MuQSS调度器之调度器初始化(三)
MuQSS调度器
基于前两篇介绍MuQSS调度器的文章:
- MuQSS调度器之设计文档(一)
- MuQSS调度器之跳表分析(二)
本文开始分析MuQSS调度器到底是如何工作的。
初始化
MuQSS调度器初始化代码流程大体如下:
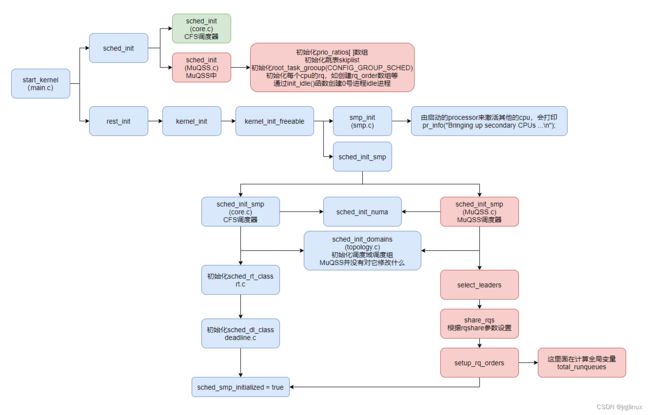
sched_init()
MuQSS.c中定义了调度器初始化函数,主要作用:
- 定义prio_ratios数组,后面计算task deadline时需要用到
- 初始化0号进程init_task的跳表节点
- 初始化每个cpu的rq队列,其中last_jiffy就是jiffies值,clock等都为0
- 多处理器情况下初始化cpu的rq中和负载相关的字段
- 将0号进程init_task变为idle进程
void __init sched_init(void)
{
[...省略代码...]
prio_ratios[0] = 128;
for (i = 1 ; i < NICE_WIDTH ; i++)
prio_ratios[i] = prio_ratios[i - 1] * 11 / 10; //优先级比率数组
skiplist_node_init(&init_task.node); //初始化init_task的跳表skiplist节点
[...省略代码...]
/******************************初始化每个cpu的rq************************************/
for_each_possible_cpu(i) {
rq = cpu_rq(i);
rq->node = kmalloc(sizeof(skiplist_node), GFP_ATOMIC);
skiplist_init(rq->node);
rq->sl = new_skiplist(rq->node);
rq->lock = kmalloc(sizeof(raw_spinlock_t), GFP_ATOMIC);
raw_spin_lock_init(rq->lock);
rq->nr_running = 0;
rq->nr_uninterruptible = 0;
rq->nr_switches = 0;
rq->clock = rq->old_clock = rq->last_niffy = rq->niffies = 0; //初始clock为0
rq->last_jiffy = jiffies; //这里记录的是jiffies值
[...省略代码...]
}
/**********************多处理器下初始化每个cpu的rq中和负载均衡相关字段*******************************/
#ifdef CONFIG_SMP
cpu_ids = i;
/*
* Set the base locality for cpu cache distance calculation to
* "distant" (3). Make sure the distance from a CPU to itself is 0.
*/
for_each_possible_cpu(i) {
int j;
[...省略代码...]
for (j = 1; j < cpu_ids; j++)
rq->rq_order[j] = rq->cpu_order[j] = cpu_rq(j);
}
#endif
[...省略代码...]
/*
* Make us the idle thread. Technically, schedule() should not be
* called from this thread, however somewhere below it might be,
* but because we are the idle thread, we just pick up running again
* when this runqueue becomes "idle".
*/
init_idle(current, smp_processor_id()); //将0号进程(init_task)变为idle进程,comm里打印的是MuQSS...
[...省略代码...]
