多云数据存储,理想与现实之间还差着什么?
去年底,“数据二十条”正式颁布,数据要素全面提速已是指日可待。
无疑,数据作为数字经济的基础,其价值的释放依赖于数据的流动、共享和应用。数据要素只有充分地流动和应用起来,才能够实现价值的最大化。
换而言之,进入多云时代的用户们,数字化转型已然迈入纵深阶段,业务侧用数的及时性和灵活性大幅提升,这也促使了数据的“双循环”出现:数据在内部能够很好地拉通、流动、共享和管理,数据对外需要与各大公有云服务商对接、流动与应用。
这一切使得多云数据存储成为今年以来市场的热门话题。那么,企业上云和用数面临着哪些重要挑战?多云数据存储有着哪些新趋势?哪些存储能力是用户未来不可忽视的?近日,信通院携手云计算与数据存储厂商联合发布了《多云数据存储白皮书》(以下简称:《白皮书》),全面分析了当前多云数据存储所面临的挑战与未来发展趋势,为企业多云时代的用数带来了一份绝佳参考指南。

多云时代,企业用数有这些拦路虎
多云环境正在成为越来越多用户的标配。根据混合云产业推进联盟的数据显示,我国已经有88.7%的用户选择了多云架构。
多云之所以获得用户们的青睐,究其原因,主要是它可以取长补短,最大限度匹配业务对于灵活性的需求,同时实现成本最优化;此外,多云还能实现多元供应体系,减少对单一云平台的过度依赖和提升云环境的容错率,避免因为故障导致全线业务崩塌,保障业务连续性。
作为多云架构中数据资源的载体,多云数据存储肩负着数据要素的传输、处理、存储和应用等多个环节,在数据要素价值释放中扮演着极为重要的角色。因此,随着数据要素化全面提速,多云数据存储的重要性也得以凸显。
不过,理想很丰满,现实就有多骨感。就在多云数据存储蓬勃发展之际,市场参与者众多、烟囱式的建设方式以及对于上云应用适配不足,使得数据流动有限、壁垒众多,无形中成为企业上云和用数的拦路虎、绊脚石。
《白皮书》就指出,多云时代,企业在上云用数主要面临五大挑战:多云数据流动难、跨云数据共享难、多云应用改造难、数据安全保护难和数据应用能效低五大挑战。
比如,很多企业用户都面临着多云数据流动难的情况,尤其是跨云流动的数据多样性还很不足。众所周知,当前很多企业的多云环境往往是:私有云+多个公有云+边缘侧的组合,企业往往根据不同应用的不同特点,将应用部署到最合适的环境之中,但却面临着跨云数据一致性难以保障、数据跨云流动耗时低效、数据难以跨企业应用、跨数据存储类型流动等问题。

另外,跨云数据共享难也是当前众多用户面临的一大难题。由于每家云服务商在应用接口、数据交换标准、技术采用上存在着差异,所以天然在生态上难以互通、跨云调用数据难度大,多云之间数据共享等互操作性难度大且成本高昂。
以某零售企业为例,它自身在本地私有云环境部署了传统的数据仓库应用,而营销团队可能在A云上正在使用某款云数据仓库应用来做个性化营销,而数据科学团队则可能在B云上正在进行其他模型的机器学习训练,一旦出现新项目需要共享多云之间的数据,就会遇到数据可移植性和互操作性的难题,跨云数据共享难度可见一斑。
因此,数据存储作为云的数据底座,肩负着多云数据自由流动、高效共享与应用的重任,未来必然会被所有上云用数的企业所倚重,成为他们数字化转型中的坚实底座。
这些多云数据存储趋势不容忽视
今天,大多数企业均会与多个云服务商合作,数据通常分散在不同的地方,数据可能存放在数据存储厂商的存储系统之中,可能放在公有云服务商的云存储之中,还可能存放在边缘侧的超融合系统之中,技术栈极为复杂且管理困难,很容易造成更多的数据孤岛。
因此,《白皮书》认为,多云环境下第一个最为迫切的重要趋势就是面向多云构建统一的数据底座,以消除跨云数据共享的难度,让跨云数据共享不再成为难事。这其中,构建全局数据视图又至关重要,以数据为中心,基于统一元数据构建全局命名空间提供统一数据视图,通过全局数据视图和广域网络,实现数据跨云、跨域、跨服务商共享。
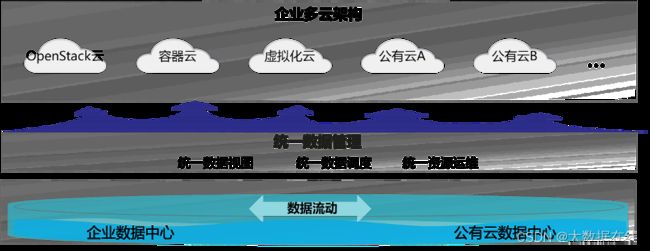
例如,在超算云环境中,数据密集型科研场景的大量涌现,很多超算用户常见的情况是:在数据中心C进行AI训练,但数据源来自于数据中心A和B,数据中心A和B还需要对训练结果数据实时可见和按需访问。借助跨域全局文件系统实现统一数据视图,超算用户可以实现跨云/数据中心的数据共享,更加高效完成各种超算任务。
《白皮书》认为,多云环境中第二个重要的趋势就是多云环境数据流转、数据分类分级将是常态,企业需要增强的智能分级存储能力,从而使能数据跨云流动。众所周知,数据的智能分级多年前已经在存储系统中出现,当时由于闪存价格昂贵,存储系统利用分级技术实现冷热数据的流动,从而在性能、成本、容量等方面实现最优。
如今,这种智能数据分级存储能力需要进一步进化与演进。多云环境中,企业的数据规模、数据类型、数据分布、数据保护等级、应用类型等均远胜过往,多样化应用对数据存储有着不同的需求,数据不仅仅需要在存储系统内部不同介质之间流动,还需要在不同存储系统,甚至跨云之间实现全生命周期的流转。
所以,企业需要增强基于策略的数据智能分级流动能力。在多云环境中,利用基于数据存储的分级、复制等技术,实现企业多云数据中心之间、不同类型数据存储之间基于策略的数据分级流动,以实现跨云数据复制,数据迁移,数据备份等。
例如,很多企业级存储系统均有网关功能,可以与公有云进行对接,将数据复制或者备份到公有云之中,不仅实现了存储容量、成本的最优,还能利用公有云实现数据保护与容灾。
《白皮书》认为,在多云环境中,云边协同的场景会越来越多,随着云边协同不断深入,边缘IT基础设施会加速向功能齐全、集成度高和宽环境适配的超融合架构演进,来实现资源协同、应用协同、数据协同、智能协同、管理协同五大云边协同。
事实上,当前在很多行业中,云边协同场景成为常态,像无人驾驶、智慧矿山、智能交通、智慧零售、智慧能源等均是典型的云边协同。这种场景往往是典型的智能化应用场景,会综合运用到云计算、物联网、大数据、人工智能等多种技术,边缘侧环境复杂、并且会持续产生大量数据,需要将边缘侧数据传输到云端进行人工智能模型训练,然后再将模型下发到边缘侧运行。
例如,在很多智慧风电场景中,规模通常能达到上千甚至上万台风机,一个风机具备2000个以上的检测点,检测点每天产生的数据量能够达到PB级别,在云端集控中心的工业大数据平台需要不断收集海量数据进行训练和迭代各种算法模型,然后将运维预警模型下发到边缘侧,对于边缘侧的基础设施的功能、性能、环境适配等要求越来越高。
除了这三大趋势之外,《白皮书》认为,多云数据存储还需要加快面向容器演进,从而助力应用云化改造;加快部署安全可信数据存储,从而加强多云数据安全;推动介质节能、算法节能等数据存储高效节能技术,从而实现绿色低碳发展。
《白皮书》倡议:推动多云数据产业发展
如今,业界普遍认为多云不是云发展过程中的一个临时阶段,而是企业基础设施的一种新常态,未来将持续在企业数字化转型中发挥着关键作用。
多云数据产业由于存在着大量的市场参与者,既有各种云服务商,还有广大传统企业级存储厂商,更有一些边缘设备、安全厂商,虽然技术路径、产品侧重点各有不同,但大家普遍意识到,“各自为政”的思维愈发不符合用户在多云时代的用数需求,加强多云数据产业建设,不断完善产业生态,实现数据自由流动、数据高效共享是产业发展的必然趋势。
为此,《白皮书》联合产业界发出了三大倡议:
首先,继续完善多云数据存储能力,持续促进数据共享、跨云自由流动。数据存储层最适合解决数据自由流动的难题,虽然当前云服务提供商和数据存储厂商已经有了很多合作,在数据互通、数据灾备和数据服务等方面实现不小突破,但未来需要加大合作力度,消除更多障碍,让多云数据交互安全、可信,从而在业务中产生更大价值。
其次,多云数据存储需要联合更多行业用户进行创新实践,助力行业推广应用。像金融、政府、交通、能源、零售等行业均在向多云环境演进,典型应用实践很容易形成推广效应,在该案例所属行业中起到带头作用,有利于多云数据创新在不同行业中的推广与应用。
第三,继续构建与完善多云数据互联互通标准,搭建产业合作平台,构建开放的数据流动环境。当前,多元环境中各大厂商虽然实现了一定程度的互联互通,但是行业标准的建设尚处于早期阶段。行业标准是行业通用语言,也是产业长期发展的基础。未来,需要围绕实际应用场景,联合产、学、研、用各方,通过业界优秀实践孵化行业标准,推动多云数据存储产业良性发展。
总体而言,随着企业上云与用数成为大势所趋,多云数据存储也面临着产业发展的关键时刻,解决数据流动、数据共享等难题已经迫在眉睫,这不仅仅需要产业界在技术、产品与解决方案上持续创新与突破,更需要产、学、研、用各方构建起良性生态,让多云数据存储真正成为释放数据价值的“助推器”。