Day50 Hadoop概述及其架构
目录
概述:
启动Hadoop
失败的情况:
1、没有该Hadoop界面:
2、Hadoop界面中没有子节点:
上传文件
运行wordcount
参数解释:
Hadoop基本命令
详细启动脚本介绍
1、全部启动集群所有进程
2、单独启动hdfs(web端口50070)和yarn(web端口8088)的相关进程
3、单独启动某一个进程
hdfs shell
常用操作:
概述:
Hadoop的三种运行模式:
1.本地模式(学习)
1.没有HDFS,使用当前系统下的文件系统
2.没有YARN,使用的是Linux中的资源
3.使用了 Map-Reduce Framework
2.伪分布式模式(学习)
1.只有单台机器
2.使用HDFS、Yarn、MapReduce
3.分布式模式(企业级)
1.多台服务器
2.集群模式,包含整个Hadoop组件
启动Hadoop
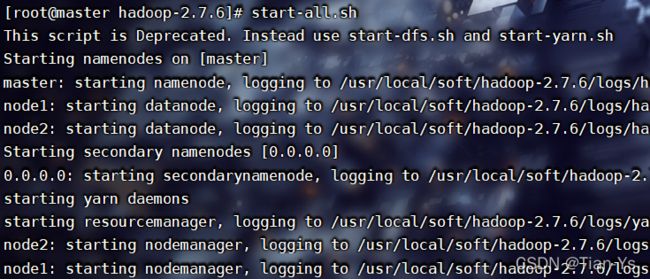
开启Hadoop集群所需要的所有虚拟机,使用Xshell或者FinalShell等连接到虚拟机,在主节点上输入命令:bash start-all.sh或者直接输入start-all.sh启动hadoop集群。
首次启动时会有一个确认是否连接本地的选项,输入yes即可。
启动完之后,由于整个Hadoop实际上是由Java编写出来的,所以在启动完之后可以使用jps命令查看当前启动的进程
输入:jps查看Hadoop中的各配置文件是否启动生效
主节点上的进程: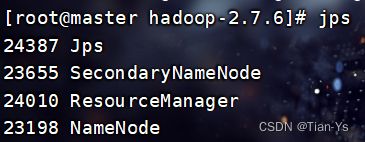
两个子节点上的进程: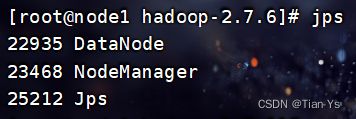
有这些内容表示配置文件都已生效
进入浏览器中输入master:50070查看Hadoop是否启动成功
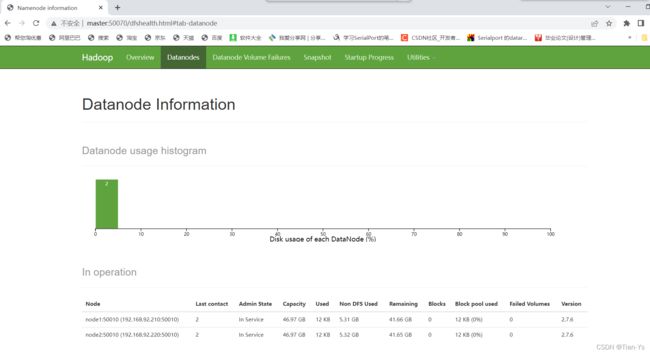
出现上述界面以及界面中含有两个子节点的信息,表示Hadoop启动成功
失败的情况:
1、没有该Hadoop界面:
可能原因:Windows中没有配置关于虚拟机的映射,因此找不到虚拟机的ip地址
解决办法:进入到C:/Windows/system32/driver/etc/hosts文件,打开该文件并向其中加入映射:
主节点IP地址 主节点主机名
子节点1IP地址 子节点1主机名
子节点2IP地址 子节点2主机名
点击保存并退出再次进入到浏览器中输入上述命令
若该文件在保存时弹出无法保存,只需将其移动至桌面打开,添加完映射后即可保存,然后将其移动至原来的文件夹中即可。
2、Hadoop界面中没有子节点:
原因:在设置配置文件时,其中某个配置文件的内容错误导致该文件没有生效
解决办法:进入到配置文件中查看其内容是否出错,对错误处进行修改保存。
然后输入命令:stop-all.sh停止Hadoop,删除主节点下的/usr/local/soft/hadoop-2.7.6下的tmp目录以及所有子节点中的/usr/local/soft/hadoop-2.7.6目录。
再重新分发:
scp -r /usr/local/soft/hadoop-2.7.6/ node1:/usr/local/soft/
scp -r /usr/local/soft/hadoop-2.7.6/ node2:/usr/local/soft/
最后输入命令:hdfs namenode -format 格式化namenode,重新启动Hadoop。
这里注意:配置文件中涉及到主机名以及端口号的部分需要改为自己的主机名及端口号等内容。
具体关于Hadoop的配置文件内容请前往Day44中查看
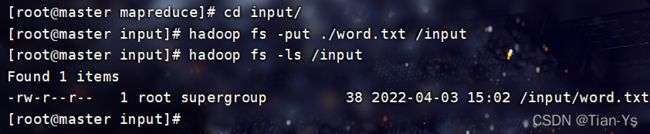
上传文件
向Hadoop中上传文件
命令:hadoop fs -put 文件名 上传路径
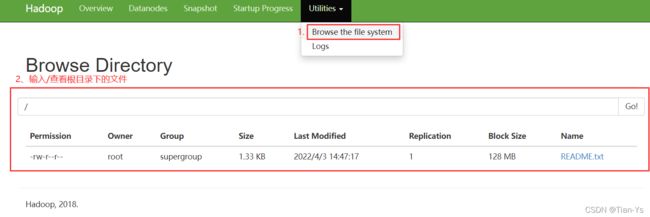
上传该目录下的README.txt文件至Hadoop的根目录下

进入到Hadoop中查看上传结果:
输入master:8088可以进入到yarn的控制页面
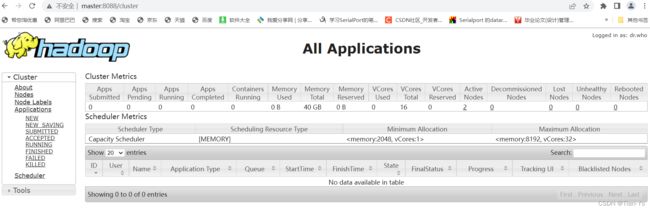
在该页面中可以查看当前正在运行以及正在提交的命令等
运行wordcount
进入到hadoop-2.7.6目录下的share/hadoop/mapreduce目录中,查看当前目录下的各种jar包
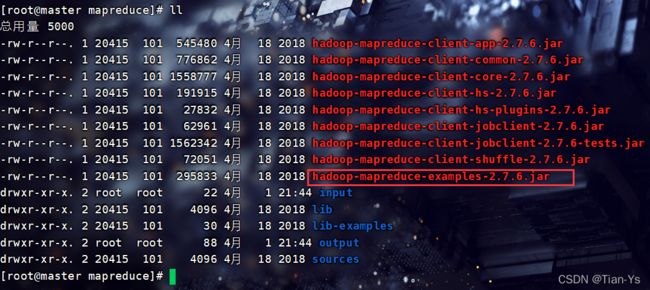
测试所选中的jar包:
在Hadoop中创建一个目录用于接收上传的目录文件,在将input目录中的txt文件上传到hadoop中
使用ls可以查看Hadoop中指定目录下的文件
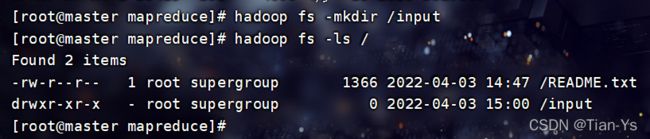
上传文件后的结果:
 测试jar包将输出目录output也放在根目录下 :运行wordcount实例
测试jar包将输出目录output也放在根目录下 :运行wordcount实例
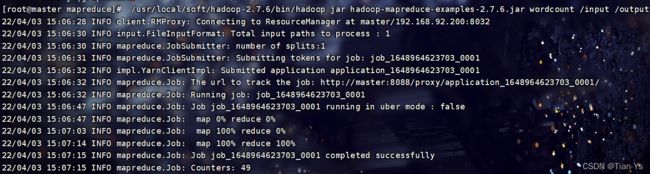
测试结果可以在yarn页面下查看:

这里显示状态为finished,表示测试成功
去Hadoop平台下观察具体结果:
Hadoop中会多出两个文件,刚创建的input目录和输出目录output,输出目录下会有两个文件

这表示txt文件中的内容以及被输出到了output下的success中,具体查看可以点击success下载查看
参数解释:
input目录下的各种参数解释:
 Permission:文件的权限,第一位表示该文件是否为目录文件,是表示d,不是表示-,r表示可读,w表示可写,x表示可执行
Permission:文件的权限,第一位表示该文件是否为目录文件,是表示d,不是表示-,r表示可读,w表示可写,x表示可执行
Owner:所有权
Group:该文件所属的用户组
Size:该文件的实际大小
Last Modified:最后一次的修改时间
Replication:副本数,个数在hdfs-site.xml配置文件中设置
Block Size:指一个block的最大容量也是标准容量为128MB
Name:文件名称
Hadoop基本命令
详细启动脚本介绍
1、全部启动集群所有进程
启动:在sbin目录下start-all.sh
停止:在sbin目录下stop-all.sh
2、单独启动hdfs(web端口50070)和yarn(web端口8088)的相关进程
启动:start-dfs.sh start-yarn.sh
停止:stop-dfs.sh stop-yarn.sh
该启动在每次重新启动集群的时候使用
3、单独启动某一个进程
启动hdfs:sbin/hadoop-daemon.sh start (namenode | datanode)
停止hdfs:sbin/hadoop-daemon.sh stop (namenode | datanode)
启动yarn:sbin/yarn-daemon.sh start (resourcemanager | nodemanager)
停止yarn:sbin/yarn-daemon.sh stop(resourcemanager | nodemanager)
用于当某个进程启动失败或者异常down掉的时候,重启进程
hdfs shell
hdfs shell表示的是一个执行命令的一个命令窗口,在这其中可以执行命令
调用文件系统(FS)Shell命令应使用 bin/hdfs dfs -xxx 的形式
含有两种命令模式:
1、hadoop fs -命令
2、hdfs dfs -命令
常用操作:
-ls 查看hdfs上目录,如 hdfs dfs -ls /
展示HDFS文件信息 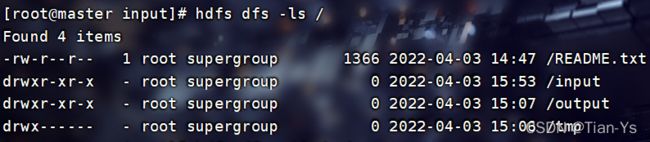
-put 将本地文件上传到hdfs,如hdfs dfs -put 本地文件路径 hdfs路径
-copyFromLocal 从本地上传文件,也可以实现上传操作
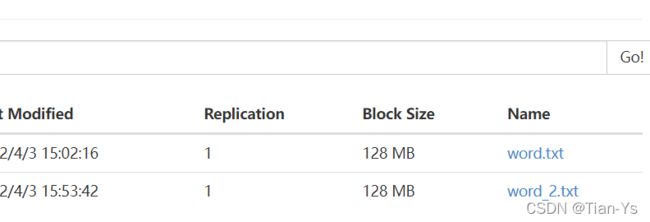
举例: 将本地文件夹input下的另一个文件word_2.txt上传到Hadoop中,使用copyFromLocal
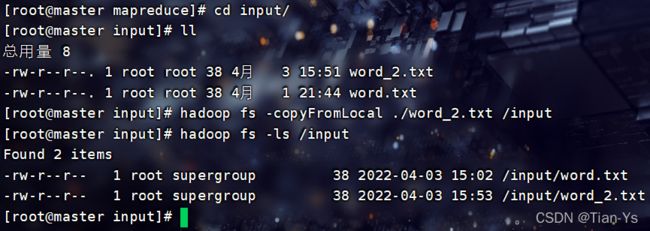
进入到Hadoop中查看结果:
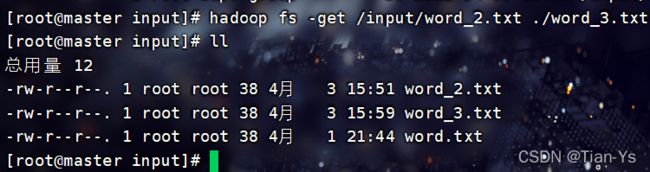
-get 将hdfs文件下载到本地,如 hdfs dfs -get hdfs文件路径 本地文件路径
-copyToLocal 下载文件到本地,也可以实现下载操作
举例:将刚上传的word_2.txt文件下载到本地并使用word_3.txt保存
-mkdir 在hdfs 上创建文件夹,如hdfs dfs -mkdir /test,加上-p表示迭代创建多级目录
-cp 将hdfs文件或目录复制 如 hdfs dfs -cp /test.txt /a/
-cat 查看hdfs上文件内容 如hdfs dfs -cat /test.txt
-chmod 赋予文件权限,如hdfs dfs -chmod u+x 路径 #表示对指定路径或文件赋予执行使用者权限
举例:赋予word.txt用户可执行权限

结果:

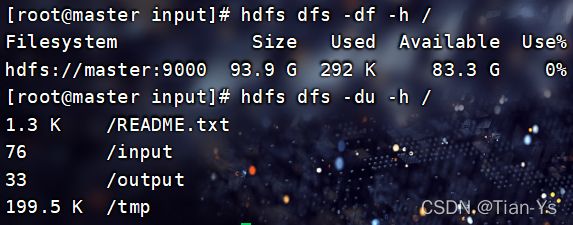
-df -h hdfs dfs -df -h / 查看HDFS根目录中空间使用情况
-du -h hdfs dfs -du -h / 查看指定目录下的文件大小
举例:
-mv 移动目录或者文件
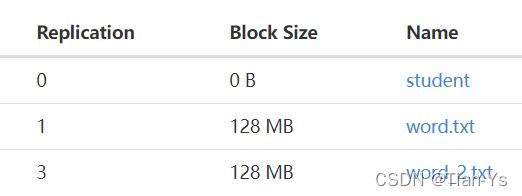
-setrep 设置副本数,如hadoop fs -setrep 副本数 多个路径
将input目录下的word_2.txt文件的副本数修改为3

进入到Hadoop中查看结果:
注意:setrep只可以进行修改,不可以进行上传,若在使用setrep时误操作写成了将本地文件设置副本数为3的同时上传到Hadoop中的根目录下,该操作会报错找不到目标文件, 然后将根目录下的所有文件的副本数全部设置为3
查看文件内容
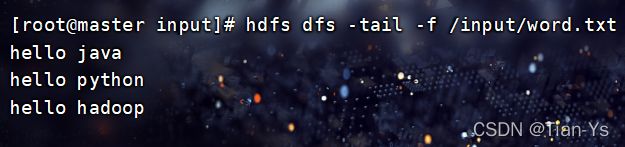
-tail 从文件末尾查看文件内容
-f:
hadoop fs -tail -f /input/word.txt 表示追踪文件的内容-cat
hadoop fs -cat /input/word.txt
使用cat同样可以实现查看文件内容