}
优先级比例prio_ratios[]
MUQSS中定了了prio_ratios[40],nice值为0对应的prio_raios值为128。
prio_ratios[0] = 128;
for (i = 1 ; i < NICE_WIDTH ; i++)
prio_ratios[i] = prio_ratios[i - 1] * 11 / 10; //优先级比率数组

如果不看基数128,只看系数1.1,其根据nice宽度值的曲线如下:
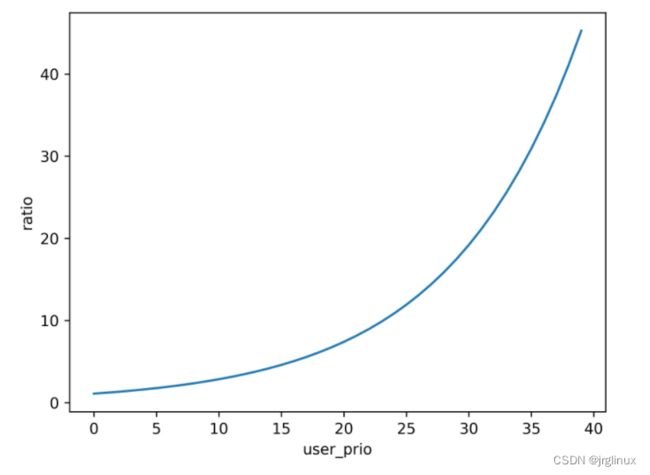
可以看出其设计思想:
- 进程的优先级越低(nice值越大),其计算deadline的系数越大,且系数曲线导数是增大的。
调度域基础概念
参考这篇博文:Linux内核的进程负载均衡机制
所有CPU一共分为三个层次:SMT,MC,NUMA,每层都包含了所有CPU,但是划分粒度不同。根据Cache和内存的相关性划分调度域,调度域内的CPU又划分一次调度组。越往下层调度域越小,越往上层调度域越大。进程负载均衡会尽可能的在底层调度域内部解决,这样Cache利用率最优。
从分层的视角分析,每层都有per-cpu数组保存每个CPU对应的调度域和调度组,它们是在初始化时已经提前分配的内存。值得注意的是
- 每个CPU对应的调度域数据结构都包含了有效的内容,比如说SMT层中,CPU0和CPU1对应的不同调度域数据结构,内容是一模一样的。
- 每个CPU对应的调度组数据结构不一定包含了有效内容,比如说MC层中,CPU0和CPU1指向不同的struct sched_domain,但是sched_domain->groups指向的调度组确是同样的数据结构,这些调度组组成了环。
每个CPU的进程运行队列有一个成员指向其所在调度域。从最低层到最高层。
我们可以在/proc/sys/kernel/sched_domain/cpuX/ 中看到CPU实际使用的调度域个数以及每个调度域的名字和配置参数。
cpu位置以及rq共享
MuQSS中的rq->cpu_locality[]数组记录了cpu之间的"locality属性距离大小"。rq->cpu_order[]中记录cpu的排序,rq->rq_order[]数组记录rq的排序。
/* Define RQ share levels */
#define RQSHARE_NONE 0
#define RQSHARE_SMT 1
#define RQSHARE_MC 2
#define RQSHARE_MC_LLC 3
#define RQSHARE_SMP 4
#define RQSHARE_ALL 5
/* Define locality levels */
#define LOCALITY_SAME 0
#define LOCALITY_SMT 1
#define LOCALITY_MC_LLC 2
#define LOCALITY_MC 3
#define LOCALITY_SMP 4
#define LOCALITY_DISTANT 5
初始化
cpu_locality[], cpu_order[], rq_order[]是在sched_init()函数中初始化的。
#ifdef CONFIG_SMP
cpu_ids = i;
/*
* Set the base locality for cpu cache distance calculation to
* "distant" (3). Make sure the distance from a CPU to itself is 0.
