machine unlearning 论文阅读笔记
文章目录
-
- 前言
- 概要
- 导论
- unlearning 定义
- SISA 系统
- 时间复杂度
- 实验测试
- 总结
前言
做一篇发表在顶会S&P - 4 2 n d 42^{nd} 42nd IEEE Symposium of Security and Privacy 的paper阅读笔记
Machine Unlearning
这是一篇关于机器遗忘学习的paper, 顾名思义, machine unlearning就是让训练好的模型遗忘掉特定数据训练效果/特定参数, 以达到保护模型中隐含数据的目的.
随着隐私保护法的颁布, 最近两年机器遗忘学习逐渐成为AI security和privacy领域的研究热点, 不同于传统的数据安全和隐私保护问题, AI模型中的隐私保护问题更加棘手, 因为已经训练好的模型通常不能实现将已用训练数据训练出来的参数遗忘的目标, 比如电商推荐系统中一个用户的浏览历史和购买历史会暴露一个人的偏好等信息, 但是如果用户要求平台遗忘掉她/他的偏好, 就目前看来商用推荐系统都是做不到的, 这样就造成很直接的隐私泄露问题, 而machine unlearning的研究就是为了解决这类问题而提出的.
在大数据时代, 普通人只要上网就相当于裸奔, 唯一不同的是大数据时代的隐私保护可不是穿衣服那么简单.
概要
用户应该拥有访问和删除他们共享到网络上数据的权利, 这是多数数据安全法和隐私保护法中规定的权利.
不过现实是这个权利通常不能得到保障, 而在AI时代, 机器学习的广泛应用更是加剧了这个问题, 因为一个用数据训练好的模型会记住相关数据. 此外一些成功的模型攻击技术也会泄露模型中的数据导致用户隐私泄露的风险, 因此模型遗忘是一个必要的需求.
本文提出一种模型遗忘框架, 简称SISA. 这个框架通过策略性限制数据点在训练过程中的影响来加快模型遗忘训练. 同时这个遗忘框架可以应用于所有的学习算法(*), 特别是状态算法比如 stochastic gradient descent for deep neural networks. 优势包括跨数据集的遗忘操作, 分布式用户遗忘申请, 而且会将这些因素考虑到遗忘策略中进一步降低遗忘成本.
模型的测试数据集包括了不同的领域, 如Purchase, SVHN, ImageNet; 而且遗忘带来的精度下降很小. 本文工作可以实际应用于数据管理业务.
导论
最近颁布的法案General Data Protection Regulation (GDPR) in the European Union, the California
Consumer Privacy Act [6] in the United States, and PIPEDA privacy legislation in Canada [7] include provisions that require the so-called right to be forgotten [8].要求用户拥有删除自身数据的权利. 由此用户数据在ML中的遗忘被提上研究日程.
不同于 ε − ε- ε−differential的隐私保护机器学习, 机器遗忘学习的需求是正交于前者的. 前者保证用户数据对训练模型的贡献维持在一个小的水平, 但不是完全没贡献, 而后者要求一个数据点对模型训练的影响完全降为0. 所以模型遗忘和差分隐私的研究是不相关的.
先前的工作表明模型遗忘可以通过以特定顺序的训练数据交给模型来实现, …
重新训练是一种比较幼稚的遗忘学习方法, 代价就是时间和计算开销巨大. 而遗忘学习是要实现遗忘之后的模型和不用这个数据点训练的模型有一样的状态效果.

这是一个高严格要求的定义, 不同于防止投毒攻击的遗忘定义, 这个定义要求彻底的遗忘.
简单了解一下投毒攻击和对抗样本https://www.secrss.com/articles/3417
Sharded, Isolated,Sliced, and Aggregated training, SISA框架

主要思想: 将训练集分为shards, shards中分为slices, 对于每个slice训练之后记录model parameters, 每个数据点被划分到不同的shards和slices中, unlearn时就是排除掉对应数据点然后retrain对应的shard和slices, 以空间开销换取训练的时间开销.
对比完全重训练和部分重训练的baseline, SISA实现了准确性和时间开销的权衡. 首先在简单学习任务中, 对比第一个baseline, 在Purchase上是4.63x, SVHN上是2.45x, 对比第二个baseline, 虽然SISA时间开销降低很多, 但是精度也大幅下降.
接着在复杂学习任务中, 也有同样的问题, 而且精度下降更多.
加速效益只在遗忘请求小于3倍的shards数目时存在, 而且对于复杂任务shards越多, 精度下降越大, 但是对slices没有这个规律, slices始终都提供加速效益. 而对于分布式遗忘请求, 如果将分布因素考虑进来, 可以在简单训练任务中实现极小的精度下降效果.
contributions
- formulate a new, intuitive definition of unlearning.
- introduce SISA training, a practical approach for unlearning that relies on data sharding and slicing to reduce the computational overhead of unlearning
- analytically derive the asymptotic reduction in time to unlearn points with sharding and slicing
- sharding and slicing combined do not impact accuracy significantly for simple learning tasks
- For complex learning tasks, we demonstrate that a combination of transfer learning and SISA training induces a nominal decrease in accuracy
challenges
- limited understanding of how each data point impacts the model
- Stochasticity in training
- Training is incremental
- Stochasticity in learning
总结起来, 挑战性主要来自数据点对模型的影响的理解缺失, 模型的增量训练过程, 和训练数据集sample和学习算法的随机性

