MySQL架构浅析
一,MySQL的整体架构
我们可以先看看下图MySQL的整体架构图
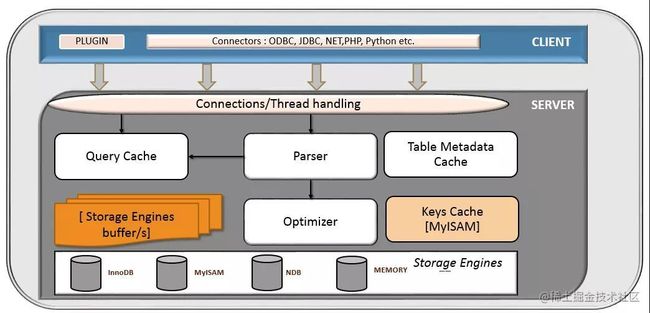
MySQL的逻辑架构大致可以分为三层
- 应用层
- 服务层
- 存储引擎层
1.1 应用层
应用层是MySQL体系架构的最上层,它可其他client-server架构一样,主要包含如下内容:
- 连接处理
- 用户鉴权
- 安全管理
1. 连接处理当一个客户端向服务端发送连接请求后,MySQL server会从线程池中分配一个线程来和客户端进行连接,以后该客户端的请求都会被分配到该线程上。MySQL Server为了提高性能,提供了线程池,减少了创建线程和释放线程所花费的时间。
2. 用户鉴权 当客户端向MySQL服务端发起连接请求后,MySQL server会对发起连接的用户进行鉴权处理,MySQL鉴权依据是: 用户名,客户端主机地址和用户密码
3. 安全管理 当客户连接到MySQL server后,MySQL server会根据用户的权限来判断用户具体可执行哪些操作。
1.2 服务层
该层是MySQL Server的核心层,提供了MySQL Server数据库系统的所有逻辑功能,该层可以分为如下不同的组件:
- MySQL Management Server & utilities(系统管理)
- SQL Interface(SQL 接口)
- SQL Parser(SQL 解析器)
- Optimizer (查询优化器)
- Caches & buffers(缓存)
1. MySQL Management Server & utilities(系统管理) 提供了丰富的数据库管理功能,具体如下:
- 数据库备份和恢复
- 数据库安全管理,如用户及权限管理
- 数据库复制管理
- 数据库集群管理
- 数据库分区,分库,分表管理
- 数据库元数据管理
2. SQL Interface(SQL 接口) SQL接口,接收用户的SQL命令并进行处理,得到用户所需要的结果,具体处理功能如下:
- Data Manipulation Language (DML).
- Data Definition Language (DDL).
- 存储过程
- 视图
- 触发器
3. SQL Parser(SQL 解析器) 解析器的作用主要是解析查询语句,最终生成语法树。首先解析器会对查询语句进行语法分析,如果语句语法有错误,则返回相应的错误信息。语法检查通过后,解析器会查询缓存,如果缓存中有对应的语句,就直接返回结果不进行接下来的优化执行操作。
注:读者会疑问,从缓存中查出来的数据会不会被修改,与真实的数据不一致,这里读者大可放心,因为缓存中数据被修改,会被清出缓存。
4. Optimizer(查询优化器) 优化器的作用主要是对查询语句进行优化,包括选择合适的索引,数据的读取方式。
5. Caches & buffers(缓存) 包括全局和引擎特定的缓存,提高查询的效率。如果查询缓存中有命中的查询结果,则查询语句就可以从缓存中取数据,无须再通过解析和执行。这个缓存机制是由一系列小缓存组成,如表缓存、记录缓存、key缓存、权限缓存等。
1.3 存储引擎层
1. 存储引擎 存储引擎是MySQL中具体与文件打交道的子系统,也是MySQL最有特色的地方。MySQL区别于其他数据库的最重要特点是其插件式的表存储引擎。他根据MySQL AB公司提供的文件访问层抽象接口来定制一种文件访问的机制(该机制叫存储引擎)。
2. 物理文件 物理文件包括:redolog、undolog、binlog、errorlog、querylog、slowlog、data、index等
二,一条SQL语句的旅程
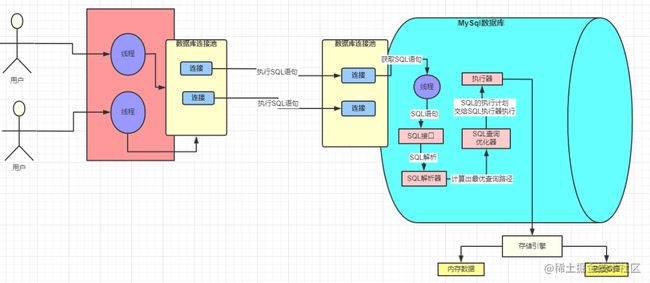
2.1 连接交互
我们在对MySQL进行CURD操作的时候,依赖于MySQL驱动来帮助我们进行连接的建立和维护,在底层帮助我们维护一个线程池来和MySQL服务器端进行交互。采用连接池大大节省了不断创建与销毁线程的开销。,网络中的连接都是由线程来处理的,所谓网络连接说白了就是一次请求,每次请求都会有相应的线程去处理的。也就是说对于 SQL 语句的请求在 MySQL 中是由一个个的线程去处理的。
2.2 解析SQL与优化
MySQL 中处理请求的线程在获取到请求以后获取 SQL 语句去交给 SQL 接口去处理。但是这个 SQL 是写给我们人看的,机器哪里知道你在说什么?这个时候解析器就上场了。他会将 SQL 接口传递过来的 SQL 语句进行解析,翻译成 MySQL 自己能认识的语言
然后就轮到查询优化器登场了,查询优化器内部具体怎么实现的我们不需要是关心,我需要知道的是 MySQL 会帮我去使用他自己认为的最好的方式去优化这条 SQL 语句,并生成一条条的执行计划,比如你创建了多个索引,MySQL 会依据成本最小原则来选择使用对应的索引,这里的成本主要包括两个方面, IO 成本和 CPU 成本
2.3 存储引擎的处理
在经过执行器处理之后,交由存储引擎进行最后的存储过程。这里只简要概述InnoDB处理的流程
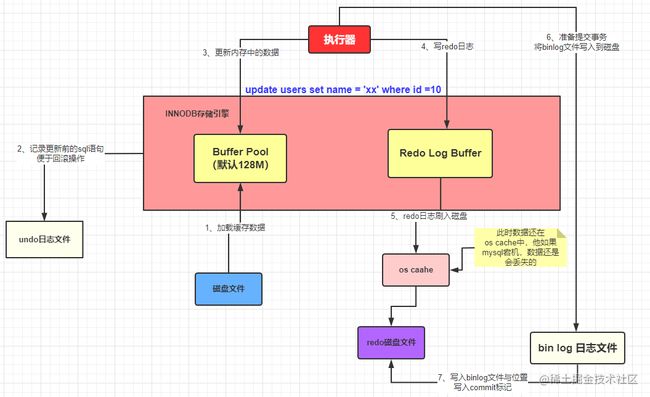
这里再简要概述一些基本概念:
buffer pool
Buffer Pool (缓冲池)是 InnoDB 存储引擎中非常重要的内存结构,顾名思义,缓冲池其实就是类似 Redis 一样的作用,起到一个缓存的作用,因为我们都知道 MySQL 的数据最终是存储在磁盘中的,如果没有这个 Buffer Pool 那么我们每次的数据库请求都会磁盘中查找,这样必然会存在 IO 操作,这肯定是无法接受的。但是有了 Buffer Pool 就是我们第一次在查询的时候会将查询的结果存到 Buffer Pool 中,这样后面再有请求的时候就会先从缓冲池中去查询,如果没有再去磁盘中查找。
undo log
记录数据被修改前的样子
redo log
记录数据被修改后的样子
除了从磁盘中加载文件和将操作前的记录保存到 undo 日志文件中,其他的操作是在内存中完成的,内存中的数据的特点就是:断电丢失。如果此时 MySQL 所在的服务器宕机了,那么 Buffer Pool 中的数据会全部丢失的。这个时候 redo 日志文件就需要来大显神通了
binlog
记录整个过程,分为statement、mixed、rows三种模式,属于逻辑性质的记录,且属于MySQL层面的文件,并非属于存储引擎。