*/
for_each_possible_cpu(i) {
int j;
rq = cpu_rq(i);
#ifdef CONFIG_SCHED_SMT
rq->siblings_idle = sole_cpu_idle;
#endif
#ifdef CONFIG_SCHED_MC
rq->cache_idle = sole_cpu_idle;
#endif
rq->cpu_locality = kmalloc(cpu_ids * sizeof(int *), GFP_ATOMIC);
/*这里初始化cpu_locality数组,cpu相对于自己locality为0,相对于其他cpu初始值都赋值5(DISTANT)*/
for_each_possible_cpu(j) {
if (i == j)
rq->cpu_locality[j] = LOCALITY_SAME;
else
rq->cpu_locality[j] = LOCALITY_DISTANT;
}
rq->rq_order = kmalloc(cpu_ids * sizeof(struct rq *), GFP_ATOMIC);
rq->cpu_order = kmalloc(cpu_ids * sizeof(struct rq *), GFP_ATOMIC);
rq->rq_order[0] = rq->cpu_order[0] = rq; /*rq_order和cpu_order首个元素都指向该cpu自己的rq*/
for (j = 1; j < cpu_ids; j++)
rq->rq_order[j] = rq->cpu_order[j] = cpu_rq(j); /*rq_order和cpu_order从第2个至最后元素依次指向cpu1、cpu2的rq*/
}
#endif
此时,locality和cpu_order以及rq_order只是初始化,后面还会要修改:
[ 0.238872] MuQSS locality CPU 0 to 0: 0
[ 0.238903] MuQSS locality CPU 0 to 1: 5
[ 0.238915] MuQSS locality CPU 0 to 2: 5
[ 0.238924] MuQSS locality CPU 0 to 3: 5
[ 0.238958] MuQSS cpu_order CPU 0 to 0 : 0
[ 0.238978] MuQSS cpu_order CPU 0 to 1 : 1
[ 0.238988] MuQSS cpu_order CPU 0 to 2 : 2
[ 0.238996] MuQSS cpu_order CPU 0 to 3 : 3
[ 0.239037] MuQSS rq_order CPU 0 to 0 : 0
[ 0.239056] MuQSS rq_order CPU 0 to 1 : 1
[ 0.239065] MuQSS rq_order CPU 0 to 2 : 2
[ 0.239072] MuQSS rq_order CPU 0 to 3 : 3
[ 0.239086] MuQSS locality CPU 1 to 0: 5
[ 0.239095] MuQSS locality CPU 1 to 1: 0
[ 0.239102] MuQSS locality CPU 1 to 2: 5
[ 0.239110] MuQSS locality CPU 1 to 3: 5
[ 0.239130] MuQSS cpu_order CPU 1 to 0 : 1
[ 0.239137] MuQSS cpu_order CPU 1 to 1 : 1
[ 0.239145] MuQSS cpu_order CPU 1 to 2 : 2
[ 0.239153] MuQSS cpu_order CPU 1 to 3 : 3
[ 0.239161] MuQSS rq_order CPU 1 to 0 : 1
[ 0.239168] MuQSS rq_order CPU 1 to 1 : 1
[ 0.239176] MuQSS rq_order CPU 1 to 2 : 2
[ 0.239184] MuQSS rq_order CPU 1 to 3 : 3
[ 0.239191] MuQSS locality CPU 2 to 0: 5
[ 0.239199] MuQSS locality CPU 2 to 1: 5
[ 0.239207] MuQSS locality CPU 2 to 2: 0
[ 0.239214] MuQSS locality CPU 2 to 3: 5
[ 0.239222] MuQSS cpu_order CPU 2 to 0 : 2
[ 0.239229] MuQSS cpu_order CPU 2 to 1 : 1
[ 0.239237] MuQSS cpu_order CPU 2 to 2 : 2
[ 0.239245] MuQSS cpu_order CPU 2 to 3 : 3
[ 0.239252] MuQSS rq_order CPU 2 to 0 : 2
[ 0.239260] MuQSS rq_order CPU 2 to 1 : 1
[ 0.239267] MuQSS rq_order CPU 2 to 2 : 2
[ 0.239275] MuQSS rq_order CPU 2 to 3 : 3
[ 0.239283] MuQSS locality CPU 3 to 0: 5
[ 0.239290] MuQSS locality CPU 3 to 1: 5
[ 0.239298] MuQSS locality CPU 3 to 2: 5
[ 0.239305] MuQSS locality CPU 3 to 3: 0
[ 0.239313] MuQSS cpu_order CPU 3 to 0 : 3
[ 0.239321] MuQSS cpu_order CPU 3 to 1 : 1
[ 0.239328] MuQSS cpu_order CPU 3 to 2 : 2
[ 0.239336] MuQSS cpu_order CPU 3 to 3 : 3
[ 0.239344] MuQSS rq_order CPU 3 to 0 : 3
[ 0.239351] MuQSS rq_order CPU 3 to 1 : 1
[ 0.239359] MuQSS rq_order CPU 3 to 2 : 2
[ 0.239371] MuQSS rq_order CPU 3 to 3 : 3
cpu_locality[]的更新
参考select_leaders()函数中的分析,其中会涉及根据配置来更新cpu_locality[]数组。
cpu_order[]/rq_order[]的更新
参考setup_rq_orders()函数,其会更新cpu_order[]/rq_order[]数组。
初始化rqshare
通过内核boot参数“rqshare=”来传递
/*
* This determines what level of runqueue sharing will be done and is
* configurable at boot time with the bootparam rqshare =
*/
static int rqshare __read_mostly = CONFIG_SHARERQ; /* Default RQSHARE_MC */
static int __init set_rqshare(char *str)
{
if (!strncmp(str, "none", 4)) {
rqshare = RQSHARE_NONE;
return 0;
}
if (!strncmp(str, "smt", 3)) {
rqshare = RQSHARE_SMT;
return 0;
}
if (!strncmp(str, "mc", 2)) {
rqshare = RQSHARE_MC;
return 0;
}
if (!strncmp(str, "llc", 3)) {
rqshare = RQSHARE_MC_LLC;
return 0;
}
if (!strncmp(str, "smp", 3)) {
rqshare = RQSHARE_SMP;
return 0;
}
if (!strncmp(str, "all", 3)) {
rqshare = RQSHARE_ALL;
return 0;
}
return 1;
}
__setup("rqshare=", set_rqshare);
rqshare会在后面shed_init_smp()中用到,具体是在以下一些函数中涉及。
select_leaders()
cpu的拓扑结构基础概念参考:参考这里
设置每个online cpu之间的relative cache distance(相对缓存距离),用数组形式保存,便于快速查找。位置locality是由CPUs之间最近的sched_domain决定的。SMT和MC中共享cache的CPU会被当做是local CPU。同一个node中的分开的CPU不会当做是local CPU。不在同一个调度域中的CPU,会被认为很遥远distant。
static void __init select_leaders(void)
{
struct rq *rq, *other_rq, *leader;
struct sched_domain *sd;
int cpu, other_cpu;
#ifdef CONFIG_SCHED_SMT
bool smt_threads = false;
#endif
for (cpu = 0; cpu < num_online_cpus(); cpu++) { //遍历每个online的CPU
rq = cpu_rq(cpu);
leader = NULL;
/* First check if this cpu is in the same node */
for_each_domain(cpu, sd) {
if (sd->level > SD_LV_MC)
continue;
if (rqshare != RQSHARE_ALL) //只要rqshare != all, 每个domain都需要找leader
leader = NULL;
/* Set locality to local node if not already found lower */
for_each_cpu(other_cpu, sched_domain_span(sd)) {
if (rqshare >= RQSHARE_SMP) { //这个if分支指明只有smp和all两种rqshare下才会去找leader,其他情况不执行该if分支
other_rq = cpu_rq(other_cpu);
/* Set the smp_leader to the first CPU */
if (!leader)
leader = rq;
if (!other_rq->smp_leader)
other_rq->smp_leader = leader; //每个node的第一个physical cpu指向leader也就是rq
}
if (rq->cpu_locality[other_cpu] > LOCALITY_SMP)
rq->cpu_locality[other_cpu] = LOCALITY_SMP; //修改cpu_locality最大值就是4,除了cpu离自己为0,离其他cpu都是4
}
}
/*
* Each runqueue has its own function in case it doesn't have
* siblings of its own allowing mixed topologies.
*/
#ifdef CONFIG_SCHED_MC
leader = NULL;
if (cpumask_weight(core_cpumask(cpu)) > 1) { //目前通过gdb跟踪看,这里分支都没进去过
cpumask_copy(&rq->core_mask, llc_core_cpumask(cpu));
cpumask_clear_cpu(cpu, &rq->core_mask);
for_each_cpu(other_cpu, core_cpumask(cpu)) {
if (rqshare == RQSHARE_MC ||
(rqshare == RQSHARE_MC_LLC && cpumask_test_cpu(other_cpu, llc_core_cpumask(cpu)))) {
other_rq = cpu_rq(other_cpu);
/* Set the mc_leader to the first CPU */
if (!leader)
leader = rq;
if (!other_rq->mc_leader)
other_rq->mc_leader = leader;
}
if (rq->cpu_locality[other_cpu] > LOCALITY_MC) {
/* this is to get LLC into play even in case LLC sharing is not used */
if (cpumask_test_cpu(other_cpu, llc_core_cpumask(cpu)))
rq->cpu_locality[other_cpu] = LOCALITY_MC_LLC;
else
rq->cpu_locality[other_cpu] = LOCALITY_MC;
}
}
rq->cache_idle = cache_cpu_idle;
}
#endif
#ifdef CONFIG_SCHED_SMT
leader = NULL;
if (cpumask_weight(thread_cpumask(cpu)) > 1) { //目前通过gdb跟踪看,这里分支都没进去过
cpumask_copy(&rq->thread_mask, thread_cpumask(cpu));
cpumask_clear_cpu(cpu, &rq->thread_mask);
for_each_cpu(other_cpu, thread_cpumask(cpu)) {
if (rqshare == RQSHARE_SMT) {
other_rq = cpu_rq(other_cpu);
/* Set the smt_leader to the first CPU */
if (!leader)
leader = rq;
if (!other_rq->smt_leader)
other_rq->smt_leader = leader;
}
if (rq->cpu_locality[other_cpu] > LOCALITY_SMT)
rq->cpu_locality[other_cpu] = LOCALITY_SMT;
}
rq->siblings_idle = siblings_cpu_idle;
smt_threads = true;
}
#endif
}
#ifdef CONFIG_SMT_NICE
if (smt_threads) {
check_siblings = &check_smt_siblings;
wake_siblings = &wake_smt_siblings;
smt_schedule = &smt_should_schedule;
}
#endif
for_each_online_cpu(cpu) {
rq = cpu_rq(cpu);
for_each_online_cpu(other_cpu) {
printk(KERN_DEBUG "MuQSS locality CPU %d to %d: %d\n", cpu, other_cpu, rq->cpu_locality[other_cpu]);
}
}
}
来拆分下上面的select_leaders代码分析分析:
#首先是3个for循环
for循环遍历所有cpu{
for循环遍历每个cpu所在的domain调度域{
for循环遍历domain中每个cpu{
这里会处理RQSHARE_SMP以及RQSHARE_ALL两种,其smp_leader指向第一个for循环下的cpu的rq;
这里会设置cpu的locality,其到自己locality是0,到其他cpu都复制4
}
}
}
rqshare=all

rqshare=smp
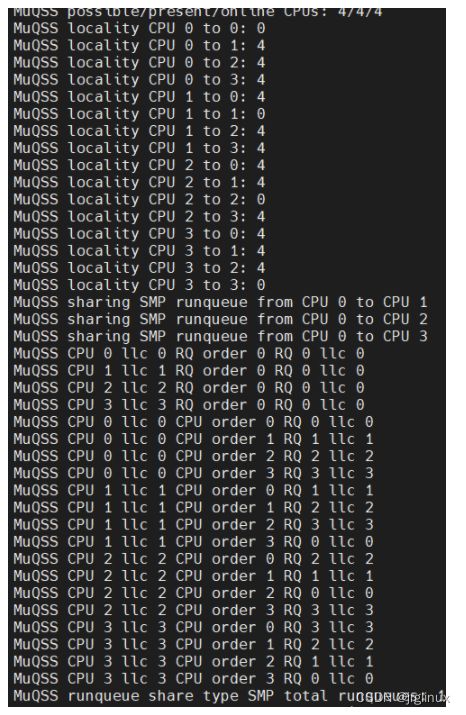
rqshare=llc

rqshare=mc
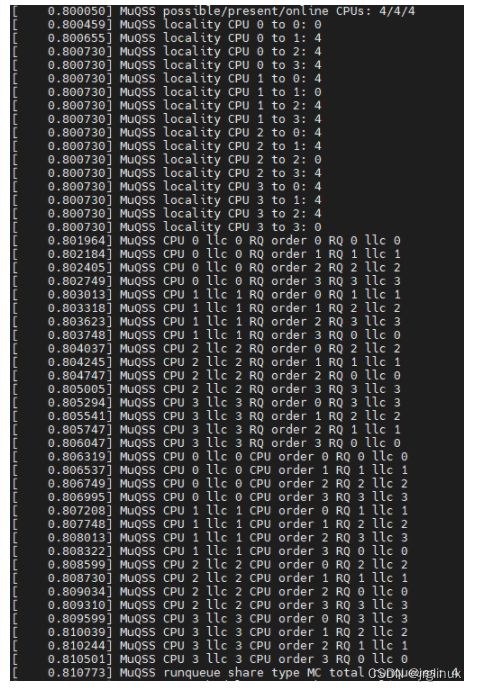
rqshare=smt
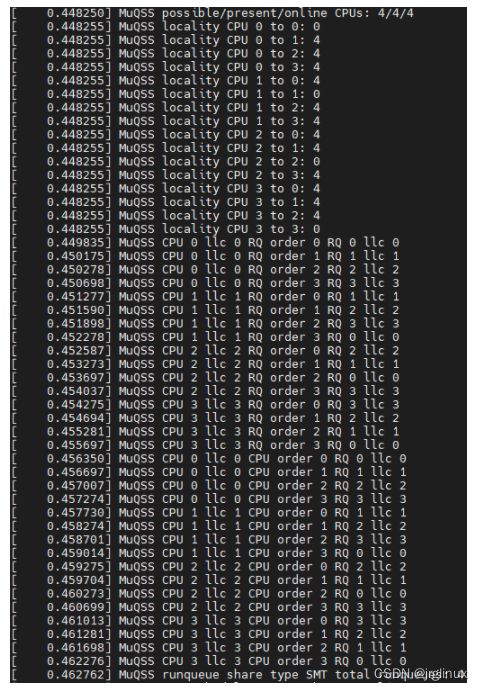
rqshare=none
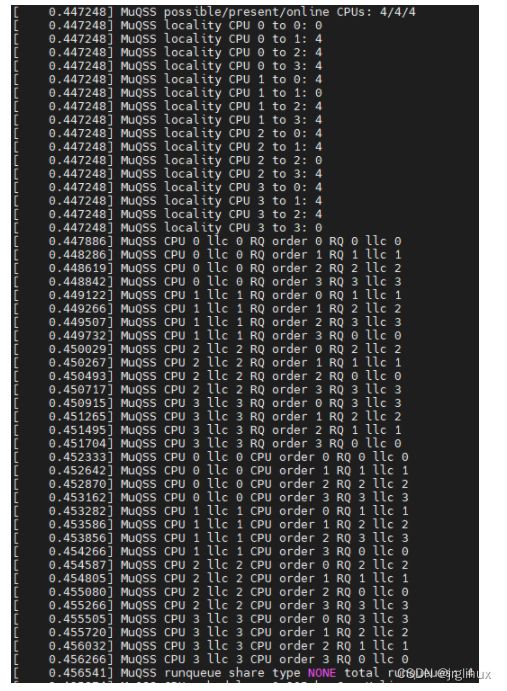
对比以上rqshare的6种可能性打印看,x86架构下locality就两种值,0(LOCALITY_SAME)或者4(LOCALITY_SMP)。
setup_rq_orders
该函数设置rq->rq_orders[]数组和rq->cpu_orders[]数组
static void __init setup_rq_orders(void)
{
int *selected_cpus, *ordered_cpus;
struct rq *rq, *other_rq;
int cpu, other_cpu, i;
selected_cpus = kmalloc(sizeof(int) * NR_CPUS, GFP_ATOMIC); //分配int型数组空间,NR_CPUS个int元素
ordered_cpus = kmalloc(sizeof(int) * NR_CPUS, GFP_ATOMIC);
total_runqueues = 0; /*这里total_runqueues按理应该等于online_cpus的数量*/
for_each_online_cpu(cpu) {
int locality, total_rqs = 0, total_cpus = 0;
rq = cpu_rq(cpu);
if (rq->is_leader)
total_runqueues++; /*is_leader和total_runqueues有关联, rqshare=smp/all时,所有cpu共享leader的rq,total_runqueue=1*/
/*从locality_same = 0, 遍历到 locality_distant = 5, 共执行6次for循环*/
for (locality = LOCALITY_SAME; locality <= LOCALITY_DISTANT; locality++) {
int selected_cpu_cnt, selected_cpu_idx, test_cpu_idx, cpu_idx, best_locality, test_cpu;
int ordered_cpus_idx;
ordered_cpus_idx = -1;
selected_cpu_cnt = 0;
for_each_online_cpu(test_cpu) {
if (cpu < num_online_cpus() / 2)
other_cpu = cpu + test_cpu;
else
other_cpu = cpu - test_cpu;
if (other_cpu < 0)
other_cpu += num_online_cpus();
else
other_cpu %= num_online_cpus();
/* gather CPUs of the same locality */
if (rq->cpu_locality[other_cpu] == locality) {
selected_cpus[selected_cpu_cnt] = other_cpu;
selected_cpu_cnt++;
}
}
/* reserve first CPU as starting point */
if (selected_cpu_cnt > 0) {
ordered_cpus_idx++;
ordered_cpus[ordered_cpus_idx] = selected_cpus[ordered_cpus_idx];
