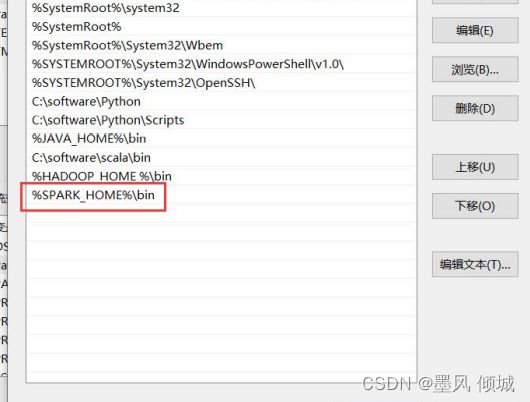
配置spark环境Spark不用安装,直接用刚才解压好的文件配置环境就行了。在环境变量中新增一个变量,叫SPARK_HOME值为spark的安装路径。

在系统变量Path中添加一个spark\bin路径,如果已经配置SPARK_HOME,可以直接填:
%SPARK_HOME%\bin
七、 Spark启动及监视
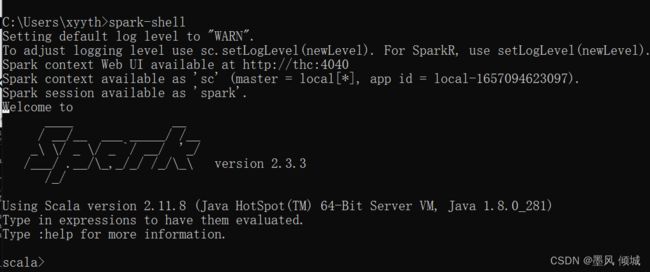
输入spark-shell命令
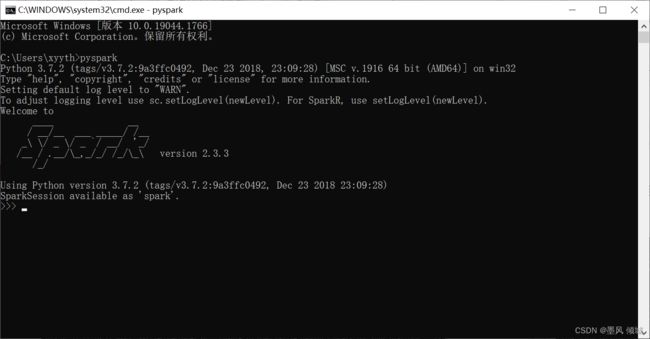
输入pyspark命令
浏览器进入:http://localhost: 4040 /jobs/