上图中说明了遗忘难题, 假设一个model初始状态是 M A M_A MA, 加入一个新的数据点 d u d_u du后, 训练得到 M B M_B MB, 这时我们想要遗忘掉 d u d_u du回退到 M A M_A MA的状态, 如果没有记录之前的parameters的话, 这是不可能的! 而可行的做法就是要么 M A M_A MA全盘retrain到 M C M_C MC, 要么 M B M_B MB部分retrain到 M C M_C MC两种方法. (感觉现实非常的悲观)
unlearning 定义
Formalizing the Problem of Unlearning
以一种博弈形式定义遗忘问题, 两种角色, 服务提供者S, 用户U, 当用户revoke data的时候, S应该modify model M得到 M ¬ d u M_{\neg d_u} M¬du, 然后应该让用户相信这个 M ¬ d u M_{\neg d_u} M¬du和完全重训练得到的模型一样.

两个方面
(1) 相同数据集训练的模型不一定完全相同
(2) 只需要能够证明去掉数据点后的distribution of models和基于去掉数据点训练集进行完全重训练的distribution of models不可区分就满足遗忘要求
六个目标
(1) 易理解性: 应该让unlearning的目标通俗易懂
(2) 可比较的准确度: unlearned的模型进度下降对比baseline应该在小范围内
(3) 遗忘的时间开销小: 应该比baseline训练时间少
(4) 可证明的保证: unlearning策略进行遗忘后, 应该可以被证明确实达到遗忘目标
(5) 模型不可知: 对于不同模型遗忘策略都适用
(6) 有限开支: 任何遗忘策略不应该给机器学习过程添加过多负担
已有的解决方案
(1) Differential Privacy: 差分隐私不能完全消除遗忘数据点的影响
(2) Certified Removal Mechanisms: 只能适用简单模型, 复杂非线性模型
(3) Statistical Query Learning: 顺序数据集训练, 但是时间开销比较大, 而且不适用复杂模型
(4) Decremental Learning: 从data-protection角度看问题, 定义了一个完全数据删除的通用方式, 但是没有得到检测是否适用于各类模型
SISA 系统
模型框架

简单来说, SISA就是分割dataset和model的一种训练模式, 每个model用一个分割的dataset进行训练, 每个model又按slices分割子数据集, 进一步减少遗忘的代价, 每个model训练完成后将执行融合然后输出预测结果, 这里拆开模型是为了降低遗忘代价, 但是必然会损失精度, 模型效果随着shards的增加而下降, 如果想要提高精度, 又需要付出遗忘代价, 所以需要在两者之间寻求平衡
SISA不适用情形: decision tree learning
决策树根据一个特征划分数据集的指标如Gini impurity来添加特征, 因此一个slice被添加时, 树结构就要重建. slice方法对决策树学习不适用
techniques
(1) Sharding: 假设用户u的数据点只被包括在一个shard中, 这样unlearning的开销更小, baseline是分布式训练的 D \ d u D \backslash d_u D\du的model, 因为虽然shards可以分布式训练, 但是不排除单个dataset也可以分布式训练, 所以这个baseline要对标用去除 d u d_u du数据点的数据集分布式训练的model, 即使如此, 这个baseline的时间开销依然是远远高出SISA的
(2) Isolation: 每个shard是相互独立的, 因此model总体泛化性(generalization ability)必可避免会下降, 但是恰当选择shards的数量可以在某些学习任务中避免这个缺陷
(3) Slicing: 每个shard再划分为R个slices, 每个slices相互独立, 每个slice记为 D k , i D_{k, i} Dk,i. 模型按以下过程训练