selected_cpus[ordered_cpus_idx] = -1;
}
/* take each CPU and sort it within the same locality based on each inter-CPU localities */
for (test_cpu_idx = 1; test_cpu_idx < selected_cpu_cnt; test_cpu_idx++) {
/* starting point with worst locality and current CPU */
best_locality = LOCALITY_DISTANT;
selected_cpu_idx = test_cpu_idx;
/* try to find the best locality within group */
for (cpu_idx = 1; cpu_idx < selected_cpu_cnt; cpu_idx++) {
/* if CPU has not been used and locality is better */
if (selected_cpus[cpu_idx] > -1) {
other_rq = cpu_rq(ordered_cpus[ordered_cpus_idx]);
if (best_locality > other_rq->cpu_locality[selected_cpus[cpu_idx]]) {
/* assign best locality and best CPU idx in array */
best_locality = other_rq->cpu_locality[selected_cpus[cpu_idx]];
selected_cpu_idx = cpu_idx;
}
}
}
/* add our next best CPU to ordered list */
ordered_cpus_idx++;
ordered_cpus[ordered_cpus_idx] = selected_cpus[selected_cpu_idx];
/* mark this CPU as used */
selected_cpus[selected_cpu_idx] = -1;
}
/* set up RQ and CPU orders */
for (test_cpu = 0; test_cpu <= ordered_cpus_idx; test_cpu++) {
other_rq = cpu_rq(ordered_cpus[test_cpu]);
/* set up cpu orders */
rq->cpu_order[total_cpus++] = other_rq;
if (other_rq->is_leader) {
/* set up RQ orders */
rq->rq_order[total_rqs++] = other_rq;
}
}
}
}
kfree(selected_cpus);
kfree(ordered_cpus);
#ifdef CONFIG_X86
for_each_online_cpu(cpu) {
rq = cpu_rq(cpu);
for (i = 0; i < total_runqueues; i++) {
printk(KERN_DEBUG "MuQSS CPU %d llc %d RQ order %d RQ %d llc %d\n", cpu, per_cpu(cpu_llc_id, cpu), i,
rq->rq_order[i]->cpu, per_cpu(cpu_llc_id, rq->rq_order[i]->cpu));
}
}
for_each_online_cpu(cpu) {
rq = cpu_rq(cpu);
for (i = 0; i < num_online_cpus(); i++) {
printk(KERN_DEBUG "MuQSS CPU %d llc %d CPU order %d RQ %d llc %d\n", cpu, per_cpu(cpu_llc_id, cpu), i,
rq->cpu_order[i]->cpu, per_cpu(cpu_llc_id, rq->cpu_order[i]->cpu));
}
}
#endif
}