python处理excel(数据分析)
此脚本使用openpyxl库对excel进行操作。
主要功能
此库主要的功能有四个:
- 导入excel表:使用函数load_workbook即可,如
workxls = load_workbook('work.xlsx')
- 读取表:先使用sheetnames字段值取得所有sheet名,然后根据sheet名取得该sheet。然后可以通过cell函数指定row与column取得值(value),如:
sheetnames = workxls.sheetnames
for sheetname in sheetnames:
sheet = workxls.get_sheet_by_name(sheetname)
for i in range(1,workxls.max_row+1):
for j in range(1,workxls.max_column+1):
print(sheet.cell(row=i, column=j).value)
- 写入表:同样使用的是cell函数,通过设定value值即可更改表中的值,如:
sheet.cell(row=6, column=6, value=6)
- 保存更改:使用save函数,指定文件名即可保存,如:
workxls.save('result.xlsx')
注意事项:
- max_row与max_column是取得sheet中数据的最大行与最大列数,但是有时是不准的,因为有的是空行/列,这时,还是手动输入的好。
- 读取合并格时将最左上的格读成该合并格的值,其他为None。
数据分析
读取excel表中的数据是要进行分析的,这时候首先应该做的是如何保存分析数据,以谁作为键,以谁作为值,是以sheet名分多个部分存储还是合在一个里面。不仅如此,使用字典还是列表等存储方式也会对数据的分析造成影响。
这里我使用字典进行存储,因为主要任务是对数据指标进行排序,然后输出对应排序结果的城市名称,所以我以数据指标作为“大”键,创建字典,然后以“城市:指标值”进行存储。
字典的排序
这个部分花了我很长时间,先说说排序正确格式:
dict={'广州': 0.63385324750839, '深圳': 1, '佛山': 0.4214618485089, '东莞': 0.121729284191413, '北京': 0.472064389109345, '上海': 0.435534382682676, '杭州': 0.497954686878373, '苏州': 0.693492027869304, '南京': 0.543267808505646, '成都': 0}
# 首先要将字典用items函数做成元组,然后用Key=?指定排序的数据,使用reverse决定升序降序
print(sorted(dict.items(),key=lambda dict:dict[1],reverse=True))
再说说我的历程:
首先我是使用最简单的排序:
sorted(dict,reverse=True)
这个代码在这种情况下输出结果正确:
dict={"3":3,"1":1,"2":2,"4":4}
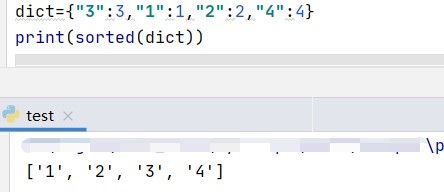
但是在这种情况下结果错误:
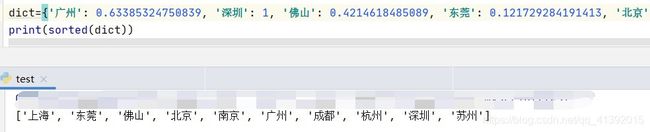
奇了怪,然后查了很久才查到正确的代码。
示例代码:
from openpyxl import load_workbook
workxls = load_workbook('work.xlsx')
sheetnames = workxls.sheetnames
xlsval = dict()
for sheetname in sheetnames:
xlsval[sheetname]=dict()
sheet = workxls.get_sheet_by_name(sheetname)
mrow=17 # 手动输入比使用max_row值更好,因为,鬼知道那个xls的行列到底是多少行,有的没有值也算,离谱
mcol=11
startwr = 19
sheet.cell(row=startwr, column=1,value="指标")
citydict=dict()
for i in range(2, mcol+1):
sheet.cell(row=startwr, column=i, value=sheet.cell(row=2,column=i).value)
citydict[sheet.cell(row=2,column=i).value]=0
startwr+=1
for i in range(3,mrow+1):
xlsval[sheetname][sheet.cell(row=i,column=1).value]=dict()
for j in range(2, mcol+1):
xlsval[sheetname][sheet.cell(row=i, column=1).value][sheet.cell(row=2,column=j).value]=sheet.cell(row=i,column=j).value
sortdict=xlsval[sheetname][sheet.cell(row=i, column=1).value]
# 首先要将字典用items函数,然后用Key=?指定排序的数据,使用reverse决定升序降序。
sortlist = sorted(sortdict.items(),key=lambda sortdict:sortdict[1],reverse=True)
sheet.cell(row=startwr, column=1, value=sheet.cell(row=i,column=1).value)
for i in range(0,len(sortlist)):
citydict[sortlist[i][0]]=i+1
colindex=2
for key in citydict.keys():
sheet.cell(row=startwr, column=colindex, value=citydict[key])
colindex+=1
startwr+=1
workxls.save('result.xlsx')