ICASSP 2022 | 标点恢复——一套可以同时服务单模态和多模态文本的标点恢复框架
导读
在信息时代,自动语音识别技术 (Automatic Speech Recognition, ASR) 已成为互联网领域一大典型应用,尤其是在智能手机等设备上,语音识别功能已经成为标配。同时,该技术本身还经常作为上游工具,为语音翻译、智能客服等服务提供支持。然而,现今主流的自动语音识别系统是把语音信号识别为无标点的文本块,而这种无标点的本文块往往不能有效地被下游系统利用,由此,标点恢复(punctuation restoration) 任务应运而生,旨在恢复语音识别系统输出文本的标点符号。
今天为大家介绍一篇收录于 ICASSP 2022 的论文:Unified Multimodal Punctuation Restoration Framework for Mixed-Modality Corpus,由字节跳动人工智能实验室完成。本论文提出了一套适用于标点恢复的多模态框架 UniPunc:一方面,新框架可以使用语音信息辅助标点恢复;另一方面,UniPunc 又避免了以往多模态标点恢复模型过分依赖语音信息、无法处理语音缺失文本的困境。

论文链接:https://arxiv.org/abs/2202.00468
代码链接:https://github.com/Yaoming95/UniPunc
标点恢复:从单模态到多模态
以往的标点恢复模型可以分为单模态和多模态两类:简单而言,单模态模型仅依赖纯文本信息做标点恢复,而多模态模型会同时接受文本与其对应的语音信号,联合两种输入做标点恢复。
两类标点恢复模型各自面临一定的局限性:
对于单模态模型而言,由于人类语言天然带有歧义性,许多句子可能存在多种标点断句的方式,而不同的标点会带来大相径庭的句义——对此,英国作家琳恩·特拉斯曾举过一对生动的例子:panda eats shoots and leaves(熊猫吃嫩芽和叶片)与panda eats, shoots, and leaves(熊猫吃饭、开枪、并离开)。此外,由于不涉及语音信息,单模态模型时常无法获知说话人的情感态度,这会导致模型在一些句子末尾难以抉择以句号还是问号作为结束符。

图1:琳恩·特拉斯所举的标点歧义例句,她还基于这个生动的例子写作了一本畅销书[1]以引导公众对于标点符号的重视
对于多模态模型而言,线上应用有时会面临存储空间或隐私政策等限制,导致模型不能获取语音信息,进而无法提供标点恢复后的语句。此外,与单模态模型仅使用纯文本相比,多模态系统需要收集带有语音的句子作为训练语料,而这类语音句子的获取需要更大的人力成本,因此,多模态系统可用的训练资料相对更少。
使用一个框架联合单模态和多模态语句
UniPunc 论文作者提出了一套新框架,这套框架可以同时处理混合了单模态纯文本与多模态语音文本的语料,并同时为两种语句恢复标点。具体地,该框架可以拆分为三大部分:文本编码器、声学助理器和模态融合器。图2 展示了其总架构。

图2:UniPunc 总架构
:::
文本编码器把无标点的文本句子的信息编码成句嵌入向量,并将其作为文本特征输出给下游的模块。本文作者使用了目前流行的 BERT 预训练模型[2]作为文本编码器的主干。
声学助理器则会按照句子是否带有语音信息来提供不同的音频特征。对于有音频的句子,声学助理器会通过预训练的音频表征模型[3]将其转换为神经网络可以输入的特征编码,同时,考虑到音频的长度(通常每秒16000-40000个采样点)往往远长于文本语句(通常每秒1-3词),作者还引入了一个下采样网络缩短音频特征;对于无音频的纯文本,作者则引入了一个虚拟嵌入机制来模拟其特征。
模态融合器则来完成跨模态融合,将文本特征和音频特征融合为混合特征以供下游的分类器进行标点分类。具体地,作者利用了类注意力机制的网络结构,分别引入了自注意力和交叉注意力的子网络,其中自注意力子网络用来进一步提取文本特征,交叉注意力子网络用于融合文本特征和音频特征。根据注意力网络的性质,二者输出的特征矩阵大小相同,作者对其做了加和操作。值得一提的是,模态融合器和其他类注意力机制的网络一样,可以叠加多层以加强网络效果。
在两类模态下都可以提升性能
作者在 MUST-C [4]和 Multilingual TEDx [5]两个真实环境的语音语料库上进行了实验,二者的语音及文本都来源于TED演讲集。为了分别体现 UniPunc 在单模态、多模态场景下的性能,作者利用语音语料库分别构建了两个新的数据集,分别称为 English-Audio 和 English-Mix ,其中前者所有语句包含音频,而后者的则是混合了音频语句和无音频文本。
论文选取了多个单模态(如BERT,SAPR[6]),多模态 (如MuSe[7]、TTS数据增强[8]) 的SOTA模型作为实验的比较基线,其中多模态模型仅在 English-Audio 数据集上进行训练,因为它们不支持纯文本的处理,单模态模型则在两种数据集上进行实验作为基线结果。
作者在多模态数据集 English-Audio 和混合模态数据集 English-Mix 下训练了两套 UniPunc 模型,分别记作 UniPunc-Audio 和 UniPunc-Mix ,以方便和单模态基线、多模态基线做全面对比。论文采用了句号、逗号、问号三种标点恢复的准确率、召回率以及F1分数作为评价指标。下图展示了作者的实验结果:

图3:UniPunc主实验结果
:::
主要结论有以下三点:
-
UniPunc-Mix 能取得最后的标点恢复效果,证明了新框架的有效性;
-
在不引入单模态数据的情况下,仅使用 English-Audio 训练的 UniPunc-Audio 也在性能上超越了SOTA多模态基线;
-
在有音频的测试数据上,UniPunc-Mix 的效果略好于 UniPunc-Audio,作者调查发现,加入的单模态纯文本主要提升了 UniPunc-Mix 标点恢复的召回率。
作者还使用论述了 UniPunc 框架具有一定的普适性:通过把 UniPunc框架嫁接到传统的单模态基线 BiLSTM 上,或者是把它和 contextual dropout 方法[9]联合使用,它都可以继续提升原模型或者原方法的性能:
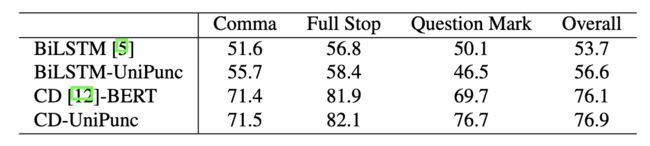
图4:UniPunc普适性实验结果
:::
总结
今天介绍的 ICASSP 2022 论文引入了一种新的多模态标点恢复框架 UniPunc,与传统的标点恢复模型相比,UniPunc 结合了单模态模型和多模态模型的优点,且可以在混合模态的数据上进行训练和推理。
作者在来源TED演讲集的数据上进行了实验,证明了 UniPunc 的性能优势,以及它对混合模态数据处理的普适性。
参考文献
[1]Truss, Lynne. Eats, shoots & leaves: The zero tolerance approach to punctuation. Penguin, 2004.
[2]Kenton, Jacob Devlin Ming-Wei Chang, and Lee Kristina Toutanova. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” In NAACL-HLT 2019.
[3]Baevski, Alexei, et al. “wav2vec 2.0: A framework for self-supervised learning of speech representations.” In NeurIPS 2020.
[4] Cattoni, Roldano, et al. “MuST-C: A multilingual corpus for end-to-end speech translation.” Computer Speech & Language 2021.
[5] Salesky, Elizabeth, et al. “The Multilingual TEDx Corpus for Speech Recognition and Translation.” In Interspeech 2021.
[6] Wang, Feng, et al. “Self-attention based network for punctuation restoration.” In ICPR, 2018.
[7] Sunkara, Monica, et al. “Multimodal Semi-Supervised Learning Framework for Punctuation Prediction in Conversational Speech.” In Interspeech 2020.
[8] Soboleva, Daria, et al. “Replacing human audio with synthetic audio for on-device unspoken punctuation prediction.” In ICASSP 2021.
[9] Silva, Andrew, Barry-John Theobald, and Nicholas Apostoloff. “Multimodal Punctuation Prediction with Contextual Dropout.” In ICASSP 2021.
-The End-
关于我“门”
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门-TechBeat技术社区(https://datayi.cn/w/GR4vQ82o)以及将门创投基金。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”: