Introduction
Hello again!
We are in the process of optimizing a SQL Server database, and so far we have done lots of things. We applied indexing in our database tables and then re-factored the TSQLs to optimize the data access routines. If you are wondering where we did all these and what are the things we have done, take a look at the following articles in this series:
- Top 10 steps to optimize data access in SQL Server: Part I (Use indexing)
- Top 10 steps to optimize data access in SQL Server: Part II (Re-factor TSQL and apply best practices)
So, you have done all these and still having performance problems with your database? Let me tell you one thing. Even after you have applied proper indexing along with re-factoring your TSQLs with best practices, some data access routines might still be there which would be expensive in terms of their execution time. There must be some smart ways to deal with these.
Yes, there are. SQL Server offers you some rich indexing techniques that you might have not used earlier. These could surprise you with the performance benefits they possibly offer. Let us start implementing those advanced indexing techniques:
Step 6: Apply some advanced indexing techniques
Implement computed columns and create an index on these
You might have written application code where you select a result set from the database and do a calculation for each row in the result set to produce the ultimate information to show in the output. For example, you might have a query that retrieves Order information from the database, and in the application, you might have written code to calculate the total Order price by doing arithmetic operations on Product and Sales data. But, why don't you do all this processing in the database?
Take a look at the following figure. You can specify a database column as a "computed column" by specifying a formula. While your TSQL includes the computed column in the select list, the SQL engine will apply the formula to derive the value for this column. So, while executing the query, the database engine will calculate the Order total price and return the result for the computed column.
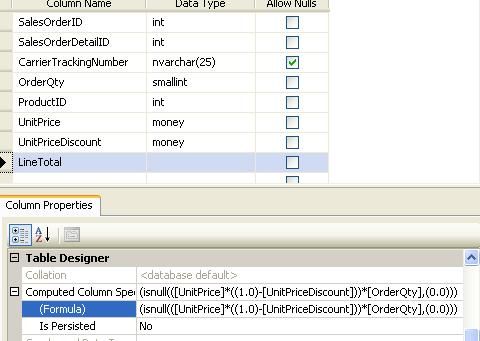
Sounds good. Using a computed column in this way would allow you to do the entire calculation in the back-end. But sometimes, this might be expensive if the table contains a large number of rows. The situation might get worse if the computed column is specified in the WHERE clause in a SELECT statement. In this case, to match the specified value in the WHERE clause, the database engine has to calculate the computed column's value for each row in the table. This is a very inefficient process because it always requires a table or full clustered index scan.
So, we need to improve performance on computed columns. How? The solution is, you need to create an index on the computed columns. When an index is built on a computed column, SQL Server calculates the result in advance and builds an index over them. Additionally, when the corresponding column values are updated (that the computed column depends on), the index values on the computed column are also updated. So, while executing the query, the database engine does not have to execute the computation formula for every row in the result set. Rather, the pre-calculated values for the computed column are just selected and returned from the index. As a result, creating an index on a computed column gives you excellent performance boost.
Note: If you want to create an index on a computed column, you must make sure that the computed column formula does not contain any "nondeterministic" function (for example, getdate() is a nondeterministic function because each time you call it, it returns a different value).
Create "Indexed Views"
Did you know that you can create indexes on views (with some restrictions)? Well, if you have come this far, let us learn about indexed views!
Why do we use Views?
As we all know, Views are nothing but compiled SELECT statements residing as objects in a database. If you implement your common and expensive TSQLs using Views, it's obvious that you can re-use these across your data access routines. Doing this will enable you to join Views with other tables/views to produce an output result set, and the database engine will merge the view definition with the SQL you provide and will generate an execution plan to execute. Thus, sometimes Views allow you to re-use common complex SELECT queries across your data access routines, and also let the database engine to re-use execution plans for some portion of your TSQLs.
Take my word. Views don't give you any significant performance benefit. In my early SQL days, when I first learned about views, I got exited thinking that Views were something that "remembers" the result for the complex SELECT query it is built upon. But soon, I was disappointed to know that Views are nothing but compiled queries, and Views just can't remember any result set. (Poor me! I can bet many of you got the same wrong idea about Views in your first SQL days.)
But now, I may have a surprise for you! You can do something on a View so that it can truly "remember" the result set for the SELECT query it is composesd of. How? It's not hard; you just have to create indexes on the View.
Well, if you apply indexing on a View, the View becomes an "indexed view". For an indexed View, the database engine processes the SQL and stores the result in the data file just like a clustered table. SQL Server automatically maintains the index when data in the base table changes. So, when you issue a SELECT query on the indexed View, the database engine simply selects values from an index, which obviously performs very fast. Thus, creating indexes on views gives you excellent performance benefits.
Please note that nothing comes free. As creating indexed Views gives you performance boost, when data in the base table changes, the database engine has to update the index also. So, you should consider creating indexed Views when the view has to process too many rows with aggregate functions, and when data and the base table do not change often.
How to create an indexed View?
- Create/modify the view specifying the
SCHEMABINDINGoption:
CREATE VIEW dbo.vOrderDetails WITH SCHEMABINDING AS SELECT...
- Create a unique clustered index on the View.
- Create a non-clustered index on the View as required.
Wait! Don't get too much exited about indexed Views. You can't always create indexes on Views. Following are the restrictions:
- The View has to be created with the
SCHEMABINDINGoption. In this case, the database engine will not allow you to change the underlying table schema. - The View cannot contain nondeterministic functions,
DISTINCTclause, or subquery. - The underlying tables in the View must have a clustered index (primary keys).
Try finding the expensive TSQLs in your application that are already implemented using Views or that could be implemented using Views. Try creating indexes on these Views to boost up your data access performance.
Create indexes on User Defined Functions (UDF)
Did you know this? You can create indexes on User Defined Functions too in SQL Server. But, you can't do this in a straightforward way. To create an index on a UDF, you have to create a computed column specifying a UDF as the formula, and then you have to create an index on the computed column field.
Here are the steps to follow:
- Create the function (if not exists already) and make sure that the function (that you want to create the index on) is deterministic. Add the
SCHEMABINDINGoption in the function definition and make sure that there is no non-deterministic function/operator (getdate()ordistinctetc.) in the function definition.
For example:
CREATE FUNCTION [dbo.ufnGetLineTotal] ( -- Add the parameters for the function here @UnitPrice [money], @UnitPriceDiscount [money], @OrderQty [smallint] ) RETURNS money WITH SCHEMABINDING AS BEGIN return (((@UnitPrice*((1.0)-@UnitPriceDiscount))*@OrderQty)) END
- Add a computed column in your desired table and specify the function with parameters as the value of the computed column.
CREATE FUNCTION [dbo.ufnGetLineTotal] ( -- Add the parameters for the function here @UnitPrice [money], @UnitPriceDiscount [money], @OrderQty [smallint] ) RETURNS money WITH SCHEMABINDING AS BEGIN return (((@UnitPrice*((1.0)-@UnitPriceDiscount))*@OrderQty)) END
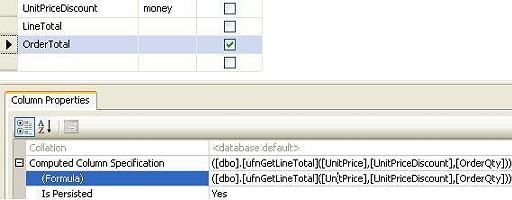
- Create an index on the computed column.
We have already seen that we can create an index on computed columns to retrieve faster results on computed columns. But, what benefit could we achieve by using a UDF in the computed columns and creating an index on those?
Well, doing this would give you a tremendous performance benefit when you include the UDF in a query, especially if you use UDFs in the join conditions between different tables/views. I have seen lots of join queries written using UDFs in the joining conditions. I've always thought UDFs in join conditions are bound to be slow (if the number of results to process is significantly large), and there has to be a way to optimize it. Creating indexes on functions in the computed columns is the solution.
Create indexes on XML columns
Create indexes on XML columns if there is any. XML columns are stored as binary large objects (BLOBs) in SQL Server (SQL Server 2005 and later) which can be queried using XQuery, but querying XML data types can be very time consuming without an index. This is true especially for large XML instances because SQL Server has to shred the binary large object containing the XML at runtime to evaluate the query.
To improve query performance on XML data types, XML columns can be indexed. XML indexes fall in two categories:
Primary XML indexes
When the primary index on an XML column is created, SQL Server shreds the XML content and creates several rows of data that includes information like element and attribute names, the path to the root, node types and values, and so on. So, creating the primary index enables SQL server to support XQuery requests more easily.
Following is the syntax for creating a primary XML index:
CREATE PRIMARY XML INDEX index_name ON <object> ( xml_column )
Secondary XML indexes
Creating primary XML indexes improves XQuery performance because the XML data is shredded already. But, SQL Server still needs to scan through the shredded data to find the desired result. To further improve query performance, secondary XML index should be created on top of primary XML indexes.
Three types of secondary XML indexes are there. These are:
- "Path" secondary XML indexes: Useful when using the
.exist()methods to determine whether a specific path exists. - "Value" secondary XML indexes: Used when performing value-based queries where the full path is unknown or includes wildcards.
- "Property" secondary XML indexes: Used to retrieve property values when the path to the value is known.
Following is the syntax for creating secondary XML indexes:
CREATE XML INDEX index_name ON <object> ( xml_column ) USING XML INDEX primary_xml_index_name FOR { VALUE | PATH | PROPERTY }
Please note that the above guidelines are the basics. But, creating indexes blindly on each and every table on the mentioned columns may not always result in performance optimization, because sometimes, you may find that creating indexes on particular columns in particular tables result in slowing down data insert/update operations in that table (particularly if the table has a low selectivity on a column). Also, if the table is a small one containing a small number of rows (say, <500), creating an index on the table might in turn increase the data retrieval performance (because, for smaller tables, a table scan is faster). So, we should be judicious while determining the columns to create indexes on.
Step 7: Apply de-normalizations, use history tables and pre-calculated columns
De-normalization
If you are designing a database for an OLTA system (Online Transaction Analytical system that is mainly a data warehouse which is optimized for read-only queries), you can (and should) apply heavy de-normalizing and indexing in your database. That is, the same data will be stored across different tables, but the reporting and data analytical queries would run very fast on these kinds of databases.
But, if you are designing a database for an OLTP system (Online Transaction Processing System that is mainly a transactional system where mostly data update operations take place [that is, INSERT/UPDATE/DELETE operations which we are used to work with most of the time]), you are advised to implement at least 1st, 2nd, and 3rd Normal forms so that you can minimize data redundancy, and thus minimize data storage and increase manageability.
Despite the fact that we should apply normalizations in an OLTP system, we usually have to run lots of read operations (SELECT queries) on the database. So, after applying all the optimization techniques so far, if you find that some of your data retrieval operations are still not performing efficiently, you need to consider applying some sort of de-normalization. So the question is, how should you apply de-normalization and why would this improve performance?
Let us see a simple example to find the answer
Let's say we have two tables OrderDetails(ID,ProductID,OrderQty) and Products(ID,ProductName) that store Order Detail information and Product information, respectively. Now, to select the product names with their ordered quantity for a particular order, we need to issue the following query that requires joining the OrderDetails and Products tables.
SELECT Products.ProductName,OrderQty FROM OrderDetails INNER JOIN Products ON OrderDetails.ProductID = Products.ProductID WHERE SalesOrderID = 47057
Now, if these two tables contain a huge number of rows, and if you find that the query is still performing slowly even after applying all the optimization steps, you can apply some de-normalization as follows:
- Add the column ProductName to the OrderDetails table and populate the ProductName column values.
- Rewrite the above query as follows:
SELECT ProductName,OrderQty FROM OrderDetails WHERE SalesOrderID = 47057
Please note that after applying de-normalization in the OrderDetails table, you no longer need to join the OrderDetails table with the Products table to retrieve product names and their ordered quantity. So, while executing the SQL, the execution engine does not have to process any joining between the two tables. So the query performs relatively faster.
Please note that in order to improve the Select operation's performance, we had to do a sacrifice. The sacrifice was, we had to store the same data (ProductName) in two places (in the OrderDetails and Products tables). So, while we insert/update the ProductName field in the Products table, we also have to do the same in the OrderDetails table. Additionally, doing this de-normalization will increase the overall data storage.
So, while de-normalizing, we have to do some trade-offs between data redundancy and the Select operation's performance. Also, we have to re-factor some of our data insert/update operations after applying de-normalization. Please be sure to apply de-normalization only if you have applied all other optimization steps and yet need to boost up the data access performance. Also, make sure that you don't apply heavy de-normalizations so that your basic data design does not get destroyed. Apply de-normalization (when required) only on the key tables that are involved in the expensive data access routines.
History tables
In your application, if you have some data retrieval operation (say, reporting) that periodically runs on a time period, and if the process involves tables that are large in size having normalized structure, you can consider moving data periodically from your transactional normalized tables into a de-normalized, heavily indexed, single history table. You also can create a scheduled operation in your database server that would populate this history table at a specified time each day. If you do this, the periodic data retrieval operation then has to read data only from a single table that is heavily indexed, and the operation would perform a lot faster.
For example, let's say a chain store has a monthly sales reporting process that takes 3 hours to complete. You are assigned to minimize the time it takes, and to do this, you can follow these steps (along with performing other optimization steps):
- Create a history table with de-normalized structure and heavy indexing to store sales data.
- Create a scheduled operation in SQL Server that runs on a 24 hours interval (midnight) and specify a SQL for the scheduled operation to populate the history table from the transactional tables.
- Modify your reporting code so that it reads data from the history table now.
Creating the scheduled operation
Follow these simple steps to create a scheduled operation in SQL Server that periodically populates a history table on a specified schedule.
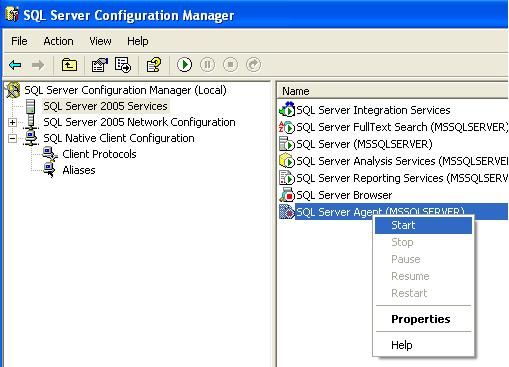
- Make sure that SQL Server Agent is running. To do this, launch the SQL Server Configuration Manager, click on SQL Server 2005 Services, and start the SQL Server Agent by right clicking on it.
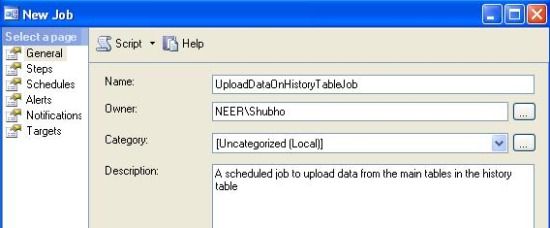
- Expand the SQL Server Agent node in Object Explorer and click on the "Job" node to create a new job. In the General tab, provide the job name and descriptions.
- On the "Steps" tab, click on the "New" button to create a new job step. Provide a name for the step and also provide the TSQL (that would load the history table with the daily sales data) and provide the Type as "Transact-SQL script (T-SQL)". Press "OK" to save the step.
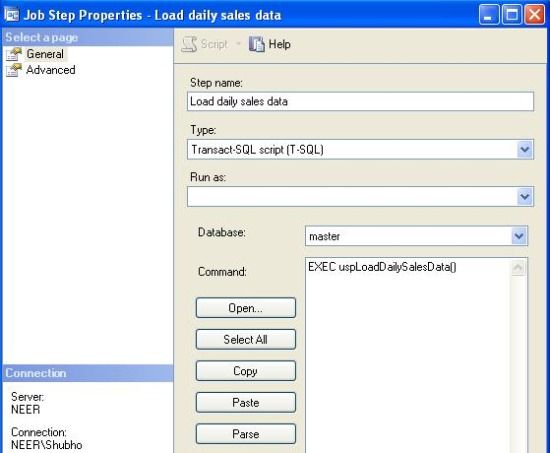
- Go to the "Schedule" tab and click on the "New" button to specify a job schedule.
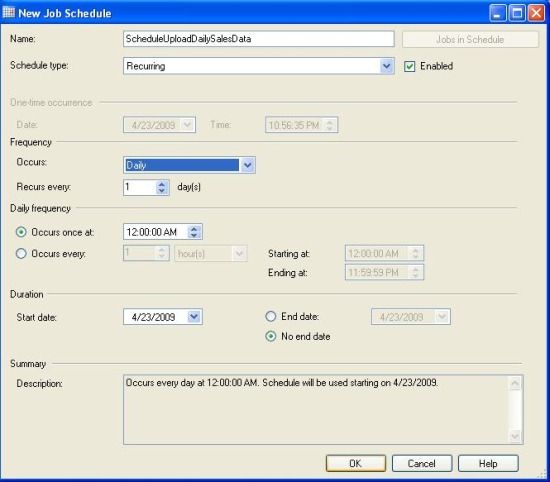
- Click the "OK" button to save the schedule and also apply the schedule on the specified job.
Perform expensive calculations in advance in data INSERT/UPDATE, simplify SELECT query
Naturally, in most of the cases in your application, you will see that data insert/update operations occur one by one, for each record. But, data retrieval/read operations involve multiple records at a time.
So, if you have a slowly running read operation (Select query) that has to do complex calculations to determine a resultant value for each row in the big result set, you can consider doing the following:
- Create an additional column in a table that will contain the calculated value.
- Create a trigger for Insert/Update events on this table, and calculate the value there using the same calculation logic that was in the
Selectquery earlier. After calculation, update the newly added column value with the calculated value. - Replace the existing calculation logic from your
Selectquery with the newly created field
After implementing the above steps, the insert/update operation for each record in the table will be a bit slower (because the trigger will now be executed to calculate a resultant value), but the data retrieval operation should run faster than before. The reason is obvious; while the SELECT query executes, the database engine does not have to process the expensive calculation logic any more for each row.
What's next?
I wish you have enjoyed all the optimization steps done so far. We have gone through indexing, refactoring the TSQLs, applying some advanced indexing techniques, de-normalizing portion of the database, and using History tables, to speed up our data access routines. Having done all of the above steps should bring your data access operations to a satisfactory level, but we are not satisfied yet (are we?).
So, we are going to do many more things to do further optimizations in our data access operations. Let's now go through the next article in this series:
- Top 10 steps to optimize data access in SQL Server: Part IV (Diagnose database performance problems)
History
- First version: 1 May 2010.