每个slice是递增式训练, 按每个 e i e_i ei的epochs递增训练集进行训练, 为了平衡每个slice的训练时间, 设 e i e_i ei是训练 i D R \frac{iD}{R} RiD个样本的epochs数量, 假设每个 e i = e / R e_i = e / R ei=e/R, e ′ e' e′是不划分slice时的训练epochs, 则可以估计划分的训练时间为
e ′ D = ∑ i = 1 R e i i D R ≡ e = 2 R R + 1 e ′ e^{\prime} D=\sum_{i=1}^{R} e_{i} \frac{i D}{R} \equiv e=\frac{2 R}{R+1} e^{\prime} e′D=i=1∑ReiRiD≡e=R+12Re′
(4) Aggregation: 聚合目标是结合每个分布式模型提高整体预测准确性, 并且应该不包括训练集数据, 否则遗忘就要涉及到聚合部分, 最后输出结果由每个子模型的输出结果按相同权重综合决定
论文考虑训一个controller model动态调整每个子模型的权重, 但是结果表明精度提升和付出的代价性价比过低, 所以放弃这个想法.
challenges
(1) Weak Learners: 分割数据集进行训练不可避免会导致model效果下降
(2) Hyperparameter Search: 每个子model需要统一Hyperparameter, 并且选择初始化的参数很重要
时间复杂度
经过测试得到遗忘数据点和retrain时间成线性关系, 测试的数据集为SVHN, Purchase
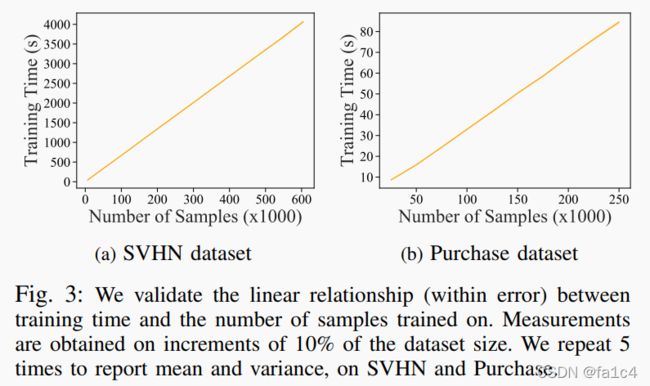
分析sharding和slicing的时间开销, 分两种情况, 1)遗忘请求按顺序到达, 2)遗忘请求打包到达
| conditions | sharding | slicing |
|---|---|---|
| sequential | E [ C ] = ( N S + 1 2 S − 1 ) K − K 2 2 S \mathbb{E}[C]=\left(\frac{N}{S}+\frac{1}{2 S}-1\right) K-\frac{K^{2}}{2 S} E[C]=(SN+2S1−1)K−2SK2 | E [ C ] = E [ ∑ i = r R 2 e ′ R + 1 i D R ] = e ′ D ( 2 3 + 1 3 R ) \mathbb{E}[C]=\mathbb{E}\left[\sum_{i=r}^{R} \frac{2 e^{\prime}}{R+1} \frac{i D}{R}\right]=e^{\prime} D\left(\frac{2}{3}+\frac{1}{3 R}\right) E[C]=E[∑i=rRR+12e′RiD]=e′D(32+3R1) |
| batches | E [ C ] = N ( 1 − ( 1 − 1 S ) K ) − K \mathbb{E}[C]=N\left(1-\left(1-\frac{1}{S}\right)^{K}\right)-K E[C]=N(1−(1−S1)K)−K | E [ C ] = 2 e ′ D R ( R + 1 ) ( R ( R + 1 ) 2 − 1 2 ( E [ r min 2 ] − E [ r min ] ) ) \mathbb{E}[C]=\frac{2 e^{\prime} D}{R(R+1)}\left(\frac{R(R+1)}{2}-\frac{1}{2}\left(\mathbb{E}\left[r_{\min }^{2}\right]-\mathbb{E}\left[r_{\min }\right]\right)\right) E[C]=R(R+1)2e′D(2R(R+1)−21(E[rmin2]−E[rmin])) |
实验测试
实验要测试四个方面
(1) sharding对精度的影响
(2) slicing对精度的影响
(3) SISA对retrain时间的改进效果
(4) 上面的指标/效果对简单模型和复杂模型的差别
对照两组baseline
(1) batch K
(2) 1/S

实验用到的数据集有以下
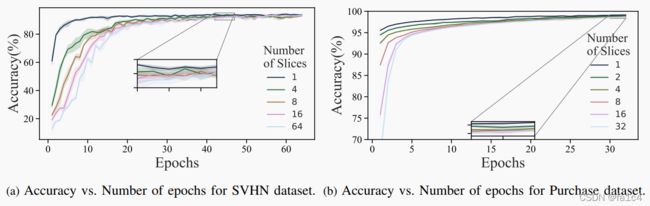
遗忘请求数, 时间开销, 模型精度

slice数量和精度
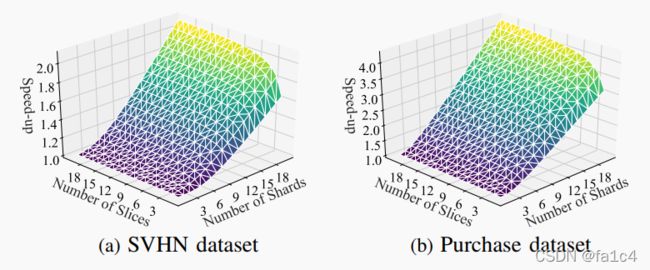
shards数量和精度

slices和shards结合, 与精度
引入transformor时的精度与shards数量

总结
SISA的原理总结起来就是分布式训练 + 集成学习
集成学习采用增强算法甚至是集成神经网络, 提高模型精度
改进方法
(1) 数据重复(data replication)
合理选择数据点, 增大训练集, 以此提高模型精度
不过要求这些数据点被请求遗忘的概率要尽可能小
(2) core dataset
不是全部数据都有用, 选择重要的数据子集core dataset
后话
SISA的开源代码似乎是有BUG, 没调试出来
如果要做论文方案复现, 其实也不算特别难, sharding 和 slicing机制大部分工作都是数据预处理, 切分好数据集就可以依次投喂训练模型了.